







 BML是一款用于BGP数据集生成和特征提取的工具,源于法国留尼旺大学的研究,旨在方便BGP和机器学习模型的开发。它支持统计和图形特征,以及自定义特征构建,简化了BGP安全研究中的数据处理流程。BML基于BGPStream,可以从RouteViews和RIPE RIS项目的数据中提取信息。用户可以通过设置时间段、选择采集器和时间片长度来定制数据集。
BML是一款用于BGP数据集生成和特征提取的工具,源于法国留尼旺大学的研究,旨在方便BGP和机器学习模型的开发。它支持统计和图形特征,以及自定义特征构建,简化了BGP安全研究中的数据处理流程。BML基于BGPStream,可以从RouteViews和RIPE RIS项目的数据中提取信息。用户可以通过设置时间段、选择采集器和时间片长度来定制数据集。
研究BGP安全的小伙伴们都知道,分析BGP安全事件容易,但是收集BGP事件的特征超难。主要的原因有两点,一点是有效特征难以构建,第二点则是基于BGP数据流的特征很难生成。今天我给大家推荐一款非常好用的BGP特征生成工具--BML。
BML 是一种 BGP 数据集生成工具,可提取文献中的大部分已知特征,Internet 拓扑,允许用户从 BGP 数据构建特定功能。BML除了提供32 个合成特征(从BGP volume和AS Path中生成)和 14 个 BGP 图形特征,这是现有文献中的大部分已知特征,还允许用户从 BGP 数据中构建自定义特征,非常方便实用。 BML是法国留尼旺大学的Kevin Hoarau等人构建的,相关论文发布在IEEE International Conference on Communications Workshops上,原文地址是:BML: An Efficient and Versatile Tool for BGP Dataset Collection,感兴趣的小伙伴们可以去看看原文。
BML的数据来源是RouteViews和 RIPE RIS项目提供的BGP数据,这两个项目是当前最权威的BGP路由信息收集项目,自 2000 年以来一直在收集和归档分布在世界各地的不同收集器提供的 BGP 数据。每个收集器都会接收来自其所有邻居的 BGP 更新,并相应地更新其路由信息库 (RIB)。但是BML使用的底层框架是BGPStream,它并不是直接从Routeviews和Ris中获取数据。BGPStream是CAIDA提供的一个对来自 BGP 路由信息的数据进行净化的软件,我们可以利用BGPStream净化后的 BGP 数据需要进行转换以提取有用信息,这个软件以后有机会咱们再细讲。
在研究BGP安全的文献中,广泛采用的特征是从BGP数据转换提取的特征。这些特征分为不同的类别:i) 反映 BGP 稳定性的volume特征和反映拓扑变化的 AS-PATH 特征;ii) 反映 BGP 底层图结构的图特征。BML的目标就是方便的从 BGP 数据中提取所有特征。
1. 技术框架
BML通过自动化 BGP 的部分工作流程,让 BGP 专家和机器学习从业者能够专注于开发和评估 BGP 或 ML 模型。BML的目标是通过确保以下几点来加快模型的迭代:
- 首先,构建和更新数据集只需要确定感兴趣的时段和一组参数;
- 其次,改变 ML 模型和/或数据转换不需要重新收集 BGP 数据。
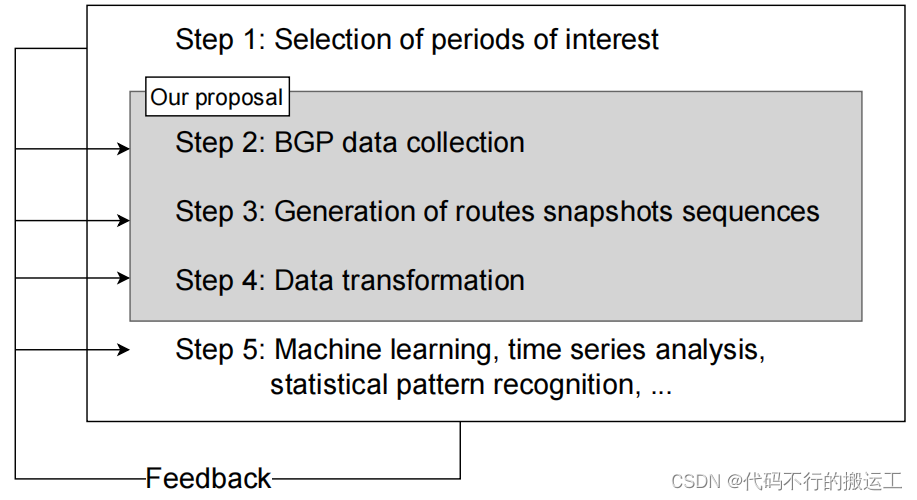
想要使用BML,你得先确定你感兴趣的时间段。如果你是研究安全的,那也就是你关注的事件的发生时间段。一旦在步骤➊中确定了感兴趣的时间段,在步骤➋中,BML 就会使用特定的数据结构自动收集数据。对于每个感兴趣的时间段,BML 会提取 BGP 路由的周期性快照,并在第➌步生成无损且存储高效的表示。在第➍步中,BML 提出了辅助函数,以简化数据转换的开发,从而满足用户或 ML 模型的要求。转换函数的输出可用于解释或训练和测试 ML 模型(步骤➎)。

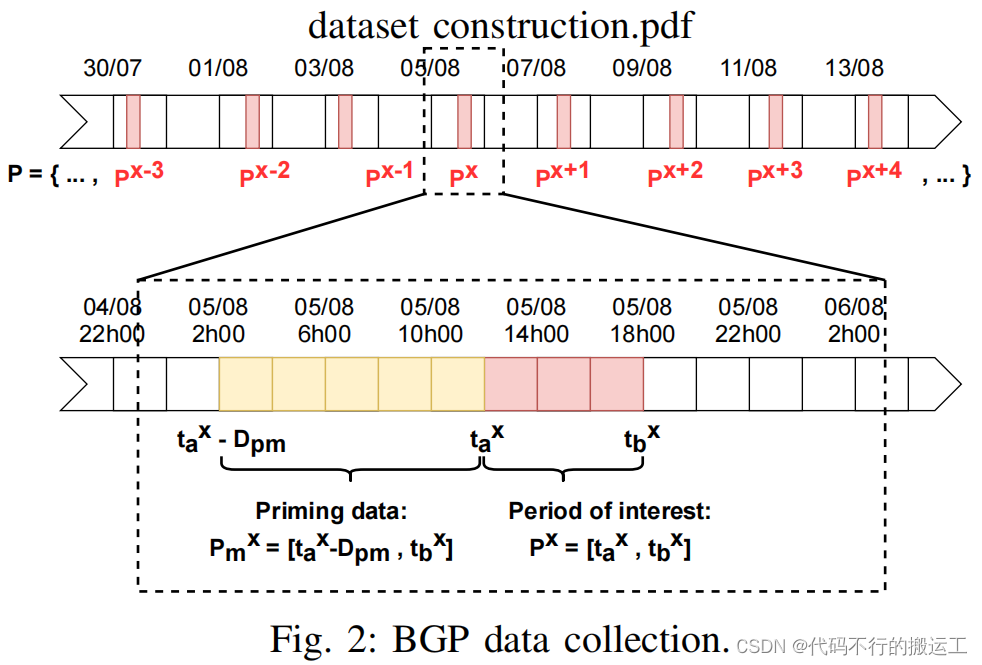
