










Torch 预测模型
本文档是为dart版本0.15.0及更高版本编写的。
我们假设你已经知道dart中的协变量。如果你是这个话题的新手,我们建议你先阅读我们关于协变量的指南。
本章内容
第一小节涵盖了Torch Forecasting Models(TFMs)最重要的一点:
- 怎样用TFMs
- Top-level look at chunks
- TFM covariates support
- Time span requirements for target and covariate series
第二小节深入介绍了在使用TFMs进行训练和预测时如何使用输入数据。
介绍
In Darts, Torch Forecasting Models (TFMs) are broadly speaking “machine learning based” models, which denote PyTorch-based (deep learning) models.
TFMs在输入目标的固定长度块(子样本)和* _协变量系列(如果支持)上训练和预测。目标是我们想要预测未来的系列,* _协变量是过去和/或未来的协变量。
每个块包含一个输入块(代表样本的过去)和一个输出块(代表样本的未来)。样本的预测点位于输入块的末端。这些块的长度必须在创建模型时指定,参数为input_chunk_length和output_chunk_length(下一小节将详细介绍块)。
# model that looks 7 time steps back (past) and 1 time step ahead (future)
model = SomeTorchForecastingModel(input_chunk_length=7,
output_chunk_length=1,
**model_kwargs)
所有的TFMs都可以在单个或多个目标序列上训练,并且,根据它们的协变量支持(在本小节中涉及),past_covariates和/或future_covariates。当使用协变量时,你必须为每个目标序列提供一个专用的过去和/或未来协变量序列。
也可以在培训期间使用带有专用协变量的验证集。如果协变量具有所需的时间跨度,您可以将其用于培训、验证和预测。(本款所述)
# fit the model on a single target series with optional past and / or future covariates
model.fit(target,
past_covariates=past_covariates,
future_covariates=future_covariates,
val_series=target_val, # optionally, use a validation set
