




在集合通信中,“逻辑节点” 和 “逻辑链路” 是对物理硬件的抽象映射,核心作用是屏蔽底层硬件差异(如 GPU / 服务器型号、物理拓扑),让通信算法更通用;而算法实施和资源调度则由集合通信库(如 NCCL、OpenMPI) 主导,配合集群调度系统、AI 框架完成协同。
一、先搞懂:逻辑节点 vs 逻辑链路(抽象 vs 物理)
可以把集合通信的 “逻辑层” 理解为 “快递物流的电子调度系统”—— 物理硬件是 “仓库、货车、公路”,逻辑层是 “物流 APP 里的虚拟节点、虚拟路线”,不关心具体硬件,只关注 “谁和谁通信、走什么路径”。
1. 逻辑节点:通信的 “虚拟参与方”
- 定义:将参与集合通信的物理设备(如单张 GPU、单台服务器、单个 CPU 核心)抽象为 “统一的虚拟节点”,用唯一标识(
rank)区分(如 rank=0、rank=1、…、rank=N-1)。 - 通俗类比:快递物流中,每个 “仓库”“配送站” 被抽象为 APP 里的 “发货点”“收货点”,不管仓库是大是小、在哪个城市,APP 只认 “虚拟节点 ID”。
- 核心作用:
- 屏蔽硬件差异:不管是本地 GPU、远程服务器,还是不同厂商的芯片,在逻辑层都是 “平等的节点”,通信算法无需修改即可适配;
- 简化通信管理:集合通信库通过
rank管理节点,比如AllReduce只需知道 “所有 rank 参与聚合”,无需关心每个 rank 对应哪台硬件。
- 举例:8 台服务器、每台 8 张 GPU(共 64 卡)的集群,逻辑节点就是
rank=0到rank=63,每个rank对应一张 GPU(物理设备);若按服务器分组,也可将每台服务器抽象为一个逻辑节点(rank=0到rank=7),用于跨服务器的上层通信。
2. 逻辑链路:节点间的 “虚拟通信通道”
- 定义:将两个逻辑节点之间的物理通信路径(如 NVLink、PCIe、InfiniBand)抽象为 “虚拟链路”,只关注 “链路带宽、延迟” 等逻辑属性,不关心底层物理介质。
- 通俗类比:快递物流中,“北京仓库→上海仓库” 的虚拟路线(逻辑链路),可能对应实际的 “公路运输” 或 “航空运输”(物理路径),APP 只显示 “预计时效、运费”(逻辑属性),不关心具体走哪条公路、哪个航班。
- 核心作用:
- 抽象物理路径:逻辑链路屏蔽了 “是 NVLink 还是 InfiniBand”“是否跨 NUMA 节点” 等细节,通信算法只需基于 “链路带宽 / 延迟” 选择最优策略;
- 简化路径规划:集合通信库通过逻辑链路构建 “虚拟拓扑”(如逻辑全互联、逻辑环形),无需感知物理拓扑的复杂性。
- 举例:
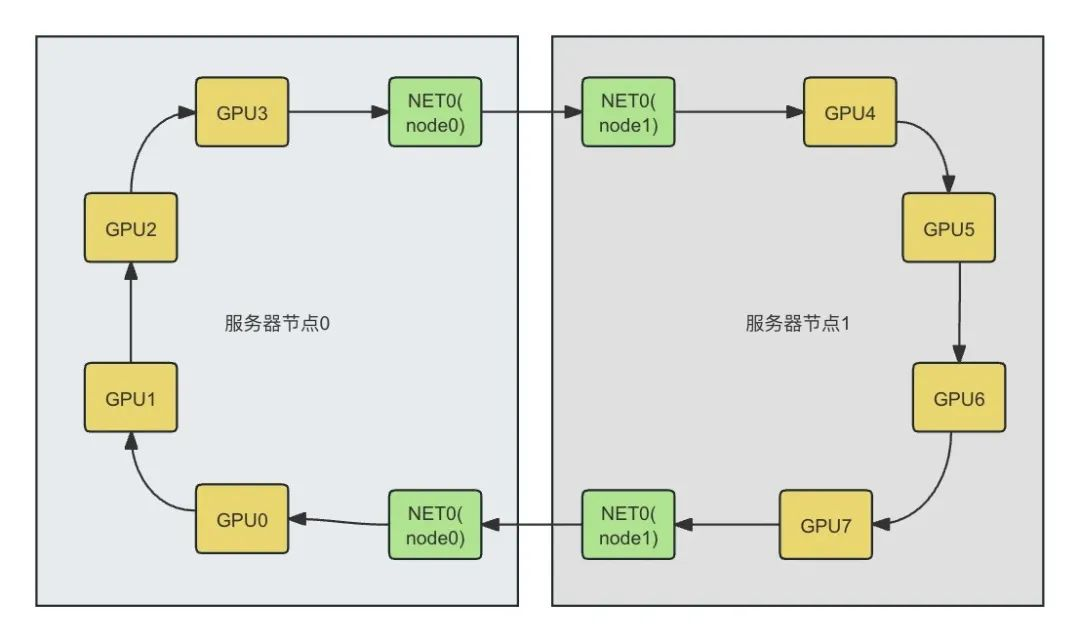
rank=0(GPU0)和rank=1(GPU1)的逻辑链路,底层可能是 NVLink(物理路径 1)或 PCIe(物理路径 2),集合通信库会自动检测物理路径的带宽(如 NVLink 900GB/s、PCIe 128GB/s),并将该带宽作为逻辑链路的属性,用于算法选择(如优先用 NVLink 的逻辑链路传输)。
