






MyBatis
ORM(Object Relational Mapping): 对象关系映射,指的是持久化数据和实体对象的映射模式,解决面向对象与关系型数据库存在的互不匹配的现象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fzv6B0iA-1686861880249)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-ORM介绍.png)]
MyBatis:
-
MyBatis 是一个优秀的基于 Java 的持久层框架,它内部封装了 JDBC,使开发者只需关注 SQL 语句本身,而不需要花费精力去处理加载驱动、创建连接、创建 Statement 等过程。
-
MyBatis 通过 XML 或注解的方式将要执行的各种 Statement 配置起来,并通过 Java 对象和 Statement 中 SQL 的动态参数进行映射生成最终执行的 SQL 语句。
-
MyBatis 框架执行 SQL 并将结果映射为 Java 对象并返回。采用 ORM 思想解决了实体和数据库映射的问题,对 JDBC 进行了封装,屏蔽了 JDBC 底层 API 的调用细节,使我们不用操作 JDBC API,就可以完成对数据库的持久化操作。
MyBatis 官网地址:http://www.mybatis.org/mybatis-3/
参考视频:https://space.bilibili.com/37974444/
基本操作
相关API
Resources:加载资源的工具类
InputStream getResourceAsStream(String fileName):通过类加载器返回指定资源的字节流- 参数 fileName 是放在 src 的核心配置文件名:MyBatisConfig.xml
SqlSessionFactoryBuilder:构建器,用来获取 SqlSessionFactory 工厂对象
SqlSessionFactory build(InputStream is):通过指定资源的字节输入流获取 SqlSession 工厂对象
SqlSessionFactory:获取 SqlSession 构建者对象的工厂接口
SqlSession openSession():获取 SqlSession 构建者对象,并开启手动提交事务SqlSession openSession(boolean):获取 SqlSession 构建者对象,参数为 true 开启自动提交事务
SqlSession:构建者对象接口,用于执行 SQL、管理事务、接口代理
- SqlSession 代表和数据库的一次会话,用完必须关闭
- SqlSession 和 Connection 一样都是非线程安全,每次使用都应该去获取新的对象
注:update 数据需要提交事务,或开启默认提交
SqlSession 常用 API:
| 方法 | 说明 |
|---|---|
| List selectList(String statement,Object parameter) | 执行查询语句,返回List集合 |
| T selectOne(String statement,Object parameter) | 执行查询语句,返回一个结果对象 |
| int insert(String statement,Object parameter) | 执行新增语句,返回影响行数 |
| int update(String statement,Object parameter) | 执行删除语句,返回影响行数 |
| int delete(String statement,Object parameter) | 执行修改语句,返回影响行数 |
| void commit() | 提交事务 |
| void rollback() | 回滚事务 |
| T getMapper(Class cls) | 获取指定接口的代理实现类对象 |
| void close() | 释放资源 |
映射配置
映射配置文件包含了数据和对象之间的映射关系以及要执行的 SQL 语句,放在 src 目录下
命名:StudentMapper.xml
-
映射配置文件的文件头:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> -
根标签:
- :核心根标签
- namespace:属性,名称空间
-
功能标签:
- < select >:查询功能标签
- :新增功能标签
- :修改功能标签
- :删除功能标签
- id:属性,唯一标识,配合名称空间使用
- resultType:指定结果映射对象类型,和对应的方法的返回值类型(全限定名)保持一致,但是如果返回值是 List 则和其泛型保持一致
- parameterType:指定参数映射对象类型,必须和对应的方法的参数类型(全限定名)保持一致
- statementType:可选 STATEMENT,PREPARED 或 CALLABLE,默认值:PREPARED
- STATEMENT:直接操作 SQL,使用 Statement 不进行预编译,获取数据:$
- PREPARED:预处理参数,使用 PreparedStatement 进行预编译,获取数据:#
- CALLABLE:执行存储过程,CallableStatement
-
参数获取方式:
-
SQL 获取参数:
#{属性名}<mapper namespace="StudentMapper"> <select id="selectById" resultType="student" parameterType="int"> SELECT * FROM student WHERE id = #{id} </select> <mapper/>
-
强烈推荐官方文档:https://mybatis.org/mybatis-3/zh/sqlmap-xml.html
核心配置
核心配置文件包含了 MyBatis 最核心的设置和属性信息,如数据库的连接、事务、连接池信息等
命名:MyBatisConfig.xml
-
核心配置文件的文件头:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> -
根标签:
- :核心根标签
-
引入连接配置文件:
-
: 引入数据库连接配置文件标签
- resource:属性,指定配置文件名
<properties resource="jdbc.properties"/>
-
-
调整设置
- :可以改变 Mybatis 运行时行为
-
起别名:
-
:为全类名起别名的父标签
-
:为全类名起别名的子标签
- type:指定全类名
- alias:指定别名
-
:为指定包下所有类起别名的子标签,别名就是类名,首字母小写
<!--起别名--> <typeAliases> <typeAlias type="bean.Student" alias="student"/> <package name="com.seazean.bean"/> <!--二选一--> </typeAliase> -
-
自带别名:
别名 数据类型 string java.lang.String long java.lang.Lang int java.lang.Integer double java.lang.Double boolean java.lang.Boolean … …
-
-
配置环境,可以配置多个标签
- :配置数据库环境标签,default 属性指定哪个 environment
- :配置数据库环境子标签,id 属性是唯一标识,与 default 对应
- :事务管理标签,type 属性默认 JDBC 事务
- :数据源标签
- type 属性:POOLED 使用连接池(MyBatis 内置),UNPOOLED 不使用连接池
- :数据库连接信息标签。
- name 属性取值:driver,url,username,password
- value 属性取值:与 name 对应
-
引入映射配置文件
- :引入映射配置文件标签
- :引入映射配置文件子标签
- resource:属性指定映射配置文件的名称
- url:引用网路路径或者磁盘路径下的 sql 映射文件
- class:指定映射配置类
- :批量注册
参考官方文档:https://mybatis.org/mybatis-3/zh/configuration.html
#{}和${}
#{}:占位符,传入的内容会作为字符串加上引号,以预编译的方式传入,将 sql 中的 #{} 替换为 ? 号,调用 PreparedStatement 的 set 方法来赋值,有效的防止 SQL 注入,提高系统安全性
${}:拼接符,传入的内容会直接替换拼接,不会加上引号,可能存在 sql 注入的安全隐患
-
能用 #{} 的地方就用 #{},不用或少用 ${}
-
必须使用 ${} 的情况:
- 表名作参数时,如:
SELECT * FROM ${tableName} - order by 时,如:
SELECT * FROM t_user ORDER BY ${columnName}
- 表名作参数时,如:
-
sql 语句使用 #{},properties 文件内容获取使用 ${}
日志文件
在日常开发过程中,排查问题时需要输出 MyBatis 真正执行的 SQL 语句、参数、结果等信息,就可以借助 log4j 的功能来实现执行信息的输出。
-
在核心配置文件根标签内配置 log4j
<!--配置LOG4J--> <settings> <setting name="logImpl" value="log4j"/> </settings> -
在 src 目录下创建 log4j.properties
# Global logging configuration log4j.rootLogger=DEBUG, stdout # Console output... log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n #输出到日志文件 #log4j.appender.file=org.apache.log4j.FileAppender #log4j.appender.file.File=../logs/iask.log #log4j.appender.file.layout=org.apache.log4j.PatternLayout #log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %m%n -
pom.xml
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.21</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.21</version> </dependency>
代码实现
-
实体类
public class Student { private Integer id; private String name; private Integer age; ..... } -
StudentMapper
public interface StudentMapper { //查询全部 public abstract List<Student> selectAll(); //根据id查询 public abstract Student selectById(Integer id); //新增数据 public abstract Integer insert(Student stu); //修改数据 public abstract Integer update(Student stu); //删除数据 public abstract Integer delete(Integer id); } -
config.properties
driver=com.mysql.jdbc.Driver url=jdbc:mysql://192.168.2.184:3306/db1 username=root password=123456 -
MyBatisConfig.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <!--核心根标签--> <configuration> <!--引入数据库连接的配置文件--> <properties resource="jdbc.properties"/> <!--配置LOG4J--> <settings> <setting name="logImpl" value="log4j"/> </settings> <!--起别名--> <typeAliases> <typeAlias type="bean.Student" alias="student"/> <!--<package name="bean"/>--> </typeAliases> <!--配置数据库环境,可以多个环境,default指定哪个--> <environments default="mysql"> <!--id属性唯一标识--> <environment id="mysql"> <!--事务管理,type属性,默认JDBC事务--> <transactionManager type="JDBC"></transactionManager> <!--数据源信息 type属性连接池--> <dataSource type="POOLED"> <!--property获取数据库连接的配置信息--> <property name="driver" value="${driver}"/> <property name="url" value="${url}"/> <property name="username" value="${username}"/> <property name="password" value="${password}"/> </dataSource> </environment> </environments> <!--引入映射配置文件--> <mappers> <!--mapper引入指定的映射配置 resource属性执行的映射配置文件的名称--> <mapper resource="StudentMapper.xml"/> </mappers> </configuration> -
StudentMapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="StudentMapper"> <select id="selectAll" resultType="student"> SELECT * FROM student </select> <select id="selectById" resultType="student" parameterType="int"> SELECT * FROM student WHERE id = #{id} </select> <insert id="insert" parameterType="student"> INSERT INTO student VALUES (#{id},#{name},#{age}) </insert> <update id="update" parameterType="student"> UPDATE student SET name = #{name}, age = #{age} WHERE id = #{id} </update> <delete id="delete" parameterType="student"> DELETE FROM student WHERE id = #{id} </delete> </mapper> -
控制层测试代码:根据 id 查询
@Test public void selectById() throws Exception{ //1.加载核心配置文件 InputStream is = Resources.getResourceAsStream("MyBatisConfig.xml"); //2.获取SqlSession工厂对象 SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(is); //3.通过工厂对象获取SqlSession对象 SqlSession sqlSession = ssf.openSession(); //4.执行映射配置文件中的sql语句,并接收结果 Student stu = sqlSession.selectOne("StudentMapper.selectById", 3); //5.处理结果 System.out.println(stu); //6.释放资源 sqlSession.close(); is.close(); } -
控制层测试代码:新增功能
@Test public void insert() throws Exception{ //1.加载核心配置文件 //2.获取SqlSession工厂对象 //3.通过工厂对象获取SqlSession对象 SqlSession sqlSession = sqlSessionFactory.openSession(true); //4.执行映射配置文件中的sql语句,并接收结果 Student stu = new Student(5, "周七", 27); int result = sqlSession.insert("StudentMapper.insert", stu); //5.提交事务 //sqlSession.commit(); //6.处理结果 System.out.println(result); //7.释放资源 sqlSession.close(); is.close(); }
批量操作
三种方式实现批量操作:
-
标签属性:这种方式属于全局批量
<settings> <setting name="defaultExecutorType" value="BATCH"/> </settings>defaultExecutorType:配置默认的执行器
- SIMPLE 就是普通的执行器(默认,每次执行都要重新设置参数)
- REUSE 执行器会重用预处理语句(只预设置一次参数,多次执行)
- BATCH 执行器不仅重用语句还会执行批量更新(只针对修改操作)
-
SqlSession 会话内批量操作:
public void testBatch() throws IOException{ SqlSessionFactory sqlSessionFactory = getSqlSessionFactory(); // 可以执行批量操作的sqlSession SqlSession openSession = sqlSessionFactory.openSession(ExecutorType.BATCH); long start = System.currentTimeMillis(); try{ EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class); for (int i = 0; i < 10000; i++) { mapper.addEmp(new Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1")); } openSession.commit(); long end = System.currentTimeMillis(); // 批量:(预编译sql一次==>设置参数===>10000次===>执行1次(类似管道)) // 非批量:(预编译sql=设置参数=执行)==》10000 耗时更多 System.out.println("执行时长:" + (end - start)); }finally{ openSession.close(); } } -
Spring 配置文件方式(applicationContext.xml):
<!--配置一个可以进行批量执行的sqlSession --> <bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate"> <constructor-arg name="sqlSessionFactory" ref="sqlSessionFactoryBean"/> <constructor-arg name="executorType" value="BATCH"/> </bean>@Autowired private SqlSession sqlSession;
代理开发
代理规则
分层思想:控制层(controller)、业务层(service)、持久层(dao)
调用流程:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZzNSlELJ-1686861880250)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/分层思想调用流程.png)]
传统方式实现 DAO 层,需要写接口和实现类。采用 Mybatis 的代理开发方式实现 DAO 层的开发,只需要编写 Mapper 接口(相当于 Dao 接口),由 Mybatis 框架根据接口定义创建接口的动态代理对象
接口开发方式:
- 定义接口
- 操作数据库,MyBatis 框架根据接口,通过动态代理的方式生成代理对象,负责数据库的操作
Mapper 接口开发需要遵循以下规范:
-
Mapper.xml 文件中的 namespace 与 DAO 层 mapper 接口的全类名相同
-
Mapper.xml 文件中的增删改查标签的id属性和 DAO 层 Mapper 接口方法名相同
-
Mapper.xml 文件中的增删改查标签的 parameterType 属性和 DAO 层 Mapper 接口方法的参数相同
-
Mapper.xml 文件中的增删改查标签的 resultType 属性和 DAO 层 Mapper 接口方法的返回值相同
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HWdnvCRy-1686861880250)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/接口代理方式实现DAO层.png)]
实现原理
通过动态代理开发模式,只编写一个接口不写实现类,通过 getMapper() 方法最终获取到 MapperProxy 代理对象,而这个代理对象是 MyBatis 使用了 JDK 的动态代理技术生成的
动态代理实现类对象在执行方法时最终调用了 MapperMethod.execute() 方法,这个方法中通过 switch case 语句根据操作类型来判断是新增、修改、删除、查询操作,最后一步回到了 MyBatis 最原生的 SqlSession 方式来执行增删改查
-
代码实现:
public Student selectById(Integer id) { Student stu = null; SqlSession sqlSession = null; InputStream is = null; try{ //1.加载核心配置文件 is = Resources.getResourceAsStream("MyBatisConfig.xml"); //2.获取SqlSession工厂对象 SqlSessionFactory s = new SqlSessionFactoryBuilder().build(is); //3.通过工厂对象获取SqlSession对象 sqlSession = s.openSession(true); //4.获取StudentMapper接口的实现类对象 StudentMapper mapper = sqlSession.getMapper(StudentMapper.class); //5.通过实现类对象调用方法,接收结果 stu = mapper.selectById(id); } catch (Exception e) { e.getMessage(); } finally { //6.释放资源 if(sqlSession != null) { sqlSession.close(); } if(is != null) { try { is.close(); } catch (IOException e) { e.printStackTrace(); } } } //7.返回结果 return stu; }
结果映射
相关标签
:返回结果映射对象类型,和对应方法的返回值类型保持一致,但是如果返回值是 List 则和其泛型保持一致
:返回一条记录的 Map,key 是列名,value 是对应的值,用来配置字段和对象属性的映射关系标签,结果映射(和 resultType 二选一)
- id 属性:唯一标识
- type 属性:实体对象类型
- autoMapping 属性:结果自动映射
内的核心配置文件标签:
-
:配置主键映射关系标签
-
:配置非主键映射关系标签
- column 属性:表中字段名称
- property 属性: 实体对象变量名称
-
:配置被包含单个对象的映射关系标签,嵌套封装结果集(多对一、一对一)
- property 属性:被包含对象的变量名,要进行映射的属性名
- javaType 属性:被包含对象的数据类型,要进行映射的属性的类型(Java 中的 Bean 类)
- select 属性:加载复杂类型属性的映射语句的 ID,会从 column 属性指定的列中检索数据,作为参数传递给目标 select 语句
-
:配置被包含集合对象的映射关系标签,嵌套封装结果集(一对多、多对多)
- property 属性:被包含集合对象的变量名
- ofType 属性:集合中保存的对象数据类型
-
:鉴别器,用来判断某列的值,根据得到某列的不同值做出不同自定义的封装行为
自定义封装规则可以将数据库中比较复杂的数据类型映射为 JavaBean 中的属性
嵌套查询
子查询:
public class Blog {
private int id;
private String msg;
