






声音的产生
声音是由于物体振动而产生的。当物体振动时,会产生扰动空气分子,空气分子会相互碰撞,形成波纹。这些波纹传播到人耳,被人耳接收,从而产生了听觉。
声音的三要素
声音的三要素是音调、响度和音色。
- 音调:音调是声音最基本的特征之一,它表示声音的音高。音调高低可以用频率来表示。频率是表示声音在单位时间内振动次数的物理量,单位为赫兹(Hz)。人耳可以听到的声音的频率范围为 20Hz 到 20kHz。频率越高,音调越高;频率越低,音调越低。
- 响度:响度是声音的另一个基本特征,它表示声音的强弱,表示声音在单位时间内传递的能量的物理量。响度越大,声音越强;响度越小,声音越弱。
- 音色:音色表示声音的质感。音色是由声音的频谱成分决定的。不同的声音具有不同的频谱成分,因此具有不同的音色。
常用音频属性
- 采样率:每秒钟采样的次数,以赫兹(Hz)为单位。决定了音频能够表示的最高频率,采样率越高,音质越好,但文件大小也越大。
- 位深度:表示每个样本的位数。决定了音频的动态范围和信噪比,位深度越高,音质越细腻。
- 声道数:单声道、立体声、多声道。多声道提供更丰富的听觉体验和空间感,但增加了文件大小。
- 文件格式:WAV, MP3, AAC, FLAC等。不同格式影响音质、压缩率和兼容性。
- 比特率:单位时间内传输的数据量,通常以kbps(千比特每秒)为单位。决定了压缩音频的质量,比特率越高,音质越好,但文件大小也越大。
- 动态范围:音频中最大和最小振幅之间的差距。较宽的动态范围可以提供更丰富的音乐细节。
- 频响范围:音频设备或文件可以重现的频率范围。决定了音频能够表现的最低和最高频率。
- 压缩类型:有损(如MP3, AAC)和无损(如FLAC, WAV)。有损压缩减小文件大小但可能损失部分音质,无损压缩保持原始音质。
- 编码格式义:用于编码或解码数字音频的程序或设备。不同的编码格式可能影响音质和文件的兼容性。
音频到文件
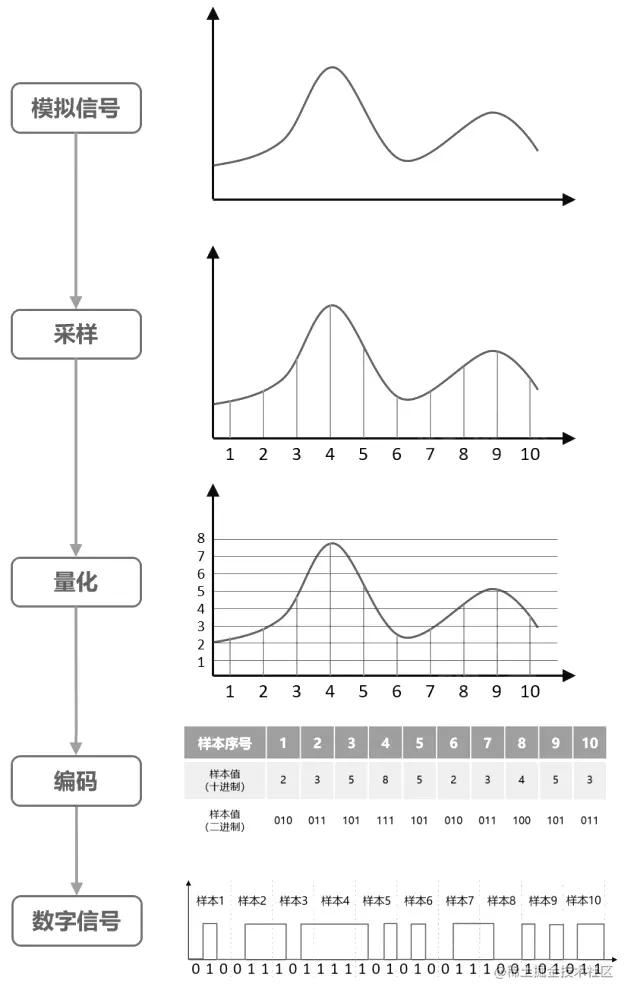
我们听到的声音都是模拟信号,如果使用计算机处理和保存声音我们需要把声音转换为音频文件,这个转换需要经过以下几个步骤:
- 采样(模拟信号 → 离散信号):模拟信号在时间上是连续的,为了便于计算机处理,将模拟信号在一定时间间隔内进行取样,得到一组离散的数值,即离散信号。采样频率是采样过程中的一个重要参数,它决定了音频文件的保真度。采样频率越高,音频文件的保真度越高,但文件的大小也会越大。根据奈奎斯特采样定理,采样频率必须大于等于信号的最高频率的两倍,才能完全还原信号。因此,对于人耳可以听到的声音(20Hz-20kHz),采样频率通常为 44.1kHz 或 48kHz。
- 量化(离散信号 → 数字信号):模拟信号是在声音的时间上离散化,量化则是将声音的幅度离散化。量化将采样得到的数值进行量化,即将其转换为有限个离散的值。量化精度是量化过程中的一个重要参数,它决定了音频文件的音质。量化精度通常用位数表示,例如 16 位量化,表示量化精度为 16 位。16 位量化可以表示 65536 个不同的值。
- 编码(数字信号 → 音频文件):将量化后的数值进行编码,以便存储和传输。编码方式有很多种,通常为 PCM 编码。PCM 编码是将量化后的数值直接存储,称为音频的裸数据格式,具有较好的保真度,但文件的大小也较大。
例如,计算一分钟的 CD 音质数据所需的存储空间,CD 的标准音频格式是:
- 采样率:44.1 kHz
- 位深度:16 位
- 声道数:2(立体声,即左右两个声道,可以视为记录几个声音信号)
基于这些参数,我们可以计算一分钟 CD 音质音频大约需要 10.09MB 的存储空间。具体计算方法如下:
-
首先,计算每秒钟的数据量:
每秒数据量(字节)=采样率 × 位深度 × 声道数/8 -
然后,将每秒的数据量乘以 60,得到每分钟的数据量:
每分钟数据量_MB = 每秒数据量 * 60 / 1024 / 1024
文件到音频
音频文件播放的过程通常使用数模转换器(DAC)来完成。DAC 将数字信号转换为连续的音频信号,其工作原理如下:
- 首先,DAC 将数字信号进行解码,也就是将数字信号转换为模拟信号。
- 转换后的模拟音频信号可能很微弱,需要通过功放等设备进行放大。
- 最后,DAC 将放大后的模拟信号输出到扬声器或耳机,与扬声器或耳机的振膜振动产生声音。