二、谁来负责?算法实施与资源调度的 “分工体系”
集合通信的核心是 “高效协同”,算法实施(如 AllReduce 怎么算)和资源调度(如用哪条链路、哪个 CPU 核心)由集合通信库、集群调度系统、AI 框架三层分工负责,底层硬件提供支撑,开发者无需干预:
1. 核心执行者:集合通信库(如 NCCL、OpenMPI)
集合通信库是 “算法实施 + 资源调度的核心”,相当于 “物流调度中心”,负责最关键的逻辑实现:
-
① 算法实施:定义集合通信的 “执行逻辑”
- 封装核心算法:实现 AllReduce、Broadcast 等原语的具体逻辑,比如 AllReduce 的 “分层聚合算法”(先单机内聚合,再跨机聚合)、“环形算法”(节点按环形传递数据);
- 自适应算法选择:根据逻辑链路的带宽 / 延迟、逻辑节点数量,自动选择最优算法。例如:
- 小规模节点(8 卡):用 “全互联算法”(逻辑链路全连通,延迟最低);
- 大规模节点(64 卡):用 “树形算法”(逻辑链路分层,扩展性强);
- 小包传输:用 “UD 模式”(逻辑链路无连接,开销低);
- 大包传输:用 “RC 模式”(逻辑链路可靠连接,无丢包)。
-
② 资源调度:分配物理资源,优化通信路径
- 物理资源映射:将逻辑节点映射到物理设备(如
rank=0→GPU0),逻辑链路映射到物理路径(如rank0-rank1逻辑链路→NVLink 物理路径); - 拓扑感知与路径优化:自动检测物理拓扑(如 GPU 互联方式、NUMA 节点、网络结构),优化逻辑链路与物理路径的映射。例如:
- NCCL 会检测 GPU 是否通过 NVLink 连接,优先将相邻
rank映射到 NVLink 互联的 GPU,让逻辑链路对应高带宽物理路径; - 避免跨 NUMA 节点:将逻辑节点
rank=0(GPU0)映射到 NUMA Node0,对应的 RDMA 网卡也在 Node0,确保逻辑链路的物理路径不跨节点,降低延迟;
- NCCL 会检测 GPU 是否通过 NVLink 连接,优先将相邻
- 硬件资源分配:调度 PCIe 带宽、网卡队列、CPU 核心等资源。例如:
- 为 RDMA 通信分配独立的网卡队列(避免队列冲突);
- 将通信库的中断处理绑定到空闲 CPU 核心(减少 CPU 开销)。
- 物理资源映射:将逻辑节点映射到物理设备(如
2. 上层调度者:集群调度系统(如 Slurm、K8s)
集群调度系统是 “资源分配的上层管理者”,相当于 “物流园区的管理员”,负责为集合通信分配 “物理资源池”:
- 节点与设备调度:接收用户任务(如 “用 64 张 GPU 训练模型”),分配物理节点(服务器)和设备(GPU、RDMA 网卡),并将这些物理资源映射为逻辑节点(
rank); - 资源隔离与配额:为不同任务分配独立的 GPU、网络带宽,避免多个集合通信任务争抢资源(如 Task1 用 GPU0-7,Task2 用 GPU8-15);