private Author author;
// set + get
}
<resultMap id="blogResult" type="Blog" autoMapping = "true">
<association property="author" column="author_id" javaType="Author" select="selectAuthor"/>
</resultMap>
<select id="selectBlog" resultMap="blogResult">
SELECT * FROM BLOG WHERE ID = #{id}
</select>
<select id="selectAuthor" resultType="Author">
SELECT * FROM AUTHOR WHERE ID = #{id}
</select>
循环引用:通过缓存解决
<resultMap id="blogResult" type="Blog" autoMapping = "true">
<id column="id" property="id"/>
<collection property="comment" ofType="Comment">
<association property="blog" javaType="Blog" resultMap="blogResult"/><!--y-->
</collection>
</resultMap
多表查询
一对一
一对一实现:
-
数据准备
CREATE TABLE person( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20), age INT ); INSERT INTO person VALUES (NULL,'张三',23),(NULL,'李四',24),(NULL,'王五',25); CREATE TABLE card( id INT PRIMARY KEY AUTO_INCREMENT, number VARCHAR(30), pid INT, CONSTRAINT cp_fk FOREIGN KEY (pid) REFERENCES person(id) ); INSERT INTO card VALUES (NULL,'12345',1),(NULL,'23456',2),(NULL,'34567',3); -
bean 类
public class Card { private Integer id; //主键id private String number; //身份证号 private Person p; //所属人的对象 ...... } public class Person { private Integer id; //主键id private String name; //人的姓名 private Integer age; //人的年龄 } -
配置文件 OneToOneMapper.xml,MyBatisConfig.xml 需要引入(可以把 bean 包下起别名)
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="OneToOneMapper"> <!--配置字段和实体对象属性的映射关系--> <resultMap id="oneToOne" type="card"> <!--column 表中字段名称,property 实体对象变量名称--> <id column="cid" property="id" /> <result column="number" property="number" /> <!-- association:配置被包含对象的映射关系 property:被包含对象的变量名 javaType:被包含对象的数据类型 --> <association property="p" javaType="bean.Person"> <id column="pid" property="id" /> <result column="name" property="name" /> <result column="age" property="age" /> </association> </resultMap> <select id="selectAll" resultMap="oneToOne"> <!--SQL--> SELECT c.id cid,number,pid,NAME,age FROM card c,person p WHERE c.pid=p.id </select> </mapper> -
核心配置文件 MyBatisConfig.xml
<!-- mappers引入映射配置文件 --> <mappers> <mapper resource="one_to_one/OneToOneMapper.xml"/> <mapper resource="one_to_many/OneToManyMapper.xml"/> <mapper resource="many_to_many/ManyToManyMapper.xml"/> </mappers> -
测试类
public class Test01 { @Test public void selectAll() throws Exception{ //1.加载核心配置文件 InputStream is = Resources.getResourceAsStream("MyBatisConfig.xml"); //2.获取SqlSession工厂对象 SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(is); //3.通过工厂对象获取SqlSession对象 SqlSession sqlSession = ssf.openSession(true); //4.获取OneToOneMapper接口的实现类对象 OneToOneMapper mapper = sqlSession.getMapper(OneToOneMapper.class); //5.调用实现类的方法,接收结果 List<Card> list = mapper.selectAll(); //6.处理结果 for (Card c : list) { System.out.println(c); } //7.释放资源 sqlSession.close(); is.close(); } }
一对多
一对多实现:
-
数据准备
CREATE TABLE classes( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) ); INSERT INTO classes VALUES (NULL,'程序一班'),(NULL,'程序二班') CREATE TABLE student( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(30), age INT, cid INT, CONSTRAINT cs_fk FOREIGN KEY (cid) REFERENCES classes(id) ); INSERT INTO student VALUES (NULL,'张三',23,1),(NULL,'李四',24,1),(NULL,'王五',25,2); -
bean 类
public class Classes { private Integer id; //主键id private String name; //班级名称 private List<Student> students; //班级中所有学生对象 ........ } public class Student { private Integer id; //主键id private String name; //学生姓名 private Integer age; //学生年龄 } -
映射配置文件
<mapper namespace="OneToManyMapper"> <resultMap id="oneToMany" type="bean.Classes"> <id column="cid" property="id"/> <result column="cname" property="name"/> <!--collection:配置被包含的集合对象映射关系--> <collection property="students" ofType="bean.Student"> <id column="sid" property="id"/> <result column="sname" property="name"/> <result column="sage" property="age"/> </collection> </resultMap> <select id="selectAll" resultMap="oneToMany"> <!--SQL--> SELECT c.id cid,c.name cname,s.id sid,s.name sname,s.age sage FROM classes c,student s WHERE c.id=s.cid </select> </mapper> -
代码实现片段
//4.获取OneToManyMapper接口的实现类对象 OneToManyMapper mapper = sqlSession.getMapper(OneToManyMapper.class); //5.调用实现类的方法,接收结果 List<Classes> classes = mapper.selectAll(); //6.处理结果 for (Classes cls : classes) { System.out.println(cls.getId() + "," + cls.getName()); List<Student> students = cls.getStudents(); for (Student student : students) { System.out.println("\t" + student); } }
多对多
学生课程例子,中间表不需要 bean 实体类
-
数据准备
CREATE TABLE course( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) ); INSERT INTO course VALUES (NULL,'语文'),(NULL,'数学'); CREATE TABLE stu_cr( id INT PRIMARY KEY AUTO_INCREMENT, sid INT, cid INT, CONSTRAINT sc_fk1 FOREIGN KEY (sid) REFERENCES student(id), CONSTRAINT sc_fk2 FOREIGN KEY (cid) REFERENCES course(id) ); INSERT INTO stu_cr VALUES (NULL,1,1),(NULL,1,2),(NULL,2,1),(NULL,2,2); -
bean类
public class Student { private Integer id; //主键id private String name; //学生姓名 private Integer age; //学生年龄 private List<Course> courses; // 学生所选择的课程集合 } public class Course { private Integer id; //主键id private String name; //课程名称 } -
配置文件
<mapper namespace="ManyToManyMapper"> <resultMap id="manyToMany" type="Bean.Student"> <id column="sid" property="id"/> <result column="sname" property="name"/> <result column="sage" property="age"/> <collection property="courses" ofType="Bean.Course"> <id column="cid" property="id"/> <result column="cname" property="name"/> </collection> </resultMap> <select id="selectAll" resultMap="manyToMany"> <!--SQL--> SELECT sc.sid,s.name sname,s.age sage,sc.cid,c.name cname FROM student s,course c,stu_cr sc WHERE sc.sid=s.id AND sc.cid=c.id </select> </mapper>
鉴别器
需求:如果查询结果是女性,则把部门信息查询出来,否则不查询 ;如果是男性,把 last_name 这一列的值赋值
<!--
column:指定要判断的列名
javaType:列值对应的java类型
-->
<discriminator javaType="string" column="gender">
<!-- 女生 -->
<!-- resultType不可缺少,也可以使用resutlMap -->
<case value="0" resultType="com.bean.Employee">
<association property="dept"
select="com.dao.DepartmentMapper.getDeptById"
column="d_id">
</association>
</case>
<!-- 男生 -->
<case value="1" resultType="com.bean.Employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
</case>
</discriminator>
延迟加载
两种加载
立即加载:只要调用方法,马上发起查询
延迟加载:在需要用到数据时才进行加载,不需要用到数据时就不加载数据,延迟加载也称懒加载
优点: 先从单表查询,需要时再从关联表去关联查询,提高数据库性能,因为查询单表要比关联查询多张表速度要快,节省资源
坏处:只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,查询工作也要消耗时间,所以可能造成用户等待时间变长,造成用户体验下降
核心配置文件:
| 标签名 | 描述 | 默认值 |
|---|---|---|
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载,特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 | false |
| aggressiveLazyLoading | 开启时,任一方法的调用都会加载该对象的所有延迟加载属性。否则每个延迟加载属性会按需加载(参考 lazyLoadTriggerMethods) | false |
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
assocation
分布查询:先按照身份 id 查询所属人的 id、然后根据所属人的 id 去查询人的全部信息,这就是分步查询
-
映射配置文件 OneToOneMapper.xml
一对一映射:
- column 属性表示给要调用的其它的 select 标签传入的参数
- select 属性表示调用其它的 select 标签
- fetchType=“lazy” 表示延迟加载(局部配置,只有配置了这个的地方才会延迟加载)
<mapper namespace="OneToOneMapper"> <!--配置字段和实体对象属性的映射关系--> <resultMap id="oneToOne" type="card"> <id column="id" property="id" /> <result column="number" property="number" /> <association property="p" javaType="bean.Person" column="pid" select="one_to_one.PersonMapper.findPersonByid" fetchType="lazy"> <!--需要配置新的映射文件--> </association> </resultMap> <select id="selectAll" resultMap="oneToOne"> SELECT * FROM card <!--查询全部,负责根据条件直接全部加载--> </select> </mapper> -
PersonMapper.xml
<mapper namespace="one_to_one.PersonMapper"> <select id="findPersonByid" parameterType="int" resultType="person"> SELECT * FROM person WHERE id=#{pid} </select> </mapper> -
PersonMapper.java
public interface PersonMapper { User findPersonByid(int id); } -
测试文件
public class Test01 { @Test public void selectAll() throws Exception{ InputStream is = Resources.getResourceAsStream("MyBatisConfig.xml"); SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(is); SqlSession sqlSession = ssf.openSession(true); OneToOneMapper mapper = sqlSession.getMapper(OneToOneMapper.class); // 调用实现类的方法,接收结果 List<Card> list = mapper.selectAll(); // 不能遍历,遍历就是相当于使用了该数据,需要加载,不遍历就是没有使用。 // 释放资源 sqlSession.close(); is.close(); } }
collection
同样在一对多关系配置的 结点中配置延迟加载策略, 结点中也有 select 属性和 column 属性
-
映射配置文件 OneToManyMapper.xml
一对多映射:
- column 是用于指定使用哪个字段的值作为条件查询
- select 是用于指定查询账户的唯一标识(账户的 dao 全限定类名加上方法名称)
<mapper namespace="OneToManyMapper"> <resultMap id="oneToMany" type="bean.Classes"> <id column="id" property="id"/> <result column="name" property="name"/> <!--collection:配置被包含的集合对象映射关系--> <collection property="students" ofType="bean.Student" column="id" select="one_to_one.StudentMapper.findStudentByCid"> </collection> </resultMap> <select id="selectAll" resultMap="oneToMany"> SELECT * FROM classes </select> </mapper> -
StudentMapper.xml
<mapper namespace="one_to_one.StudentMapper"> <select id="findPersonByCid" parameterType="int" resultType="student"> SELECT * FROM person WHERE cid=#{id} </select> </mapper>
注解开发
单表操作
注解可以简化开发操作,省略映射配置文件的编写
常用注解:
- @Select(“查询的 SQL 语句”):执行查询操作注解
- @Insert(“插入的 SQL 语句”):执行新增操作注解
- @Update(“修改的 SQL 语句”):执行修改操作注解
- @Delete(“删除的 SQL 语句”):执行删除操作注解
参数注解:
- @Param:当 SQL 语句需要多个(大于1)参数时,用来指定参数的对应规则
核心配置文件配置映射关系:
<mappers>
<package name="使用了注解的Mapper接口所在包"/>
</mappers>
<!--或者-->
<mappers>
<mapper class="包名.Mapper名"></mapper>
</mappers>
基本增删改查:
-
创建 Mapper 接口
package mapper; public interface StudentMapper { //查询全部 @Select("SELECT * FROM student") public abstract List<Student> selectAll(); //新增数据 @Insert("INSERT INTO student VALUES (#{id},#{name},#{age})") public abstract Integer insert(Student student); //修改操作 @Update("UPDATE student SET name=#{name},age=#{age} WHERE id=#{id}") public abstract Integer update(Student student); //删除操作 @Delete("DELETE FROM student WHERE id=#{id}") public abstract Integer delete(Integer id); } -
修改 MyBatis 的核心配置文件
<mappers> <package name="mapper"/> </mappers> -
bean类
public class Student { private Integer id; private String name; private Integer age; } -
测试类
@Test public void selectAll() throws Exception{ //1.加载核心配置文件 InputStream is = Resources.getResourceAsStream("MyBatisConfig.xml"); //2.获取SqlSession工厂对象 SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(is); //3.通过工厂对象获取SqlSession对象 SqlSession sqlSession = ssf.openSession(true); //4.获取StudentMapper接口的实现类对象 StudentMapper mapper = sqlSession.getMapper(StudentMapper.class); //5.调用实现类对象中的方法,接收结果 List<Student> list = mapper.selectAll(); //6.处理结果 for (Student student : list) { System.out.println(student); } //7.释放资源 sqlSession.close(); is.close(); }
多表操作
相关注解
实现复杂关系映射之前我们可以在映射文件中通过配置 来实现,使用注解开发后,可以使用 @Results 注解,@Result 注解,@One 注解,@Many 注解组合完成复杂关系的配置
| 注解 | 说明 |
|---|---|
| @Results | 代替 标签,注解中使用单个 @Result 注解或者 @Result 集合 使用格式:@Results({ @Result(), @Result() })或@Results({ @Result() }) |
| @Result | 代替< id> 和 标签,@Result 中属性介绍: column:数据库的列名 property:封装类的变量名 one:需要使用 @One 注解(@Result(one = @One)) Many:需要使用 @Many 注解(@Result(many= @Many)) |
| @One(一对一) | 代替 标签,多表查询的关键,用来指定子查询返回单一对象 select:指定调用 Mapper 接口中的某个方法 使用格式:@Result(column=“”, property=“”, one=@One(select=“”)) |
| @Many(多对一) | 代替 标签,多表查询的关键,用来指定子查询返回对象集合 select:指定调用 Mapper 接口中的某个方法 使用格式:@Result(column=“”, property=“”, many=@Many(select=“”)) |
一对一
身份证对人
-
PersonMapper 接口
public interface PersonMapper { //根据id查询 @Select("SELECT * FROM person WHERE id=#{id}") public abstract Person selectById(Integer id); } -
CardMapper接口