val_past_covariates=past_covariates_val,
val_future_covariates=future_covariates_val)
# fit the model on multiple target series
model.fit([target, target2, ...],
past_covariates=[past_covariates, past_covariates2, ...],
...
)
您可以为任何输入目标TimeSeries或多个作为TimeSeries序列给定的目标生成预测。这也适用于在训练中没有看到的系列,只要每个系列至少包含input_chunk_length时间步。
# predict the next n=3 time steps for any input series with `series`
prediction = model.predict(n=3,
series=target,
past_covariates=past_covariates,
future_covariates=future_covariates)
最高级的是用chunks进行训练和预测
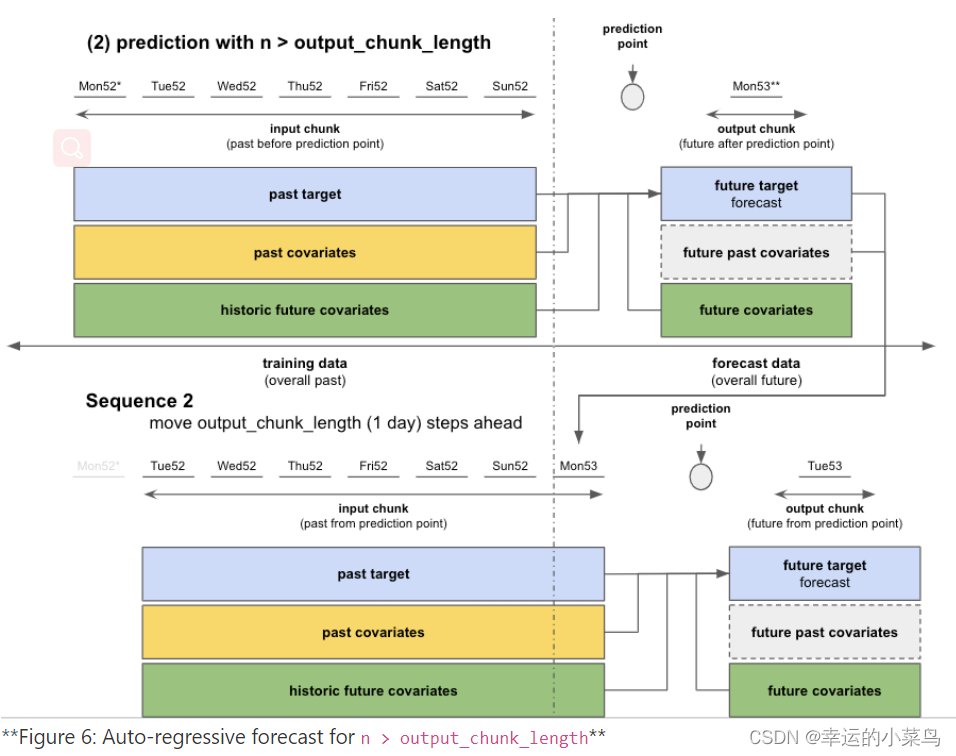
在图1中,您可以看到在调用fit()或predict()时数据是如何分布到每个示例的输入和输出块的。在本例中,我们使用每日频率查看数据。输入块从target中提取值,也可以从属于输入块时间跨度的past_covariates和/或future_covariates中提取值。这些future_协变量的“过去”值被称为“历史未来协变量”。
输出块只接受属于输出块时间跨度的可选future_covariates值。我们的past_covariates的未来值——“未来过去协变量”——只用于提供带有新数据的即将到来的样本的输入块。
所有这些信息都用于预测“未来目标”——“过去目标”结束后的下一个output_chunk_length点。
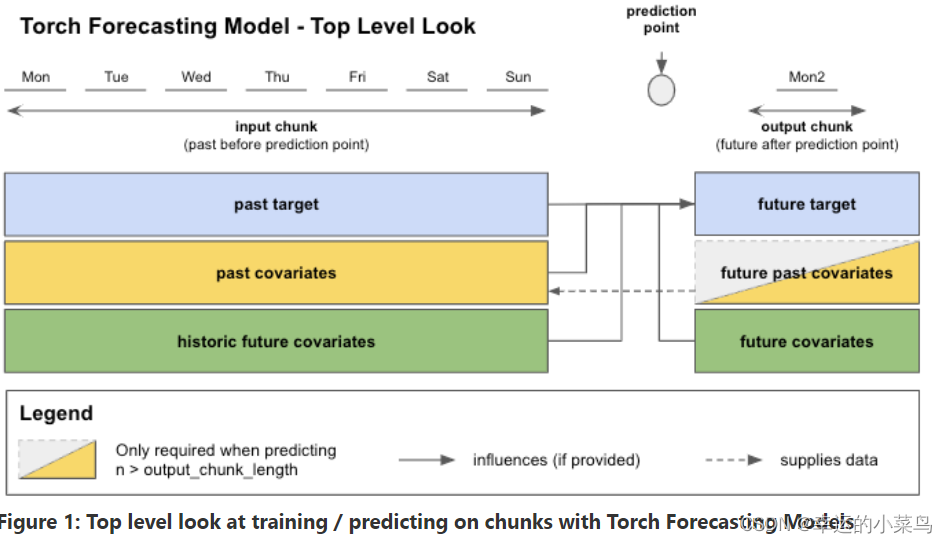
当调用predict()并根据您的预测水平n,模型可以一次性预测(如果n <= output_chunk_length),或者通过预测未来的多个块(如果n > output_chunk_length)来自动回归。这就是为什么用 past_covariates进行预测时,你可能必须提供额外的“你的 past_covariates 的未来值”的原因。
torch 支持协变量预测的模型
在内部,Darts有5种类型的{X}CovariatesModel类实现,以覆盖之前提到的协变量类型的不同组合:
Table 1: Darts’ “{X}CovariatesModels” covariate support
