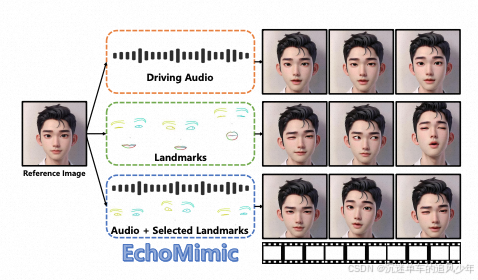
Diffusion Models专栏文章汇总:入门与实战 前言:目前肖像图片动画(portrait image animation)领域存在的一个问题是,仅由音频驱动的方法由于音频信号相对较弱,有时会不稳定,而仅由面部关键点驱动的方法虽然驱动更稳定,但由于对关键点信息的过度控制,可能会导致不自然的结果。EchoMimic 同时使用音频和面部关键点进行训练,有效解决了这一问题。 目录 贡献概述 方法详解 实验 训练 推理 数据集 评价方法 贡献概述 目前肖像图片动画(portrait image anim









 超级会员免费看
超级会员免费看


 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








