







因线上 kafka 集群磁盘资源不够导致服务停止,现在亟需启动服务恢复业务流程;因此领导给出的指示是删除今天 0 点之前的数据,后续在做系列优化如:扩容、缩短数据过期时间、压缩等。
github地址:https://github.com/kpretty/kafka-util
gitee地址:https://gitee.com/uhope/kafka-util
一、如何删除
kafka 本身给我们提供了删除日志的脚本kafka-delete-records.sh,脚本的提示信息如下:
This tool helps to delete records of the given partitions down to the specified offset.
Option Description
------ -----------
--bootstrap-server <String: server(s) REQUIRED: The server to connect to.
to use for bootstrapping>
--command-config <String: command A property file containing configs to
config property file path> be passed to Admin Client.
--help Print usage information.
--offset-json-file <String: Offset REQUIRED: The JSON file with offset
json file path> per partition. The format to use is:
{"partitions":
[{"topic": "foo", "partition": 1,
"offset": 1}],
"version":1
}
--version Display Kafka version.
从提示信息可以看出该脚本可以删除指定 topic-partition 指定偏移量之前的数据,通过 --offset-json-file 给一个删除策略的 json 文件,其中 json 的格式如下:
{
"partitions": [
{"topic": "foo", "partition": 1, "offset": 1}
],
"version":1
}
注:offset 为 -1 表示删除所有数据
做到这里难住我了,主题和分区这个信息很容易获取,但是这个偏移量就很难了,我们使用的是原生的 kafka 似乎没有现成的工具来获取今天零点数据的偏移量(有现成的请告诉我,我所掌握的 kafka 知识解决不了)
二、拓展功能
为了做到快速获取指定时间戳的各主题分区的消息偏移量功能,我决定拓展这个功能;因此需要做到如下如下功能:
- 获取指定 topic 的所有分区
- 获取每个 topic 所有分区对应时间戳的偏移量
- 输出指定格式的 json 文件
拓展的功能需要尽可能接近原生 kafka 脚本使用习惯
2.1 项目准备
初步构思需要的依赖有:kafka客户端、参数解析、json依赖、打包插件,因此 pom 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>kafka-util</artifactId>
<version>${kafka.version}</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<kafka.version>2.7.1</kafka.version>
</properties>
<dependencies>
<!-- kafka 客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
<scope>provided</scope><!-- 打包时添加,kafka本身也依赖,可以不用打进去 -->
</dependency>
<!-- json 依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.80</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
<!-- 参数解析 -->
<dependency>
<groupId>net.sf.jopt-simple</groupId>
<artifactId>jopt-simple</artifactId>
<version>5.0.4</version>
<scope>provided</scope><!-- 打包时添加,kafka本身也依赖,可以不用打进去 -->
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
<configuration>
<archive>
<manifest>
<mainClass>
</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
构建用于存储删除策略的 POJO 类
package tech.kpretty.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
/**
* @author wjun
* @date 2022/6/1 10:18
* @email wj2247689442@gmail.com
* @describe 删除策略 POJO 类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DeleteMetaJson {