Each Torch Forecasting Model inherits from one {X}CovariatesModel (covariate class names are abbreviated by the X-part):
Table 2: Darts’ Torch Forecasting Model covariate support
训练集、测试集和预测需要目标测试时间跨度
模型根据序列的时间轴自动提取相关数据。如果fit()和predict()满足下面的要求,可以对它们使用相同的协变量序列。
只有在从传递给fit()的数据中提取出至少一个具有输入和输出块的样本时,训练才有效。这适用于训练和验证数据。就所需的最短时间跨度而言,这意味着:
- 最小长度的目标序列input_chunk_length + output_chunk_length
- covariates指南2.3节中fit()的时间跨度要求。
对于预测,你必须提供你希望预测的目标系列。对于任何预测视界,最小时间跨度的要求是:
- 最小长度的目标序列input_chunk_length
- predict()的时间跨度要求也来自协变量指南2.3节。
边注:我们的*RNNModels在模型创建时接受一个training_length参数,而不是output_chunk_length参数。在内部,这些模型的output_chunk_length自动设置为1。对于训练,过去的目标的最小长度必须为training_length + 1,对于预测,长度为input_chunk_length。
深入研究在使用TFMs进行训练和预测时如何使用输入数据
Training
让我们来看看这些模型是如何工作的。
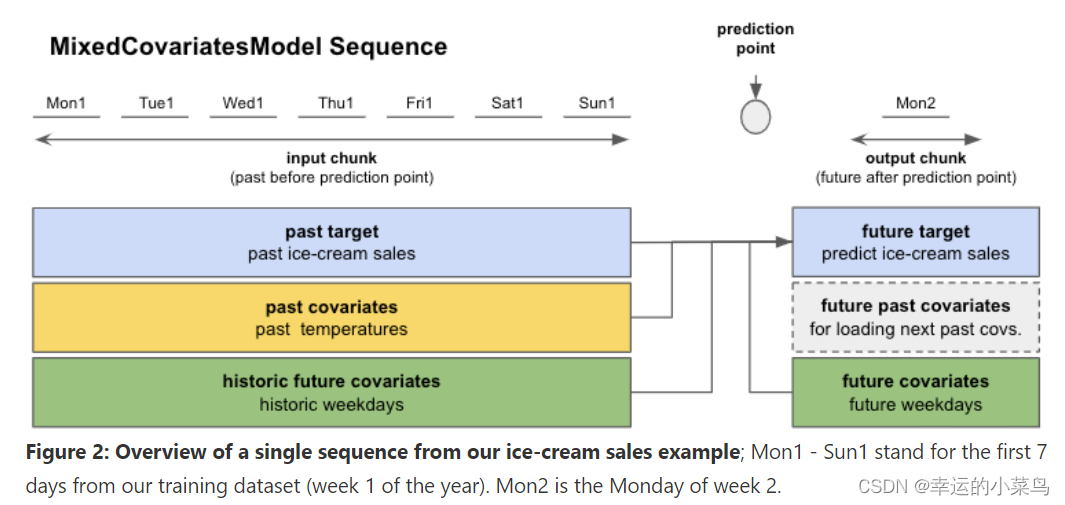
假设我们经营一家冰淇淋店,我们想要预测第二天的销量。我们有一年(365天)的过去一天的冰淇淋销售数据和平均测量的每日环境温度。我们还注意到,我们的冰淇淋销量取决于一周中的哪一天,因此我们希望将这一点包含在我们的模型中。
- 过去目标:实际过去的冰淇淋销量
- 未来目标:预测第二天的冰淇淋销量
- 过去协变量:在过去的温度中测量的平均每日温度
- 未来协变量:过去和未来工作日的星期几
检查表1,一个可以容纳这种协变量的模型是SplitCovariatesModel(如果我们不使用未来协变量的历史值),或者MixedCovariatesModel(如果我们使用)。我们选择MixedCovariatesModel - TFTModel。
想象一下,我们在过去的冰淇淋销售中看到了一种每周重复的模式。因此,我们设置input_chunk_length = 7天,让模型回顾过去一整个星期。可以将output_chunk_length设置为1天,以预测第二天。
现在我们可以创建一个模型并训练它了!图2向您展示了TFTModel将如何使用我们的数据。