public interface CardMapper { //查询全部 @Select("SELECT * FROM card") @Results({ @Result(column = "id",property = "id"), @Result(column = "number",property = "number"), @Result( property = "p", // 被包含对象的变量名 javaType = Person.class, // 被包含对象的实际数据类型 column = "pid", // 根据查询出的card表中的pid字段来查询person表 /* one、@One 一对一固定写法 select属性:指定调用哪个接口中的哪个方法 */ one = @One(select = "one_to_one.PersonMapper.selectById") ) }) public abstract List<Card> selectAll(); } -
测试类(详细代码参考单表操作)
//1.加载核心配置文件 //2.获取SqlSession工厂对象 //3.通过工厂对象获取SqlSession对象 //4.获取StudentMapper接口的实现类对象 CardMapper mapper = sqlSession.getMapper(CardMapper.class); //5.调用实现类对象中的方法,接收结果 List<Card> list = mapper.selectAll();
一对多
班级和学生
-
StudentMapper接口
public interface StudentMapper { //根据cid查询student表 cid是外键约束列 @Select("SELECT * FROM student WHERE cid=#{cid}") public abstract List<Student> selectByCid(Integer cid); } -
ClassesMapper接口
public interface ClassesMapper { //查询全部 @Select("SELECT * FROM classes") @Results({ @Result(column = "id", property = "id"), @Result(column = "name", property = "name"), @Result( property = "students", //被包含对象的变量名 javaType = List.class, //被包含对象的实际数据类型 column = "id", //根据id字段查询student表 many = @Many(select = "one_to_many.StudentMapper.selectByCid") ) }) public abstract List<Classes> selectAll(); } -
测试类
//4.获取StudentMapper接口的实现类对象 ClassesMapper mapper = sqlSession.getMapper(ClassesMapper.class); //5.调用实现类对象中的方法,接收结果 List<Classes> classes = mapper.selectAll();
多对多
学生和课程
-
SQL 查询语句
SELECT DISTINCT s.id,s.name,s.age FROM student s,stu_cr sc WHERE sc.sid=s.id SELECT c.id,c.name FROM stu_cr sc,course c WHERE sc.cid=c.id AND sc.sid=#{id} -
CourseMapper 接口
public interface CourseMapper { //根据学生id查询所选课程 @Select("SELECT c.id,c.name FROM stu_cr sc,course c WHERE sc.cid=c.id AND sc.sid=#{id}") public abstract List<Course> selectBySid(Integer id); } -
StudentMapper 接口
public interface StudentMapper { //查询全部 @Select("SELECT DISTINCT s.id,s.name,s.age FROM student s,stu_cr sc WHERE sc.sid=s.id") @Results({ @Result(column = "id",property = "id"), @Result(column = "name",property = "name"), @Result(column = "age",property = "age"), @Result( property = "courses", //被包含对象的变量名 javaType = List.class, //被包含对象的实际数据类型 column = "id", //根据查询出的student表中的id字段查询中间表和课程表 many = @Many(select = "many_to_many.CourseMapper.selectBySid") ) }) public abstract List<Student> selectAll(); } -
测试类
//4.获取StudentMapper接口的实现类对象 StudentMapper mapper = sqlSession.getMapper(StudentMapper.class); //5.调用实现类对象中的方法,接收结果 List<Student> students = mapper.selectAll();
缓存机制
缓存概述
缓存:缓存就是一块内存空间,保存临时数据
作用:将数据源(数据库或者文件)中的数据读取出来存放到缓存中,再次获取时直接从缓存中获取,可以减少和数据库交互的次数,提升程序的性能
缓存适用:
- 适用于缓存的:经常查询但不经常修改的,数据的正确与否对最终结果影响不大的
- 不适用缓存的:经常改变的数据 , 敏感数据(例如:股市的牌价,银行的汇率,银行卡里面的钱)等等
缓存类别:
- 一级缓存:SqlSession 级别的缓存,又叫本地会话缓存,自带的(不需要配置),一级缓存的生命周期与 SqlSession 一致。在操作数据库时需要构造 SqlSession 对象,在对象中有一个数据结构(HashMap)用于存储缓存数据,不同的 SqlSession 之间的缓存数据区域是互相不影响的
- 二级缓存:mapper(namespace)级别的缓存,二级缓存的使用,需要手动开启(需要配置)。多个 SqlSession 去操作同一个 Mapper 的 SQL 可以共用二级缓存,二级缓存是跨 SqlSession 的
开启缓存:配置核心配置文件中 标签
- cacheEnabled:true 表示全局性地开启所有映射器配置文件中已配置的任何缓存,默认 true
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s2aCDBEb-1686861880251)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-缓存的实现原理.png)]
参考文章:https://www.cnblogs.com/ysocean/p/7342498.html
一级缓存
一级缓存是 SqlSession 级别的缓存
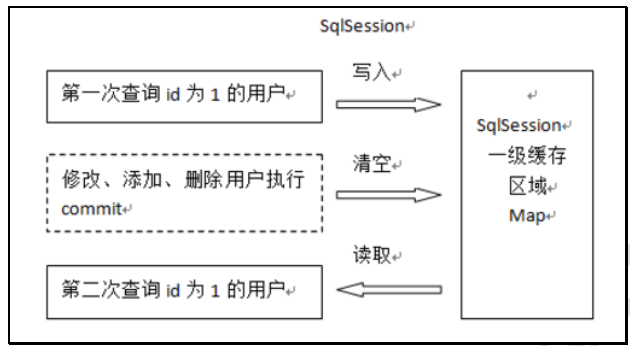
工作流程:第一次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,如果没有,从数据库查询用户信息,得到用户信息,将用户信息存储到一级缓存中;第二次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,缓存中有,直接从缓存中获取用户信息。
一级缓存的失效:
- SqlSession 不同
- SqlSession 相同,查询条件不同时(还未缓存该数据)
- SqlSession 相同,手动清除了一级缓存,调用
sqlSession.clearCache() - SqlSession 相同,执行 commit 操作或者执行插入、更新、删除,清空 SqlSession 中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读
Spring 整合 MyBatis 后,一级缓存作用:
- 未开启事务的情况,每次查询 Spring 都会创建新的 SqlSession,因此一级缓存失效
- 开启事务的情况,Spring 使用 ThreadLocal 获取当前资源绑定同一个 SqlSession,因此此时一级缓存是有效的
测试一级缓存存在
public void testFirstLevelCache(){
//1. 获取sqlSession对象
SqlSession sqlSession = SqlSessionFactoryUtils.openSession();
//2. 通过sqlSession对象获取UserDao接口的代理对象
UserDao userDao1 = sqlSession.getMapper(UserDao.class);
//3. 调用UserDao接口的代理对象的findById方法获取信息
User user1 = userDao1.findById(1);
System.out.println(user1);
//sqlSession.clearCache() 清空缓存
UserDao userDao2 = sqlSession.getMapper(UserDao.class);
User user = userDao.findById(1);
System.out.println(user2);
//4.测试两次结果是否一样
System.out.println(user1 == user2);//true
//5. 提交事务关闭资源
SqlSessionFactoryUtils.commitAndClose(sqlSession);
}
二级缓存
基本介绍
二级缓存是 mapper 的缓存,只要是同一个命名空间(namespace)的 SqlSession 就共享二级缓存的内容,并且可以操作二级缓存
作用:作用范围是整个应用,可以跨线程使用,适合缓存一些修改较少的数据
工作流程:一个会话查询数据,这个数据就会被放在当前会话的一级缓存中,如果会话关闭或提交一级缓存中的数据会保存到二级缓存
二级缓存的基本使用:
-
在 MyBatisConfig.xml 文件开启二级缓存,cacheEnabled 默认值为 true,所以这一步可以省略不配置
<!--配置开启二级缓存--> <settings> <setting name="cacheEnabled" value="true"/> </settings> -
配置 Mapper 映射文件
<cache>标签表示当前这个 mapper 映射将使用二级缓存,区分的标准就看 mapper 的 namespace 值<mapper namespace="dao.UserDao"> <!--开启user支持二级缓存--> <cache eviction="FIFO" flushInterval="6000" readOnly="" size="1024"/> <cache></cache> <!--则表示所有属性使用默认值--> </mapper>eviction(清除策略):
LRU– 最近最少使用:移除最长时间不被使用的对象,默认FIFO– 先进先出:按对象进入缓存的顺序来移除它们SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象
flushInterval(刷新间隔):可以设置为任意的正整数, 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新
size(引用数目):缓存存放多少元素,默认值是 1024
readOnly(只读):可以被设置为 true 或 false
- 只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改,促进了性能提升
- 可读写的缓存会(通过序列化)返回缓存对象的拷贝, 速度上会慢一些,但是更安全,因此默认值是 false
type:指定自定义缓存的全类名,实现 Cache 接口即可
-
要进行二级缓存的类必须实现 java.io.Serializable 接口,可以使用序列化方式来保存对象。
public class User implements Serializable{}
相关属性
-
select 标签的 useCache 属性
映射文件中的
<select>标签中设置useCache="true"代表当前 statement 要使用二级缓存(默认)注意:如果每次查询都需要最新的数据 sql,要设置成 useCache=false,禁用二级缓存
<select id="findAll" resultType="user" useCache="true"> select * from user </select> -
每个增删改标签都有 flushCache 属性,默认为 true,代表在执行增删改之后就会清除一、二级缓存,保证缓存的一致性;而查询标签默认值为 false,所以查询不会清空缓存
-
localCacheScope:本地缓存作用域, 中的配置项,默认值为 SESSION,当前会话的所有数据保存在会话缓存中,设置为 STATEMENT 禁用一级缓存
源码解析
事务提交二级缓存才生效:DefaultSqlSession 调用 commit() 时会回调 executor.commit()
-
CachingExecutor#query():执行查询方法,查询出的数据会先放入 entriesToAddOnCommit 集合暂存
// 从二缓存中获取数据,获取不到去一级缓存获取 List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { // 回调 BaseExecutor#query list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); // 将数据放入 entriesToAddOnCommit 集合暂存,此时还没放入二级缓存 tcm.putObject(cache, key, list); } -
commit():事务提交,清空一级缓存,放入二级缓存,二级缓存使用 TransactionalCacheManager(tcm)管理
public void commit(boolean required) throws SQLException { // 首先调用 BaseExecutor#commit 方法,【清空一级缓存】 delegate.commit(required); tcm.commit(); } -
TransactionalCacheManager#commit:查询出的数据放入二级缓存
public void commit() { // 获取所有的缓存事务,挨着进行提交 for (TransactionalCache txCache : transactionalCaches.values()) { txCache.commit(); } }public void commit() { if (clearOnCommit) { delegate.clear(); } // 将 entriesToAddOnCommit 中的数据放入二级缓存 flushPendingEntries(); // 清空相关集合 reset(); }private void flushPendingEntries() { for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) { // 将数据放入二级缓存 delegate.putObject(entry.getKey(), entry.getValue()); } }
增删改操作会清空缓存:
-
update():CachingExecutor 的更新操作
public int update(MappedStatement ms, Object parameterObject) throws SQLException { flushCacheIfRequired(ms); // 回调 BaseExecutor#update 方法,也会清空一级缓存 return delegate.update(ms, parameterObject); } -
flushCacheIfRequired():判断是否需要清空二级缓存
private void flushCacheIfRequired(MappedStatement ms) { Cache cache = ms.getCache(); // 判断二级缓存是否存在,然后判断标签的 flushCache 的值,增删改操作的 flushCache 属性默认为 true if (cache != null && ms.isFlushCacheRequired()) { // 清空二级缓存 tcm.clear(cache); } }
自定义
自定义缓存
<cache type="com.domain.something.MyCustomCache"/>
type 属性指定的类必须实现 org.apache.ibatis.cache.Cache 接口,且提供一个接受 String 参数作为 id 的构造器
public interface Cache {
String getId();
int getSize();
void putObject(Object key, Object value);
Object getObject(Object key);
boolean hasKey(Object key);
Object removeObject(Object key);
void clear();
}
缓存的配置,只需要在缓存实现中添加公有的 JavaBean 属性,然后通过 cache 元素传递属性值,例如在缓存实现上调用一个名为 setCacheFile(String file) 的方法:
<cache type="com.domain.something.MyCustomCache">
<property name="cacheFile" value="/tmp/my-custom-cache.tmp"/>
</cache>
- 可以使用所有简单类型作为 JavaBean 属性的类型,MyBatis 会进行转换。
- 可以使用占位符(如
${cache.file}),以便替换成在配置文件属性中定义的值
MyBatis 支持在所有属性设置完毕之后,调用一个初始化方法, 如果想要使用这个特性,可以在自定义缓存类里实现 org.apache.ibatis.builder.InitializingObject 接口
public interface InitializingObject {
void initialize() throws Exception;
}
注意:对缓存的配置(如清除策略、可读或可读写等),不能应用于自定义缓存
对某一命名空间的语句,只会使用该命名空间的缓存进行缓存或刷新,在多个命名空间中共享相同的缓存配置和实例,可以使用 cache-ref 元素来引用另一个缓存
<cache-ref namespace="com.someone.application.data.SomeMapper"/>
构造语句
动态 SQL
基本介绍
动态 SQL 是 MyBatis 强大特性之一,逻辑复杂时,MyBatis 映射配置文件中,SQL 是动态变化的,所以引入动态 SQL 简化拼装 SQL 的操作
DynamicSQL 包含的标签:
- if
- where
- set
- choose (when、otherwise)
- trim
- foreach
各个标签都可以进行灵活嵌套和组合
OGNL:Object Graphic Navigation Language(对象图导航语言),用于对数据进行访问
参考文章:https://www.cnblogs.com/ysocean/p/7289529.html
where
:条件标签,有动态条件则使用该标签代替 WHERE 关键字,封装查询条件
作用:如果标签返回的内容是以 AND 或 OR 开头的,标签内会剔除掉
表结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5FdRZvTA-1686861880252)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-动态sql用户表.png)]
if
基本格式:
<if test=“条件判断”>
查询条件拼接
</if>
我们根据实体类的不同取值,使用不同的 SQL 语句来进行查询。比如在 id 如果不为空时可以根据 id 查询,如果username 不同空时还要加入用户名作为条件,这种情况在我们的多条件组合查询中经常会碰到。
-
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="mapper.UserMapper"> <select id="selectCondition" resultType="user" parameterType="user"> SELECT * FROM user <where> <if test="id != null "> id = #{id} </if> <if test="username != null "> AND username = #{username} </if> <if test="sex != null "> AND sex = #{sex} </if> </where> </select> </mapper> -
MyBatisConfig.xml,引入映射配置文件
<mappers> <!--mapper引入指定的映射配置 resource属性执行的映射配置文件的名称--> <mapper resource="UserMapper.xml"/> </mappers> -
DAO 层 Mapper 接口
public interface UserMapper { //多条件查询 public abstract List<User> selectCondition(Student stu); } -
实现类
public class DynamicTest { @Test public void selectCondition() throws Exception{ //1.加载核心配置文件 InputStream is = Resources.getResourceAsStream("MyBatisConfig.xml"); //2.获取SqlSession工厂对象 SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(is); //3.通过工厂对象获取SqlSession对象 SqlSession sqlSession = ssf.openSession(true); //4.获取StudentMapper接口的实现类对象 UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = new User(); user.setId(2); user.setUsername("李四"); //user.setSex(男); AND 后会自动剔除 //5.调用实现类的方法,接收结果 List<Student> list = mapper.selectCondition(user); //6.处理结果 for (User user : list) { System.out.println(user); } //7.释放资源 sqlSession.close(); is.close(); } }
set
:进行更新操作的时候,含有 set 关键词,使用该标签
<!-- 根据 id 更新 user 表的数据 -->
<update id="updateUserById" parameterType="com.ys.po.User">
UPDATE user u
<set>
<if test="username != null and username != ''">
u.username = #{username},
</if>
<if test="sex != null and sex != ''">
u.sex = #{sex}
</if>
</set>
WHERE id=#{id}
</update>
- 如果第一个条件 username 为空,那么 sql 语句为:update user u set u.sex=? where id=?
- 如果第一个条件不为空,那么 sql 语句为:update user u set u.username = ? ,u.sex = ? where id=?
choose
假如不想用到所有的查询条件,只要查询条件有一个满足即可,使用 choose 标签可以解决此类问题,类似于 Java 的 switch 语句
标签:,
<select id="selectUserByChoose" resultType="user" parameterType="user">
SELECT * FROM user
<where>
<choose>
<when test="id !='' and id != null">
id=#{id}
</when>
<when test="username !='' and username != null">
AND username=#{username}
</when>
<otherwise>
AND sex=#{sex}
</otherwise>
</choose>
</where>
</select>
有三个条件,id、username、sex,只能选择一个作为查询条件
-
如果 id 不为空,那么查询语句为:select * from user where id=?
-
如果 id 为空,那么看 username 是否为空
- 如果不为空,那么语句为:select * from user where username=?