在 BML 中,值得纳入数据集的事件称为感兴趣期。时间戳位于 间隔内的来自选定收集器的所有 BGP 更新都将包含在数据集中。由于BGP协议是增量式的,因此BGP数据的收集面临着一个冷启动问题,即你确定的感兴趣的时间不一定在收集项目的单位收集时间内,因此BML设置了一个初始数据收集期,也叫引导期。在这个时期,BGP 数据会在感兴趣的时期之前收集。引导期数据以路由快照的形式存储,路由快照由算法1获得。这种表示方式减少了存储空间。默认的初始化周期设置为10小时,平均需要20MB的存储空间,而关注时段每小时需要75MB的存储空间。因此,对于BML,最重要的参数主要包括三个:
- >感兴趣时段列表:每个感兴趣时段的边界,引导时段的持续时间也应足够长,以防止冷启动,同时考虑到其对数据集大小和收集时间的影响。
- >采集器列表:在某些情况下,该参数在很大程度上取决于使用情况、收集器的位置可能很重要。
- >统计特征的时间片:从收集到的BGP数据流确定用于特征统计的时间长度。通过自定义时间片长度,确定用于统计的特征的BGP数据量。具体可以分为1分钟、2分钟等。
2. BML安装
BML提供了github下载渠道,你可以直接在服务器上使用clone命令获取BML软件。如果你下载不了,我这里提供了软件包进行下载。
$ git clone https://github.com/KevinHoarau/BML.git
$ cd BML
$ pip install . -v在下载好软件之后进行安装即可,安装过程可能需要一点时间。当然由于BML的底层框架是BGPstream,因此你得想安装好BGPstream才行。BGPstream的安装和使用在另外一个博文有描述。
3. 数据集定义和收集:
dataset.load()将描述集合参数dict的 python 作为输入。PeriodsOfInterests字段的输入为一个list-dic,每个字段描述数据集中的一个样本。数据收集代码为:
from BML.data import Dataset
from BML import utils
#################
# Data collection
folder = "dataset/" # 确定本次任务的根目录
dataset = Dataset(folder) # 开启数据收集的对象
# 设置好背景参数,这个在所有任务的数据采集中不会变化
dataset.setParams({
"PrimingPeriod": 10*60, # 10 hours of priming data
"IpVersion": [4], # only IPv4 routes
"Collectors": ["rrc06"], # rrc06: at Otemachi, Japan
})
# 输入任务列表,列表中以字典的形式详细描述任务
dataset.setPeriodsOfInterests([
{
"name": "GoogleLeak",
"label": "anomaly",
"start_time": utils.getTimestamp(2017, 8, 25, 3, 0, 0), # August 25, 2017, 3:00 UTC
"end_time": utils.getTimestamp(2017, 8, 25, 4, 0, 0) # August 25, 2017, 4:00 UTC
}
])
# run the data collection
# runJobs()有三个参数,分别是任务列表,由 dataset.getJobs()输出
# 记录数据收集的日志所在目录
# 隐藏参数nbProcess,确定开启几个进程,默认单进程
utils.runJobs(dataset.getJobs(), folder+"collect_jobs") BML 在收集样本数据时,会在样本文件夹下的日志文件中报告进展情况。然后,我们可以使用 bash 命令监控进展情况,如:
$ watch cat dataset/anomaly/GoogleLeak/log_collect_sample.log如果数据集包含多个样本(通常是这种情况),则可以使用以下方法监控处理队列:
$ watch -n 1 cat dataset/collect_jobs/queue.log4.统计特征提取
数据收集完毕后,我们就可以进行第一次数据转换。在此,我们将时间片长度设置为1分钟(period=1)来提取 BGP 统计特征。
from BML.transform import DatasetTransformation