from darts.models import TFTModel
model = TFTModel(input_chunk_length=7, output_chunk_length=1)
model.fit(series=ice_cream_sales,
past_covariates=temperature,
future_covariates=weekday)
当调用fit()时,模型将构建一个适当的darts.utils.data.TrainingDataset,指定如何对数据进行切片以获得训练样本。如果你想自己控制这个切片,你可以实例化你自己的TrainingDataset并调用model.fit_from_dataset()而不是fit()。默认情况下,大多数模型(虽然不是全部)将构建顺序数据集,这基本上意味着所提供的系列中长度为input_chunk_length + output_chunk_length的所有子片将用于训练。
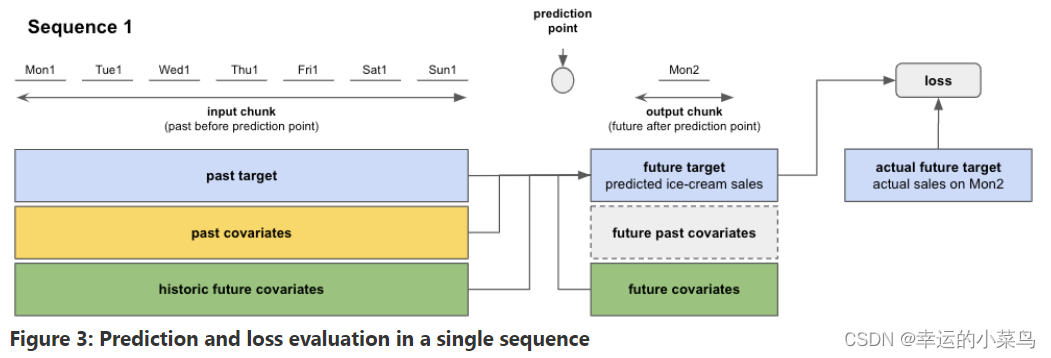
因此,在训练过程中,torch模型将按顺序遍历训练数据(见图3)。使用来自输入块和输出块的信息,模型预测输出块上的未来目标。训练损失在预测的未来目标和输出块上的实际目标值之间进行评估。该模型通过最小化所有序列的损失来进行自我训练。
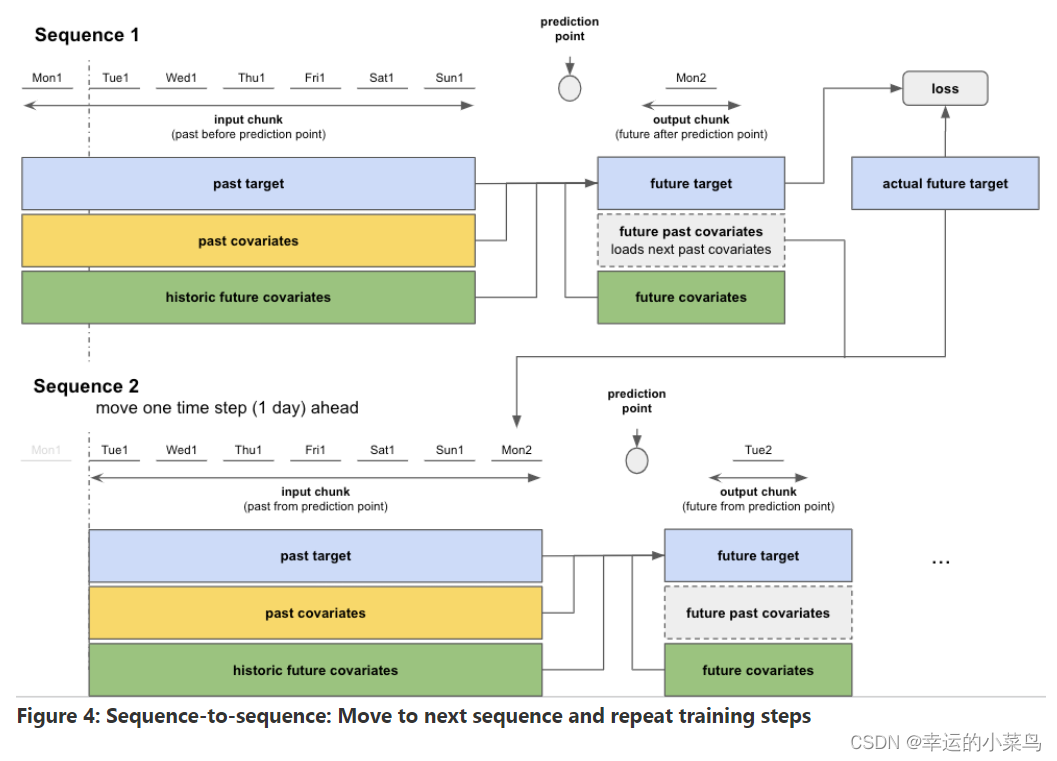
在完成第一个序列的计算后,模型移动到下一个序列并执行相同的训练步骤。每个序列的起点是从顺序数据集中随机选择的。图4显示了如果碰巧第二个序列开始于第一个时间步骤(天)之后,这将是什么样子。
这个顺序到顺序的过程重复,直到完成所有的365天。
附注:拥有“长”的目标系列可能会导致非常多的训练序列/样本。您可以使用fit()参数max_samples_per_ts为每个目标的序列/样本数量设置一个上限,模型应该在该上限上进行训练。这将获取每个目标序列最近的序列(离目标端最近的序列)。
# fit only on the 10 "most recent" sequences
model.fit(target, max_samples_per_ts=10)
带有验证集的训练
你也可以用验证数据集训练你的模型:
# create train and validation sets
ice_cream_sales_train, ice_cream_sales_val = ice_cream_sales.split_after(training_cutoff)
# train with validation set
model.fit(series=ice_cream_sales_train,
past_covariates=temperature,
future_covariates=weekday,