- 如果 username 为空,那么查询语句为 select * from user where sex=?
trim
trim 标记是一个格式化的标记,可以完成 set 或者是 where 标记的功能,自定义字符串截取
- prefix:给拼串后的整个字符串加一个前缀,trim 标签体中是整个字符串拼串后的结果
- prefixOverrides:去掉整个字符串前面多余的字符
- suffix:给拼串后的整个字符串加一个后缀
- suffixOverrides:去掉整个字符串后面多余的字符
改写 if + where 语句:
<select id="selectUserByUsernameAndSex" resultType="user" parameterType="com.ys.po.User">
SELECT * FROM user
<trim prefix="where" prefixOverrides="and | or">
<if test="username != null">
AND username=#{username}
</if>
<if test="sex != null">
AND sex=#{sex}
</if>
</trim>
</select>
改写 if + set 语句:
<!-- 根据 id 更新 user 表的数据 -->
<update id="updateUserById" parameterType="com.ys.po.User">
UPDATE user u
<trim prefix="set" suffixOverrides=",">
<if test="username != null and username != ''">
u.username = #{username},
</if>
<if test="sex != null and sex != ''">
u.sex = #{sex},
</if>
</trim>
WHERE id=#{id}
</update>
foreach
基本格式:
<foreach>:循环遍历标签。适用于多个参数或者的关系。
<foreach collection=“”open=“”close=“”item=“”separator=“”>
获取参数
</foreach>
属性:
- collection:参数容器类型, (list-集合, array-数组)
- open:开始的 SQL 语句
- close:结束的 SQL 语句
- item:参数变量名
- separator:分隔符
需求:循环执行 sql 的拼接操作,SELECT * FROM user WHERE id IN (1,2,5)
-
UserMapper.xml片段
<select id="selectByIds" resultType="user" parameterType="list"> SELECT * FROM student <where> <foreach collection="list" open="id IN(" close=")" item="id" separator=","> #{id} </foreach> </where> </select> -
测试代码片段
//4.获取StudentMapper接口的实现类对象 UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<Integer> ids = new ArrayList<>(); Collections.addAll(list, 1, 2); //5.调用实现类的方法,接收结果 List<User> list = mapper.selectByIds(ids); for (User user : list) { System.out.println(user); }
SQL片段
将一些重复性的 SQL 语句进行抽取,以达到复用的效果
格式:
<sql id=“片段唯一标识”>抽取的SQL语句</sql> <!--抽取标签-->
<include refid=“片段唯一标识”/> <!--引入标签-->
使用:
<sql id="select">SELECT * FROM user</sql>
<select id="selectByIds" resultType="user" parameterType="list">
<include refid="select"/>
<where>
<foreach collection="list" open="id IN(" close=")" item="id" separator=",">
#{id}
</foreach>
</where>
</select>
逆向工程
MyBatis 逆向工程,可以针对单表自动生成 MyBatis 执行所需要的代码(mapper.java、mapper.xml、pojo…)
generatorConfig.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<context id="testTables" targetRuntime="MyBatis3">
<commentGenerator>
<!-- 是否去除自动生成的注释 true:是 : false:否 -->
<property name="suppressAllComments" value="true" />
</commentGenerator>
<!--数据库连接的信息:驱动类、连接地址、用户名、密码 -->
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/mybatisrelation" userId="root"
password="root">
</jdbcConnection>
<!-- 默认false,把JDBC DECIMAL 和 NUMERIC 类型解析为 Integer,为 true时把JDBC DECIMAL和NUMERIC类型解析为java.math.BigDecimal -->
<javaTypeResolver>
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<!-- targetProject:生成PO类的位置!! -->
<javaModelGenerator targetPackage="com.ys.po"
targetProject=".\src">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
<!-- 从数据库返回的值被清理前后的空格 -->
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- targetProject:mapper映射文件生成的位置!! -->
<sqlMapGenerator targetPackage="com.ys.mapper"
targetProject=".\src">
<property name="enableSubPackages" value="false" />
</sqlMapGenerator>
<!-- targetPackage:mapper接口生成的位置,重要!! -->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.ys.mapper"
targetProject=".\src">
<property name="enableSubPackages" value="false" />
</javaClientGenerator>
<!-- 指定数据库表,要生成哪些表,就写哪些表,要和数据库中对应,不能写错! -->
<table tableName="items"></table>
<table tableName="orders"></table>
<table tableName="orderdetail"></table>
<table tableName="user"></table>
</context>
</generatorConfiguration>
生成代码:
public void testGenerator() throws Exception{
List<String> warnings = new ArrayList<String>();
boolean overwrite = true;
//指向逆向工程配置文件
File configFile = new File(GeneratorTest.class.
getResource("/generatorConfig.xml").getFile());
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config,
callback, warnings);
myBatisGenerator.generate(null);
}
参考文章:https://www.cnblogs.com/ysocean/p/7360409.html
构建 SQL
基础语法
MyBatis 提供了 org.apache.ibatis.jdbc.SQL 功能类,专门用于构建 SQL 语句
| 方法 | 说明 |
|---|---|
| SELECT(String… columns) | 根据字段拼接查询语句 |
| FROM(String… tables) | 根据表名拼接语句 |
| WHERE(String… conditions) | 根据条件拼接语句 |
| INSERT_INTO(String tableName) | 根据表名拼接新增语句 |
| INTO_VALUES(String… values) | 根据值拼接新增语句 |
| UPDATE(String table) | 根据表名拼接修改语句 |
| DELETE_FROM(String table) | 根据表名拼接删除语句 |
增删改查注解:
- @SelectProvider:生成查询用的 SQL 语句
- @InsertProvider:生成新增用的 SQL 语句
- @UpdateProvider:生成修改用的 SQL 语句注解
- @DeleteProvider:生成删除用的 SQL 语句注解。
- type 属性:生成 SQL 语句功能类对象
- method 属性:指定调用方法
基本操作
-
MyBatisConfig.xml 配置
<!-- mappers引入映射配置文件 --> <mappers> <package name="mapper"/> </mappers> -
Mapper 类
public interface StudentMapper { //查询全部 @SelectProvider(type = ReturnSql.class, method = "getSelectAll") public abstract List<Student> selectAll(); //新增数据 @InsertProvider(type = ReturnSql.class, method = "getInsert") public abstract Integer insert(Student student); //修改操作 @UpdateProvider(type = ReturnSql.class, method = "getUpdate") public abstract Integer update(Student student); //删除操作 @DeleteProvider(type = ReturnSql.class, method = "getDelete") public abstract Integer delete(Integer id); } -
ReturnSQL 类
public class ReturnSql { //定义方法,返回查询的sql语句 public String getSelectAll() { return new SQL() { { SELECT("*"); FROM("student"); } }.toString(); } //定义方法,返回新增的sql语句 public String getInsert(Student stu) { return new SQL() { { INSERT_INTO("student"); INTO_VALUES("#{id},#{name},#{age}"); } }.toString(); } //定义方法,返回修改的sql语句 public String getUpdate(Student stu) { return new SQL() { { UPDATE("student"); SET("name=#{name}","age=#{age}"); WHERE("id=#{id}"); } }.toString(); } //定义方法,返回删除的sql语句 public String getDelete(Integer id) { return new SQL() { { DELETE_FROM("student"); WHERE("id=#{id}"); } }.toString(); } } -
功能实现类
public class SqlTest { @Test //查询全部 public void selectAll() throws Exception{ //1.加载核心配置文件 InputStream is = Resources.getResourceAsStream("MyBatisConfig.xml"); //2.获取SqlSession工厂对象 SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is); //3.通过工厂对象获取SqlSession对象 SqlSession sqlSession = sqlSessionFactory.openSession(true); //4.获取StudentMapper接口的实现类对象 StudentMapper mapper = sqlSession.getMapper(StudentMapper.class); //5.调用实现类对象中的方法,接收结果 List<Student> list = mapper.selectAll(); //6.处理结果 for (Student student : list) { System.out.println(student); } //7.释放资源 sqlSession.close(); is.close(); } @Test //新增 public void insert() throws Exception{ //1 2 3 4获取StudentMapper接口的实现类对象 StudentMapper mapper = sqlSession.getMapper(StudentMapper.class); //5.调用实现类对象中的方法,接收结果 ->6 7 Student stu = new Student(4,"赵六",26); Integer result = mapper.insert(stu); } @Test //修改 public void update() throws Exception{ //1 2 3 4 5调用实现类对象中的方法,接收结果 ->6 7 Student stu = new Student(4,"赵六wq",36); Integer result = mapper.update(stu); } @Test //删除 public void delete() throws Exception{ //1 2 3 4 5 6 7 Integer result = mapper.delete(4); } }
运行原理
运行机制
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O9YxLjLV-1686861880252)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-执行流程.png)]
MyBatis 运行过程:
-
加载 MyBatis 全局配置文件,通过 XPath 方式解析 XML 配置文件,首先解析核心配置文件, 标签中配置属性项有 defaultExecutorType,用来配置指定 Executor 类型,将配置文件的信息填充到 Configuration对象。最后解析映射器配置的映射文件,并构建 MappedStatement 对象填充至 Configuration,将解析后的映射器添加到 mapperRegistry 中,用于获取代理
-
创建一个 DefaultSqlSession 对象,根据参数创建指定类型的 Executor,二级缓存默认开启,把 Executor 包装成缓存执行器
-
DefaulSqlSession 调用 getMapper(),通过 JDK 动态代理获取 Mapper 接口的代理对象 MapperProxy
-
执行 SQL 语句:
- MapperProxy.invoke() 执行代理方法,通过 MapperMethod#execute 判断执行的是增删改查中的哪个方法
- 查询方法调用 sqlSession.selectOne(),从 Configuration 中获取执行者对象 MappedStatement,然后 Executor 调用 executor.query 开始执行查询方法
- 首先通过 CachingExecutor 去二级缓存查询,查询不到去一级缓存查询,最后去数据库查询并放入一级缓存
- Configuration 对象根据 标签的 statementType 属性创建 StatementHandler 对象,在 StatementHandler 的构造方法中,创建了 ParameterHandler 和 ResultSetHandler 对象
- 最后获取 JDBC 原生的 Connection 数据库连接对象,创建 Statement 执行者对象,然后通过 ParameterHandler 设置预编译参数,底层是 TypeHandler#setParameter 方法,然后通过 StatementHandler 回调执行者对象执行增删改查,最后调用 ResultsetHandler 处理查询结果
四大对象:
- StatementHandler:执行 SQL 语句的对象
- ParameterHandler:设置预编译参数用的
- ResultHandler:处理结果集
- Executor:执行器,真正进行 Java 与数据库交互的对象
参考视频:https://www.bilibili.com/video/BV1mW411M737?p=71
获取工厂
SqlSessionFactoryBuilder.build(InputStream, String, Properties):构建工厂
XMLConfigBuilder.parse():解析核心配置文件每个标签的信息(XPath)
-
parseConfiguration(parser.evalNode("/configuration")):读取节点内数据, 是 MyBatis 配置文件中的顶层标签settings = settingsAsProperties(root.evalNode("settings")):读取核心配置文件中的 标签settingsElement(settings):设置框架相关的属性configuration.setCacheEnabled():设置缓存属性,默认是 trueconfiguration.setDefaultExecutorType():设置 Executor 类型到 configuration,默认是 SIMPLE
mapperElement(root.evalNode("mappers")):解析 mappers 信息,分为 package 和 单个注册两种-
if...else...:根据映射方法选择合适的读取方式 -
XMLMapperBuilder.parse():解析 mapper 的标签的信息-
configurationElement(parser.evalNode("/mapper")):解析 mapper 文件,顶层节点-
buildStatementFromContext(context.evalNodes("select...")):解析每个操作标签XMLStatementBuilder.parseStatementNode():解析操作标签的所有的属性builderAssistant.addMappedStatement(...):封装成 MappedStatement 对象加入 Configuration 对象,代表一个增删改查的标签
-
-
-
Class<?> mapperInterface = Resources.classForName(mapperClass):加载 Mapper 接口 -
Configuration.addMappers():将核心配置文件配置的映射器添加到 mapperRegistry 中,用来获取代理对象-
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type):创建注解解析器 -
parser.parse():解析 Mapper 接口-
SqlSource sqlSource = getSqlSourceFromAnnotations():获取 SQL 的资源对象[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wX4wmj1P-1686861880253)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-SQL资源对象.png)]
-
builderAssistant.addMappedStatement(...):封装成 MappedStatement 对象加入 Configuration 对象
-
-
-
return configuration:返回配置完成的 configuration 对象
return new DefaultSqlSessionFactory(config):返回工厂对象,包含 Configuration 对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9f8YxSpm-1686861880253)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-获取工厂对象.png)]
总结:解析 XML 是对 Configuration 中的属性进行填充,那么可以在一个类中创建 Configuration 对象,自定义其中属性的值来达到配置的效果
获取会话
DefaultSqlSessionFactory.openSession():获取 Session 对象,并且创建 Executor 对象
DefaultSqlSessionFactory.openSessionFromDataSource(…):ExecutorType 为 Executor 的类型,TransactionIsolationLevel 为事务隔离级别,autoCommit 是否开启事务
-
transactionFactory.newTransaction(DataSource, IsolationLevel, boolean:事务对象 -
configuration.newExecutor(tx, execType):根据参数创建指定类型的 Executor- 批量操作笔记的部分有讲解到 的属性 defaultExecutorType,根据配置创建对象
- 二级缓存默认开启,会包装 Executor 对象
new CachingExecutor(executor)
return new DefaultSqlSession(configuration, executor, autoCommit):返回 DefaultSqlSession 对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o3qupzrl-1686861880253)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-获取会话对象.png)]
获取代理
Configuration.getMapper(Class, SqlSession):获取代理的 mapper 对象
MapperRegistry.getMapper(Class, SqlSession):MapperRegistry 是 Configuration 属性,在获取工厂对象时初始化
(MapperProxyFactory<T>) knownMappers.get(type):获取接口信息封装为 MapperProxyFactory 对象mapperProxyFactory.newInstance(sqlSession):创建代理对象new MapperProxy<>(sqlSession, mapperInterface, methodCache):包装对象- methodCache 是并发安全的 ConcurrentHashMap 集合,存放要执行的方法
MapperProxy<T> implements InvocationHandler说明 MapperProxy 默认是一个 InvocationHandler 对象
Proxy.newProxyInstance():JDK 动态代理创建 MapperProxy 对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XTXACzgU-1686861880254)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-获取代理对象.png)]
执行SQL
MapperProxy.invoke():执行 SQL 语句,Object 类的方法直接执行
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 当前方法是否是属于 Object 类中的方法
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
// 当前方法是否是默认方法
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 包装成一个 MapperMethod 对象并初始化该对象
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 【根据 switch-case 判断使用的什么类型的 SQL 进行逻辑处理】,此处分析查询语句的查询操作
return mapperMethod.execute(sqlSession, args);
}
sqlSession.selectOne(String, Object):查询数据
public Object execute(SqlSession sqlSession, Object[] args) {
//.....