private List<TopicPartitionOffsetMeta> partition;
private static final int version = 1;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class TopicPartitionOffsetMeta {
private String topic;
private int partition;
private long offset;
@Override
public String toString() {
return "{\"topic\":" + "\"" + topic + "\"," + "\"partition\":" + partition + "," + "\"offset\":" + offset + "}";
}
}
public static TopicPartitionOffsetMeta of(String topic, int partition, long offset) {
return new TopicPartitionOffsetMeta(topic, partition, offset);
}
@Override
public String toString() {
return "{\"partitions\":" + partition +
",\"version\":" + version + "}";
}
}
2.1 获取主题分区
kafka 提供了 AdminClient 类用来在代码中代替 kafka-topics.sh、kafka-configs.sh 等脚本功能,获取给定主题所有分区代码如下:
/**
* 获取待删除 topic 的分区信息
*
* @param server kafka server ip:port
* @param topics need delete topic
* @return topic and partition infos
*/
private static List<TopicPartition> buildTopicPartition(String server, List<String> topics) {
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, server);
// 构建 kafka admin 客户端
AdminClient client = KafkaAdminClient.create(properties);
ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
try {
// 获取指定 topic 的信息
client.describeTopics(topics).all().get().values().forEach(value -> {
String topic = value.name();
value.partitions().forEach(partition -> topicPartitions.add(new TopicPartition(topic, partition.partition())));
});
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
client.close();
return topicPartitions;
}
2.2 获取指定分区对应时间戳的offset
查询官方文档可知消费者提供offsetsForTimes方法,传入一个Map<TopicPartition, Long>返回Map<TopicPartition, OffsetAndTimestamp>,OffsetAndTimestamp 保存当前 TopicPartition 的偏移量和消息的时间戳(这个时间戳是消息到kafka的时间,这个时间是大于给定时间的最小时间戳),代码如下:
/**
* @param server kafka server ip:port
* @param topicAndPartitions topic and partition infos
* @param timestamp delete the data before this timestamp
* @return delete strategy json string
*/
private static String buildStrategy(String server, List<TopicPartition> topicAndPartitions, long timestamp) {
ArrayList<DeleteMetaJson.TopicPartitionOffsetMeta> metas = new ArrayList<>();
// kafka 连接信息
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, DEFAULT_CONSUMER);
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
HashMap<TopicPartition, Long> timestampsToSearch = new HashMap<>();
// 构建分区和时间戳的映射
topicAndPartitions.forEach(topicPartition -> timestampsToSearch.put(topicPartition, timestamp));