val_series=ice_cream_sales_val,
val_past_covariates=temperature,
val_future_covariates=weekday)
如果分割数据,必须定义一个training_cutoff(分割数据集的日期或分数),以便训练和验证数据集都满足本小节的最小长度要求。
您还可以使用时间序列的另一个子集作为验证集,而不是按时间分割。
该模型以与之前相同的方式训练自己,但还会在验证数据集上评估损失。如果您想跟踪验证集中性能最好的模型,则必须启用检查点保存,如下所示。
存储和加载模型状态
默认情况下,模型不会自动保存任何检查点。如果您想跟踪验证集上性能最好的模型和最近的5个epoch,您必须在模型创建时启用检查点保存。
model = SomeTorchForecastingModel(..., model_name='MyModel', save_checkpoints=True)
# checkpoints are saved automatically
model.fit(...)
# load the model state that performed best on validation set
best_model = model.load_from_checkpoint(model_name='MyModel', best=True)
你也可以手动保存或加载:
model.save_model(model_path)
loaded_model = model.load_model(model_path)
/ !警告/ !在dart开发的这个阶段,我们(还)没有确保向后兼容性,所以可能并不总是能够加载由旧版本库保存的模型。
Forecast/prediction
在训练了模型之后,我们想要在365天的训练数据之后预测未来任意天数的冰淇淋销量。
实际的预测工作与我们训练序列数据的方式非常相似。根据我们想要预测的天数,即预测地平线n,我们区分两种情况:
- 如果n <= output_chunk_length:我们可以一次预测n(使用一次“内部模型调用”)
- 在我们的例子中:预测第二天的冰淇淋销量(n = 1)
- 如果n >output_chunk_length:我们必须通过多次调用内部模型来预测n。每次调用都输出output_chunk_length预测点。我们需要多少调用就进行多少调用,直到我们以一种自回归的方式得到最后的n个预测点
- 在我们的例子中:一次性预测未来3天的冰淇淋销量(n = 3)
为此,我们必须为365天训练数据结束后的下一个n - output_chunk_length = 2个时间步(天)提供额外的past_covariates 。不幸的是,我们没有测量未来的温度。但让我们假设我们有未来两天的气温预报。我们只要把它们加到温度上,预测就会起作用!