// 解析传入的参数
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
// DefaultSqlSession.selectList(String, Object)
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
// 获取执行者对象
MappedStatement ms = configuration.getMappedStatement(statement);
// 开始执行查询语句,参数通过 wrapCollection() 包装成集合类
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
}
Executor#query():
-
CachingExecutor.query():先执行 CachingExecutor 去二级缓存获取数据public class CachingExecutor implements Executor { private final Executor delegate; // 包装了 BaseExecutor,二级缓存不存在数据调用 BaseExecutor 查询 }-
MappedStatement.getBoundSql(parameterObject):把 parameterObject 封装成 BoundSql构造函数中有:
this.parameterObject = parameterObject[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r0DYiBlD-1686861880255)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-boundSql对象.png)]
-
CachingExecutor.createCacheKey():创建缓存对象 -
ms.getCache():获取二级缓存 -
tcm.getObject(cache, key):尝试从二级缓存中获取数据
-
-
BaseExecutor.query():二级缓存不存在该数据,调用该方法localCache.getObject(key):尝试从本地缓存(一级缓存)获取数据
-
BaseExecutor.queryFromDatabase():缓存获取数据失败,开始从数据库获取数据,并放入本地缓存-
SimpleExecutor.doQuery():执行 query-
configuration.newStatementHandler():创建 StatementHandler 对象- 根据 标签的 statementType 属性,根据属性选择创建哪种对象
- 判断 BoundSql 是否被创建,没有创建会重新封装参数信息到 BoundSql
- StatementHandler 的构造方法中,创建了 ParameterHandler 和 ResultSetHandler 对象
interceptorChain.pluginAll(statementHandler):拦截器链
-
prepareStatement():通过 StatementHandler 创建 JDBC 原生的 Statement 对象getConnection():获取 JDBC 的 Connection 对象handler.prepare():初始化 Statement 对象instantiateStatement(Connection connection):Connection 中的方法实例化对象- 获取普通执行者对象:
Connection.createStatement() - 获取预编译执行者对象:
Connection.prepareStatement()
- 获取普通执行者对象:
handler.parameterize():进行参数的设置ParameterHandler.setParameters():通过 ParameterHandler 设置参数typeHandler.setParameter():底层通过 TypeHandler 实现,回调 JDBC 的接口进行设置
-
StatementHandler.query():调用 JDBC 原生的 PreparedStatement 执行 SQLpublic <E> List<E> query(Statement statement, ResultHandler resultHandler) { // 获取 SQL 语句 String sql = boundSql.getSql(); statement.execute(sql); // 通过 ResultSetHandler 对象封装结果集,映射成 JavaBean return resultSetHandler.handleResultSets(statement); }resultSetHandler.handleResultSets(statement):处理结果集-
handleResultSet(rsw, resultMap, multipleResults, null):底层回调-
handleRowValues():逐行处理数据,根据是否配置了 属性选择是否使用简单结果集映射-
首先判断数据是否被限制行数,然后进行结果集的映射
-
最后将数据存入 ResultHandler 对象,底层就是 List 集合
public class DefaultResultHandler implements ResultHandler<Object> { private final List<Object> list; public void handleResult(ResultContext<?> context) { list.add(context.getResultObject()); } }
-
-
-
return collapseSingleResultList(multipleResults):可能存在多个结果集的情况
-
-
-
localCache.putObject(key, list):放入一级(本地)缓存
-
return list.get(0):返回结果集的第一个数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gDDNW2C5-1686861880255)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/MyBatis-执行SQL过程.png)]
插件使用
插件原理
实现原理:插件是按照插件配置顺序创建层层包装对象,执行目标方法的之后,按照逆向顺序执行(栈)

在四大对象创建时:
- 每个创建出来的对象不是直接返回的,而是
interceptorChain.pluginAll(parameterHandler) - 获取到所有 Interceptor(插件需要实现的接口),调用
interceptor.plugin(target)返回 target 包装后的对象 - 插件机制可以使用插件为目标对象创建一个代理对象,代理对象可以拦截到四大对象的每一个执行
@Intercepts(
{
@Signature(type=StatementHandler.class,method="parameterize",args=java.sql.Statement.class)
})
public class MyFirstPlugin implements Interceptor{
//intercept:拦截目标对象的目标方法的执行
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("MyFirstPlugin...intercept:" + invocation.getMethod());
//动态的改变一下sql运行的参数:以前1号员工,实际从数据库查询11号员工
Object target = invocation.getTarget();
System.out.println("当前拦截到的对象:" + target);
//拿到:StatementHandler==>ParameterHandler===>parameterObject
//拿到target的元数据
MetaObject metaObject = SystemMetaObject.forObject(target);
Object value = metaObject.getValue("parameterHandler.parameterObject");
System.out.println("sql语句用的参数是:" + value);
//修改完sql语句要用的参数
metaObject.setValue("parameterHandler.parameterObject", 11);
//执行目标方法
Object proceed = invocation.proceed();
//返回执行后的返回值
return proceed;
}
// plugin:包装目标对象的,为目标对象创建一个代理对象
@Override
public Object plugin(Object target) {
//可以借助 Plugin 的 wrap 方法来使用当前 Interceptor 包装我们目标对象
System.out.println("MyFirstPlugin...plugin:mybatis将要包装的对象" + target);
Object wrap = Plugin.wrap(target, this);
//返回为当前target创建的动态代理
return wrap;
}
// setProperties:将插件注册时的property属性设置进来
@Override
public void setProperties(Properties properties) {
System.out.println("插件配置的信息:" + properties);
}
}
核心配置文件:
<!--plugins:注册插件 -->
<plugins>
<plugin interceptor="mybatis.dao.MyFirstPlugin">
<property name="username" value="root"/>
<property name="password" value="123456"/>
</plugin>
</plugins>
分页插件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pGxHuUeH-1686861880256)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/分页介绍.png)]
- 分页可以将很多条结果进行分页显示。如果当前在第一页,则没有上一页。如果当前在最后一页,则没有下一页,需要明确当前是第几页,这一页中显示多少条结果。
- MyBatis 是不带分页功能的,如果想实现分页功能,需要手动编写 LIMIT 语句,不同的数据库实现分页的 SQL 语句也是不同,手写分页 成本较高。
- PageHelper:第三方分页助手,将复杂的分页操作进行封装,从而让分页功能变得非常简单
分页操作
开发步骤:
-
导入 PageHelper 的 Maven 坐标
-
在 MyBatis 核心配置文件中配置 PageHelper 插件
注意:分页助手的插件配置在通用 Mapper 之前
<plugins> <plugin interceptor="com.github.pagehelper.PageInterceptor"> <!-- 指定方言 --> <property name="dialect" value="mysql"/> </plugin> </plugins> <mappers>.........</mappers> -
与 MySQL 分页查询页数计算公式不同
static <E> Page<E> startPage(int pageNum, int pageSize):pageNum第几页,pageSize页面大小@Test public void selectAll() { //第一页:显示2条数据 PageHelper.startPage(1,2); List<Student> students = sqlSession.selectList("StudentMapper.selectAll"); for (Student student : students) { System.out.println(student); } }
参数获取
PageInfo构造方法:
PageInfo<Student> info = new PageInfo<>(list): list 是 SQL 执行返回的结果集合,参考上一节
PageInfo相关API:
- startPage():设置分页参数
- PageInfo:分页相关参数功能类。
- getTotal():获取总条数
- getPages():获取总页数
- getPageNum():获取当前页
- getPageSize():获取每页显示条数
- getPrePage():获取上一页
- getNextPage():获取下一页
- isIsFirstPage():获取是否是第一页
- isIsLastPage():获取是否是最后一页
mybatis(tedu)
1. 前课作业
-
创建数据库
tedu_umscreate database tedu_ums; -
创建数据表
t_user,该表中至少包含:id、username、password、age、phone、email,字段约束可自行设计,并保留SQL语句,下同create table t_user ( id int auto_increment, username varchar(16) unique not null, password varchar(16) not null, age int, phone varchar(20), email varchar(50), primary key(id) ) default charset=utf8; -
向
t_user表添加不少于10条数据insert into t_user ( username, password, age, phone, email ) values ( 'root', '12r435r34', 21, '13800138001', 'root@tedu.cn' ), ( 'admin', '12hghe34', 22, '13800138002', 'admin@tedu.cn' ), ( 'spring', '1234', 23, '13800138003', 'spring@tedu.cn' ), ( 'mybatis', '12cxv34', 24, '13800138004', 'mybatis@tedu.cn' ), ( 'html', '12876734', 25, '13800138005', 'html@tedu.cn' ), ( 'filter', '12132134', 26, '13800138006', 'filter@tedu.cn' ), ( 'jdbc', '1221434334', 27, '13800138007', 'jdbc@tedu.cn' ), ( 'java', '12r54334', 28, '13800138008', 'java@tedu.cn' ), ( 'mvc', '12ferdaf34', 29, '13800138009', 'mvc@tedu.cn' ), ( 'servlet', '12fdsaf34', 30, '13800138010', 'servlet@tedu.cn' ); -
查询
t_user表中所有数据select id, username, password, age, phone, email from t_user; -
获取
t_user表中数据的数量select count(id) from t_user; -
获取
t_user表指定username值为xx的数据select id, username, password, age, phone, email from t_user where username='mvc'; -
获取
t_user表中年龄从高到低排列的前5条数据select id, username, password, age, phone, email from t_user order by age desc limit 0, 5; -
删除
t_user表中指定username值为xx的数据delete from t_user where username='mvc'; -
将
t_user表中年龄大于xx的数据的密码修改为xxupdate t_user set password='P@ssw0rd' where age>26; -
修改
t_user表中指定id为xx的数据的电子邮箱是xxupdate t_user set email='user20@tedu.cn' where id=20;
2. MyBatis框架
2.1. 作用
解决持久层数据处理的问题,主要是基于JDBC技术的原生代码比较繁琐,没有经过任何优化,开发甚至执行效率低下!
使用MyBatis框架时,不必关心JDBC技术如何实现,只需要编写需要执行的操作的抽象方法,例如User findById(Integer id),然后,为这个方法映射所需执行的SQL语句即可。
2.2. 第1次使用MyBatis插入数据
前提:在数据库系统中已经存在tedu_ums数据库,且存在t_user表,结构可参考昨天的作业。
步骤1:创建项目
创建时,Artifact Id为MYBATIS,Group Id为cn.tedu.mybatis。
创建过程与前次课程相同。
步骤2:创建实体类
通常,每张数据表都有一个与之对应的实体类,在实体类中,有相同数量的属性,数据类型应该保持一致,属性名称与字段名应该一一对应(在Java中的属性名称应该采用驼峰命名法,而数据库领域中并不区分大小写),所有的属性都应该是私有的,且都存在公有的SET/GET方法,整个实体类应该是实现了Serializable接口的!
步骤3:添加依赖
<!-- MyBatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>
<!-- MyBatis与Spring整合 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.2</version>
</dependency>
<!-- Spring JDBC,版本需要与spring-webmvc保持一致 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.3.9.RELEASE</version>
</dependency>
<!-- MySQL连接 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
<!-- 数据库连接池 -->
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<!-- Junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
注意:下载的新的依赖的jar可能是损坏的文件,如果保证代码正确的前提下,无法得到预期的运行效果,应该删除本地仓库中的jar包并重新更新!
步骤4:配置数据库连接
在src\main\resources下创建db.properties文件,用于配置数据库连接的相关信息:
# data-source
url=jdbc:mysql://localhost:3306/tedu_ums?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
driver=com.mysql.cj.jdbc.Driver
username=root
password=root
initialSize=2
maxActive=10
然后,在src\main\resources下使用spring-dao.xml配置:
<!-- 读取db.properties -->
<util:properties id="dbConfig"
location="classpath:db.properties" />
<!-- 配置数据源 -->
<bean class="org.apache.commons.dbcp.BasicDataSource">
<!-- driverClassName是BasicDataSource中定义的名称 -->
<property name="driverClassName"
value="#{dbConfig.driver}" />
<property name="url"
value="#{dbConfig.url}" />
<property name="username"
value="#{dbConfig.username}" />
<property name="password"
value="#{dbConfig.password}" />
<property name="initialSize"
value="#{dbConfig.initialSize}" />
<property name="macActive"
value="#{dbConfig.maxActive}" />
</bean>
步骤5:编写方法
使用MyBatis时,无需自行编写JDBC相关代码,只需要创建Java接口文件,并将需要执行的数据操作的抽象方法添加在接口中即可!
通常,建议按照“增 > 查 > 删 > 改”的顺序开发相关功能。
目标:向数据表中插入新的用户数据。
则创建cn.tedu.mybatis.mapper.UserMapper接口,然后,添加“插入新的用户数据”的抽象方法:
Integer insert(User user);
使用MyBatis时,执行的增、删、改操作均返回
Integer,表示受影响的行数。
步骤6:编写XML映射
使用MyBatis时,还需要与接口的抽象方法对应的SQL语句,该SQL语句是在XML文件中配置的!
从FTP下载somemapper.zip,得到所需的XML文件,并重命名为UserMapper.xml。
通常,接口文件的数量与XML映射文件的数量是相同的,是一一对应的!
映射的XML文件应该存放到src\main\resources下,但是,项目中可能存在多个映射文件,为了便于管理,会在resources下创建mappers文件夹,然后把映射的XML文件放在这个文件夹中。
然后,配置该XML映射文件:
<!-- namespace:映射的接口的全名 -->
<mapper namespace="cn.tedu.mybatis.mapper.UserMapper">
<!-- 根据执行的SQL种类选择节点 -->
<!-- id:抽象方法的名称 -->
<!-- parameterType:抽象方法的参数类型 -->
<!-- SQL语句中的参数使用#{}框住User类中的属性名 -->
<!-- SQL语句不需要使用分号表示结束 -->
<insert id="insert"
parameterType="cn.tedu.mybatis.entity.User">
INSERT INTO t_user (
username, password,
age, phone, email
) VALUES (
#{username}, #{password},
#{age}, #{phone}, #{email}
)
</insert>
</mapper>
步骤7:完成MyBatis的配置
<!-- MyBatis:MapperScannerConfigurer -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<!-- 接口文件在哪里 -->
<property name="basePackage"
value="cn.tedu.mybatis.mapper" />
</bean>
<!-- MyBatis:SqlSessionFactoryBean -->
<bean class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 数据源 -->
<property name="dataSource"
ref="dataSource" />
<!-- XML文件在哪里 -->
<property name="mapperLocations"
value="classpath:mappers/*.xml" />
</bean>
步骤8:执行单元测试
public class UserMapperTestCase {
@Test
public void insert() {
AbstractApplicationContext ac
= new ClassPathXmlApplicationContext(
"spring-dao.xml");
UserMapper userMapper
= ac.getBean("userMapper", UserMapper.class);
User user = new User();
user.setUsername("mapper");
user.setPassword("1234");
user.setAge(31);
user.setPhone("13900139001");
user.setEmail("mapper@tedu.cn");
Integer rows = userMapper.insert(user);
System.out.println("rows=" + rows);
ac.close();
}
}
2.3. 获取当前表中所有用户数据
分析需要执行的SQL语句:
select * from t_user
设计抽象方法:
List<User> findAll();
在查询时,MyBatis会得到
List集合类型的结果,如果存在匹配的数据,则全部封装在该List集合中,如果没有匹配的数据,则返回的List集合是长度为0的集合。
配置映射:
<select id="findAll"
resultType="xx.xx.xx.User">
select * from t_user
</select>
任何查询都必须指定
resultType属性,当然,也可以替换为resultMap,关于resultMap,下周再讲……
2.4. 根据用户名查询用户数据
分析需要执行的SQL语句:
select * from t_user where username=?
设计抽象方法:
User findByUsername(String username);
查询时,如果返回值声明为某数据类型,却不是
List集合,MyBatis会尝试从List集合中取出第1个元素,如果存在,则返回该元素,如果不存在(没有匹配的结果,List集合的长度为0),则返回null。
配置映射:
<select id="findByUsername"
resultType="xx.xx.xx.User">
select * from t_user where username=#{username}
</select>
2.5. 获取t_user表中数据的数量
分析需要执行的SQL语句:
select count(id) from t_user
设计抽象方法:
Integer getCount();
在查询时,查询结果与返回值的类型相匹配即可!所以,如果查询的是数据的数量,查询结果是数字,所设计的抽象方法的返回值就可以是Integer。
配置映射:
<select id="getCount"
resultType="java.lang.Integer">
select count(id) from t_user
</select>
目前,所设计的抽象方法只允许存在最多1个参数!
2.6. 小结
-
MyBatis使用简单,可以简化开发,开发者不必关注数据库编程的细节;
-
使用MyBatis编程主要做好:(1)设计SQL语句; (2)设计抽象方法; (3)配置映射;
-
所有的
xx.properties和spring-dao.xml中的配置,需要理解,需要掌握修改配置值,不需要记住; -
关于抽象方法:如果是增删改操作,返回值固定设计为
Integer,如果是查询操作,根据查询结果来决定,例如可能是List<User>、User、Integer……;方法的名称应该尽量对应所执行的数据操作,而不应该是某个业务,例如插入数据的方法名可以是insert,或者addnew,但是不应该使用reg;目前,只允许使用最多1个参数,如果一定要使用多个,请封装为1个参数; -
关于映射配置:根据所执行的操作选择
<insert>、<delete>、<update>、<select>节点,无论是哪个节点,必须配置id,取值为对应的抽象方法的名称;在SQL语句中的参数使用#{}框住即可; -
关于执行结果:如果是增删改操作,只能获得受影响的行数,可以根据该结果判断操作成功与否;如果是执行查询操作,当结果声明为
List时,无论是否查询到数据,返回有效的List集合对象,如果没有匹配的数据,则List的长度为0;当结果声明为某个对象,例如User时,如果没有匹配的数据,则返回null。
1. 执行插入数据时获取自增长的id
当需要获取新增的数据的id时,首先,需要在<insert>节点中添加2个属性:
useGeneratedKeys="true"
keyProperty="id"
以上配置中,useGeneratedKeys表示获取自增长的键(自增长的字段的值),keyProperty表示键的属性名,即对应的类中的属性名(即该id是User类中的id,并非t_user表中的id)!
添加以上配置之后,插入数据操作的返回值依然表示“受影响的行数”,但是,用于执行插入操作的参数对象中就会包含自动生成的id值,例如,调用时的代码:
System.out.println("增加前:" + user);
Integer rows = userMapper.insert(user);
System.out.println("rows=" + rows);
System.out.println("增加后:" + user);
结果例如:
增加前:User [id=null, username=jsd1808, password=1234, age=31, phone=13900139008, email=jsd1808@tedu.cn]
rows=1
增加后:User [id=24, username=jsd1808, password=1234, age=31, phone=13900139008, email=jsd1808@tedu.cn]
可以记住:在配置时,需要配置4个属性。
2. 使用多个参数
功能设定:将t_user表中年龄大于xx的数据的密码修改为xx
分析所执行的SQL语句:
update t_user set password=? where age>?