# features extraction every minute
# 启动一个转换特征类对象
datTran = DatasetTransformation(folder, "BML.transform", "Features")
# 设置类对象的参数,主要是时间片参数
datTran.setParams({
"global":{
"Period": 1,
}
})
# run the data transformation
# 启动转换特征的进程
utils.runJobs(datTran.getJobs(), folder+"transform_jobs") 同样,样品的转化过程也可以通过以下方法进行监测:
$ watch cat dataset/anomaly/GoogleLeak/transform/Features/log_transform_sample.log此外,还可以通过以下方法监测整体的改造进度:
$ watch -n 1 cat dataset/transform_jobs/queue.log
默认情况下,转换的输出保存在样本文件夹中的 json 文件中。该文件的默认名称是:.{tranformation_name}_{period}.json。统计特征主要包括:
| 特征名 | 描述 |
| nb_A | 公告的BGP更新数量 |
| nb_W | 撤回的BGP更新数量 |
| nb_implicit_W | 隐式撤回的BGP更新数量 |
| nb_dup_A | 重复公告的BGP更新数量 |
| nb_dup_W | 重复撤销的BGP更新数量 |
| nb_A_prefix | 公告的前缀数量 |
| nb_W_prefix | 撤回的前缀数量 |
| max_A_prefix | 每个前缀的最大公告数量 |
| avg_A_prefix | 每个前缀的平均公告数量 |
| max_A_AS | 每个 AS 的最大公告数量 |
| avg_A_AS | 每个 AS 的平均公告数量 |
| nb_orign_change | 起源属性(IGP,EGP,不完整)更改。 之前宣布的公告将起源属性进行了改变,进行了一个新的重新声明。 |
| nb_new_A | 未存储在 RIB 中的新宣告数量 |
| nb_new_A_afterW | 在撤回之后重新宣告的数量 |
| max_path_len | 所有消息的最大路径长度 |
| avg_path_len | 所有消息的平均路径长度 |
| max_editdist | 所有消息的最大路径编辑长度 |
| avg_editdist | 所有消息的平均路径编辑长度 |
| editdist_7 | 具有 k 值的编辑距离计算的是与上一条已知路径具有给定 k 距离的信息更新数量。(k=7-17) |
| editdist_8 | |
| editdist_9 | |
| editdist_10 | |
| editdist_11 | |
| editdist_12 | |
| editdist_13 | |
| editdist_14 | |
| editdist_15 | |
| editdist_16 | |
| editdist_17 | |
| nb_tolonger | 与来自于同一个收集器的前一条路径相比,更长/更短的BGP更新消息数量 |
| nb_toshorter | |
| avg_interarrival | 所有消息的平均时间间隔 |
5.图形特征提取
同样,我们也可以提取 BGP 图特征。
# graph features extraction every minute
datTran = DatasetTransformation(folder, "BML.transform", "GraphFeatures")
datTran.setParams({
"global":{
"Period": 1,
}
})
# run the data transformation
utils.runJobs(datTran.getJobs(), folder+"transform_jobs") 图特征主要包括:
| 特征名 | 描述 | 特征含义 |