temperature = temperature.concatenate(temperature_forecast, axis=0)
性能建议
用32-bits的数据构建时间序列
dart中的模型将动态地转换自己(为64位或32位),以遵循TimeSeries中的d类型。当一切(数据和模型)都使用float32时,通常可以获得较大的性能和内存增益。要实现这一点,从具有dtype np的数组(或数据框架支持数组)构建TimeSeries就足够了。Float32,或者简单地调用my_series32 = my_series.astype(np.float32)。调用my_series。dtype提供TimeSeries的dtype。
Use a GPU
调整批处理大小
更大的批处理大小往往会加快训练速度,因为它减少了每个epoch向后传递的次数,并有可能更好地并行化计算。然而,它也改变了训练动态(例如,你可能需要更多的epoch,收敛动态受到影响)。此外,较大的批处理大小会增加内存消耗。所以这里也需要一些测试。
调整num_loader_workers
dart中的所有深度学习模型在fit()和predict()函数中都有一个参数num_loader_workers,用于在PyTorch DataLoaders中配置num_workers参数。默认情况下,它被设置为0,这意味着主进程也将负责加载数据。设置num_workers > 0将使用其他worker加载数据。这通常会带来一些开销(显著增加内存消耗),但在某些情况下,它还可以显著提高性能。理想的值取决于许多因素,如批处理大小、是否使用GPU、数字o
Small models first
Data in Memory and I/O bottlenecks
Do not use all possible sub-series for training
默认情况下,当调用fit()时,Darts中的模型将构建一个适合您正在使用的模型的TrainingDataset实例(例如,PastCovariatesTorchModel, FutureCovariatesTorchModel等)。默认情况下,这些训练数据集通常会包含每个TimeSeries中所有可能的连续(输入、输出)子序列。如果TimeSeries很长,这将导致大量的训练样本,这将直接(线性)影响一个时期训练模型所需的时间。有两个选项可以限制这一点:为fit()函数指定max_samples_per_ts参数。这将只使用每个TimeSeries最近的max_samples_per_ts样本进行训练。如果这个选项没有达到您想要的效果,您可以实现自己的TrainingDataset实例,并定义如何对TimeSeries进行切片以供您自己进行培训。我们建议看一看这个子模块,看看如何做的例子。
Early Stop
提前停止训练是减少训练时间的有效方法。通过在一组nr_epochs_val_period的验证损失没有改善的情况下停止训练,使用早期停止训练对更少的epoch模型进行训练。
通过利用PyTorch Lightning的earlystop回调,可以很容易地在所有基于模型的dart神经网络上实现提前停止,如下面的示例代码所示。
from darts.models import NBEATSModel
from darts.datasets import AirPassengersDataset
from pytorch_lightning.callbacks import EarlyStopping
from torchmetrics import MeanAbsolutePercentageError
import pandas as pd
from darts.dataprocessing.transformers import Scaler
# Read data:
series = AirPassengersDataset().load()
# Create training and validation sets:
train, val = series.split_after(pd.Timestamp(year=1957, month=12, day=1))
# Normalize the time series (note: we avoid fitting the transformer on the validation set)
transformer = Scaler()
transformer.fit(train)
train = transformer.transform(train)
val = transformer.transform(val)
# A TorchMetric or val_loss can be used as the monitor
torch_metrics = MeanAbsolutePercentageError()
# Early stop callback
my_stopper = EarlyStopping(
monitor="val_MeanAbsolutePercentageError", # "val_loss",
patience=5,
min_delta=0.05,
mode='min',
)
pl_trainer_kwargs = {"callbacks": [my_stopper]}
# Create the model
model = NBEATSModel(
input_chunk_length=24,
output_chunk_length=12,
n_epochs=500,
torch_metrics=torch_metrics,
pl_trainer_kwargs=pl_trainer_kwargs)
model.fit(
series=train,
val_series=val,
)
Hyperparameter Tuning with Ray Tune
超参数调优是为模型找到最佳参数的好方法。Ray Tune提供了一种方便的方式来加速这一过程的自动修剪。
下面是一个如何使用Ray Tune与NBEATSModel模型使用异步Hyperband调度器的例子。
from darts.models import NBEATSModel
from darts.datasets import AirPassengersDataset
from pytorch_lightning.callbacks import EarlyStopping
import pandas as pd
from darts.dataprocessing.transformers import Scaler
