







1. 研究目的
本模型主要针对自回归(AR)和扩散模型存在的缺点提出的:
- 需要大量的训练数据和参数来实现良好的性能,庞大的数据和模型规模带来了极高的计算预算和硬件要求
- 多步生成设计(逐词生成和渐进降噪需要数百个推理步骤),大大减慢了图像合成的过程
- 没有像GAN那样直观的平滑潜在空间,它将有意义的视觉属性映射到潜在向量。多步生成设计打破了合成过程,分散了有意义的潜在空间。它使得合成过程需要精心设计的提示来控制(合成的视觉特征对控制具有挑战性,并且需要精心设计的提示)
- 自回归模型具有缓慢生成缺陷
2. 模型结构
模型结构图:
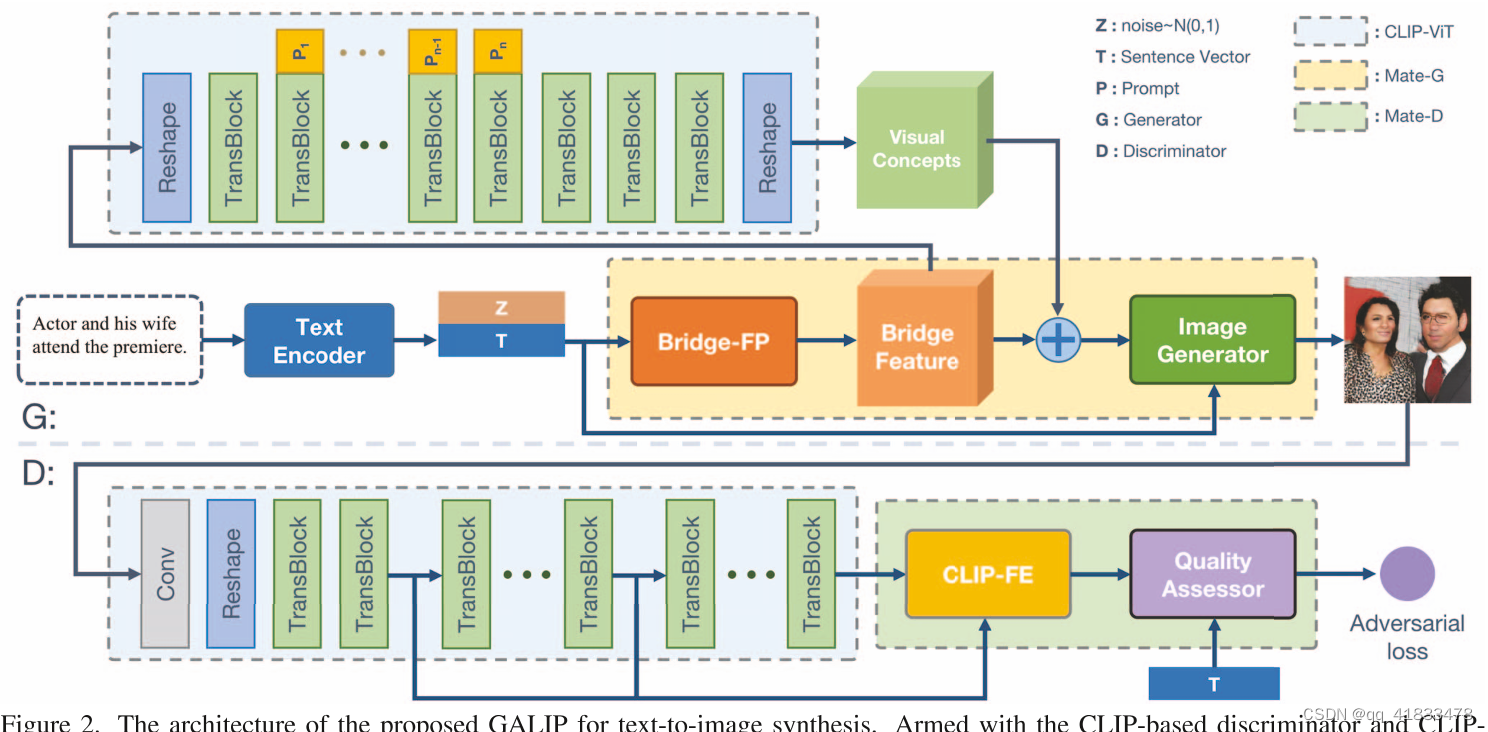
GALIP 由三部分组成: CLIP 文本编码器、基于 CLIP 的鉴别器、 CLIP 增强生成器
2.1 文本编码器
预训练的 CLIP 文本编码器采用文本描述并产生全局句子向量 T。在文本编码器是 GAN 框架下的 CLIP 增强的生成器和基于 CLIP 的鉴别器之后。
2.2 CLIP增强的生成器
CLIP增强的的生成器包括 一个冻结的CLIP-ViT 和一个可学习的匹配生成器Mate-G
- Mate-G 有三个主要模块,桥特征预测器(Bridge-FP)、提示预测器PP(在这个图中没有体现出来,下幅图会出现)和图像生成器。
- CLIP 增强的生成器有两个输入,从文本编码器编码的句子向量 T 和从高斯分布采样的噪声向量 Z。噪声向量保证了合成图像的多样性。
- 在 CLIP 增强的的生成器中,句子向量和噪声首先被馈送到桥特征预测器Bridge-FP中。桥梁特征预测器将句子向量和噪声转换为 CLIP-ViT 的桥梁特征。此外,我们在CLIP-ViT中为变压器块(TransBlock)添加了几个文本条件提示,用于任务适应。
- 最后,图像生成器利用预测的视觉概念、桥梁特征、句子和噪声向量来合成高质量的图像。
2.3 基于CLIP的鉴别器
基于clip的鉴别器包括一个冻结的CLIPViT和一个可学习的Mate-D