- 容错与故障转移:若某物理节点(服务器)故障,自动将对应的逻辑节点迁移到其他物理节点,确保集合通信继续执行。
3. 接口封装者:AI 框架(如 PyTorch、TensorFlow)
AI 框架是 “开发者与通信库的桥梁”,相当于 “物流 APP”,负责简化调用,无需开发者关注底层:
- 封装通信库 API:将 NCCL/OpenMPI 的底层接口(如
ncclAllReduce)封装为高层接口(如torch.distributed.all_reduce),开发者一行代码即可调用; - 逻辑节点管理:自动初始化逻辑节点(
rank)、通信组(group),比如 PyTorch DDP 会为每张 GPU 分配唯一rank,并创建全局通信组; - 与调度系统协同:对接 Slurm/K8s,获取分配的物理资源(如 GPU 数量、节点 IP),并传递给集合通信库,实现 “任务提交→资源分配→通信初始化” 的自动化。
4. 底层支撑者:硬件与驱动(GPU、网卡、驱动)
硬件是 “物理基础”,驱动是 “硬件与软件的桥梁”,为算法实施和资源调度提供支撑:
- 硬件提供通信能力:GPU 的 NVLink、RDMA 网卡的 InfiniBand、PCIe Switch 等,提供物理通信路径和带宽;
- 驱动提供抽象接口:GPU 驱动(如 CUDA Driver)、网卡驱动(如 MLNX_OFED)将硬件能力抽象为标准接口,让集合通信库能识别物理资源(如 GPU 显存地址、网卡队列)。
三、逻辑图解释
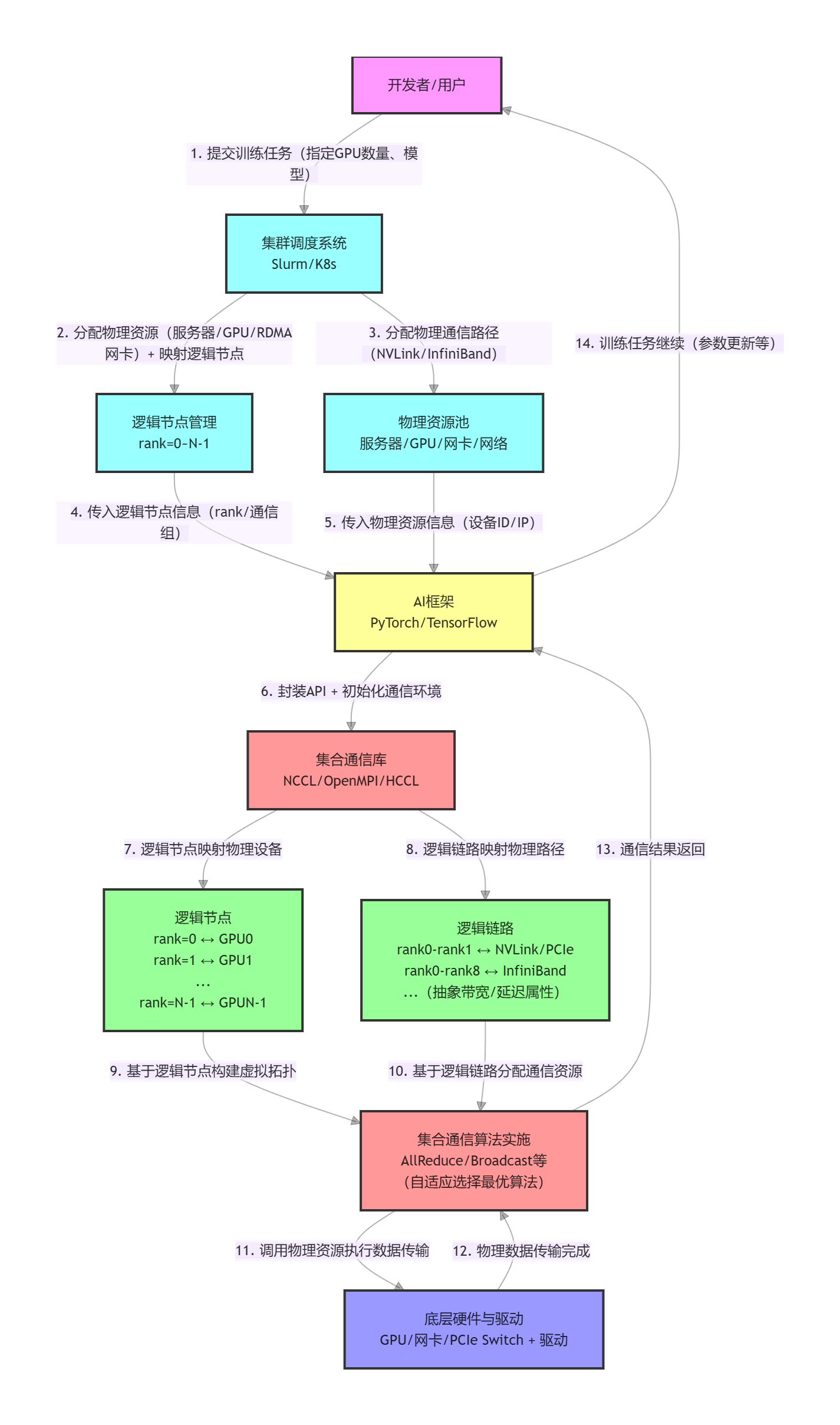
1. 层级关系(从上层到下层):
- 用户层:发起任务请求(如 “用 64 卡训练大模型”);
- 调度层:Slurm/K8s 负责 “分配物理资源 + 映射逻辑节点”,是资源的 “管理者”;
- 框架层:PyTorch 封装接口,是用户与通信库的 “桥梁”;
- 通信层:集合通信库是核心,负责 “逻辑与物理的映射 + 算法实施 + 资源调度”;
- 硬件层:提供物理通信能力(GPU / 网卡 / 网络),是底层支撑。
2. 核心交互逻辑:
- 逻辑节点 / 链路是集合通信库的 “抽象工具”:屏蔽物理硬件差异,让算法能通用适配不同集群;
- 集合通信库是 “核心执行者”:一边对接 AI 框架的高层调用,一边映射到底层物理资源,自动完成算法选择和资源分配;
- 数据流向:用户任务 → 调度分配 → 框架封装 → 通信库执行(逻辑→物理映射) → 硬件传输 → 结果反馈。
3. 关键标注:
- 逻辑节点(D1):1:1 映射物理 GPU(或服务器),用
rank标识; - 逻辑链路(D2):抽象物理路径(NVLink/InfiniBand 等),只关注带宽 / 延迟;
- 集合通信库(D):是逻辑与物理的 “转换器”,也是算法实施和资源调度的核心。