from torchmetrics import MetricCollection, MeanAbsolutePercentageError, MeanAbsoluteError
from ray import tune
from ray.tune import CLIReporter
from ray.tune.integration.pytorch_lightning import TuneReportCallback
from ray.tune.schedulers import ASHAScheduler
def train_model(model_args, callbacks, train, val):
torch_metrics = MetricCollection([MeanAbsolutePercentageError(), MeanAbsoluteError()])
# Create the model using model_args from Ray Tune
model = NBEATSModel(
input_chunk_length=24,
output_chunk_length=12,
n_epochs=500,
torch_metrics=torch_metrics,
pl_trainer_kwargs={"callbacks": callbacks, "enable_progress_bar": False},
**model_args)
model.fit(
series=train,
val_series=val,
)
# Read data:
series = AirPassengersDataset().load()
# Create training and validation sets:
train, val = series.split_after(pd.Timestamp(year=1957, month=12, day=1))
# Normalize the time series (note: we avoid fitting the transformer on the validation set)
transformer = Scaler()
transformer.fit(train)
train = transformer.transform(train)
val = transformer.transform(val)
# Early stop callback
my_stopper = EarlyStopping(
monitor="val_MeanAbsolutePercentageError",
patience=5,
min_delta=0.05,
mode='min',
)
# set up ray tune callback
tune_callback = TuneReportCallback(
{
"loss": "val_Loss",
"MAPE": "val_MeanAbsolutePercentageError",
},
on="validation_end",
)
# define the hyperparameter space
config = {
"batch_size": tune.choice([16, 32, 64, 128]),
"num_blocks": tune.choice([1, 2, 3, 4, 5]),
"num_stacks": tune.choice([32, 64, 128]),
"dropout": tune.uniform(0, 0.2),
}
reporter = CLIReporter(
parameter_columns=list(config.keys()),
metric_columns=["loss", "MAPE", "training_iteration"],
)
resources_per_trial = {"cpu": 8, "gpu": 1}
# the number of combinations to try
num_samples = 10
scheduler = ASHAScheduler(max_t=1000, grace_period=3, reduction_factor=2)
train_fn_with_parameters = tune.with_parameters(
train_model, callbacks=[my_stopper, tune_callback], train=train, val=val,
)
analysis = tune.run(
train_fn_with_parameters,
resources_per_trial=resources_per_trial,
# Using a metric instead of loss allows for
# comparison between different likelihood or loss functions.
metric="MAPE", # any value in TuneReportCallback.
mode="min",
config=config,
num_samples=num_samples,
scheduler=scheduler,
progress_reporter=reporter,
name="tune_darts",
)
print("Best hyperparameters found were: ", analysis.best_config)
作为一个例子,我们在这里展示了在能量数据集(das .datasets. energydataset)的前80%上训练一个epoch所需的时间,该数据集包含一个多变量序列,它有28050个时间步长,有28个维度。我们训练了两个模型;NBEATSModel和TFTModel,具有默认参数,input_chunk_length=48和output_chunk_length=12(这将产生27991个带有默认顺序训练数据集的训练样本)。对于TFT模型,我们还设置了参数add_cyclic_encoder=‘hour’。测试在Intel CPU i9-10900K CPU @ 3.70GHz, Nvidia RTX 2080 GPU, 32gb RAM上进行。所有TimeSeries都预加载在内存中,并作为列表提供给模型。














 3753
3753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