- CLIP-ViT通过卷积层和一系列变压器块将图像转换为图像特征。
- Mate-D中的CLIP特征提取器(CLIP-FE)从CLIP-ViT中的不同层收集图像特征。
- 然后它进一步从收集的CLIP特征中提取信息丰富的视觉特征,用于质量评估器。
- 最后,根据提取的信息特征和句子向量的质量评估器将预测对抗性损失。通过将合成图像与真实图像区分开来,鉴别器促进生成器合成更高质量的图像。
3. CLIP增强的生成器更具体的结构
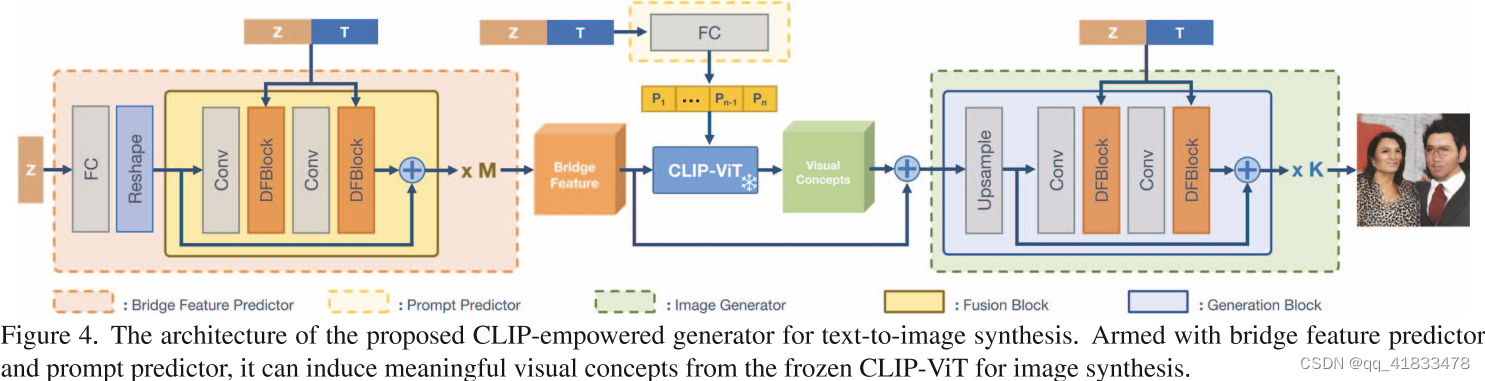
CLIP增强的的生成器包括 一个冻结的CLIP-ViT 和一个可学习的匹配生成器Mate-G3.1
3.1 桥特征预测器的内容
- 桥特征预测器,用红色虚线框突出显示。
- Bridge-FP 由 FC(Fully-Connected)层和 M 个融合块(F-BLK)组成。输入噪声被送入 FC 层并重塑为 (7, 7, 64) 作为初始桥特征。FC层输出的初始桥特征仍然包含大量噪声。因此,我们应用一系列 F-BLK来融合文本信息并使其更有意义。
- F-BLK由两个卷积层(Conv)和两个深度文本图像融合块(DFBlock)组成。DFBlock通过堆叠的仿射变换在融合文本和图像特征方面的有效性。因此,我们采用它来融合文本特征和中间桥特征。
- F-BLK 中有一个快捷方式(就是图中 “+” 键)添加,用于有效的信息传播和梯度反向传播。
- 通过Bridge-FP,句子和噪声向量将被翻译成桥特征,该特征被调整以从CLIP-ViT中诱导有意义的视觉概念。
3.2 提示预测器的内容
上幅图中没有体现出来的提示预测器PP,这幅图有画出
- CLIP-ViT 被预训练以从图像数据预测视觉特征。文本和图像数据之间存在很大差距。为了减轻从文本特征中桥接特征翻译的困难,我们采用了提示调优,它在ViT的域转移方面表现出了有效性。
- 我们设计了一个提示预测器,它通过 FC 层根据句子和噪声向量预测提示。在CLIP-ViT中,预测的文本条件提示被附加到视觉补丁嵌入后面。此外,我们发现最好不要在CLIP-ViT的最后几层中添加提示,最后几层总结了视觉特征并输出最后几层的图像表现。因为从最后几层的文本和噪声预测的提示可能会缺陷其性能。
