







一、问题复现
不知你是否遇到过 join 结果明显不匹配的情况,例如on t1.join_key = t2.join_key中两个join_key明显不相等,但 join 的结果却将其匹配在一起。今日博主在通过用户 id 关联获取用户信息时发现一个用户 id 可以在用户维表中匹配出若干条(用户维表不存在数据重复),如下:
-- 业务表
create table tmp_hz_perm.tmp_20240520_1
(
id string
) stored as parquet;
-- 用户维度表
create table tmp_hz_perm.tmp_20240520_2
(
id bigint,
name string
) stored as parquet;
插入若干条数据
insert into tmp_hz_perm.tmp_20240520_1
values ('4268348961309240666');
insert into tmp_hz_perm.tmp_20240520_2
values (4268348961309240666, 'user1'),
(4268348961309241004, 'user2'),
(3268348961319241004, 'user3');
模拟事故 sql
-- sql-1
select *
from tmp_hz_perm.tmp_20240520_1 t1
left join tmp_hz_perm.tmp_20240520_2 t2 on t1.id = t2.id;
我们期望的结果是返回user1,但实际情况却是匹配出多条数据

有经验的小伙伴可能一眼就看出来 join 的问题,那就是两个join_key数据类型不一致,恭喜你成功找到了这个问题!!!那么对应的解决方案就是保持数据类型一致即可
-- sql-2
select *
from tmp_hz_perm.tmp_20240520_1 t1
left join tmp_hz_perm.tmp_20240520_2 t2 on cast(t1.id as bigint) = t2.id;
结束了吗???显然没有!我们还没有探寻这个问题的本质
二、本质分析
上面的现象可以总结出两点疑问:
- 数据不一致真的查询不出来数据吗
- 为什么会关联出一条完全不相干的数据
对于问题一,数据不一致是可以查询出来的,例如
-- sql-3
select * from tmp_hz_perm.tmp_20240520_2 where id = '4268348961309240666';
+----------------------+----------------------+
| tmp_20240520_2.id | tmp_20240520_2.name |
+----------------------+----------------------+
| 4268348961309240666 | user1 |
+----------------------+----------------------+
1 row selected (0.145 seconds)
回答问题二需要从执行计划出发
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
t2
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
t2
TableScan
alias: t2
Statistics: Num rows: 3 Data size: 6 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 UDFToDouble(id) (type: double)
1 UDFToDouble(id) (type: double)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Left Outer Join 0 to 1
keys:
0 UDFToDouble(id) (type: double)
1 UDFToDouble(id) (type: double)
outputColumnNames: _col0, _col4, _col5
Statistics: Num rows: 3 Data size: 6 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col4 (type: bigint), _col5 (type: string)
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 3 Data size: 6 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 3 Data size: 6 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Execution mode: vectorized
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
注意 hive 的执行计划中比我们想象中要多做一步UDFToDouble,其原因就是当两个关联键数据不一致时为了还可以进行关联,hive 将其 key 统一转换为Double,同时也可以看一下UDFToDouble的处理逻辑
public DoubleWritable evaluate(LongWritable i) {
if (i == null) {
return null;
} else {
doubleWritable.set(i.get());
return doubleWritable;
}
}
public DoubleWritable evaluate(Text i) {
if (i == null) {
return null;
} else {
if (!LazyUtils.isNumberMaybe(i.getBytes(), 0, i.getLength())) {
return null;
}
try {
doubleWritable.set(Double.parseDouble(i.toString()));
return doubleWritable;
} catch (NumberFormatException e) {
// MySQL returns 0 if the string is not a well-formed double value.
// But we decided to return NULL instead, which is more conservative.
return null;
}
}
}
// doubleWritable.set(...)
public void set(double value) {
this.value = value;
}
可以看出set入参均是 double,那么4268348961309240666在进行数据转换时一定会发生精度丢失(远超 double 的范围),下面的一个小 demo 可以很好的解释为什么会匹配出不相等的数据
package fun.uhope;
import org.apache.hadoop.hive.ql.udf.UDFToDouble;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
public class Test {
public static void main(String[] args) {
String k1 = "4268348961309240666";
long k2 = 4268348961309240666L;
long k3 = 4268348961309241004L;
long k4 = 3268348961309241004L;
UDFToDouble uDFToDouble1 = new UDFToDouble();
UDFToDouble uDFToDouble2 = new UDFToDouble();
UDFToDouble uDFToDouble3 = new UDFToDouble();
UDFToDouble uDFToDouble4 = new UDFToDouble();
DoubleWritable v1 = uDFToDouble1.evaluate(new Text(k1));
DoubleWritable v2 = uDFToDouble2.evaluate(new LongWritable(k2));
DoubleWritable v3 = uDFToDouble3.evaluate(new LongWritable(k3));
DoubleWritable v4 = uDFToDouble4.evaluate(new LongWritable(k4));
System.out.println(v1);
System.out.println(v2);
System.out.println(v3);
System.out.println(v4);
System.out.println(v1.compareTo(v2));
System.out.println(v1.compareTo(v3));
System.out.println(v1.compareTo(v4));
System.out.println((double) k2 == (double) k3);
System.out.println((double) k2 == (double) k4);
System.out.println(k2 == k3);
}
}
结果如下:
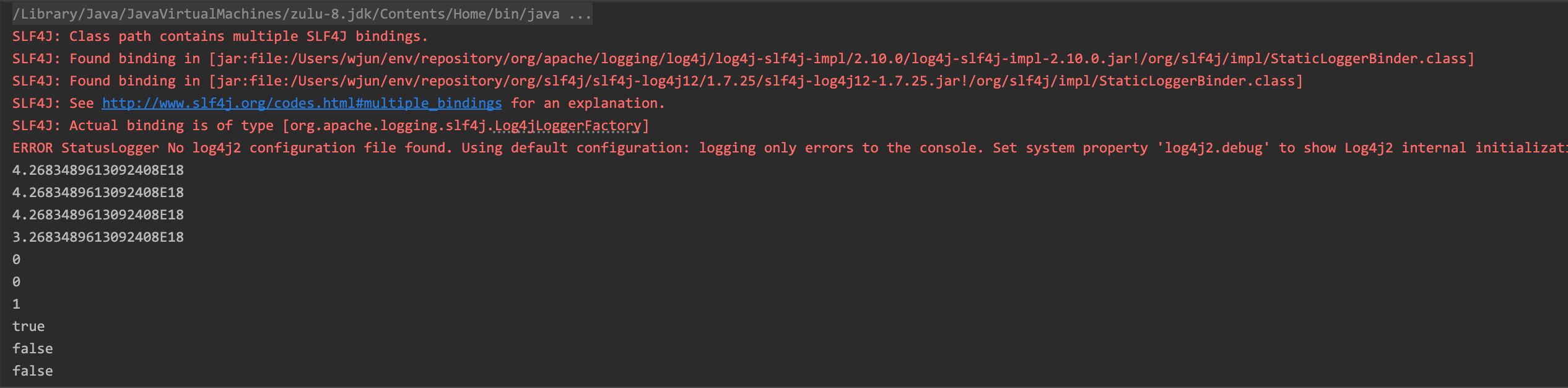
对于sql-2、sql-3各位可以查看一下各自的执行计划就能明白为什么可以得到期望的结果
思考: 针对 hive join 过程中当数据类型不一致时采用
UDFToDouble是否合理
















 4003
4003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











