






目录
2.其他需要访问共享文件夹的ubuntu将本地文件连接到smb共享文件夹
一、ubuntu配置
1.主节点创建共享文件夹
(1)检查环境及更新
su root
apt-get updata
apt-get upgrade(2)安装Samba
sudo apt-get install samba
(3)在/home目录下创建共享文件夹,名为share。修改share目录的读写权限
mkdir /home/share
sudo chmod 777 /home/share(4)在目录/etc/samba下,在smb.conf文件底部添加如下代码。[share]为自定义共享名称
[share]
path=/home/share
available=yes
browseable=yes
public=yes
writable=yes
guest-ok=yes(5)重启samba服务
service smba restart(6)测试是否创建成功
在windows系统中使用win+R,在弹出窗口输入\\192.168.0.0(这里为共享文件夹主机的ip)
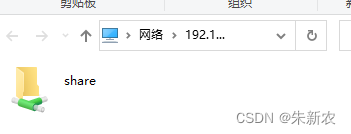
2.其他需要访问共享文件夹的ubuntu将本地文件连接到smb共享文件夹
(1)安装cifs工具
sudo apt install cifs-utils(2)挂载samba硬盘
sudo mount.cifs <//SAMBA-IP/SHARE_PATH> <本地路径> -o user=username,pass=password,rw,file_mode=0777,dir_mode=0777例如:
sudo mount.cifs //目标ip/share /home/hadoop/jq_zhu/ -o user=hadoop,pass=123qwe,rw,file_mode=0777,dir_mode=0777
二、代码实现
# coding:utf-8
import torch
import torchvision
import torch.utils.data.distributed
from torchvision import transforms
import argparse
import os
import torch.distributed as dist
from torch.multiprocessing import Process
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=0, type=int)
parser.add_argument("--world_size", default=2, type=int)
args = parser.parse_args()
def main(rank, world_size):
print('start ...... ')
dist.init_process_group("gloo", init_method='tcp://192.168.***.***:12357', rank=rank, world_size=world_size)
# 数据加载部分,直接利用torchvision中的datasets
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256, sampler=train_sampler)
# 网络搭建,调用torchvision中的resnet
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv1d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = torch.nn.parallel.DistributedDataParallel(net)
# 定义loss与opt
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
# 网络训练
for epoch in range(10):
for i, data in enumerate(data_loader_train):
images, labels = data
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
print("start training .... ")
if i % 10 == 0:
print("loss: {}".format(loss.item()))
if __name__ == "__main__":
main(args.local_rank, args.world_size1.进程初始化
初始化进程组函数:
def init_process_group(backend,
init_method=None,
timeout=default_pg_timeout,
world_size=-1,
rank=-1,
store=None,
group_name=''):backend:指定当前进程要使用的通信后端。这里使用支持CPU的gloo
init_method:指定当前进程组初始化方式。可选择使用tcp、env、共享文件夹方法
rank:指定当前进程的优先级,rank=0为主进程,即master节点
world_size:总进程数
2.分配数据
torch.utils.data.distributed.DistributedSampler:传统的DP是直接将batch切分到不同的卡,这种操作常见现象是第一块卡的显存比其他卡都高,尤其是训练low-level方向等需要大图训练的任务。不同于DP,这里的DistributedSampler确保dataloader只会load到整个数据集的一个特定子集,它为每一个子进程划分出一部分数据集,以避免不同进程之间数据重复。
3.拷贝模型
torch.nn.parallel.DistributedDataParallel: 这个包是实现多机多卡分布训练最核心东西,它可以帮助我们在不同机器的多个模型拷贝之间平均梯度。
4.执行命令
在多个机器上分别执行以下命令,这里设置world_size=2,使用两台机器的cpu
# master node
python3 train.py --local_rank=0 --world_size=2
# node 1
python3 train.py --local_rank=1 --world_size=2三、解决问题
问题1.[/pytorch/third_party/gloo/gloo/transport/tcp/pair.cc:799] connect [127.0.0.1]:5030: Connection refused
解决方法:使用ip addr查看网络名称为enp5s0,在命令窗口执行
export GLOO_SOCKET_IFNAME=enp5s0参考
Pytorch多机多卡分布式训练 - 吴文灏的文章 - 知乎 https://zhuanlan.zhihu.com/p/373395654
Pytorch多机多卡分布式训练 - 谜一样的男子的文章 - 知乎 https://zhuanlan.zhihu.com/p/68717029
多机多卡分布式训练(Distributed Data DataParallel, DDP)安装踩坑记录 - xyl-507的文章 - 知乎 https://zhuanlan.zhihu.com/p/366735372
PyTorch 21.单机多卡操作(分布式DataParallel,混合精度,Horovod) - 科技猛兽的文章 - 知乎 https://zhuanlan.zhihu.com/p/158375055
PyTorch分布式训练基础--DDP使用 - kaiyuan的文章 - 知乎 https://zhuanlan.zhihu.com/p/358974461
Pytorch 分布式训练 - 会飞的闲鱼的文章 - 知乎 https://zhuanlan.zhihu.com/p/76638962
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









