










🤗 PEFT(参数高效微调)是由Huggingface团队开发的开源框架,专为大型预训练模型(如GPT、LLaMA、T5等)设计,用于高效地将大型预训练模型适配到各种下游应用,而无需对模型的所有参数进行微调,因为微调成本过高。PEFT 方法仅微调少量(额外的)模型参数,从而显著降低计算和存储成本,同时获得与完全微调模型相当的性能。这使得在消费级硬件上训练和存储大型语言模型 (LLMs) 变得更加容易。
一、介绍与安装
1、作用
-
降低计算与存储成本
PEFT通过冻结大部分预训练参数,仅调整少量新增或特定层参数(如低秩矩阵、适配器模块),可将训练参数量缩减至原模型的0.1%-1%。例如,微调12B参数的模型时,显存需求从80GB降至18GB,模型保存文件仅需几MB。 -
缓解灾难性遗忘
传统全参数微调可能覆盖预训练阶段学到的通用知识,而PEFT通过保留主体参数,使模型在适应新任务时仍保持原有能力。 -
支持多任务适配
PEFT允许在同一模型中集成多种任务的适配器(Adapter),例如LoRA或Prefix Tuning,实现灵活的多任务学习。
2、支持的高效微调方法
-
LoRA(低秩适应):通过向权重矩阵添加低秩分解的增量矩阵(如秩r=8)进行微调,适用于文本生成、分类等任务。
-
Prefix Tuning/Prompt Tuning:在输入层添加可学习的连续提示(Prompt),引导模型输出,适合少样本学习。
-
AdaLoRA:动态调整低秩矩阵的秩,增强复杂任务(如多领域适应)的灵活性。
-
IA3:通过向量缩放激活层参数,在少样本场景下性能超越全参数微调。
3、技术优势
- 生态友好
无缝对接Transformers、Accelerate等库,支持分布式训练与混合精度计算,简化部署流程。 - 性能无损
实验表明,PEFT微调后的模型性能与全参数微调相当,甚至在某些少样本任务中表现更优。 - 存储高效
适配器文件体积小(如LoRA的adapter_model.bin仅几MB),便于共享与版本管理。
4、安装
- 方式一:从 PyPI 安装🤗PEFT
pip install peft
- 方式二:Source
pip install git+https://github.com/huggingface/peft
二、微调大模型DeepSeek-R1-Distill-Qwen-1.5B
1、使用modelscope 下载数据集和模型
- 下载数据集
#数据集下载
!modelscope download --dataset himzhzx/muice-dataset-train.catgirl --local_dir ./data
- 下载模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download("deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",cache_dir='./models')
2、改造数据集
由于 transformers 的 Trainer 训练器默认 接收的的数据集格式化为 :
{
'input_ids':'xxx',
'attention_mask':'xxx',
'labels':'xxx',
}
需要对上述下载的数据集进行改造,改造代码如下:
#数据集处理
class Mydata(Dataset):
def __init__(self, tokenizer, max_len = 255):
with open("./data/muice-dataset-train.catgirl.json", 'r', encoding='utf-8') as f:
self.json_data = json.load(f)
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.json_data)
def __getitem__(self, index):
data = self.json_data[index]
question = data['instruction']
answener = data['output']
q = self.tokenizer.apply_chat_template(
[{'role':'user','content':question}],
tokenize = False,
