







要在一个已知的串中找到子串第一次出现的位置,主串和模式串的匹配,有两种方法。
(一)暴力解决,朴素匹配
枚举,直到主串结束。两个for循环。第一个for循环遍历整个主串,对于主串的每一个字符作为发起点,然后第二个for循环开始遍历整个子串,不断比较主串所指元素与子串所指元素是否匹配,
如果匹配,一直向后移动,直到子串最后都匹配成功的话,返回本次匹配的主串的发起点。
如果不匹配,继续枚举主串的下一个发起点,然后继续一个一个与子串匹配。
class Solution {
public int strStr(String haystack, String needle) {
int len1=haystack.length();
int len2=needle.length();
char[] haystack1=haystack.toCharArray();
char[] needle1=needle.toCharArray();
for(int i=0;i<=len1-len2;i++){
int k=i;
int j;
for( j=0;j<len2;j++){
if(haystack1[k]!=needle1[j]){
break;
}
k++;
}
if(j==len2){
return i;
}
}
return -1;
}
}
(二)KMP算法
上述的暴力求解问题的时间复杂度是O((n-m)*m),n是主串的长度,m是子串的长度。
KMP算法可以用更高效的速度解决字符串匹配的问题。
KMP可以在匹配过程当中减少数据的多次匹配。
例如,主串abeababeabf和子串abeabf进行匹配的时候
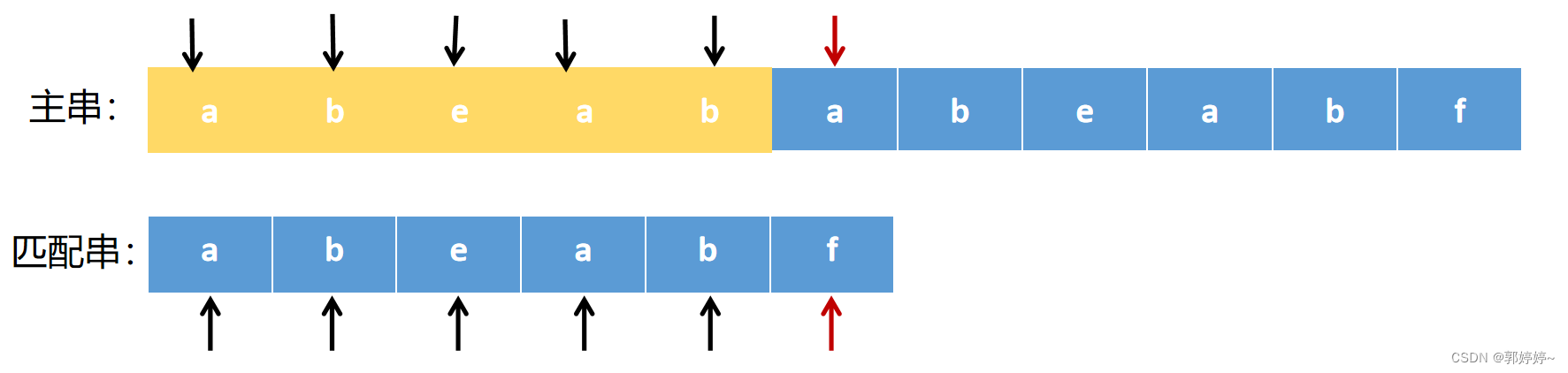
前边的abeab都匹配成功了,到最后的a和f匹配失败了。
如果是朴素匹配的方法,下一步是主串的起始点向后移动一位,找到首字母与子串相同的,继续与子串进行匹配,即ababea和abeabf匹配
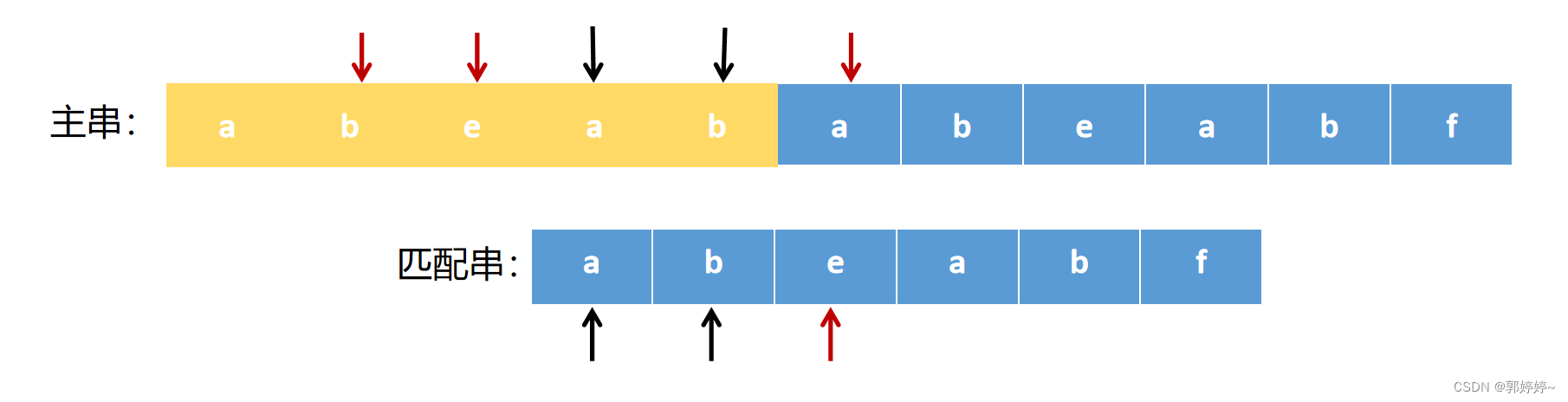
第一次匹配和第二次匹配的过程中这里的ab都进行过比较,子串的前边和后边是有重合的。所以我们只要将子串直接移动到这个位置就行,会减少很多不必要的比较。
这就是KMP的思想。匹配串会检查之前已经匹配成功的部分中是否存在相同的【前缀】和【后缀】。如果存在就跳转到前缀的下一个位置继续往下匹配。
KMP:

直接跳转到ababea 与abeabf进行匹配。
如果继续匹配失败,子串的前边不存在相同的【前缀】和【后缀】,这时候只能回到匹配串的起始位置重新开始。
到a和e匹配不成功,又没有前后缀,只能重新从头开始比较。
KMP算法不会进行回溯。
从子串某个位置跳转到下一个位置,是看子串的前后缀情况,是与主串无关的,所以要找到子串的前后缀关系。称为找next数组。
next数组的构建:
next数组是指除当前字符外(不包含当前字符)的公共前后缀的最长长度,找最长公共前后缀。
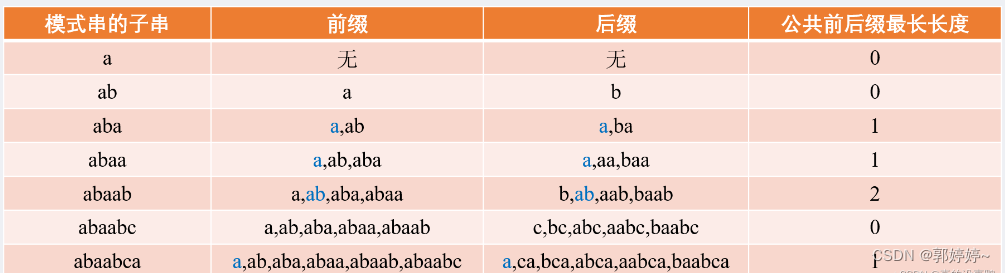
默认:next[1]=0
class Solution {
public int strStr(String haystack, String needle) {
if (needle.isEmpty()) return 0;
int len1 = haystack.length();
int len2 = needle.length();
haystack = " " + haystack;
needle = " " + needle;
char[] s = haystack.toCharArray();
char[] p = needle.toCharArray();
// 构建 next 数组
int[] next = new int[len2 + 1];
for (int i = 2, j = 0; i <= len2; i++) {
while (j > 0 && p[i] != p[j + 1]) j = next[j];
if (p[i] == p[j + 1]) j++;
next[i] = j;
}
for (int i = 1, j = 0; i <= len1; i++) {
while (j > 0 && s[i] != p[j + 1]) j = next[j];
if (s[i] == p[j + 1]) j++;
if (j == len2) return i - len2;
}
return -1;
}
}















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