三、完整流程示例:64 卡 GPU 集群执行 AllReduce 的分工
以 “64 张 GPU(8 台服务器,每台 8 卡)用 NCCL 执行 AllReduce 梯度同步” 为例,看各角色的分工:
-
集群调度系统(Slurm):
- 接收任务:用户提交 “用 64 张 GPU 训练” 的任务,Slurm 分配 8 台服务器(物理节点),每台服务器 8 张 GPU;
- 资源映射:将 64 张 GPU 映射为逻辑节点
rank=0-rank=63,并将节点 IP、GPU 编号等信息传递给 AI 框架。
-
AI 框架(PyTorch):
- 初始化通信:调用
torch.distributed.init_process_group(backend='nccl'),启动 NCCL 通信库; - 创建通信组:创建全局通信组(包含
rank=0-rank=63),并将本地梯度张量传递给 NCCL。
- 初始化通信:调用
-
集合通信库(NCCL):
- 逻辑链路构建:检测每对
rank的物理路径(如单机内 GPU 用 NVLink,跨机用 InfiniBand),构建逻辑链路,并记录链路带宽 / 延迟; - 算法选择:根据逻辑节点数量(64)和逻辑链路属性,选择 “分层 AllReduce 算法”(先单机内聚合,再跨机聚合);
- 资源调度:为单机内聚合分配 NVLink 链路,为跨机聚合分配 InfiniBand 链路,并绑定空闲 CPU 核心处理通信中断;
- 算法实施:执行 AllReduce 逻辑 —— 单机内 8 张 GPU 通过 NVLink 聚合梯度(
rank0-7→服务器 1 梯度),8 台服务器通过 InfiniBand 聚合全局梯度,再将结果分发到每个rank。
- 逻辑链路构建:检测每对
-
硬件与驱动:
- GPU 驱动提供 GPU 显存地址映射,让 NCCL 能直接访问梯度数据;
- RDMA 网卡驱动提供 InfiniBand 通信接口,实现跨机数据传输。
四、核心总结
- 逻辑节点 / 链路:是集合通信对物理硬件的抽象,核心价值是 “屏蔽差异、简化算法”,让通信库无需关注具体硬件,专注于高效协同;
- 分工体系:
- 集合通信库(NCCL/OpenMPI):核心执行者,负责算法实施(原语逻辑)和资源调度(路径 / 硬件分配);
- 集群调度系统(Slurm/K8s):上层管理者,负责分配物理资源池;
- AI 框架(PyTorch):接口封装者,简化开发者调用;
- 开发者视角:无需关心逻辑节点 / 链路的细节,也无需干预算法和调度,只需通过 AI 框架调用
all_reduce等接口,底层会自动优化。
对于科研场景,管理员已提前优化通信库(如 NCCL 拓扑感知)和调度系统(如 Slurm 资源配额),开发者只需专注于模型训练,无需手动配置底层逻辑。

















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









