







11.1 打开和关闭文件
- 文本文件一般由单一特定编码的字符组成,如UTF-8编码。
- 二进制文件直接由比特0和比特1组成,没有统一字符编码,文件内部数据的组织格式与文件用途有关。例:.png图像
- 二进制文件由于没有统一的编码,只能当做字节流,不能看作字符串。
- 二进制文件和文本文件最主要的区别在于是否有统一的字符编码。
- 无论文件创建为文本文件或者二进制文件,都可以用“文本文件方式”和“二进制文件方式”打开,打开后的操作不同。
11.1 打开文件
要打开文件,可使用函数open,它位于自动导入的模块io中。函数open将文件名作为唯一必不可少的参数,并返回一个文件对象。
file object = open(file_name [, access_mode][, buffering])
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见之后的完全列表。这个参数是非强制的,默认文件访问模式为只读®。
Buffering:如果buffering的值被设为0,就不会有缓冲。如果buffering的值取1,访问文件时会缓冲一行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
f = open('somefile.txt')
如果文件位于其他地方,可指定完整的路径。如果指定的文件不存在,将看到类似于下面的异常:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileNotFoundError: [Errno 2] No such file or directory: 'somefile.txt'
文件模式

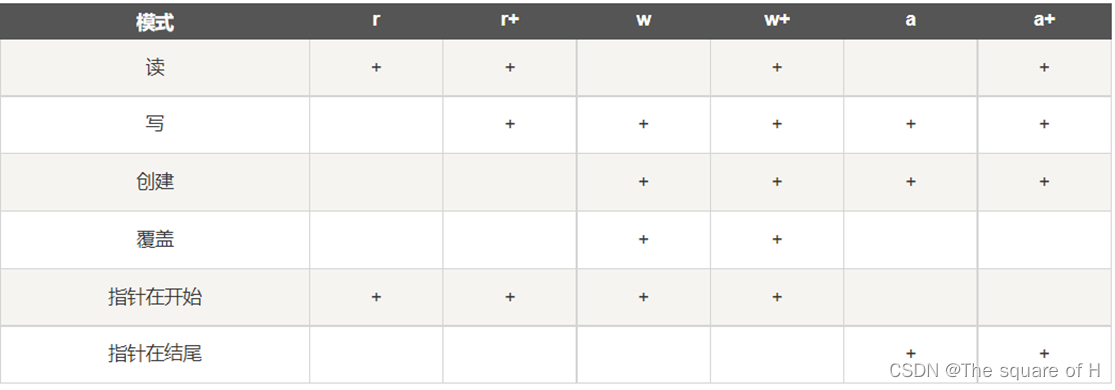
- ’ r’、‘w’、‘x’、‘a’可以和’b’、‘t’、'+'组合使用,形成既表达读写又表达文件模式的方式。
- 默认模式为’rt’,这意味着将把文件视为经过编码的Unicode文本,因此将自动执行解码和编码,且默认使用UTF-8编码。要指定其他编码和Unicode错误处理策略,可使用关键字参数encoding和errors。
- 通常,Python使用通用换行模式。在这种模式下,后面将讨论的readlines等方法能够识别所有合法的换行符(‘\n’、‘\r’和’\r\n’)。如果要使用这种模式,同时禁止自动转换,可将关键字参数newline设置为空字符串,如open(name,
newline=‘’)。如果要指定只将’\r’或’\r\n’视为合法的行尾字符,可将参数newline设置为相应的行尾字符。这样,读取时不会对行尾字符进行转换,但写入时将把’\n’替换为指定的行尾字符。
11.1.2 Python对文件的操作步骤
Python对文本文件和二进制文件采用统一的操作步骤,即“打开–操作–关闭”。
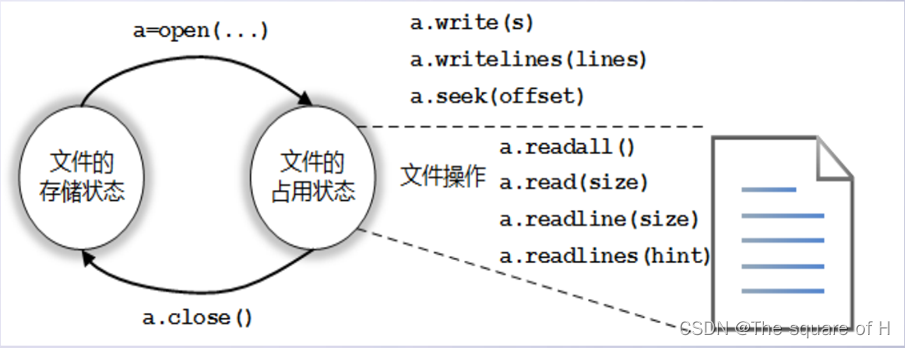
操作系统中的系统默认处于存储状态,需要先打开文件,使得当前程序有权操作这个文件,打开不存在的文件可以创建文件。打开后的文件处于占用状态,操作后需要将文件关闭,关闭将释放对文件的控制使文件恢复存储状态。
11.1.3 关闭文件
文件使用结束后要用close()方法关闭,释放文件的使用授权。若不关闭,则文件一直处于打开状态。
使用方法:<变量名>.close()
例:
binFile = open(“somefile.txt","rb")#b表示二进制文件方式
binFile.close()
实际上,有一条专门为此设计的语句,那就是with语句。
with open("somefile.txt") as somefile:
do_something(somefile)
with语句让你能够打开文件并将其赋给一个变量(这里是somefile)。在语句体中,你将数据写入文件(还可能做其他事情)。到达该语句末尾时,将自动关闭文件,即便出现异常亦如此。
11.1.4 with语句
with open("somefile.txt") as somefile:
do_something(somefile)
- 上下文管理器:实现了__enter__()和__exit__()两个特殊方法的对象,它们用于定义在with语句中资源的获取和释放行为
- enter():在with语句块执行前调用,负责获取资源并返回资源对象
- exit():在with语句块执行完毕后调用,负责释放资源。
- 上下文管理器可以用于确保资源的正确打开和关闭,以及在出现异常时执行清理操作。
