









 EasyFont是一个基于风格学习的系统,能够帮助用户轻松创建自己的大规模手写字体库。系统通过学习用户少量手写样本的风格,自动合成所有字符的个人笔迹,包括复杂的中文汉字。它采用非刚性点集配准方法提取笔画轨迹,利用神经网络学习和重构整体风格,同时恢复手写细节。通过精心设计的输入字符选择、笔画提取和细节建模,确保生成的字体库具有高质量的文本呈现效果。该系统为中文手写字体的个性化生成提供了一种创新解决方案。
EasyFont是一个基于风格学习的系统,能够帮助用户轻松创建自己的大规模手写字体库。系统通过学习用户少量手写样本的风格,自动合成所有字符的个人笔迹,包括复杂的中文汉字。它采用非刚性点集配准方法提取笔画轨迹,利用神经网络学习和重构整体风格,同时恢复手写细节。通过精心设计的输入字符选择、笔画提取和细节建模,确保生成的字体库具有高质量的文本呈现效果。该系统为中文手写字体的个性化生成提供了一种创新解决方案。
一种基于风格学习的系统用来构建你的手写字体库
(EasyFont: A Style Learning-Based System to Easily Build Your Large-Scale Handwriting Fonts)
问题:怎么样设计每个人自己的艺术风格字体?英文上因为只有26个字母比较方便,但是对于中文很难
提出解决方法:提出一个系统EasyFont,通过学习你写的少量字体的风格(自己精心挑选,少于1%),自动合成字体库中的所有字符(如中文)的个人笔迹。
为了构建一个全自动手写字体生成系统,从以下两个方面来考虑:
1、怎样自动的去分解输入的字体,从而将其转换为统一的、可学习的数据?
2、怎样描述和重构用户特定的手写风格?
用户过程:用户写一些系统规定的汉字,拍照上传到系统,在接收到这些文本图像后,系统大约在两小时内自动生成一个用户笔迹字体库。
首先基于非刚性点集配准方法和若干启发式规则(several heuristic rules),对输入文本图像中分割出来的每个字符图像提取每个笔画的书写轨迹。然后利用神经网络学习和重构用户的整体笔迹风格,将用户的笔迹风格分解为笔画形状风格和笔画布局风格。同时,笔画连接性和轮廓形状等笔迹细节也得到了正确的描述和恢复。最后,一个完整的个人字体库可以通过对人工书写样本和机器生成的手写所有其他字符的图像进行矢量化来生成。
文章的三个贡献:
1、设计一个笔画提取算法,从训练好的字体骨架流形(font skeleton manifold)【骨架即书写轨迹】中构造最合适的参考数据,然后通过非刚性点集配准方法(non-rigid point set registration)建立目标字符和参考字符之间的对应关系。这样我们就可以准确的知道用户是如何编写这些字符的。
【刚性配准:给定两个点集,刚性配准产生一个刚性变化,该变化将一个点集映射到另一个点集。刚性变换定义为不改变任何两点之间距离的变化,一般这种转换只包括平移和旋转
非刚性配准:给定两个点集,非刚性配准产生一个非刚性变换,该变化将一个点集映射到另一个点集。非刚性变化有变形、缩放,也可以涉及到其他非线性变换】
2、提出了一个系统使人可以轻松生成大规模手写字体。此外,通过使用专门设计的输入字符选择方案、自动笔画提取、手写细节恢复技术,系统生成的字库在实际使用中几乎保证高质量的文本呈现结果。
3、手动指定了标准‘楷体’样式中所有27533个汉字和其他两种手写样式中较小字符集的每个笔画的书写轨迹。这种真实数据与实验中使用一组不同风格的其他手写图像数据可以作为手写合成的基准。
方法概述:
整体上分为offline和online
在线下,首先创建参考数据,手动指定标准“楷体”字库中所有笔画的写入轨迹,用作样本学习的参考数据;然后正确选择一系列输入字符集,在实际应用中,为了满足实不同需求,对一系列输入字符集进行适当的选择;最后构建字体骨架流形(font skeleton manifold ),以生成最合适笔画提取的参考数据(reference data)。
在线上,首先进行文本分割,将输入的文本照片分割成单个字符图像的笔画轨迹;然后进行笔画提取,对每个字符图像提取每个笔画的书写轨迹,选择正确的提取结果;在进行整体风格学习,利用ANNs(人工神经网络)来学习和重构用户的整体笔迹风格,将其分解为笔画形状风格(stroke shape style)和笔画布局风格(stroke layout style);同时进行细节建模,使得笔画连通性(stroke connectivity)和轮廓形状(shapes of contours)在内的手写细节也得到了恰当的描述和恢复;最后字体生成,通过向所有其他字符的人工书写样本图像和机器生成的手写图像向量化来生成一个完整的个人字体库。
3.1、选择输入的字符集:
要想模仿用户的笔迹,系统需要学习相应的、足够的样本。构成汉字基本要素的笔画共有32种,在离线状态下,对于“楷体”中27533和汉字手动指定每个笔画的书写轨迹,并定义1032类组件(这些组件由一组笔画组成),由于同一基本类型的笔画形状差异较大,进一步将其划分为339个细粒度类别。根据这些参考数据,可以选择涵盖所有339中笔画的字符来确定一个合适的字符集。
如图:(a)演示将汉字样本分解为各个部分,最后再分解成笔画。
(b)构成汉字最基本的笔画,可以分为32个基类

