







什么是分布式事务 ?
- 对于分布式系统而言,需要保证分布式系统中的数据一致性,保证数据在子系统中始终保持一致,避免业务出现问题
- 分布式系统中对数要么一起成功,要么一起失败,必须是一个整体性的事务
- 分布式事务指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上
- 简单的说,在分布式系统上一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务节点上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败
- 典型的分布式事务场景
- 跨库事务
- 跨库事务指的是,一个应用某个功能需要操作多个库,不同的库中存储不同的业务数据。笔者见过一个相对比较复杂的业务,一个业务中同时操作了9个库
- 分库分表
- 通常一个库数据量比较大或者预期未来的数据量比较大,都会进行水平拆分,也就是分库分表
- 微服务化
- 需要保证这些跨服务的对多个数据库的操作要不都成功,要不都失败,实际上这可能是最典型的分布式事务场景
- 跨库事务
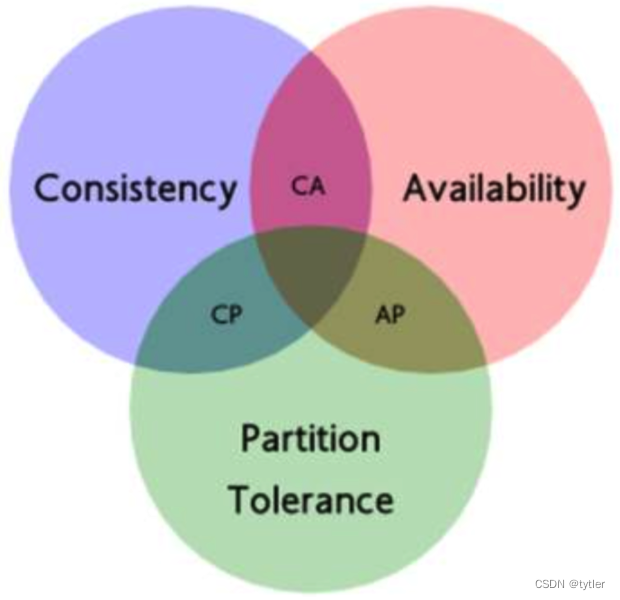
CAP定理
- 分布式事务的理论基础
- 数据库事务 ACID 四大特性,无法满足分布式事务的实际需求,这个时候又有一些新的大牛提出一些新的理论
- CAP定理
- 一致性(Consistency):客户端知道一系列的操作都会同时发生(生效)
- 可用性(Availability):每个操作都必须以可预期的响应结束
- 分区容错性(Partition tolerance):即使出现单个组件无法可用,操作依然可以完成
- 一致性
- 数据一致性指 “all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,不能存在中间状态
- 分布式环境中,一致性是指多个副本之间能否保持一致的特性,在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处理一致的状态
- 例如对于电商系统用户下单操作,库存减少、用户资金账户扣减、积分增加等操作必须在用户下单操作完成后必须是一致的;不能出现类似于库存已经减少,而用户资金账户尚未扣减,积分也未增加的情况;如果出现了这种情况,那么就认为是不一致的
- 数据一致性分为强一致性、弱一致性、最终一致性
- 如果的确能像上面描述的那样时刻保证客户端看到的数据都是一致的,那么称之为强一致性
- 如果允许存在中间状态,只要求经过一段时间后,数据最终是一致的,则称之为最终一致性
- 如果允许存在部分数据不一致,那么就称之为弱一致性
- 可用性
- 系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果
- 两个度量的维度:
- 有限时间内
- 对于用户的一个操作请求,系统必须能够在指定的时间(响应时间)内返回对应的处理结果,如果超过了这个时间范围,那么系统就被认为是不可用的。即这个响应时间必须在一个合理的值内,不让用户感到失望
- 试想,如果一个下单操作,为了保证分布式事务的一致性,需要10分钟才能处理完,那么用户显然是无法忍受的
- 返回正常结果
-
要求系统在完成对用户请求的处理后,返回一个正常的响应结果;正常的响应结果通常能够明确地反映出对请求的处理结果,即成功或失败,而不是一个让用户感到困惑的返回结果;比如返回一个系统错误如 OutOfMemory,则认为系统是不可用的
-
“返回结果” 是可用性的另一个非常重要的指标,它要求系统在完成对用户请求的处理后,返回一个正常的响应结果,不论这个结果是成功还是失败
-
- 有限时间内
- 系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果
- 分区容错性
- 即分布式系统在遇到任何网络分区故障时,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障
- 网络分区,是指分布式系统中,不同的节点分布在不同的子网络(机房/异地网络)中,由于一些特殊的原因导致这些子网络之间出现网络不连通的状态,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干孤立的区域;组成一个分布式系统的每个节点的加入与退出都可以看做是一个特殊的网络分区
CAP 应用
- 放弃 P
- 放弃分区容错性的话,则放弃了分布式,放弃了系统的可扩展性
- 放弃A
- 放弃可用性的话,则在遇到网络分区或其他故障时,受影响的服务需要等待一定的时间,再此期间无法对外提供政策的服务,即不可用
- 放弃C
- 放弃一致性的话(这里指强一致),则系统无法保证数据保持实时的一致性,在数据达到最终一致性时,有个时间窗口,在时间窗口内,数据是不一致的
对于分布式系统来说,P是不能放弃的,因此架构师通常是在可用性(A)和一致性(C)之间权衡
- CAP 理论告诉我们
- 目前很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题
- 基于 CAP 理论,很多系统在设计之初就要对这三者做出取舍
- 任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability) 和 分区容错性(Partition tolerance),最多只能同时满足两项
- 在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证最终一致性
- 问:为什么分布式系统中无法同时保证一致性和可用性?
- 答:首先一个前提,对于分布式系统而言,分区容错性是一个最基本的要求,因此基本上我们在设计分布式系统的时候只能从 一致性(C) 和 可用性(A) 之间进行取舍
- 如果保证了一致性(C):
- 对于节点 N1 和 N2,当往 N1 里写数据时,N2 上的操作必须被暂停,只有当 N1 同步数据到 N2 时才能对 N2 进行读写请求,在 N2 被暂停操作期间客户端提交的请求会收到失败或超时;显然,这与可用性是相悖的
- 如果保证了可用性(A):那就不能暂停 N2 的读写操作,但同时 N1 在写数据的话,这就违背了一致性的要求
- 如果保证了一致性(C):
BASE 理论
- CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸,对于 C 我们采用的方式和策略就是保证最终一致性
- BASE 定理
- BASE 是 Basically Available(基本可用)、Soft state(软状态) 和Eventually consistent(最终一致性) 三个短语的缩写
- BASE 基于 CAP 定理演化而来,核心思想是即时无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性
- BASE 理论的特点
- BASE 理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID 特性是相反的
- 它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态
- 但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID 特性和BASE 理论往往又会结合在一起
- BASE 理论与 CAP 的关系
- BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结, 是基于 CAP 定理逐步演化而来的
- BASE 理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性
- BASE 理论其实就是对 CAP 理论的延伸和补充,主要是对 AP 的补充
- 牺牲数据的强一致性,来保证数据的可用性,虽然存在中间装填,但数据最终一致
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