add_generation_prompt = True
)
q_input_ids = self.tokenizer.encode(q)
a_input_ids = self.tokenizer.encode(answener)
input_ids = q_input_ids + a_input_ids
attention_mask = [1]*len(input_ids)
labels = [-100]*len(q_input_ids) + a_input_ids
if len(input_ids) > self.max_len:
input_ids = input_ids[:self.max_len]
attention_mask = attention_mask[:self.max_len]
labels = labels[:self.max_len]
else:
padding_len = self.max_len - len(input_ids)
input_ids = input_ids + [self.tokenizer.pad_token_id] * padding_len
attention_mask = attention_mask + [0]*padding_len
labels = labels + [-100]*padding_len
return {
'input_ids':torch.tensor(input_ids, dtype=torch.long),
'attention_mask':torch.tensor(attention_mask, dtype=torch.long),
'labels':torch.tensor(labels, dtype=torch.long)
}
dataset = Mydata(tokenizer)
# dataset[0]
train_data = DataLoader(dataset, batch_size=32, shuffle=True)
for i in train_data:
print(i)
break
3、配置 Lora 参数
#配置 lora 参数
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
task_type=TaskType.CAUSAL_LM,
target_modules=['q_proj','v_proj','k_proj', 'o_proj']
)
#将 lora 与原始模型 合并在一起
lora_model = get_peft_model(model, lora_config)
#打印模型总参数,以及可训练参数和占比
lora_model.print_trainable_parameters()
4、开始训练
#配置训练参数
output_dir = './lora/train'
train_arg = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
num_train_epochs=3,
logging_steps=10,
save_steps=500,
learning_rate=2e-5,
save_total_limit=2,
fp16=False,
report_to="none"
)
#创建Trainer
trainer = Trainer(
model=lora_model,
args=train_arg,
train_dataset=dataset,
processing_class=tokenizer
)
#开始训练
trainer.train()
训练过程:
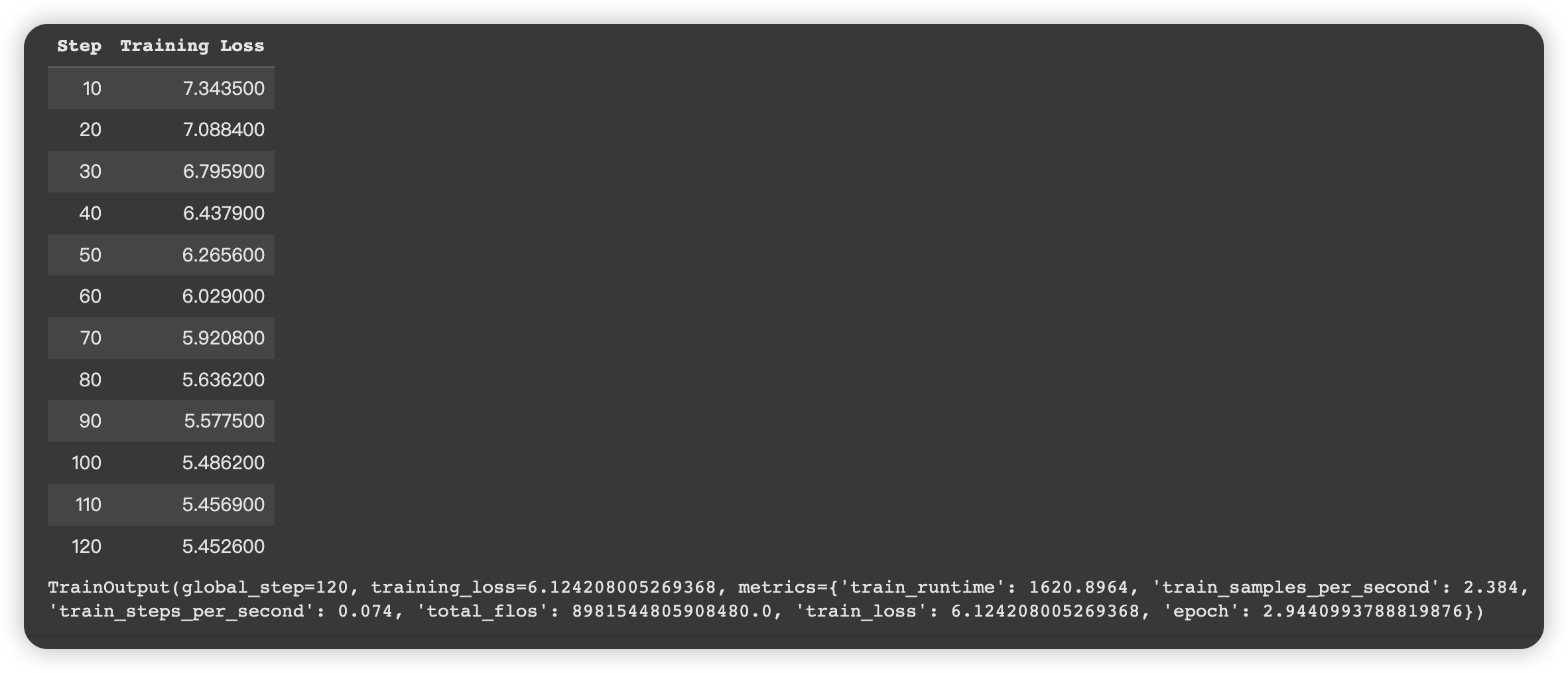
5、模型保存
#将 lora 权重合并到 基础模型上
merge_model = lora_model.merge_and_unload() #合并
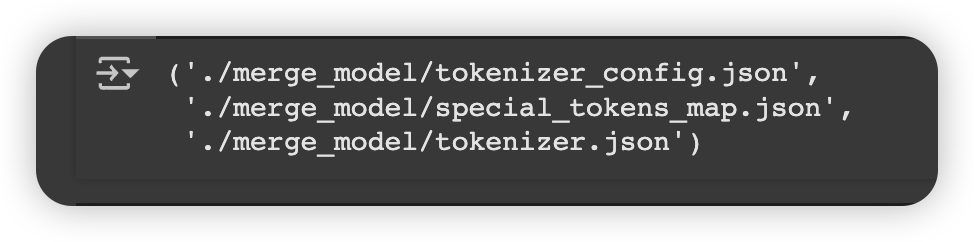
merge_model.save_pretrained("./merge_model") #保存
tokenizer.save_pretrained("./merge_model") #保存


















 3597
3597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