抽象方法:
Integer updatePasswordByAge(
Integer age, String password);
SQL映射:
<update id="updatePasswordByAge">
update t_user
set
password=#{password}
where
age>#{age}
</update>
直接调用,会报告错误:
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.binding.BindingException: Parameter 'password' not found. Available parameters are [arg1, arg0, param1, param2]
Caused by: org.apache.ibatis.binding.BindingException: Parameter 'password' not found. Available parameters are [arg1, arg0, param1, param2]
因为.java文件在编译后变成.class文件就会丢失参数名称,在最终执行的.class文件中,根本就不存在名为password或age的参数,所以,程序会报错,可行的解决方法是把多个参数封装到一个Map中,这样的话,此前使用的方法名称例如age或password就会变成Map的key,是一些字符串,并不会因为编译而丢失,最终运行就不会有问题,当然,每次运行时都需要自行将参数封装为Map,操作麻烦,还存在key拼写错误的风险,所以,MyBatis提供了@Param注解以解决这个问题:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m3yt8vR2-1686861880256)(C:\Users\Administrator\Desktop\gitee\study\增强版笔记\ssm\08.png)]
解决多个参数的问题:可以将多个参数封装为1个Map,或封装为1个自定义的数据类型,但是,更推荐使用@Param注解。
3. 关于resultMap
使用resultMap可以解决名称不匹配的问题!例如在数据表中存在is_delete字段,则实体类存在isDelete属性,则数据表中使用的名称与实体类中的属性名不一致!
前置操作:
alter table t_user add column is_delete int default 0;
update t_user set is_delete=1 where id in (11,13,15);
然后,在User类中添加private Integer isDelete;及SET/GET方法,重新生成toString()。
名称不匹配的问题可以通过自定义别名来解决,例如:
<select id="findAll"
resultType="cn.tedu.mybatis.entity.User">
select
id, username, password,
age, phone, email,
is_delete AS isDelete
from t_user
</select>
也就是:MyBatis的要求是“查询结果中的列名与返回值类型的属性名必须一致”,通过自定义别名就可以满足这个要求,并不需要通过<resultMap>来实现!
通常,需要自定义<resultMap>时,主要用于解决多表数据关联查询的问题。
例如:
create table t_department (
id int auto_increment,
name varchar(20) not null,
primary key(id)
);
insert into t_department (name) values ('UI'), ('RD'), ('TEST');
alter table t_user add column department int;
通常实体类都是与数据表一一对应的,符合设计规范,但不适用于多表的关联查询,例如当需要“查询某个部门信息的同时需要获取该部门的所有员工的信息”,则没有任何数据类型可以匹配这样的信息,为了解决这样的问题,通常会定义VO类,即Value Object类,这种类型是专用于解决实体类不满足使用需求而存在的,类的设计结构与实体类非常相似,但是,属性的设计是完全根据使用需求来决定的,例如:
public class DepartmentVO {
private Integer depId;
private String depName;
private List<User> users;
// SET/GET方法,toString(),序列化接口
}
普通的查询无法得到以上结果,查询语句可能是:
select
t_user.id, username, password, age, phone, email, is_delete,
t_department.id AS dep_id, name
from
t_user, t_department
where
t_user.department=t_department.id
and t_department.id=?
以上查询易于理解,通俗易懂,但是,不推荐使用,更推荐使用JOIN系列的查询语法:
SELECT
t_user.id, username, password, age, phone, email, is_delete,
t_department.id AS dep_id, name
FROM
t_user
INNER JOIN
t_department
ON
t_user.department=t_department.id
WHERE
t_department.id=?
这样的查询结果可能有好几行,
需要有效的封装到1个对象中,就必须依靠<resultMap>来设计封装的规则:
<!-- id:节点的唯一标识 -->
<!-- type:数据类型 -->
<resultMap id="DepartmentVoMap"
type="cn.tedu.mybatis.vo.DepartmentVO">
<!-- id节点:主键的配置 -->
<!-- column:查询结果的列名 -->
<!-- property:数据类型的属性名 -->
<id column="dep_id" property="depId"/>
<!-- 其它结果的配置 -->
<result column="name" property="depName"/>
<!-- 配置List集合 -->
<!-- ofType:集合中放的哪种类型的数据 -->
<collection property="users"
ofType="cn.tedu.mybatis.entity.User">
<!-- 自此开始,property表示User中的属性名 -->
<id column="id" property="id"/>
<result column="username" property="username"/>
<result column="password" property="password"/>
<result column="age" property="age"/>
<result column="phone" property="phone"/>
<result column="email" property="email"/>
<result column="is_delete" property="isDelete"/>
</collection>
</resultMap>
配置方式可参考:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gPYa1RBy-1686861880257)(C:\Users\Administrator\Desktop\gitee\study\增强版笔记\ssm\09.png)]
最后,应用时,与普通的数据操作相同,先添加接口与抽象方法:
public interface DepartmentMapper {
DepartmentVO findById(Integer id);
}
然后配置映射:
<select id="findById"
resultMap="DepartmentVoMap">
SELECT
t_department.id AS dep_id, name,
t_user.id, username, password,
age, phone, email,
is_delete
FROM
t_user
INNER JOIN
t_department
ON
t_user.department=t_department.id
WHERE
t_department.id=#{id}
</select>
最终,执行查询获取的结果例如:
DepartmentVO [
depId=2,
depName=RD,
users=[
User [id=13, username=spring, password=1234, age=23, phone=13800138003, email=spring@tedu.cn, isDelete=1, department=null],
User [id=14, username=mybatis, password=12cxv34, age=24, phone=13800138004, email=mybatis@tedu.cn, isDelete=0, department=null],
User [id=17, username=jdbc, password=88888888, age=27, phone=13800138007, email=jdbc@tedu.cn, isDelete=1, department=null],
User [id=21, username=mapper, password=88888888, age=31, phone=13900139001, email=mapper@tedu.cn, isDelete=1, department=null],
User [id=23, username=namespace, password=88888888, age=31, phone=13900139002, email=namespace@tedu.cn, isDelete=1, department=null]
]
]
如果提示错误TooManyResultsException,则错误多半在于查询结果的列名与<resultMap>中普通的<id/>或<result/>节点的column的配置有误!也有可能存在例如2列的名称都是id,却有多条数据的id值不同的问题!
练习:存在学生表和班级表,学生表t_student中包括id, name, age, class_id,班级表t_class中包括id, name,最终,查询时,查某班级数据时将显示该班级所有学生的信息。涉及的类为Student、Clazz。
练习步骤1:创建2张数据表,插入一定量的数据,创建对应的实体类,创建班级的VO类:
create table t_class (
id int auto_increment,
name varchar(20),
primary key (id)
);
insert into t_class (name) values ('JSD1806'),('JSD1807'),('JSD1808');
create table t_student (
id int auto_increment,
name varchar(20),
age int,
class_id int,
primary key (id)
);
insert into t_student (name,age,class_id) values ('Mike', 20, 1), ('Tom', 21, 2), ('Terry', 21, 3), ('Jerry', 22, 2), ('Lucy', 22, 1), ('Kitty', 22, 2), ('Lily', 21, 3), ('Lilei', 20, 3), ('HanMM', 23, 3), ('XiaoMing', 21, 2);
练习步骤2:创建cn.tedu.mybatis.mapper.ClazzMapper接口,复制得到src\main\resources\ClazzMapper.xml映射文件,这2个文件都是空文件即可。
练习步骤3:设计SQL语句:
SELECT
t_class.id AS cls_id,
t_class.name AS cls_name,
t_student.id AS stu_id,
t_student.name AS stu_name,
age, class_id
FROM
t_class
INNER JOIN
t_student
ON
t_class.id=t_student.class_id
WHERE
t_class.id=?;
练习步骤4:抽象方法
ClazzVO findById(Integer id);
练习步骤5:配置<select>
<select id="findById"
resultMap="ClazzVOMapper">
SELECT
t_class.id AS cls_id,
t_class.name AS cls_name,
t_student.id AS stu_id,
t_student.name AS stu_name,
age, class_id
FROM
t_class
INNER JOIN
t_student
ON
t_class.id=t_student.class_id
WHERE
t_class.id=#{id};
</select>
练习步骤6:配置<resultMap>
<resultMap id="ClazzVOMapper"
type="cn.tedu.mybatis.vo.ClazzVO">
<id column="cls_id" property="clsId"/>
<result column="cls_name" property="clsName"/>
<collection property="student"
ofType="cn.tedu.mybatis.entity.Student">
<id column="stu_id" property="id"/>
<result column="stu_name" property="name"/>
<result column="age" property="age"/>
<result column="class_id" property="classId"/>
</collection>
</resultMap>
课后练习:新添加考试成绩表t_score,包括字段id(int)、stu_id(int), subject(varchar), score(int),要求最终实现:根据学生id查询出该学生的所有成绩,例如:
XX学生成绩单
学号:xx 姓名:xx
序号 | 科目 | 分数
1 Java 80
2 SQL 70
1. MyBatis中的占位符
在MyBatis中,常见的占位符格式是#{参数},其中,也可能是参数对象中的属性,如果参数是Map类型,还可以是Map中的key。
使用#{}的占位符可用于替换值,例如:
select * from t_user where username=?
即可替换以上语句中的问号(?),在实际运行时,MyBatis会将以上SQL语句进行预编译,并后续使用#{}替换问号(?)。
假设获取用户列表时,排序规则不确定,可能使用的抽象方法是:
List<User> findAllOrderedList(String orderBy);
配置的映射可能是:
<select id="xx" resultType="xx">
select * from t_user
order by #{orderBy}
</select>
调用时:
mapper.findAllOrderedList("id asc");
mapper.findAllOrderedList("id desc");
以上代码的执行效果是失败的!需要将#{}修改为${},且在抽象方法中,这样的参数必须添加@Param注解,即:
List<User> findAllOrderedList(
@Param("orderBy") String orderBy);
<select id="xx" resultType="xx">
select * from t_user
order by ${orderBy}
</select>
然后,在调用时,就可以根据参数的不同,实现不同的排序效果!
使用${}格式的占位符并不具备预编译的效果!它是直接拼接形成的SQL语句,例如:"select * from t_user order by" + orderBy,如果一定使用${}格式的占位符来表示某个值,还需要考虑单引号类似的问题,例如:select * from t_user where username='${username}',由于只是拼接,所以,还存在SQL注入风险!
小结
使用#{}是预编译的(没有SQL注入风险,无需关注数据类型),使用${}不是预编译的;
使用#{}只能替换某个值,使用${}可以替换SQL语句中的任何部分;
关于SQL注入,不需要太过于紧张,预编译可以从根源上杜绝,或者,在执行SQL指令之前,判断参数中是否包含单引号也可以杜绝!
通过使用${},可以使得SQL更加灵活,更加通用!但是,却不推荐太过于通用的SQL!因为,即使查询条件可以自由更改,但是,不同的查询条件对应不同的需求,所需的字段列表很有可能是不一样的,查询时,获取不必要的字段,就会造成不必要的资源浪费,例如,显示列表时,可能需要用户名、密码、年龄、手机、邮箱,但是,登录的查询就只需要用户名、密码即可,年龄、手机、邮箱这几项数据在登录时是不需要的,如果也查询出来,就是浪费资源!如果变量太多,又会导致不可控因素太多,容易出错!
2. 动态SQL
在MyBatis的映射文件中,配置SQL语句时,可以添加例如<if>此类的标签,实现SQL语句的动态变化,即:参数不同,最终执行的SQL语句可能是不同的!
在使用动态SQL时,最常用的就是<if>和<foreach>这两种,<if>是用于判断的,例如:
select
*
from
t_user
<if test="where != null">
where
${where}
</if>
<if test="orderBy != null">
order by
${orderBy}
</if>
关于<foreach>,主要用于循环处理SQL语句中的某个部分,例如:批量删除某些数据!它的SQL语句可能是:
delete from t_user where id in (?,?,?)
其中,in关键字右侧的括号中的内容是不确定的,应该是由用户操作时决定的!则需要<foreach>动态的生成这个部分!
针对这个问题,设计的抽象方法可能是:
Integer deleteByIds(Integer[] ids);
配置的映射为:
<delete id="deleteByIds">
delete from
t_user
where
id in (
<foreach collection="array"
item="id" separator=",">
#{id}
</foreach>
)
</delete>
以上配置的<foreach>中,collection表示被遍历的集合对象,当抽象方法只有1个参数时,取值为list或array,取决于集合对象的数据类型,当抽象方法 有多个参数时,使用@Param注解中的名称,item表示遍历过程中的变量名,separator表示分隔符。
以上配置还可以调整为:
id in
<foreach collection="array"
item="id" separator=","
open="(" close=")">
#{id}
</foreach>
即:open表示由<foreach>处理的SQL语句的起始部分的字符串,而close表示结束部分的字符串。
Spring
概述
Spring 是分层的 JavaSE/EE 应用 full-stack 轻量级开源框架
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l8qhNv9h-1686861880257)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/Spring-框架介绍.png)]
Spring 优点:
- 方便解耦,简化开发
- 方便集成各种框架
- 方便程序测试
- AOP 编程难过的支持
- 声明式事务的支持
- 降低 JavaEE API 的使用难度
体系结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hx9VDgqR-1686861880258)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/Spring-体系结构.png)]
参考视频:https://space.bilibili.com/37974444
IoC
基本概述
- IoC(Inversion Of Control)控制反转,Spring 反向控制应用程序所需要使用的外部资源
- Spring 控制的资源全部放置在 Spring 容器中,该容器称为 IoC 容器(存放实例对象)
- 官方网站:https://spring.io/ → Projects → spring-framework → LEARN → Reference Doc
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FVTnpZam-1686861880258)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/Spring-IOC介绍.png)]
- 耦合(Coupling):代码编写过程中所使用技术的结合紧密度,用于衡量软件中各个模块之间的互联程度
- 内聚(Cohesion):代码编写过程中单个模块内部各组成部分间的联系,用于衡量软件中各个功能模块内部的功能联系
- 代码编写的目标:高内聚,低耦合。同一个模块内的各个元素之间要高度紧密,各个模块之间的相互依存度不紧密
入门项目
模拟三层架构中表现层调用业务层功能
-
表现层:UserApp 模拟 UserServlet(使用 main 方法模拟)
-
业务层:UserService
步骤:
-
导入 spring 坐标(5.1.9.release)
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.1.9.RELEASE</version> </dependency> -
编写业务层与表现层(模拟)接口与实现类 service.UserService,service.impl.UserServiceImpl
public interface UserService { //业务方法 void save(); }public class UserServiceImpl implements UserService { public void save() { System.out.println("user service running..."); } } -
建立 Spring 配置文件:resources.applicationContext.xml (名字一般使用该格式)
-
配置所需资源(Service)为 Spring 控制的资源
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- 1.创建spring控制的资源--> <bean id="userService" class="service.impl.UserServiceImpl"/> </beans> -
表现层(App)通过 Spring 获取资源(Service 实例)
public class UserApp { public static void main(String[] args) { //2.加载配置文件 ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); //3.获取资源 UserService userService = (UserService) ctx.getBean("userService"); userService.save();//user service running... } }[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sGek8qsU-1686861880258)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/Spring-IOC实现.png)]
XML开发
bean
基本属性
标签: 标签, 的子标签
作用:定义 Spring 中的资源,受此标签定义的资源将受到 Spring 控制
格式:
<beans>
<bean />
</beans>
基本属性
- id:bean 的名称,通过 id 值获取 bean (首字母小写)
- class:bean 的类型,使用完全限定类名
- name:bean 的名称,可以通过 name 值获取 bean,用于多人配合时给 bean 起别名
<bean id="beanId" name="beanName1,beanName2" class="ClassName"></bean>
ctx.getBean("beanId") == ctx.getBean("beanName1") == ctx.getBean("beanName2")
作用范围
作用:定义 bean 的作用范围
格式:
<bean scope="singleton"></bean>
取值:
- singleton:设定创建出的对象保存在 Spring 容器中,是一个单例的对象
- prototype:设定创建出的对象保存在 Spring 容器中,是一个非单例(原型)的对象
- request、session、application、 websocket :设定创建出的对象放置在 web 容器对应的位置
Spring 容器中 Bean 的线程安全问题:
-
原型 Bean,每次创建一个新对象,线程之间并不存在 Bean 共享,所以不会有线程安全的问题
-
单例 Bean,所有线程共享一个单例实例 Bean,因此是存在资源的竞争,如果单例 Bean是一个无状态 Bean,也就是线程中的操作不会对 Bean 的成员执行查询以外的操作,那么这个单例 Bean 是线程安全的
解决方法:开发人员来进行线程安全的保证,最简单的办法就是把 Bean 的作用域 singleton 改为 protopyte
生命周期
作用:定义 bean 对象在初始化或销毁时完成的工作
格式:
<bean init-method="init" destroy-method="destroy></bean>
取值:bean 对应的类中对应的具体方法名
实现接口的方式实现初始化,无需配置文件配置 init-method:
- 实现 InitializingBean,定义初始化逻辑
- 实现 DisposableBean,定义销毁逻辑
注意事项:
- 当 scope=“singleton” 时,Spring 容器中有且仅有一个对象,init 方法在创建容器时仅执行一次
- 当 scope=“prototype” 时,Spring 容器要创建同一类型的多个对象,init 方法在每个对象创建时均执行一次
- 当 scope=“singleton” 时,关闭容器(
.close())会导致 bean 实例的销毁,调用 destroy 方法一次 - 当 scope=“prototype” 时,对象的销毁由垃圾回收机制 GC 控制,destroy 方法将不会被执行
bean 配置:
<!--init-method和destroy-method用于控制bean的生命周期-->
<bean id="userService3" scope="prototype" init-method="init" destroy-method="destroy" class="service.impl.UserServiceImpl"/>
业务层实现类:
public class UserServiceImpl implements UserService{
public UserServiceImpl(){
System.out.println(" constructor is running...");
}
public void init(){
System.out.println("init....");
}
public void destroy(){
System.out.println("destroy....");
}
public void save() {
System.out.println("user service running...");
}
}
测试类:
UserService userService = (UserService)ctx.getBean("userService3");
创建方式
-
静态工厂
作用:定义 bean 对象创建方式,使用静态工厂的形式创建 bean,兼容早期遗留系统的升级工作
格式:
<bean class="FactoryClassName" factory-method="factoryMethodName"></bean>取值:工厂 bean 中用于获取对象的静态方法名
注意事项:class 属性必须配置成静态工厂的类名
bean 配置:
<!--静态工厂创建 bean--> <bean id="userService4" class="service.UserServiceFactory" factory-method="getService"/>工厂类:
public class UserServiceFactory { public static UserService getService(){ System.out.println("factory create object..."); return new UserServiceImpl(); } }测试类:
UserService userService = (UserService)ctx.getBean("userService4"); -
实例工厂
作用:定义 bean 对象创建方式,使用实例工厂的形式创建 bean,兼容早期遗留系统的升级工作
格式:
<bean factory-bean="factoryBeanId" factory-method="factoryMethodName"></bean>注意事项:
-
使用实例工厂创建 bean 首先需要将实例工厂配置 bean,交由 Spring 进行管理
-
factory-bean 是实例工厂的 Id
bean 配置:
<!--实例工厂创建 bean,依赖工厂对象对应的 bean--> <bean id="factoryBean" class="service.UserServiceFactory2"/> <bean id="userService5" factory-bean="factoryBean" factory-method="getService"/>工厂类:
public class UserServiceFactory2 { public UserService getService(){ System.out.println(" instance factory create object..."); return new UserServiceImpl(); } } -
获取Bean
ApplicationContext 子类相关API:
| 方法 | 说明 |
|---|---|
| String[] getBeanDefinitionNames() | 获取 Spring 容器中定义的所有 JavaBean 的名称 |
| BeanDefinition getBeanDefinition(String beanName) | 返回给定 bean 名称的 BeanDefinition |
| String[] getBeanNamesForType(Class<?> type) | 获取 Spring 容器中指定类型的所有 JavaBean 的名称 |
| Environment getEnvironment() | 获取与此组件关联的环境 |
DI
依赖注入
-
IoC(Inversion Of Control)控制翻转,Spring 反向控制应用程序所需要使用的外部资源
-
DI(Dependency Injection)依赖注入,应用程序运行依赖的资源由 Spring 为其提供,资源进入应用程序的方式称为注入,简单说就是利用反射机制为类的属性赋值的操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KGqilJjw-1686861880259)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/Spring-DI介绍.png)]
IoC 和 DI 的关系:IoC 与 DI 是同一件事站在不同角度看待问题
set 注入
标签: 标签, 的子标签
作用:使用 set 方法的形式为 bean 提供资源
格式:
<bean>
<property />
<property />
.....