音频编解码
音频编码的主要目的是减少音频文件的大小,同时尽量保持原始音质。这通常通过去除人耳无法察觉的信息以及压缩那些对音质影响较小的信息来实现。音频压缩可以分为无损压缩和有损压缩两种类型。
无损压缩
无损音频压缩可以在不失去任何原始数据的情况下减少文件大小。这意味着无损压缩后的文件可以完全还原成与原始音频文件完全一样的数据。无损压缩主要依赖两种技术来减少文件大小:
-
预测编码:
- 这种方法基于预测接下来的音频样本的值。通过比较实际样本值和预测值之间的差异,只需记录这些较小的差异值,而不是记录每个样本的完整值。
- 预测可以基于前一个或几个样本进行,或使用更复杂的算法来提高预测的准确性。
-
熵编码:
- 熵编码是一种统计编码技术,它通过分析音频数据中的各种元素出现的频率来进行压缩。
- 最常见的熵编码方法之一是霍夫曼编码。在这种方法中,最常出现的元素(如某个特定的差异值)会被分配更短的编码,而不常出现的元素则分配更长的编码。
常用的的无损音频压缩格式包括 FLAC、APE、ALAC,可以将音频文件的大小压缩到原来的 50% 左右,而音质几乎不会下降。
有损压缩
有损音频压缩是一种通过牺牲部分音频信息来减少文件大小的技术。这种压缩通常非常高效,能够显著减少文件大小,而人耳通常无法察觉到这种质量的损失。有损压缩通过去除一些对人类听觉不太重要的音频信息来减小文件大小,常用的技术包括:
-
掩蔽效应:
-
频率掩蔽
- 同时掩蔽:在同一时间,一个强烈的声音可以掩盖掉与它频率相近的较弱声音。
- 临界带宽:人耳对于频率的敏感度是有限的,临界带宽内的声音被视为一个整体。如果一个频带内的声音足够响,它可以掩蔽该带宽内的其他声音。
-
时间掩蔽:时间掩蔽是指一个响亮的声音可以在时间上遮蔽掉其前后的较弱声音。
- 前向掩蔽:发生在响亮声音之前的短暂时刻。前向掩蔽的效果较弱,,可以在响亮声音出现前的几毫秒内遮蔽掉较弱的声音。
- 后向掩蔽:发生在响亮声音之后。这种掩蔽作用更强,可以持续一段时间(通常是响亮声音结束后的几十毫秒到几百毫秒)。
-
-
数据削减:
- 去除那些人耳无法听到或者不太可能注意到的声音,比如过高或过低的频率。