- 文件也可用作上下文管理器。它们的方法__enter__返回文件对象本身,而方法__exit__关闭文件。
11.2 文件的基本方法
11.2.1 读取和写入
使用f.write来写入数据,还可使用f.read来读取数据
#文件的写
f = open('somefile.txt', 'w')
f.write('Hello, ')
f.write('World!')
f.close()
#文件的读
f = open('somefile.txt', 'r')
print(f.read(4))
print(f.read())
#运行结果
Hell
o, World!
11.2.2 随机存取
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
#随机存取
f = open('somefile.txt', 'w')
f.write('01234567890123456789')
f.seek(5)
f.write('Hello, World!')
f.close()
with open("somefile.txt") as somefile:
print(somefile.read())
#运行结果
01234Hello, World!89
with open('somefile.txt') as f:
print(f.read(3))
print(f.read(2))
print(f.tell())
#运行结果
012
34
5
11.2.3 读取和写入行
要读取一行(从当前位置到下一个分行符的文本),可使用方法readline。可提供一个非负整数,指定readline最多可读取多少个字符。
#readline()
with open('somefile.txt') as f:
print(f.readline())
f.seek(0)
print(f.readline(5))
#运行结果
01234Hello, World!89
01234
要读取文件中的所有行,并以列表的方式返回它们,可使用方法readlines。
方法writelines与readlines相反:接受一个字符串列表(实际上,可以是任何序列或可迭代对象),并将这些字符串都写入到文件(或流)中。请注意,写入时不会添加换行符,因此你必须自行添加。另外,没有方法writeline,因为可以使用write。
11.2.4 文件基本方法代码示例
#somefile1.txt中的内容如下
Welcome to this file
isn't a
This stupid haiku
#read(n)
f = open('somefile1.txt')
print(f.read(7))
print(f.read(4))
f.close()
#运行结果
Welcome
to
#read()
f = open('somefile1.txt')
print(f.read())
f.close()
#运行结果
Welcome to this file
isn't a
This stupid haiku
#readline()
f = open('somefile1.txt')
for i in range(3):
print(str(i) + ': ' + f.readline(), end='')
f.close()
#运行结果
0: Welcome to this file
1: isn't a
2: This stupid haiku
# pprint是 Python 标准库中的一个模块,用于将 Python 对象以一种可读性更高的格式打印出来。
# 这个函数可以将任意的 Python 对象打印成易于阅读的格式。
#readlines()
import pprint
pprint.pprint(open('somefile1.txt').readlines())
#运行结果
['Welcome to this file \n', "isn't a\n", 'This stupid haiku\n']
#write()
f = open('somefile1.txt','w+')
f.write('this\nis no\nhaiku')
f.seek(0)
print(f.read())
f.close()
#运行结果
this
is no
haiku
#writelines(list)
f = open('somefile1.txt')
lines = f.readlines()
f.close()
lines[1] = "isn't a\n"