</bean>
基本属性:
- name:对应 bean 中的属性名,要注入的变量名,要求该属性必须提供可访问的 set 方法(严格规范此名称是 set 方法对应名称,首字母必须小写)
- value:设定非引用类型属性对应的值,不能与 ref 同时使用
- ref:设定引用类型属性对应 bean 的 id ,不能与 value 同时使用
<property name="propertyName" value="propertyValue" ref="beanId"/>
代码实现:
-
DAO 层:要注入的资源
public interface UserDao { public void save(); }public class UserDaoImpl implements UserDao{ public void save(){ System.out.println("user dao running..."); } } -
Service 业务层
public interface UserService { public void save(); }public class UserServiceImpl implements UserService { private UserDao userDao; private int num; //1.对需要进行注入的变量添加set方法 public void setUserDao(UserDao userDao) { this.userDao = userDao; } public void setNum(int num) { this.num = num; } public void save() { System.out.println("user service running..." + num); userDao.save(); bookDao.save(); } } -
配置 applicationContext.xml
<!--2.将要注入的资源声明为bean--> <bean id="userDao" class="dao.impl.UserDaoImpl"/> <bean id="userService" class="service.impl.UserServiceImpl"> <!--3.将要注入的引用类型的变量通过property属性进行注入,--> <property name="userDao" ref="userDao"/> <property name="num" value="666"/> </bean> -
测试类
public class UserApp { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); UserService userService = (UserService) ctx.getBean("userService"); userService.save(); } }
构造注入
标签: 标签, 的子标签
作用:使用构造方法的形式为 bean 提供资源,兼容早期遗留系统的升级工作
格式:
<bean>
<constructor-arg />
.....<!--一个bean可以有多个constructor-arg标签-->
</bean>
属性:
- name:对应bean中的构造方法所携带的参数名
- value:设定非引用类型构造方法参数对应的值,不能与 ref 同时使用
- ref:设定引用类型构造方法参数对应 bean 的 id ,不能与 value 同时使用
- type:设定构造方法参数的类型,用于按类型匹配参数或进行类型校验
- index:设定构造方法参数的位置,用于按位置匹配参数,参数 index 值从 0 开始计数
<constructor-arg name="argsName" value="argsValue" />
<constructor-arg index="arg-index" type="arg-type" ref="beanId"/>
代码实现:
-
DAO 层:要注入的资源
public class UserDaoImpl implements UserDao{ private String username; private String pwd; private String driver; public UserDaoImpl(String driver,String username, String pwd) { this.driver = driver; this.username = username; this.pwd = pwd; } public void save(){ System.out.println("user dao running..."+username+" "+pwd+" "+driver); } } -
Service 业务层:参考 set 注入
-
配置 applicationContext.xml
<bean id="userDao" class="dao.impl.UserDaoImpl"> <!--使用构造方法进行注入,需要保障注入的属性与bean中定义的属性一致--> <!--一致指顺序一致或类型一致或使用index解决该问题--> <constructor-arg index="2" value="123"/> <constructor-arg index="1" value="root"/> <constructor-arg index="0" value="com.mysql.jdbc.Driver"/> </bean> <bean id="userService" class="service.impl.UserServiceImpl"> <property name="userDao" ref="userDao"/> <property name="num" value="666"/> </bean>方式二:使用 UserServiceImpl 的构造方法注入
<bean id="userService" class="service.impl.UserServiceImpl"> <constructor-arg name="userDao" ref="userDao"/> <constructor-arg name="num" value="666666"/> </bean> -
测试类:参考 set 注入
集合注入
标签:
作用:注入集合数据类型属性
格式:
<property>
<list></list>
</property>
代码实现:
-
DAO 层:要注入的资源
public interface BookDao { public void save(); }public class BookDaoImpl implements BookDao { private ArrayList al; private Properties properties; private int[] arr; private HashSet hs; private HashMap hm ; public void setAl(ArrayList al) { this.al = al; } public void setProperties(Properties properties) { this.properties = properties; } public void setArr(int[] arr) { this.arr = arr; } public void setHs(HashSet hs) { this.hs = hs; } public void setHm(HashMap hm) { this.hm = hm; } public void save() { System.out.println("book dao running..."); System.out.println("ArrayList:" + al); System.out.println("Properties:" + properties); for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); } System.out.println("HashSet:" + hs); System.out.println("HashMap:" + hm); } } -
Service 业务层
public class UserServiceImpl implements UserService { private BookDao bookDao; public UserServiceImpl() {} public void setBookDao(BookDao bookDao) { this.bookDao = bookDao; } public void save() { System.out.println("user service running..." + num); bookDao.save(); } } -
配置 applicationContext.xml
<bean id="userService" class="service.impl.UserServiceImpl"> <property name="bookDao" ref="bookDao"/> </bean> <bean id="bookDao" class="dao.impl.BookDaoImpl"> <property name="al"> <list> <value>seazean</value> <value>66666</value> </list> </property> <property name="properties"> <props> <prop key="name">seazean666</prop> <prop key="value">666666</prop> </props> </property> <property name="arr"> <array> <value>123456</value> <value>66666</value> </array> </property> <property name="hs"> <set> <value>seazean</value> <value>66666</value> </set> </property> <property name="hm"> <map> <entry key="name" value="seazean66666"/> <entry key="value" value="6666666666"/> </map> </property> </bean>
P
标签:<p:propertyName>,<p:propertyName-ref>
作用:为 bean 注入属性值
格式:
<bean p:propertyName="propertyValue" p:propertyName-ref="beanId"/>
开启 p 命令空间:开启 Spring 对 p 命令空间的的支持,在 beans 标签中添加对应空间支持
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
</beans>
实例:
<bean
id="userService"
class="service.impl.UserServiceImpl"
p:userDao-ref="userDao"
p:bookDao-ref="bookDao"
p:num="10"
/>
SpEL
Spring 提供了对 EL 表达式的支持,统一属性注入格式
作用:为 bean 注入属性值
格式:
<property value="EL">
注意:所有属性值不区分是否引用类型,统一使用value赋值
所有格式统一使用 value=“#{}”
-
常量 #{10} #{3.14} #{2e5} #{‘it’}
-
引用 bean #{beanId}
-
引用 bean 属性 #{beanId.propertyName}
-
引用 bean 方法 beanId.methodName().method2()
-
引用静态方法 T(java.lang.Math).PI
-
运算符支持 #{3 lt 4 == 4 ge 3}
-
正则表达式支持 #{user.name matches‘[a-z]{6,}’}
-
集合支持 #{likes[3]}
实例:
<bean id="userService" class="service.impl.UserServiceImpl">
<property name="userDao" value="#{userDao}"/>
<property name="bookDao" value="#{bookDao}"/>
<property name="num" value="#{666666666}"/>
</bean>
prop
Spring 提供了读取外部 properties 文件的机制,使用读取到的数据为 bean 的属性赋值
操作步骤:
-
准备外部 properties 文件
-
开启 context 命名空间支持
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd "> -
加载指定的 properties 文件
<context:property-placeholder location="classpath:data.properties" /> -
使用加载的数据
<property name="propertyName" value="${propertiesName}"/>
-
注意:如果需要加载所有的 properties 文件,可以使用
*.properties表示加载所有的 properties 文件 -
注意:读取数据使用 ${propertiesName} 格式进行,其中 propertiesName 指 properties 文件中的属性名
代码实现:
-
data.properties
username=root pwd=123456 -
DAO 层:注入的资源
public interface UserDao { public void save(); }public class UserDaoImpl implements UserDao{ private String userName; private String password; public void setUserName(String userName) { this.userName = userName; } public void setPassword(String password) { this.password = password; } public void save(){ System.out.println("user dao running..."+userName+" "+password); } } -
Service 业务层
public class UserServiceImpl implements UserService { private UserDao userDao; public void setUserDao(UserDao userDao) { this.userDao = userDao; } public void save() { System.out.println("user service running..."); userDao.save(); } } -
applicationContext.xml
<context:property-placeholder location="classpath:*.properties"/> <bean id="userDao" class="dao.impl.UserDaoImpl"> <property name="userName" value="${username}"/> <property name="password" value="${pwd}"/> </bean> <bean id="userService" class="service.impl.UserServiceImpl"> <property name="userDao" ref="userDao"/> </bean> -
测试类
public class UserApp { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); UserService userService = (UserService) ctx.getBean("userService"); userService.save(); } }
import
标签:,标签的子标签
作用:在当前配置文件中导入其他配置文件中的项
格式:
<beans>
<import />
</beans>
属性:
- resource:加载的配置文件名
<import resource=“config2.xml"/>
Spring 容器加载多个配置文件:
-
applicationContext-book.xml
<bean id="bookDao" class="dao.impl.BookDaoImpl"> <property name="num" value="1"/> </bean> -
applicationContext-user.xml
<bean id="userDao" class="dao.impl.UserDaoImpl"> <property name="userName" value="${username}"/> <property name="password" value="${pwd}"/> </bean> <bean id="userService" class="service.impl.UserServiceImpl"> <property name="userDao" ref="userDao"/> <property name="bookDao" ref="bookDao"/> </bean> -
applicationContext.xml
<import resource="applicationContext-user.xml"/> <import resource="applicationContext-book.xml"/> <bean id="bookDao" class="com.seazean.dao.impl.BookDaoImpl"> <property name="num" value="2"/> </bean> -
测试类
new ClassPathXmlApplicationContext("applicationContext-user.xml","applicationContext-book.xml"); new ClassPathXmlApplicationContext("applicationContext.xml");
Spring 容器中的 bean 定义冲突问题
-
同 id 的 bean,后定义的覆盖先定义的
-
导入配置文件可以理解为将导入的配置文件复制粘贴到对应位置,程序执行选择最下面的配置使用
-
导入配置文件的顺序与位置不同可能会导致最终程序运行结果不同
三方资源
Druid
第三方资源配置
-
pom.xml
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.16</version> </dependency> -
applicationContext.xml
<!--加载druid资源--> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"> <property name="driverClassName" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://192.168.2.185:3306/spring_db"/> <property name="username" value="root"/> <property name="password" value="123456"/> </bean> -
App.java
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); DruidDataSource datasource = (DruidDataSource) ctx.getBean("datasource"); System.out.println(datasource);
Mybatis
Mybatis 核心配置文件消失
-
环境 environment 转换成数据源对象
-
映射 Mapper 扫描工作交由 Spring 处理
-
类型别名交由 Spring 处理
DAO 接口不需要创建实现类,MyBatis-Spring 提供了一个动态代理的实现 MapperFactoryBean,这个类可以让直接注入数据映射器接口到 service 层 bean 中,底层将会动态代理创建类
整合原理:利用 Spring 框架的 SPI 机制,在 META-INF 目录的 spring.handlers 中给 Spring 容器中导入 NamespaceHandler 类
-
NamespaceHandler 的 init 方法注册 bean 信息的解析器 MapperScannerBeanDefinitionParser
-
解析器在 Spring 容器创建过程中去解析 mapperScanner 标签,解析出的属性填充到 MapperScannerConfigurer 中
-
MapperScannerConfigurer 实现了 BeanDefinitionRegistryPostProcessor 接口,重写 postProcessBeanDefinitionRegistry() 方法,可以扫描到 MyBatis 的 Mapper
注解开发
注解驱动
XML
启动注解扫描,加载类中配置的注解项:
<context:component-scan base-package="packageName1,packageName2"/>
说明:
- 在进行包扫描时,会对配置的包及其子包中所有文件进行扫描,多个包采用
,隔开 - 扫描过程是以文件夹递归迭代的形式进行的
- 扫描过程仅读取合法的 Java 文件
- 扫描时仅读取 Spring 可识别的注解
- 扫描结束后会将可识别的有效注解转化为 Spring 对应的资源加入 IoC 容器
- 从加载效率上来说注解优于 XML 配置文件
注解:启动时使用注解的形式替代 xml 配置,将 Spring 配置文件从工程中消除,简化书写
缺点:为了达成注解驱动的目的,可能会将原先很简单的书写,变的更加复杂。XML 中配置第三方开发的资源是很方便的,但使用注解驱动无法在第三方开发的资源中进行编辑,因此会增大开发工作量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1oX1FUMK-1686861880267)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/注解驱动示例.png)]
纯注解
注解配置类
名称:@Configuration、@ComponentScan
类型:类注解
作用:设置当前类为 Spring 核心配置加载类
格式:
@Configuration
@ComponentScan({"scanPackageName1","scanPackageName2"})
public class SpringConfigClassName{
}
说明:
- 核心配合类用于替换 Spring 核心配置文件,此类可以设置空的,不设置变量与属性
- bean 扫描工作使用注解 @ComponentScan 替代,多个包用
{} 和 ,隔开
加载纯注解格式上下文对象,需要使用 AnnotationConfigApplicationContext
@Configuration
public class SpringConfig {
@Bean
public Person person() {
return new Person1("lisi", 20);
}
}
public class MainTest {