Map<TopicPartition, OffsetAndTimestamp> topicPartitionOffsetAndTimestampMap = consumer.offsetsForTimes(timestampsToSearch);
topicPartitionOffsetAndTimestampMap.forEach((topicPartition, offsetAndTimestamp) -> {
// 若没有小于该时间戳的消息,或者老版本消息没有时间戳则返回 null
if (offsetAndTimestamp != null) {
metas.add(
DeleteMetaJson.of(topicPartition.topic(), topicPartition.partition(), offsetAndTimestamp.offset())
);
}
});
consumer.close();
return new DeleteMetaJson(metas).toString();
}
2.3 参数解析
这里使用 kafka 源码中的参数解析 jopt-simple,基本使用方式如下:
OptionParser parser = new OptionParser();
// 定义参数
ArgumentAcceptingOptionSpec<String> server = parser.accepts("bootstrap-server", "REQUIRED: server(s) to use for bootstrapping.") // args1:参数的key,对应参数 --xxx; args2:参数描述
.withRequiredArg() // 是否是必须值
.describedAs("ip1:port,ip2:port...") // 参数简单描述
.ofType(String.class); // 参数value的类型
需要注意的是.withRequiredArg()设置只是将对象中的某个属性设置为 true,本身不对传入参数是否存在做校验,需要自己实现参数校验的功能,这里构建 CommandLineUtils 工具类实现校验功能
package tech.kpretty.util;
import joptsimple.ArgumentAcceptingOptionSpec;
import joptsimple.OptionParser;
import joptsimple.OptionSet;
import java.io.IOException;
/**
* @author wjun
* @date 2022/6/1 11:15
* @email wj2247689442@gmail.com
* @describe 命令行工具类
*/
public class CommandLineUtils {
public static void checkRequest(OptionParser parser, OptionSet parse, ArgumentAcceptingOptionSpec... options) throws IOException {
for (ArgumentAcceptingOptionSpec option : options) {
// option 是必须的同时这个 option 不存在
if (option.requiresArgument() && !parse.has(option)) {
System.out.println("Miss request args: " + option.options().get(0));
parser.printHelpOn(System.out);
}
}
}
}
2.5 打包测试
将 jar 放入 kafka 的 libs 目录下,并在 bin 目录下创建脚本 kafka-strategy-maker.sh,内容如下
#!/bin/bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
exec $(dirname $0)/kafka-run-class.sh tech.kpretty.CustomizeDeleteRecord "$@"
kafka-run-class.sh 脚本会去加载 libs 下所有的 jar 并将其添加在 classpath 中,因此只需要指定类名即可,给脚本赋执行权限
先来一个 --help
./kafka-strategy-maker.sh --help
结果如下

开始测试
./kafka-strategy-maker.sh --bootstrap-server super158:9092 --topic DAS-54 --timestamp 1653793077000 --output /tmp
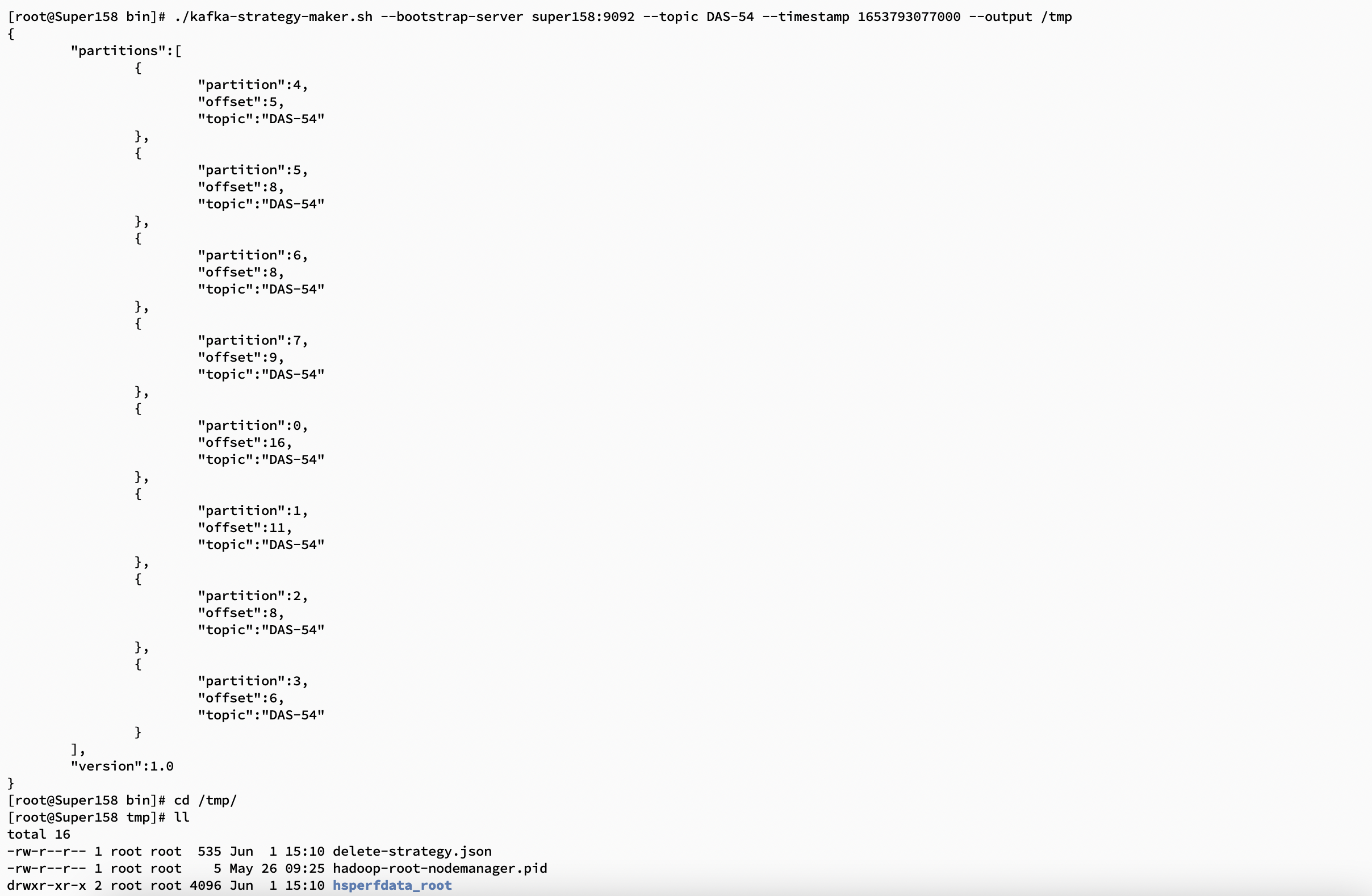
执行删除策略
./kafka-delete-records.sh --bootstrap-server super158:9092 --offset-json-file /tmp/delete-strategy.json
结果如下:

这时候满足条件的 segment 会被打上 delete 标记,等待一段时间后数据就被删除啦
更多大数据文章见作者博客:https://kpretty.tech
















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











