







1,按照这个博客https://blog.csdn.net/qq_37193537/article/details/81335165,,,已经安装成功了
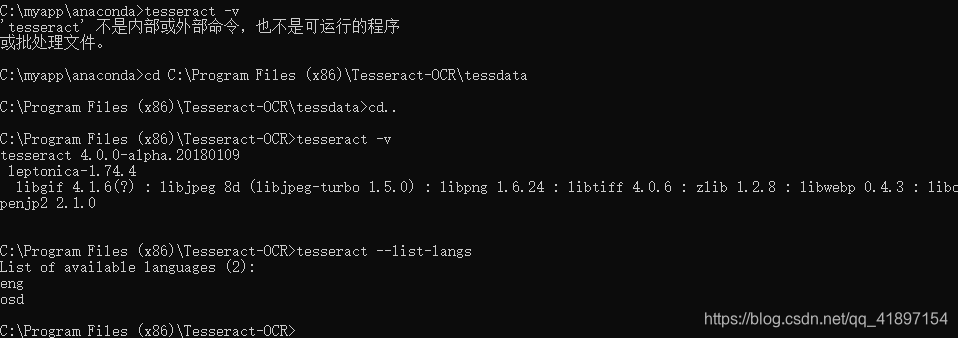
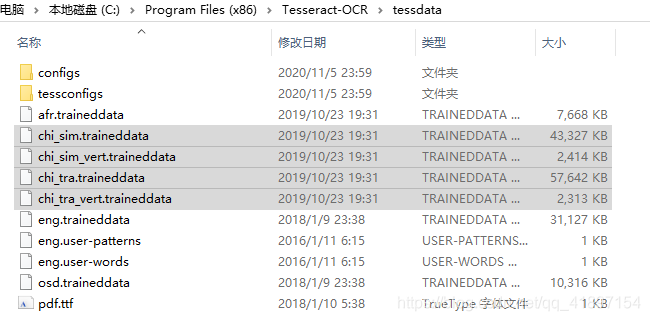
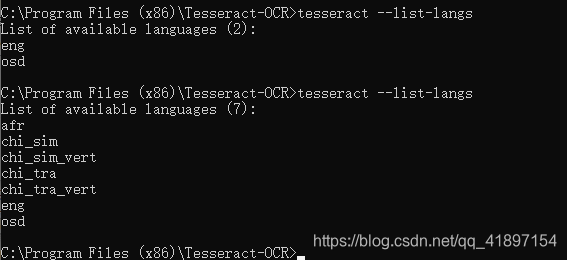
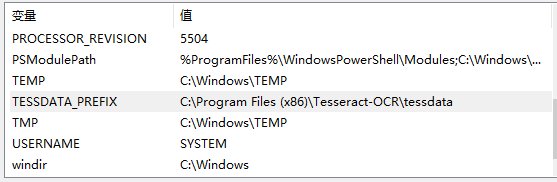
2,如何添加语言包,把对应想要的语言包放到放置tessdata文件夹并且配置TESSDATA_PREFIX环境变量指向tessdata文件夹(我复制了四个语言包如下图)
1,按照这个博客https://blog.csdn.net/qq_37193537/article/details/81335165,,,已经安装成功了
 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























