






Spark环境搭建和使用方法
1.安装spark
spark运行在linux环境下,需要与其他环境配合使用(hadoop, Java)
注意:各环境之间需要版本匹配(Spark2.4.0 Java1.8 Hadoop2.7.1)


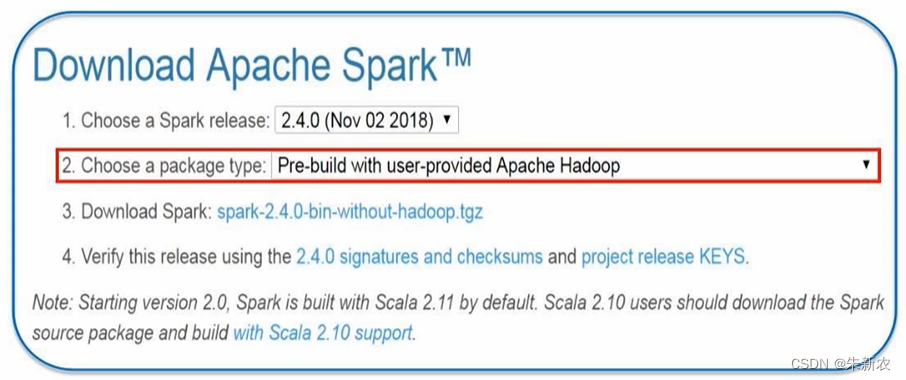
配置Spark的classpath


若需要使用HDFS中的文件,则在使用Spark前需要启动hadoop
Spark部署模式:
- spark单机模式:hadoop配置伪分布式
- spark集群模式
Standalone模式:使用spark自带的集群资源管理器(效率比较低)
YARN模式:由hadoop的YARN负责调度
Mesos模式:使用Mesis调度底层cpu资源
2.在pyspark中运行代码
特性:
- pyspark提供了简单的方式来学习spark API
- pyspark提供了Python交互式执行环境
- pyspark可以以实时,交互的方式来分析数据
pyspark命令及常用的参数:
pyspark --master <master-url>


yarn-client:一般在调试程序的时候使用
yarn-cluster:将driver建在集群中的某个节点上,企业产品上线时使用




3.开发Spark独立应用程序
- 编写程序
目的:计算文本文件中包含’a‘的行数和’b‘的行数from pyspark import SparkConf, SparkContext conf = SparkConf().setMaster("local").setAppName("My App") # local模式 sc = SparkContext(conf=conf) # 生成名为sc的SparkContext logFile = "file:///usr/local/spark/README.md" # 本地文件是file:/// logData = sc.textFile(logFile, 2).cache() # 把文本文件加载进来生成RDD,文本文件中的每一行成为 # RDD中的一个元素 numAs = logData.filter(lambda line:'a' in line).count() numBs = logData.filter(lambda line:'b' in line).count() print('Lines with a:%s, Lines with b:%s' % (numsAs, numBs)) -
在命令行执行如下:

-
也可以通过spark-submit提交:


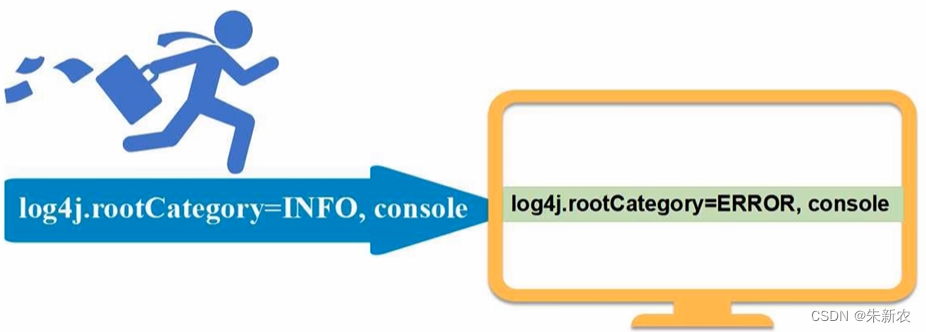
为了避免其他多余信息对运行结果干扰,可以修改log4j的日志信息显示级别:
4.Spark集群搭建
步骤:
准备工作:搭建hadoop集群环境->安装Spark->配置环境变量->Spark配置->启动Spark集群->关闭Spark集群
搭建hadoop分布式集群环境:

Spark+HDFS运行架构
安装步骤:
- 在Master节点上访问Spark官网下载Spark安装包

配置
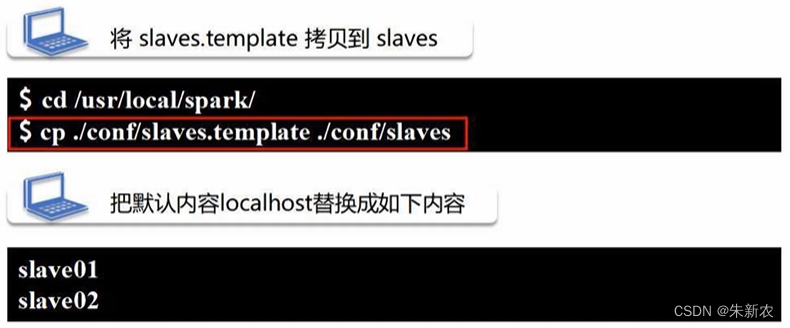
- 配置slaves文件
配置spark-env.sh文件
完成Spark和hadoop的挂接
说明hadoop相关配置信息目录
设置spark主节点的IP地址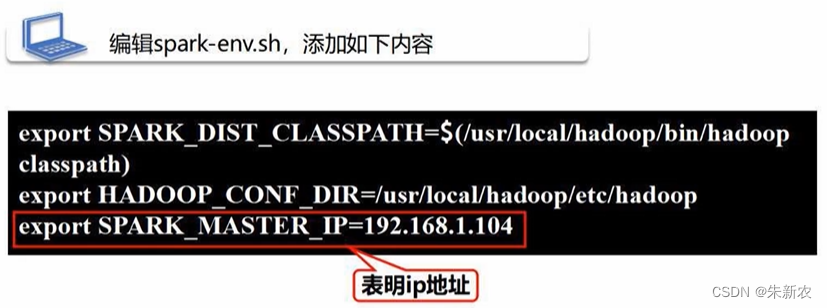
- 将Master主机上的/usr/local/spark文件夹复制到各个节点上

- 在slave01,slave02节点上分别执行下面同样的操作
基本上集群搭建完毕
- 在Master节点主机上运行
在Master节点上启动从节点
在Master主机测试环境
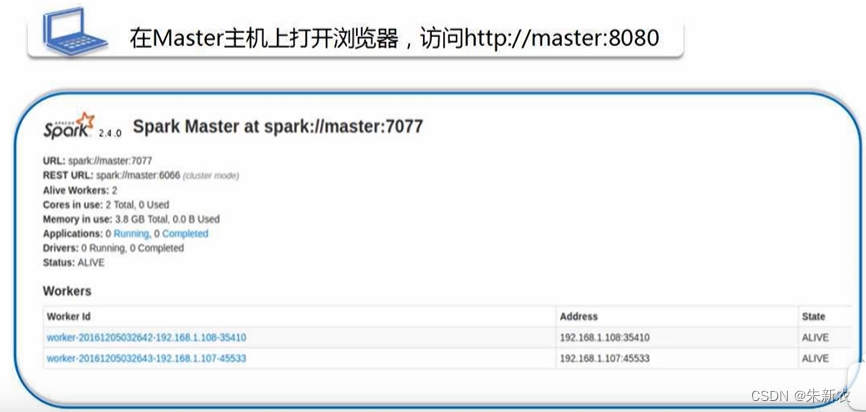
- 关闭Master节点

5.在集群上运行Spark应用程序
启动Spark集群

采用独立集群管理器

2 > &1 | grep "Pi is roughly"表示抓取含有Pi isroughly 3.1415926,其他多余的行不显示
在集群中运行pyspark:

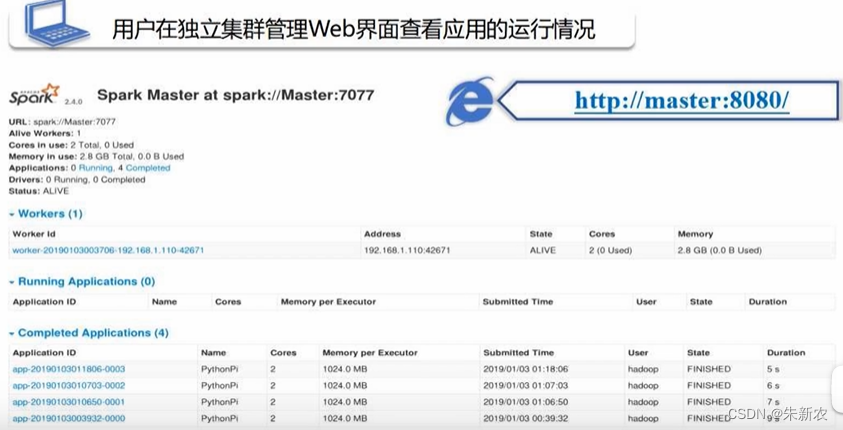
用户在独立集群管理Web界面查看应用的运行情况
在Master节点浏览器上运行http://master:8080/
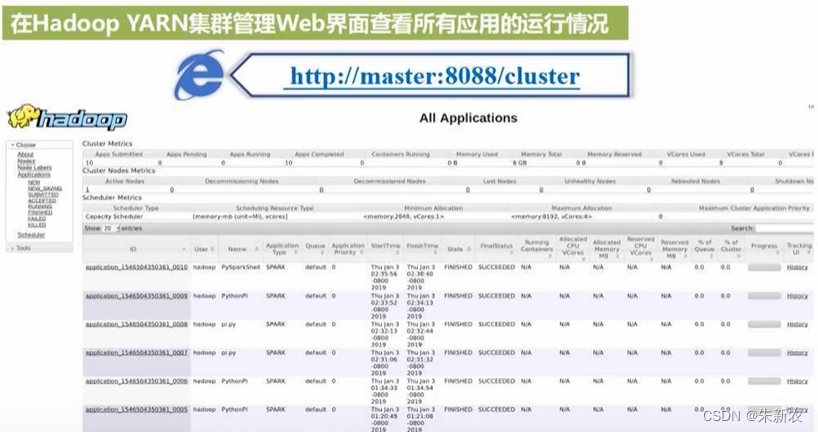
采用Hadoop YARN管理器


拷贝到浏览器中可以查看执行状态。
在集群中使用pyspark交互式环境运行
















 2448
2448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