| algebraic_connectivity | 代数连通性 | 图的代数连通性(Algebraic Connectivity)是一个图论概念,通常用于描述一个图的连通性。具体来说,对于一个给定的图,其代数连通性是该图的拉普拉斯矩阵的最小非零特征值。这个值可以用来衡量图中的连通程度,因为它反映了从一个顶点到达另一个顶点的最短路径长度。代数连通性越大,表示图中顶点间的连接越紧密,图越不容易被分割成两个独立的子图。 |
| assortativity | 同配性 | 图的同配性(Assortativity)是一个度量图中节点性质相似性的指标,通常用于社交网络、生物网络和其它复杂网络的研究。同配性主要考察的是度值相近的节点是否倾向于相互连接。如果度大的节点倾向于与度大的节点相连,那么该网络的度是正相关的,即网络是同配的。如果度大的节点倾向于与度小的节点相连,那么该网络的度是负相关的,即网络是异配的。同配系数是一种基于“度”的皮尔森相关系数,用来度量相连节点对的关系。通常而言,同配系数r的值在-1到+1之间,大于0时网络是同配的,反之是异配的。 |
| nb_of_nodes | 节点数量 | 图的节点数量 |
| nb_of_edges | 边数量 | 图的边数量 |
| diameter | 图的直径 | 图的直径是指任意两个顶点间距离的最大值,也就是图中最长路的长度。在图论中,图的直径是衡量图中的顶点之间平均距离的重要指标,用于描述图中顶点之间的最大距离。 |
| largest_eigenvalue | 最大特征值 | 图的Largest Eigenvalue是指图拉普拉斯矩阵的最大特征值。这个特征值可以用来衡量图的连通性,因为一个图的连通性与其拉普拉斯矩阵的特征值紧密相关。具体来说,如果一个图的Largest Eigenvalue接近于0,那么该图具有较好的连通性,因为它的拉普拉斯矩阵的最小特征值非常小。反之,如果Largest Eigenvalue很大,则该图的连通性较差,因为其最小特征值较大。 |
| effective_graph_resistance | 有效图形阻力 | 图的Effective Graph Resistance(有效图电阻)是另一个用于衡量图连通性的度量,类似于拉普拉斯矩阵的特征值。它通过计算图拉普拉斯矩阵的逆矩阵的元素和,来衡量图中顶点之间的连通性。Effective Graph Resistance的值越小,表示图中顶点之间的连接越紧密,图的连通性越好。与Largest Eigenvalue相比,Effective Graph Resistance能够提供一种更加准确和可靠的度量方式来评估图的连通性。 |
| symmetry_ratio | 对称比 | 在图论中,对称性比率(Symmetry Ratio)是衡量图对称性的一个重要指标。它定义为图中顶点之间的对称边的数量与图中所有可能边的一半之间的比值。如果对称性比率接近于1,则表示图中存在大量对称的边,即图具有高度的对称性。反之,如果对称性比率接近于0,则表示图中没有对称的边,即图没有太多的对称性。对称性比率是一个重要的图属性,在许多领域中都有应用,例如化学结构分析、网络流量分析、社交网络研究等。 |
| natural_connectivity | 自然连通性 | 图的自然连通性(Natural Connectivity)是衡量图连通性的另一个重要指标,用于描述图中顶点之间连接的强度。自然连通性通过图的拉普拉斯矩阵的特征值来定义,具体来说,它是拉普拉斯矩阵的所有非零特征值的平均值。自然连通性的值越大,表示图中顶点之间的连接越强,图的连通性越好。在生态学中,自然连通性被用于描述生态系统中的食物网结构,在社交网络中,自然连通性可以用来衡量网络中个体之间的相互影响程度。 |
| node_connectivity | 节点连接性 | 节点连通性(Node Connectivity)是指通过删除节点的方法使网络从连通状态变成非连通状态的难易程度。它用使网络从连通状态变成非连通状态所要删除的最少节点的数量来表示。 一般来讲,值越大,则网络由连通状态变成非连通状态需要删除的节点数目越大,说明网络的鲁棒性越强。 |
