







Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集
- 频繁项集:找出频繁一起出现的物品集的集合
- 支持度:一个项集的支持度被定义为数据集中包含该项集的记录所占的比例;
支持度 = (包含物品A的记录数量) / (总的记录数量
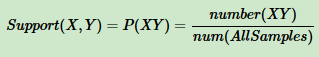
- 置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
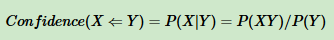
图片来源https://www.cnblogs.com/pinard/p/6293298.html
关联规则基本思想
- 找出所有频繁项集:找出支持度大于最小支持度的项集,即频繁项集
- 由频繁项集产生关联规则:这些规则必须满足最小支持度和最小可信度
- 算法核心思想:
频繁项集的非空子集一定也是频繁的
算法基本过程
- 算法命名源于算法使用了频繁项集性质的先验知识
- 算法的基本过程:
- 生成候选集:找出候选集,即有可能成为频繁集的项集
- 生成频繁项集:生成通过数据库扫描筛选出满足条件的候选集形成又一层频繁集
(频繁项集的子集也一定是频繁项集)例如:如果{A,B}是频繁集,则{A}{B}也一定是频繁集 - 生成关联规则:用得到的频繁集生成强关联规则。
- Apriori算法中候选集生成步骤:
- 自连接Lk-1
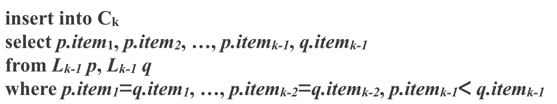
- 修剪
.
- 自连接Lk-1
算法总结
Aprior算法是一个很经典的频繁项集的挖掘算法,很多算法都是基于Aprior算法而产生的,包括FP-Tree,GSP, CBA等。这些算法利用了Aprior算法的思想,但是对算法做了改进,数据挖掘效率更好一些,因此现在一般很少直接用Aprior算法来挖掘数据了,但是理解Aprior算法是理解其它Aprior类算法的前提,同时算法本身也不复杂,因此值得好好研究一番。

















 2308
2308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