- 去除冗余信息,例如,在立体声音频中,如果两个声道非常相似,可以只存储一个声道并稍作修改来表示另一个声道。
-
采样、量化和编码:
- 降低音频信号的采样率、量化位数。
有损压缩格式能在可接受的音质损失范围内显著减少文件大小,使音频存储和传输变得更加高效,常用于存储日常使用的音频文件,常见如 MP3、AAC、OggVorbis 等。
常用的音频格式
-
编解码技术:心理声学模型、哈夫曼编码、分层压缩,支持不同的比特率。
应用场景:MP3的压缩比一般可以达到1:10或1:12,由于文件小,适合网络传输和个人便携设备,被广泛用于音乐下载、流媒体服务。 -
WAV(Waveform Audio File Format)
编解码技术:无损格式,提供未压缩的音频数据,保留原始音质。
应用场景:作为早期的数字音频标准,被广泛支持。专业音频编辑和处理。高保真音乐和音效存储。 -
编解码技术:AAC支持多达48个音轨、15个低频音轨、更多种采样率和比特率高压缩比1:18。使用了时域噪声整形、长时期预测的预测编码,利用Spectral Band Replication和Parametric Stereo等技术减少比特率,提高效率。
应用场景:相比MP3提供更好的音质,尤其在较低比特率下,被认为是MP3的继任者。 -
FLAC (Free Lossless Audio Codec)
编解码技术:开源的无损压缩技术,可以将音频数据压缩到原始大小的50%到70%。支持元数据标签、数据完整性验证和错误检测、快速解码。FLAC帧之间独立解码,实现流媒体支持。
应用场景:开源无损,在音乐爱好者和专业音频领域中非常受欢迎。它是保存和传输高质量音频的理想选择,特别是在对音质有高要求的场合。 -
编解码技术:开源的有损压缩技术。使用可变比特率编码,根据音频内容的复杂性动态调整比特率,在文件大小和音质之间实现最佳平衡。支持从单声道到5.1环绕声等多种声道配置。较低的编码和解码延迟,这对于实时应用如游戏音效和在线通信非常重要。
应用场景:高效、灵活且无版权限制,应用各种从流媒体和游戏音效。 -
ALAC (Apple Lossless Audio Codec)