3.2、学习字体的骨架流形(Learning Font Skeleton Manifold)
为了构造字体骨架流形,先使用数学形态学(mathematical morphology)的细化算法(thinning algorithm)得到训练集中每个字符的书写轨迹(即骨架)。使用每个字符的骨架而不是用轮廓简化了构建字体流形的复杂性。作者先用预定义的笔画轨迹模型通过非刚性点集配准过程,在所有选定的字体中匹配每个字符的骨架点(skeleton point)。然后作者再使用密集的骨架点为每个字符对应关系为基础,以拟合非线性流形(non-linear manifold),该流行将不同字体样式的字符连接到一个空间中。这里使用高斯过程隐变量模型(Gaussian Process Latent Variable Model)学习这个非线性模型。
【细化:又称骨架化,即在不影响原图想拓扑连接关系的条件下,尽可能用最少的迭代次数,快速准确的将宽度大于一个像素的图形线条转变为一个像素宽线条的处理过程,也就是抽取像素的骨架】
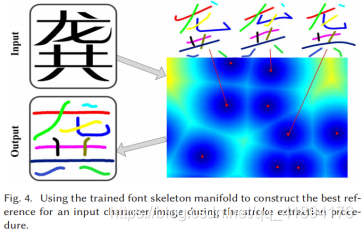
3.2.1、字符匹配(character Matching)
构建一个高维向量,其中包含用于表示每个符号的笔画骨架点。为了学习字体骨架流形,需要先建立不同字体样式的字形之间的点对应关系,作者选择设计一种基于点集配准算法。为了确定准确的对应关系,作者建立了笔画模型数据库,其中包含339个不同类别的笔画。对于每个笔画模型的书写轨迹上手工选择关键点,然后得到这个字体的骨架,骨架关键点主要有三种:起始点、终点点和角点,围绕着骨架关键点存在着丰富的文体信息。
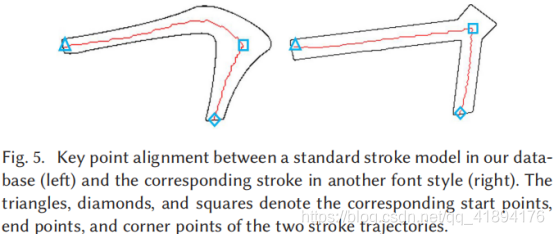
三角形:起点; 方块:终点; 正方形:角点
3.3文本分割
在接收到用户的文本图像后,系统将通过以下五个步骤从这些图像中自动分割出单个字符图像:
1)对原始文本图像进行高斯平滑和自适应图像二值化
2)找到具有连接像素的区域,计算它们的边界框,并将它们视为字符的候选;
3) 通过应用几个启发式过滤器(例如大小、长度比)丢弃不合适的候选对象宽度,黑白像素的比率)。然后,如果有效候选字符数等于需要写入的字符数,则转到下一步。否则,放大图像并返回第二步
4) 计算图片底部行中检测到的候选对象的质心,从而通过拟合这些质心点的直线来估计文本图像的旋转角度
5) 从校正后的文本图像中按顺序分割单个字符图像,并用相应字符的编码(unicode)值标记它们。
3.4笔画提取
给定一定数量的汉字图像,为了知道用户是怎么书写这些汉字,要想办法精准定位每个笔画在汉字上的书写轨迹。作者利用点集配准Coherent Point Drift (CPD)算法实现给定目标字符图像骨架与其最合适参考数据之间的非刚性配准。
【点集配准问题:给定两个点集,分配对应关系并将一个点集映射到另一个点集的变换】
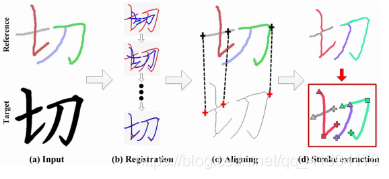
上图展示了笔画提取算法,a: 对于给定一个目标手写字符以及最适合它对的相应参考;
b : 建立它们之间的对应关系; c : 建立它们之间的通信关系; d :提取目标字符的每个笔画轨迹,再次进行配准以定位每个笔画轨迹。
3.5整体风格学习
整体风格学习有两种,1、reference data (ref), 2、handwritten character(hand).
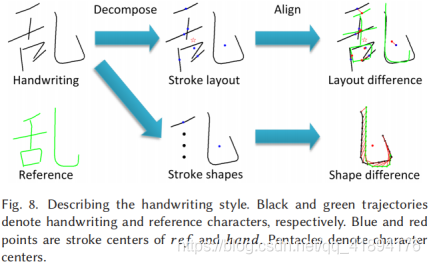
作者将汉字分解为笔画形状(SS)和笔画布局(SL),因此对于整体的书法风格分为笔画形状风格(SSS)和笔画布局风格(SLS)。
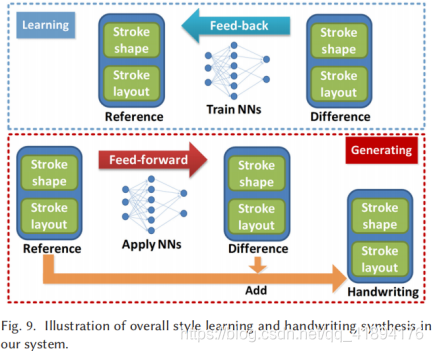
上图概述如何使用EasyFont学习和重建用户的整体笔迹风格,它包括两个过程:风格学习和笔迹合成。
数据集:www.icst.pku.edu.cn/zlian/EasyFont/


















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