f = open('somefile1.txt', 'w')
f.writelines(lines)
f.close()
f= open('somefile1.txt')
print(f.read())
f.close()
#运行结果
this
isn't a
haiku
11.3 迭代文件内容
11.3.1 每次迭代一个字符(或字节)
#每次迭代一个字符(或字节)
with open('somefile1.txt') as f:
char = f.read(1)
while char:
print(char,end='')
char = f.read(1)
#运行结果
this
isn't a
haiku
这个程序之所以可行,是因为到达文件末尾时,方法read将返回一个空字符串,但在此之前,返回的字符串都只包含一个字符(对应于布尔值True)。只要char为True,你就知道还没结束。
# 每次迭代一个字符(或字节)改进版
with open('somefile1.txt') as f:
while True:
char = f.read(1)
if not char:
break
print(char,end='')
#运行结果
this
isn't a
haiku
11.3.2 每次一行
处理文本文件时,你通常想做的是迭代其中的行,而不是每个字符。通过使用方法readline,可像迭代字符一样轻松地迭代行。
#每次一行
with open('somefile1.txt') as f:
while True:
line = f.readline()
if not line:
break
print(line,end='')
#运行结果
this
isn't a
haiku
11.3.3 读取所有内容
如果文件不太大,可一次读取整个文件;为此,可使用方法read并不提供任何参数(将整个文件读取到一个字符串中),也可使用方法readlines(将文件读取到一个字符串列表中,其中每个字符串都是一行)
#读取所有内容
with open('somefile1.txt') as f:
for char in f.read():
print(char,end='')
#运行结果
this
isn't a
haiku
with open('somefile1.txt') as f:
for line in f.readlines():
print(line,end='')
#运行结果
this
isn't a
haiku
11.3.4 文件迭代器
文件实际上是可迭代的,这意味着可在for循环中直接使用它们来迭代行。
#迭代文件
with open('somefile1.txt') as f:
for line in f:
print(line,end='')
#运行结果
this
isn't a
haiku
#在不将文件对象赋给变量的情况下迭代文件
for line in open('somefile1.txt'):
print(line,end='')
#运行结果
this
isn't a
haiku
另外,可对迭代器做的事情基本上都可对文件做,如(使用list(open(filename)))将其转换为字符串列表,其效果与使用readlines相同。
f = open('somefile2.txt', 'w')
print('First', 'line', file=f)
print('Second', 'line', file=f)
print('Third', 'and final', 'line', file=f)
f.close()
lines = list(open('somefile2.txt'))
print(lines)
first, second, third = open('somefile2.txt')
print(first,end='')
print(second,end='')
print(third,end='')
#运行结果
['First line\n', 'Second line\n', 'Third and final line\n']
First line
Second line
Third and final line
- 使用了print来写入文件,这将自动在提供的字符串后面添加换行符。
- 对打开的文件进行序列解包,从而将每行存储到不同的变量中。
11.4 小结



















 2517
2517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