编解码技术:苹果公司开发的无损压缩技术,能够压缩到原始音频数据的大约一半,已开源。ALAC的设计重点在于高效的编码和解码,使用线性预测和自适应运行长度编码等技术。
应用场景:为苹果设备设计,但开源后的ALAC现在也被多种非苹果软件和硬件支持。
音频信号分析和处理
Librosa 是 Python 比较著名的音频处理库,内置了许多基本的音频分析处理功能,我们使用这个库做一些实验:
-
基本音频属性
Sample WAV audio files可以在这里找到一些示例的 WAV 文件
import librosa import librosa.display import wave import matplotlib.pyplot as plt import numpy as np import os # 加载音频文件 file_path = "sample-12s.wav" audio, sample_rate = librosa.load(file_path, sr=None) # 提取基本参数 with wave.open(file_path, "rb") as wav_file: n_channels = wav_file.getnchannels() # 声道数 sample_width = wav_file.getsampwidth() # 采样位深度 framerate = wav_file.getframerate() # 采样率 n_frames = wav_file.getnframes() # 音频帧数 comp_type = wav_file.getcomptype() # 压缩类型 comp_name = wav_file.getcompname() # 压缩名 bit_depth = sample_width * 8 # 计算位深度 file_size = os.path.getsize(file_path) # 计算文件大小 duration = n_frames / float(framerate) # 计算音频长度 print(f"声道数: {n_channels}") print(f"采样率: {framerate} Hz") print(f"位深度: {bit_depth} bits") print(f"压缩类型: {comp_type} ({comp_name})") print(f"文件大小: {file_size} bytes") print(f"音频长度: {duration:.2f} seconds")声道数: 2 采样率: 44100 Hz 位深度: 16 bits 压缩类型: NONE (not compressed) 文件大小: 2254892 bytes 音频长度: 12.78 seconds -
音频的时域波形图和频谱分析
输出了音频的时域波形以及它的频谱分析图。波形图表示归一化的音频振幅,而频谱分析主要基于窗口化和快速傅里叶变换(FFT)的概念,能够展示在特定时间和频率上的信号强度。
plt.figure(figsize=(12, 4)) # 波形图 plt.subplot(2, 1, 1) librosa.display.waveshow(audio, sr=sample_rate) plt.title('Waveform') plt.xlabel('Time (s)') plt.ylabel('Amplitude') # 频谱分析 plt.subplot(2, 1, 2) D = librosa.amplitude_to_db(np.abs(librosa.stft(audio)), ref=np.max) librosa.display.specshow(D, sr=sample_rate, x_axis='time', y_axis='log') plt.colorbar(format='%+2.0f dB') plt.title('Spectrogram') plt.tight_layout() plt.show()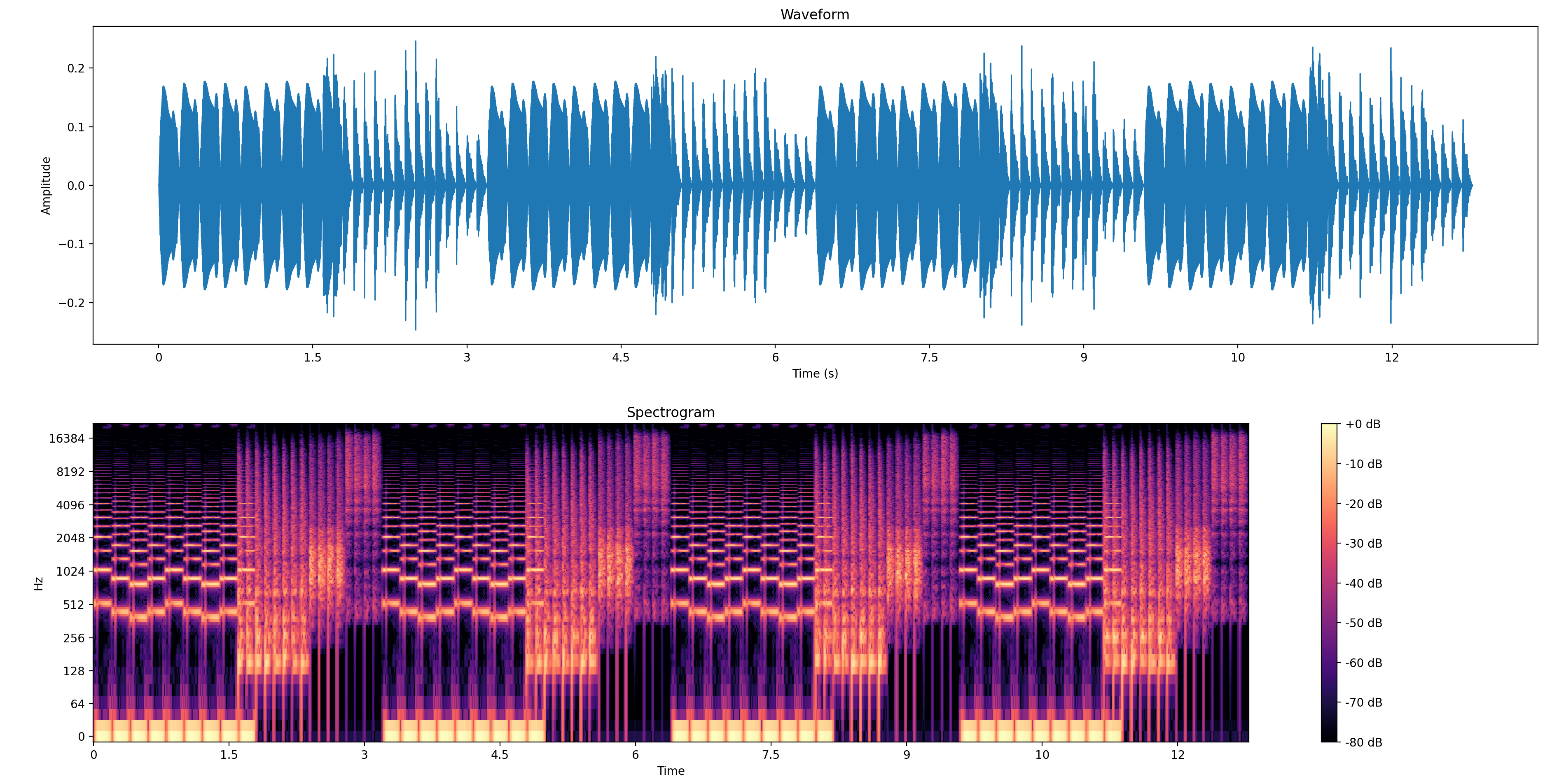
-
梅尔频率倒谱系数(MFCC)
MFCC 的计算涉及多个步骤,包括分帧加窗、FFT、梅尔滤波、取对数、DCT 等等,最后输出特征向量(语音信号的梅尔频率倒谱系数(MFCC)的原理讲解及 python 实现,语音信号处理之(四)梅尔频率倒谱系数(MFCC))