| weighted_spectrum_3 | 加权频谱(3/4) | 图的Weighted Spectrum是指图的权重谱,它是一种描述图结构特征的向量,用于衡量图中的节点和边的权重分布情况。对于一个给定的图,其权重谱可以通过对图中所有节点的权重进行排序并生成相应的频数序列来获得。参数为3的Weighted Spectrum表示在生成频数序列时,将节点按权重大小排序,并取权重排名为3的节点及其权重值。这种参数可以帮助分析图的结构特征,例如节点权重的分布情况、节点间的连接强度等。 |
| weighted_spectrum_4 | ||
| percolation_limit | 渗滤极限 | 渗流阈值(Percolation Threshold)或渗流界限,是数学和物理中的一个概念,通常用于描述多孔介质或随机网络中流体流动的阈值。在这个阈值处,网络中的流体从一部分区域渗流到另一部分区域的能力发生显著变化。在渗流理论中,渗流阈值是一个重要的参数,因为它决定了流体能否从一个节点传播到整个网络。如果一个网络中所有节点之间的连接概率足够高,那么流体可以传播到整个网络,即网络是渗流的。反之,如果连接概率较低,流体无法传播到整个网络,即网络是不渗流的。渗流阈值的存在是网络弹性的重要指标,可以用来衡量网络的连通性和稳定性。 |
| nb_spanning_trees | 生成树数量 | 图的生成树数量(Number of Spanning Trees)是指在一个连通图中,通过添加n-1条边将所有顶点连通所形成的子图的数量。对于一个有n个顶点的连通图,其生成树的数量是n的阶乘除以2(在加法意义下)。这是因为对于每个顶点,我们可以选择将其包含在生成树中,或者不包含在生成树中,所以总共有2^n种选择。但是,由于生成树中包含了n-1条边,我们需要将其中重复计算的部分去除,因此最终的结果是n的阶乘除以2。在实践中,生成树数量通常用于衡量图的连通性和可靠性,以及用于计算最小生成树等算法问题。 |
6. 自定义特征
BML 提供了基础转换对象,我们可以继承这些对象来构建自定义数据转换。在本例中,假设我们要计算在 AS-PATH 中有 Google AS(AS 15169)的区间内收到的公告数量。我们在名为 :GoogleRoutes.py 的文件中实现数据转换。
from BML.transform import BaseTransform
class GoogleRoutes(BaseTransform):
computeRoutes = False
def transforms(self, index, routes, updates):
n = 0
for update in updates:
if update["type"]=='A':
if "15169" in update["fields"]["as-path"]:
n += 1
return(n)然后,我们就可以像任何数据转换一样使用它:
# custom data transformation every minute
datTran = DatasetTransformation(folder, "GoogleRoutes", "GoogleRoutes")
datTran.setParams({
"global":{
"Period": 1,
}
})
# run the data transformation
utils.runJobs(datTran.getJobs(), folder+"transform_jobs") 7. 打印特征图像
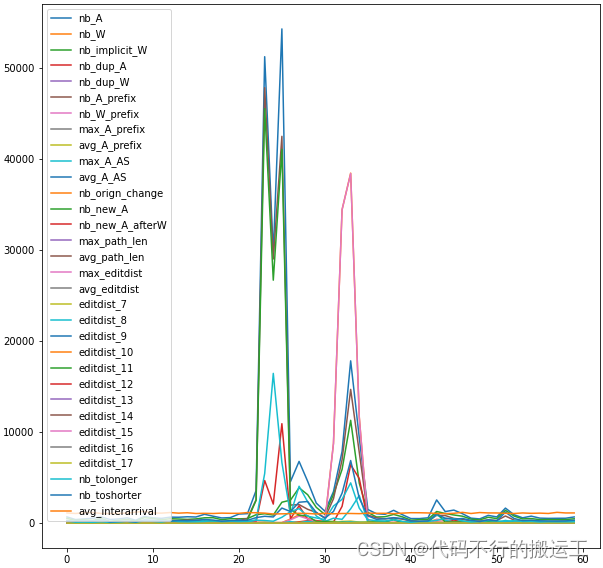
数据可以很容易地在 python 中加载和可视化:
import pandas as pd
data = pd.read_json(folder+"anomaly/GoogleLeak/transform/Features/Features_1.json")
data.plot(figsize=(10,10))输出图像为:
自定义函数的图像输出是一样的:
import pandas as pd
data = pd.read_json(folder+"anomaly/GoogleLeak/transform/GoogleRoutes/GoogleRoutes_1.json")
data.plot(figsize=(5,5))



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