3.3 图像生成器的组成内容
- 图像生成器由K个生成器块(G-BLKs)组成。我们通过快捷加法对预测的视觉概念和桥接特征求和,以实现有效的信息传播和梯度反向传播。
- 图像生成器接收总和的视觉特征作为输入,并通过每个 G-BLK 中的 DFBlocks融合句子和噪声向量。
- 上采样层在生成过程中,中间图像特征变得更大。最后,将图像特征转换为高分辨率RGB图像。
4. mate-D具体结构
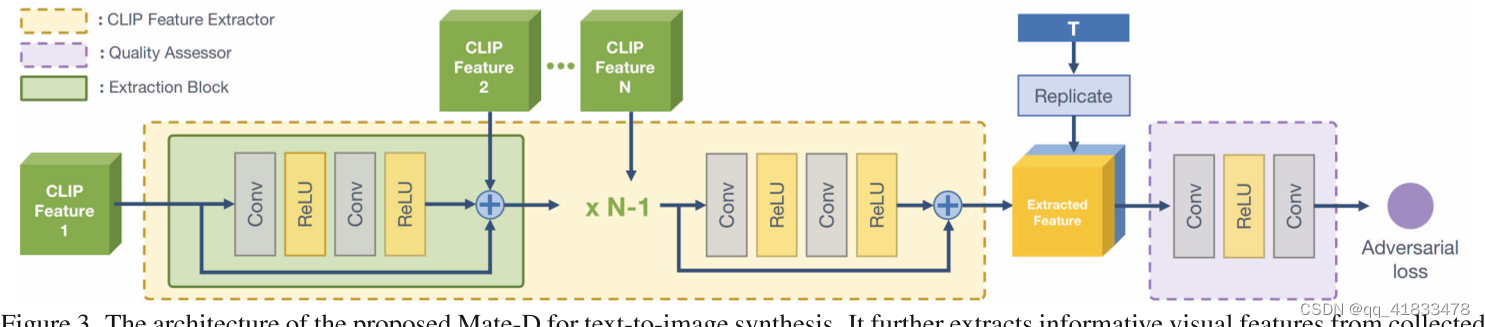
Mate-D 由 CLIP-FE 和质量评估器组成。
- 为了充分利用CLIP-ViT中复杂场景理解的知识,CLIP-FE从多层获取CLIP图像特征。CLIP-FE 收集了 N 个 CLIP 特征。我们将它们命名为 CLIP Feature 1 到 N ,它们是从 CLIP-ViT 中的浅层到深层收集的。
- 为了进一步从这些 CLIP 特征中提取信息丰富的视觉特征,我们设计了一个 CLIP-FE。它包含一系列提取块,每个块包含两个卷积层和两个 ReLU 活动函数。
- 将提取的图像特征与快捷方式和下一个CLIP特征相加。CLIP-FE 中堆叠有 N-1 个提取块。由于CLIP特征N只添加到最后一个提取块中的处理后的图像特征中。为了融合 CLIP 特征 N,我们在后面附加了两个没有 CLIP 特征添加的卷积层。
- CLIP-FE 为质量评估器提取信息丰富的视觉特征。然后复制句子向量并与提取的图像特征连接。两个卷积层预测对抗性损失以评估图像质量。
- 此外,为了稳定 Mate-D 的对抗性学习过程,我们将匹配感知梯度惩罚 (MAGP) 应用于收集的 CLIP 特征和相应的文本特征。
- 基于CLIP-ViT复杂的场景理解能力,基于clip的鉴别器可以从复杂图像中提取更多信息的视觉特征。
- 更高质量的提取视觉特征使鉴别器更容易检测非真实图像部分,提高了判别效率,从而促使生成器生成更真实的图像
5. 定量评估