MFCCs 是音频信号的短时功率谱在梅尔刻度(一种基于人耳感知的频率刻度)上的对数倒谱,能很好地表示声音的基本结构,常用于语音识别和分类时的特征表示
mfccs = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=13) plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, sr=sr, x_axis='time') plt.colorbar() plt.title('MFCC') plt.tight_layout()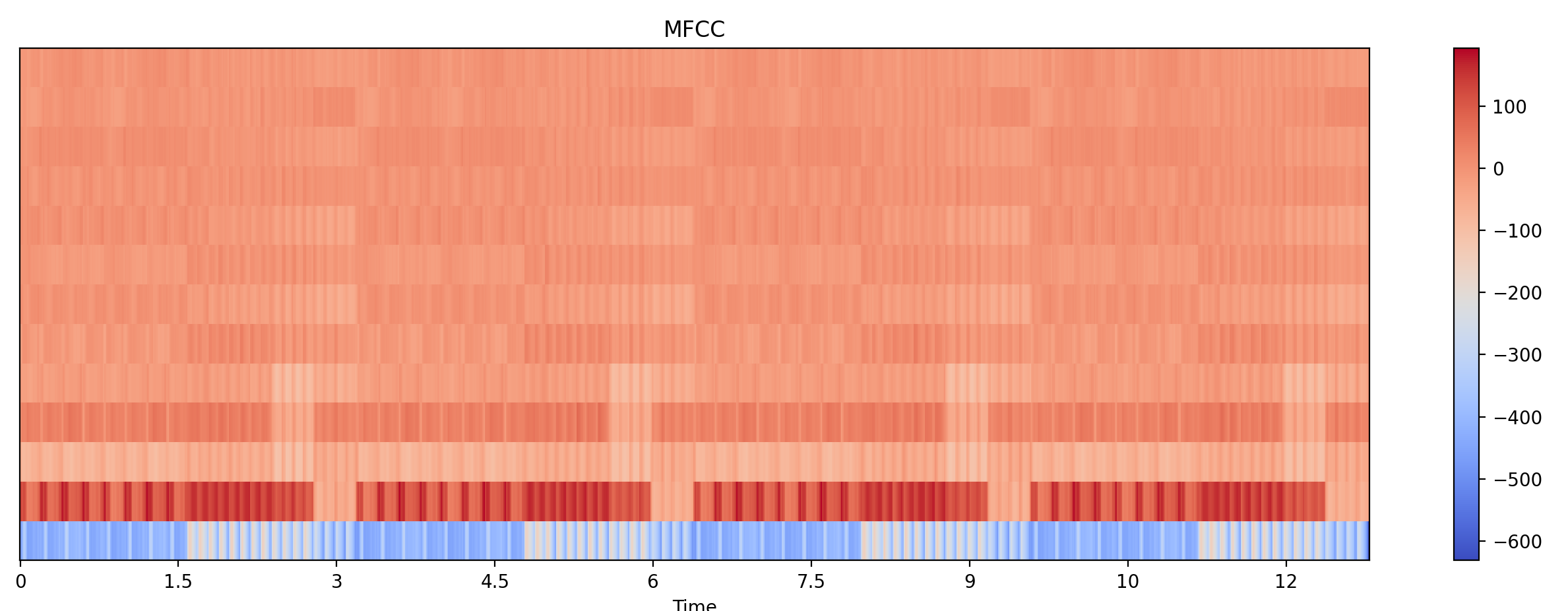
-
频谱质心(Spectral Centroid)
频谱质心是频谱功率分布的加权平均频率。
频谱质心是描述声音音色特征的关键参数之一,频谱质心越高,声音通常听起来越“亮”或“尖锐”。在音乐中,频谱质心可以用来区分不同乐器的声音,或者不同演奏风格。spectral_centroids = librosa.feature.spectral_centroid(y=audio, sr=sr)[0] plt.figure(figsize=(10, 4)) plt.semilogy(spectral_centroids.T, label='Spectral Centroid') plt.ylabel('Hz') plt.xticks([]) plt.xlim([0, spectral_centroids.shape[-1]]) plt.legend(loc='upper right') plt.title('Spectral Centroid') plt.tight_layout()
-
音色(Chroma)
音色特征是将音频信号转换为频谱表示,然后将频谱数据映射到 12 个半音上,通常使用一组滤波器或变换方法来实现。最后,将映射结果归一化,并对每个半音的能量进行汇总,形成音色特征向量。
