







 本案例基于《利用Python进行数据分析·第2版》,详述如何分析1880年至2010年间的全美婴儿姓名数据。流程包括数据整合、聚合作图、比例分析、命名趋势探讨、命名多样性的评估以及名字末尾字母比例变化和特定名称在性别中的分布等。
本案例基于《利用Python进行数据分析·第2版》,详述如何分析1880年至2010年间的全美婴儿姓名数据。流程包括数据整合、聚合作图、比例分析、命名趋势探讨、命名多样性的评估以及名字末尾字母比例变化和特定名称在性别中的分布等。
**一:介绍**
该案例来自《利用Python进行数据分析·第2版》,主要对1880-2010年间全美婴儿姓名进行分析。
二:分析流程
1:读取数据:因为一个年份有一张表,将所有的表信息合成一张以便后续分析。
years = range(1880,2011)
piece = []
columns = ['name','sex', 'births']
将每年的文件转为DataFrame
for year in years:
path = 'C:/Users/17322/Desktop/datasets/babynames/yob%d.txt' %year
frame = pd.read_csv(path, names=columns)
frame['year']= year
piece.append(frame)
合成一张
names = pd.concat(piece, ignore_index=True)
2:利用映射表进行聚合作图
total_births = names.pivot_table('birth',index = 'year', columns = 'sex',aggfunc='sum')
total_births.plot(title = 'Total births per year')

3:分析放指定名字的婴儿数相对于总出生数的比例
- 添加proportion列
def add_prop(group):
group['prop'] = group.birth / group.birth.sum()
return group
names = names.groupby(['year','sex']).apply(add_prop)
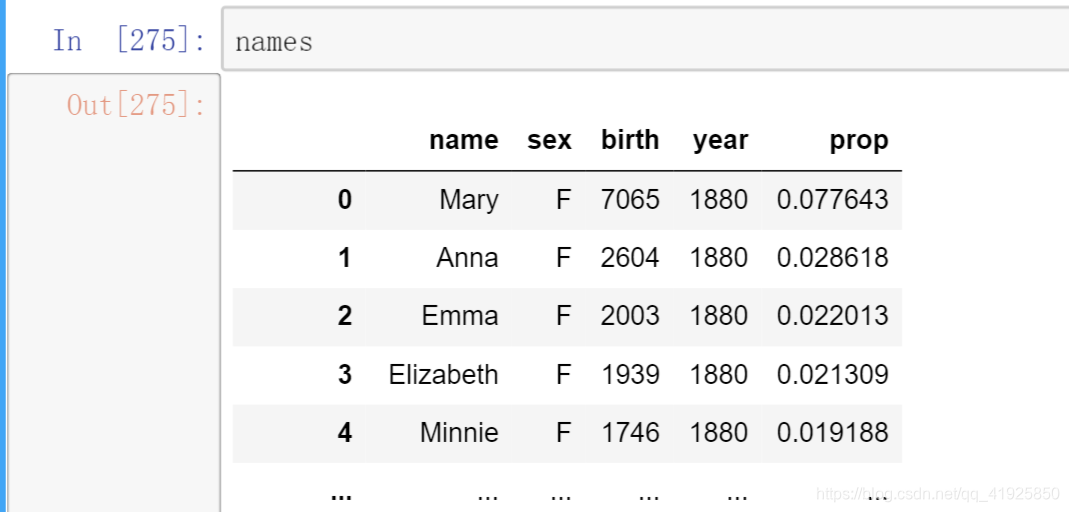
4:取子集:取出每个group前n列
def get_n(group,n):
return group. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 66
66

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