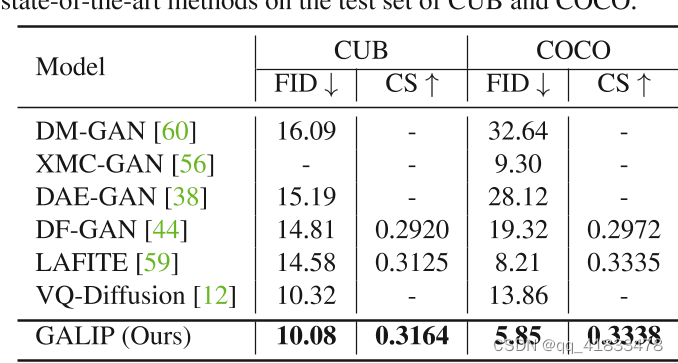
该表是GALIP和目前最流行的模型在CUB数据集和COCO数据集上进行测试,并通过FID和CS评估指标进行对比。
可以看到无论是COCO还是CUB,GALIP的FID和CS指标都是优于其他模型的。
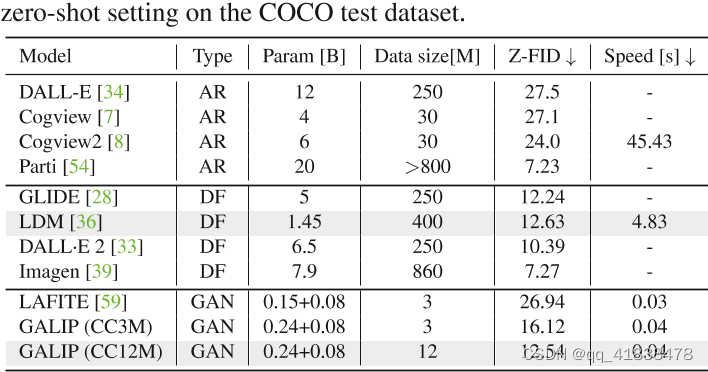
该表是在COCO测试集的零样本设置下进行大型预训练模型和GALIP进行比较
GALIP和LAFITE相比,FID下降了
GALIP和LDM相比,在GALIP的参数和数据都比较小的情况下,GALIP的速度比LDM快了近120倍
6. GALIP的优点
•更高质量的复杂图像生成: GALIP通过将预训练的CLIP模型整合到生成对抗网络(GAN)中,实现了更高质量的复杂图像生成。
•复杂场景理解能力:GALIP继承了CLIP模型的复杂场景理解能力,能够从复杂图像中提取有意义的视觉特征,从而提高图像质量。
•域泛化能力:GALIP利用CLIP模型的域泛化能力,可以将不同类型的图像映射到共享概念,实现卓越的域泛化和零样本迁移能力。
•平滑的潜在空间:与现有的大型预训练自回归和扩散模型相比,GALIP具有更平滑的潜在空间,使生成过程更具可控性。
•更快的生成速度:GALIP的生成速度比现有的大型预训练自回归和扩散模型快得多,仅需要0.04s即可生成一张图像,比LDM快约120倍。
•较低的硬件和计算成本:GALIP在CPU上快速推理,无需其他加速设置。此外,GALIP的预训练成本远低于大型自回归和扩散模型。
7. 缺点
缺点:模型大小和预训练数据集相对较小,可能限制了生成想象图像的能力
解决方法:扩大模型大小和训练数据可以提高图像质量

看上图,第一张图的柯基的头没有生成出来;第二张图不是狮子老师;第三张图并不是寿司做的房子;第四张图机器人骑着马并没有生成出来;所以由于数据集和模型太小对想象图像的生成并不好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