音色反映了音乐中 12 个不同的半音(即一个八度内的所有音符)的强度和存在性,在音乐的分析分类中用的比较多。
chroma = librosa.feature.chroma_stft(y=audio, sr=sr) plt.figure(figsize=(10, 4)) librosa.display.specshow(chroma, y_axis='chroma', x_axis='time') plt.colorbar() plt.title('Chroma') plt.tight_layout()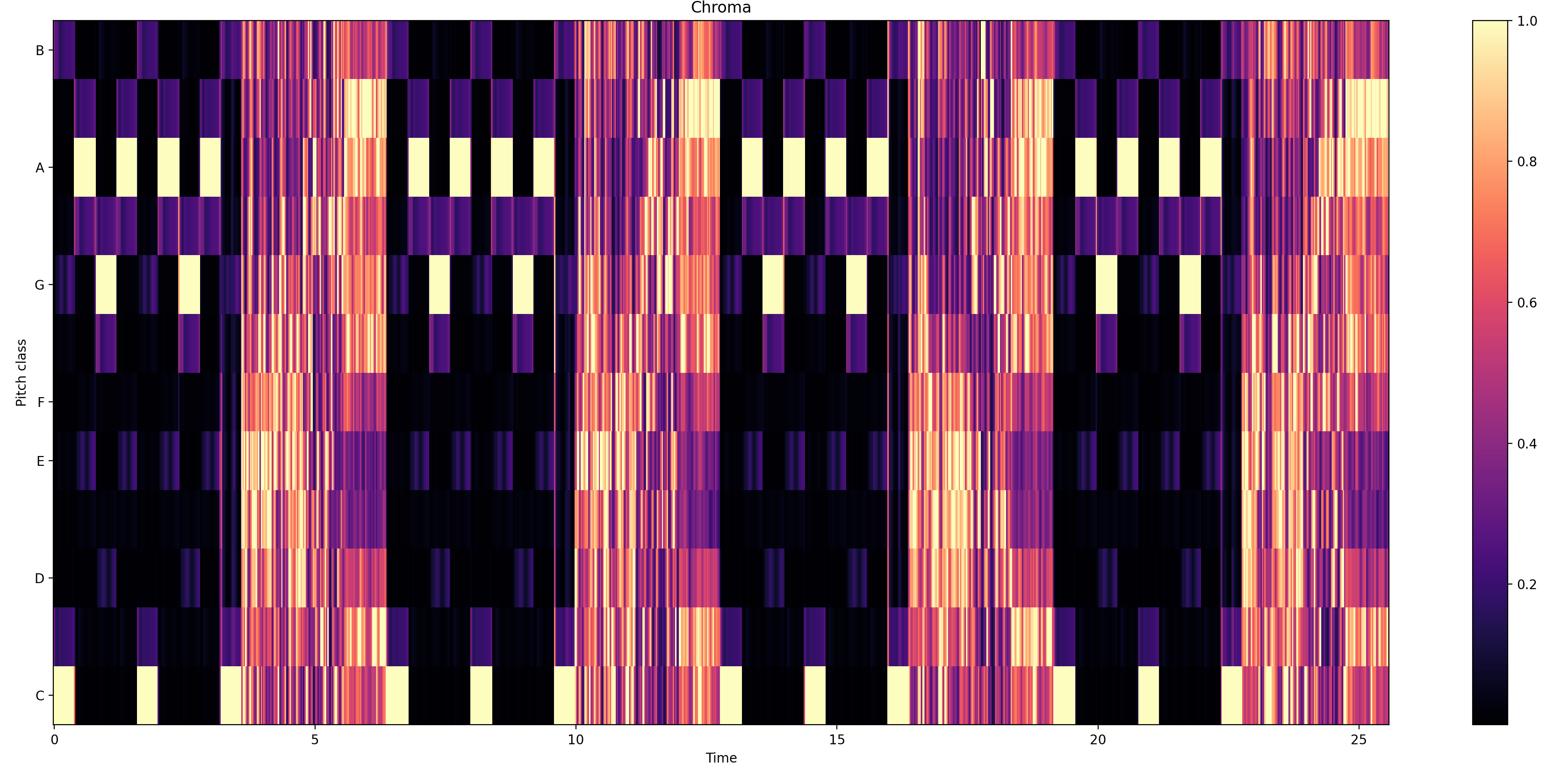
-
过零率(Zero Crossing Rate)
过零率指的是在一定时间范围内,音频信号波形穿过零点的次数。
高过零率通常与节奏快、音调变化频繁的音频相关,而低过零率则可能表示节奏较慢、音调变化较少的音频。可以用于区分音乐和语音的不同类型(如噪音、静音、语音),或不同的节奏风格。
zero_crossing_rate = librosa.feature.zero_crossing_rate(audio)[0] plt.figure(figsize=(10, 4)) plt.plot(zero_crossing_rate.T, label='Zero Crossing Rate') plt.xticks([]) plt.xlim([0, zero_crossing_rate.shape[-1]]) plt.legend(loc='upper right') plt.title('Zero Crossing Rate') plt.tight_layout()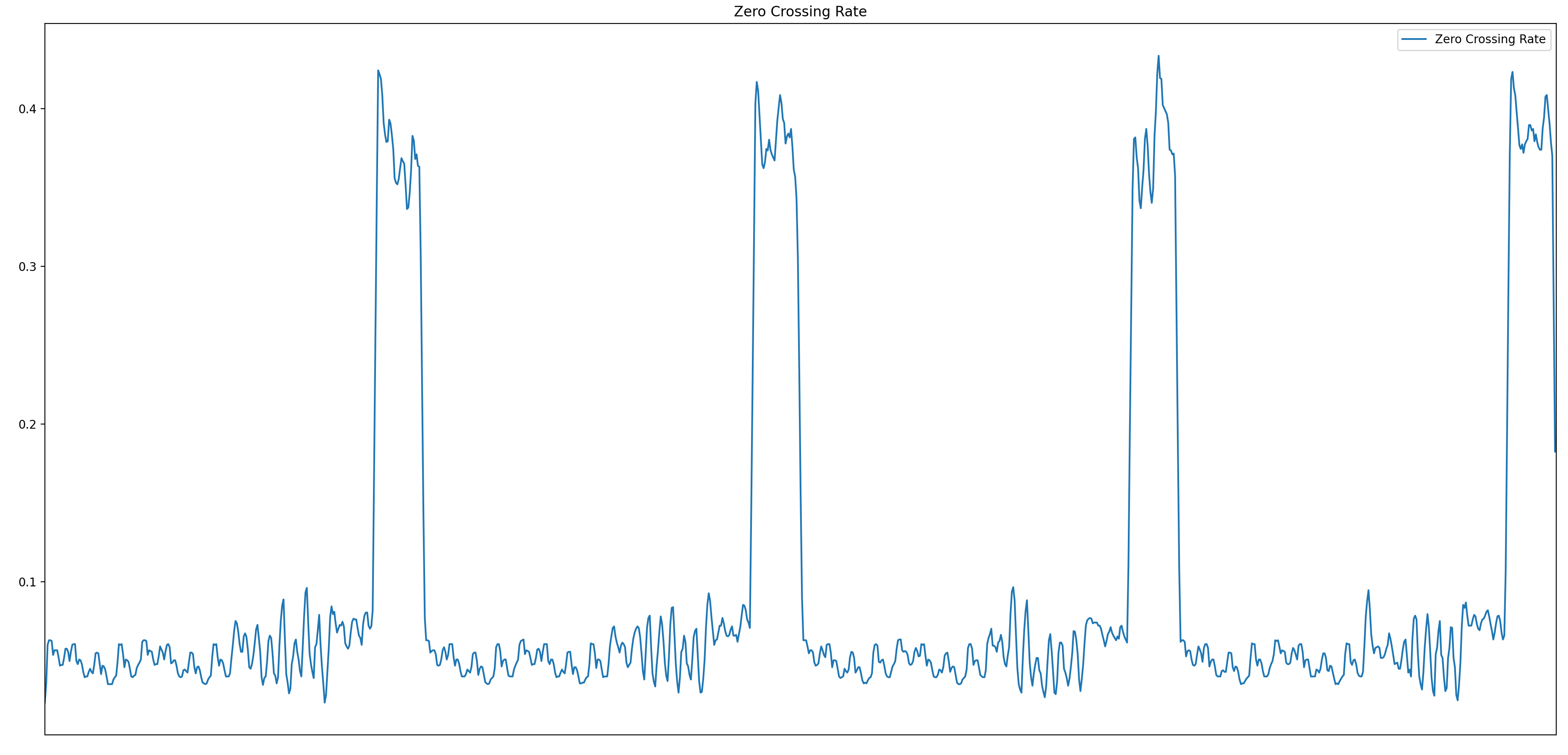
总结
音频涉及到的知识比较多,在音频分析和各种音频编解码格式中,信号处理相关知识用的很多,包括数字信号处理、傅里叶分析等等。如果要深入研究的话,感觉要把本科学过的在看一遍。。包括一些语音信号处理的书籍















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