public static void main(String[] args) {
ApplicationContext applicationContext = new
AnnotationConfigApplicationContext(SpringConfig.class);
//方式一:名称对应类名
Person bean = applicationContext.getBean(Person.class);
System.out.println(bean);
//方式二:名称对应方法名
Person bean1 = (Person) applicationContext.getBean("person1");
//方法三:指定名称@Bean("person2")
}
}
扫描器
组件扫描过滤器
开发过程中,需要根据需求加载必要的 bean,排除指定 bean
名称:@ComponentScan
类型:类注解
作用:设置 Spring 配置加载类扫描规则
格式:
@ComponentScan(
value = {"dao","service"}, //设置基础扫描路径
excludeFilters = //设置过滤规则,当前为排除过滤
@ComponentScan.Filter( //设置过滤器
type= FilterType.ANNOTATION, //设置过滤方式为按照注解进行过滤
classes = Service.class) //设置具体的过滤项,过滤所有@Service修饰的bean
)
)
属性:
- includeFilters:设置包含性过滤器
- excludeFilters:设置排除性过滤器
- type:设置过滤器类型
基本注解
设置 bean
名称:@Component、@Controller、@Service、@Repository
类型:类注解,写在类定义上方
作用:设置该类为 Spring 管理的 bean
格式:
@Component
public class ClassName{}
说明:@Controller、@Service 、@Repository 是 @Component 的衍生注解,功能同 @Component
属性:
- value(默认):定义 bean 的访问 id
作用范围
名称:@Scope
类型:类注解,写在类定义上方
作用:设置该类作为 bean 对应的 scope 属性
格式:
@Scope
public class ClassName{}
相关属性
- value(默认):定义 bean 的作用域,默认为 singleton,非单例取值 prototype
生命周期
名称:@PostConstruct、@PreDestroy
类型:方法注解,写在方法定义上方
作用:设置该类作为 bean 对应的生命周期方法
示例:
//定义bean,后面添加bean的id
@Component("userService")
//定义bean的作用域
@Scope("singleton")
public class UserServiceImpl implements UserService {
//初始化
@PostConstruct
public void init(){
System.out.println("user service init...");
}
//销毁
@PreDestroy
public void destroy(){
System.out.println("user service destroy...");
}
}
一个对象的执行顺序:Constructor >> @Autowired(注入属性) >> @PostConstruct(初始化逻辑)
加载资源
名称:@Bean
类型:方法注解
作用:设置该方法的返回值作为 Spring 管理的 bean
格式:
@Bean("dataSource")
public DruidDataSource createDataSource() { return ……; }
说明:
-
因为第三方 bean 无法在其源码上进行修改,使用 @Bean 解决第三方 bean 的引入问题
-
该注解用于替代 XML 配置中的静态工厂与实例工厂创建 bean,不区分方法是否为静态或非静态
-
@Bean 所在的类必须被 Spring 扫描加载,否则该注解无法生效
相关属性
- value(默认):定义 bean 的访问 id
- initMethod:声明初始化方法
- destroyMethod:声明销毁方法
属性注入
基本类型
名称:@Value
类型:属性注解、方法注解
作用:设置对应属性的值或对方法进行传参
格式:
//@Value("${jdbc.username}")
@Value("root")
private String username;
说明:
-
value 值仅支持非引用类型数据,赋值时对方法的所有参数全部赋值
-
value 值支持读取 properties 文件中的属性值,通过类属性将 properties 中数据传入类中
-
value 值支持 SpEL
-
@value 注解如果添加在属性上方,可以省略 set 方法(set 方法的目的是为属性赋值)
相关属性:
- value(默认):定义对应的属性值或参数值
自动装配
属性注入
名称:@Autowired、@Qualifier
类型:属性注解、方法注解
作用:设置对应属性的对象、对方法进行引用类型传参
格式:
@Autowired(required = false)
@Qualifier("userDao")
private UserDao userDao;
说明:
- @Autowired 默认按类型装配,指定 @Qualifier 后可以指定自动装配的 bean 的 id
相关属性:
- required:为 true (默认)表示注入 bean 时该 bean 必须存在,不然就会注入失败抛出异常;为 false 表示注入时该 bean 存在就注入,不存在就忽略跳过
注意:在使用 @Autowired 时,首先在容器中查询对应类型的 bean,如果查询结果刚好为一个,就将该 bean 装配给 @Autowired 指定的数据,如果查询的结果不止一个,那么 @Autowired 会根据名称来查找,如果查询的结果为空,那么会抛出异常
解决方法:使用 required = false
优先注入
名称:@Primary
类型:类注解
作用:设置类对应的 bean 按类型装配时优先装配
范例:
@Primary
public class ClassName{}
说明:
- @Autowired 默认按类型装配,当出现相同类型的 bean,使用 @Primary 提高按类型自动装配的优先级,多个 @Primary 会导致优先级设置无效
注解对比
名称:@Inject、@Named、@Resource
- @Inject 与 @Named 是 JSR330 规范中的注解,功能与 @Autowired 和 @Qualifier 完全相同,适用于不同架构场景
- @Resource 是 JSR250 规范中的注解,可以简化书写格式
@Resource 相关属性
-
name:设置注入的 bean 的 id
-
type:设置注入的 bean 的类型,接收的参数为 Class 类型
@Autowired 和 @Resource之间的区别:
-
@Autowired 默认是按照类型装配注入,默认情况下它要求依赖对象必须存在(可以设置 required 属性为 false)
-
@Resource 默认按照名称装配注入,只有当找不到与名称匹配的 bean 才会按照类型来装配注入
静态注入
Spring 容器管理的都是实例对象,@Autowired 依赖注入的都是容器内的对象实例,在 Java 中 static 修饰的静态属性(变量和方法)是属于类的,而非属于实例对象
当类加载器加载静态变量时,Spring 上下文尚未加载,所以类加载器不会在 Bean 中正确注入静态类
@Component
public class TestClass {
@Autowired
private static Component component;
// 调用静态组件的方法
public static void testMethod() {
component.callTestMethod();
}
}
// 编译正常,但运行时报java.lang.NullPointerException,所以在调用testMethod()方法时,component变量还没被初始化
解决方法:
-
@Autowired 注解到类的构造函数上,Spring 扫描到 Component 的 Bean,然后赋给静态变量 component
@Component public class TestClass { private static Component component; @Autowired public TestClass(Component component) { TestClass.component = component; } public static void testMethod() { component.callTestMethod(); } } -
@Autowired 注解到静态属性的 setter 方法上
-
使用 @PostConstruct 注解一个方法,在方法内为 static 静态成员赋值
-
使用 Spring 框架工具类获取 bean,定义成局部变量使用
public class TestClass { // 调用静态组件的方法 public static void testMethod() { Component component = SpringApplicationContextUtil.getBean("component"); component.callTestMethod(); } }
参考文章:http://jessehzx.top/2018/03/18/spring-autowired-static-field/
文件读取
名称:@PropertySource
类型:类注解
作用:加载 properties 文件中的属性值
格式:
@PropertySource(value = "classpath:filename.properties")
public class ClassName {
@Value("${propertiesAttributeName}")
private String attributeName;
}
说明:
- 不支持 * 通配符,加载后,所有 Spring 控制的 bean 中均可使用对应属性值,加载多个需要用
{} 和 ,隔开
相关属性
-
value(默认):设置加载的 properties 文件名
-
ignoreResourceNotFound:如果资源未找到,是否忽略,默认为 false
加载控制
依赖加载
@DependsOn
-
名称:@DependsOn
-
类型:类注解、方法注解
-
作用:控制 bean 的加载顺序,使其在指定 bean 加载完毕后再加载
-
格式:
@DependsOn("beanId") public class ClassName { } -
说明:
-
配置在方法上,使 @DependsOn 指定的 bean 优先于 @Bean 配置的 bean 进行加载
-
配置在类上,使 @DependsOn 指定的 bean 优先于当前类中所有 @Bean 配置的 bean 进行加载
-
配置在类上,使 @DependsOn 指定的 bean 优先于 @Component 等配置的 bean 进行加载
-
-
相关属性
- value(默认):设置当前 bean 所依赖的 bean 的 id
@Order
-
名称:@Order
-
类型:配置类注解
-
作用:控制配置类的加载顺序,值越小越先加载
-
格式:
@Order(1) public class SpringConfigClassName { }
@Lazy
-
名称:@Lazy
-
类型:类注解、方法注解
-
作用:控制 bean 的加载时机,使其延迟加载,获取的时候加载
-
格式:
@Lazy public class ClassName { }
应用场景
@DependsOn
-
微信订阅号,发布消息和订阅消息的 bean 的加载顺序控制(先开订阅,再发布)
-
双 11 活动,零点前是结算策略 A,零点后是结算策略 B,策略 B 操作的数据为促销数据,策略 B 加载顺序与促销数据的加载顺序
@Lazy
- 程序灾难出现后对应的应急预案处理是启动容器时加载时机
@Order
- 多个种类的配置出现后,优先加载系统级的,然后加载业务级的,避免细粒度的加载控制
整合资源
导入
名称:@Import
类型:类注解
作用:导入第三方 bean 作为 Spring 控制的资源,这些类都会被 Spring 创建并放入 ioc 容器
格式:
@Configuration
@Import(OtherClassName.class)
public class ClassName {
}
说明:
- @Import 注解在同一个类上,仅允许添加一次,如果需要导入多个,使用数组的形式进行设定
- 在被导入的类中可以继续使用 @Import 导入其他资源
- @Bean 所在的类可以使用导入的形式进入 Spring 容器,无需声明为 bean
Druid
-
加载资源
@Component public class JDBCConfig { @Bean("dataSource") public static DruidDataSource getDataSource() { DruidDataSource ds = new DruidDataSource(); ds.setDriverClassName("com.mysql.jdbc.Driver"); ds.setUrl("jdbc:mysql://192.168.2.185:3306/spring_db"); ds.setUsername("root"); ds.setPassword("123456"); return ds; } } -
导入资源
@Configuration @ComponentScan(value = {"service","dao"}) @Import(JDBCConfig.class) public class SpringConfig { } -
测试
DruidDataSource dataSource = (DruidDataSource) ctx.getBean("dataSource"); System.out.println(dataSource);
Junit
Spring 接管 Junit 的运行权,使用 Spring 专用的 Junit 类加载器,为 Junit 测试用例设定对应的 Spring 容器
注意:
-
从 Spring5.0 以后,要求 Junit 的版本必须是4.12及以上
-
Junit 仅用于单元测试,不能将 Junit 的测试类配置成 Spring 的 bean,否则该配置将会被打包进入工程中
test / java / service / UserServiceTest
//设定spring专用的类加载器
@RunWith(SpringJUnit4ClassRunner.class)
//设定加载的spring上下文对应的配置
@ContextConfiguration(classes = SpringConfig.class)
public class UserServiceTest {
@Autowired
private AccountService accountService;
@Test
public void testFindById() {
Account account = accountService.findById(1);
Assert.assertEquals("Mike", account.getName());
}
}
pom.xml
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.1.9.RELEASE</version>
</dependency>
IoC原理
核心类
BeanFactory
ApplicationContext:
-
ApplicationContext 是一个接口,提供了访问 Spring 容器的 API
-
ClassPathXmlApplicationContext 是一个类,实现了上述功能
-
ApplicationContext 的顶层接口是 BeanFactory
-
BeanFactory 定义了 bean 相关的最基本操作
-
ApplicationContext 在 BeanFactory 基础上追加了若干新功能
ApplicationContext 和 BeanFactory对比:
-
BeanFactory 和 ApplicationContext 是 Spring 的两大核心接口,都可以当做 Spring 的容器
-
BeanFactory 是 Spring 里面最底层的接口,是 IoC 的核心,定义了 IoC 的基本功能,包含了各种 Bean 的定义、加载、实例化,依赖注入和生命周期管理。ApplicationContext 接口作为 BeanFactory 的子类,除了提供 BeanFactory 所具有的功能外,还提供了更完整的框架功能:
- 继承 MessageSource,因此支持国际化
- 资源文件访问,如 URL 和文件(ResourceLoader)。
- 载入多个(有继承关系)上下文(即加载多个配置文件) ,使得每一个上下文都专注于一个特定的层次,比如应用的 web 层
- 提供在监听器中注册 bean 的事件
-
BeanFactory 创建的 bean 采用延迟加载形式,只有在使用到某个 Bean 时(调用 getBean),才对该 Bean 进行加载实例化(Spring 早期使用该方法获取 bean),这样就不能提前发现一些存在的 Spring 的配置问题;ApplicationContext 是在容器启动时,一次性创建了所有的 Bean,容器启动时,就可以发现 Spring 中存在的配置错误,这样有利于检查所依赖属性是否注入
-
ApplicationContext 启动后预载入所有的单实例 Bean,所以程序启动慢,运行时速度快
-
两者都支持 BeanPostProcessor、BeanFactoryPostProcessor 的使用,但两者之间的区别是:BeanFactory 需要手动注册,而 ApplicationContext 则是自动注册
FileSystemXmlApplicationContext:加载文件系统中任意位置的配置文件,而 ClassPathXmlAC 只能加载类路径下的配置文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XrDLgVwN-1686861880269)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/Spring-ApplicationContext层级结构图.png)]
BeanFactory 的成员属性:
String FACTORY_BEAN_PREFIX = "&";
- 区分是 FactoryBean 还是创建的 Bean,加上 & 代表是工厂,getBean 将会返回工厂
- FactoryBean:如果某个 bean 的配置非常复杂,或者想要使用编码的形式去构建它,可以提供一个构建该 bean 实例的工厂,这个工厂就是 FactoryBean 接口实现类,FactoryBean 接口实现类也是需要 Spring 管理
- 这里产生两种对象,一种是 FactoryBean 接口实现类(IOC 管理),另一种是 FactoryBean 接口内部管理的对象
- 获取 FactoryBean 接口实现类,使用 getBean 时传的 beanName 需要带 & 开头
- 获取 FactoryBean 内部管理的对象,不需要带 & 开头
BeanFactory 的基本使用:
Resource res = new ClassPathResource("applicationContext.xml");
BeanFactory bf = new XmlBeanFactory(res);
UserService userService = (UserService)bf.getBean("userService");
FactoryBean
FactoryBean:对单一的 bean 的初始化过程进行封装,达到简化配置的目的
FactoryBean与 BeanFactory 区别:
-
FactoryBean:封装单个 bean 的创建过程,就是工厂的 Bean
-
BeanFactory:Spring 容器顶层接口,定义了 bean 相关的获取操作
代码实现:
-
FactoryBean,实现类一般是 MapperFactoryBean,创建 DAO 层接口的实现类
public class EquipmentDaoImplFactoryBean implements FactoryBean { @Override //获取Bean public Object getObject() throws Exception { return new EquipmentDaoImpl(); } @Override //获取bean的类型 public Class<?> getObjectType() { return null; } @Override //是否单例 public boolean isSingleton() { return false; } } -
MapperFactoryBean 继承 SqlSessionDaoSupport,可以获取 SqlSessionTemplate,完成 MyBatis 的整合
public abstract class SqlSessionDaoSupport extends DaoSupport { private SqlSessionTemplate sqlSessionTemplate; // 获取 SqlSessionTemplate 对象 public void setSqlSessionFactory(SqlSessionFactory sqlSessionFactory) { if (this.sqlSessionTemplate == null || sqlSessionFactory != this.sqlSessionTemplate.getSqlSessionFactory()) { this.sqlSessionTemplate = createSqlSessionTemplate(sqlSessionFactory); } } }
过滤器
数据准备
-
DAO 层 UserDao、AccountDao、BookDao、EquipmentDao
public interface UserDao { public void save(); }@Component("userDao") public class UserDaoImpl implements UserDao { public void save() { System.out.println("user dao running..."); } } -
Service 业务层
public interface UserService { public void save(); }@Service("userService") public class UserServiceImpl implements UserService { @Autowired private UserDao userDao;//...........BookDao等 public void save() { System.out.println("user service running..."); userDao.save(); } }
过滤器
名称:TypeFilter
类型:接口
作用:自定义类型过滤器
示例:
-
config / filter / MyTypeFilter
public class MyTypeFilter implements TypeFilter { @Override /** * metadataReader:读取到的当前正在扫描的类的信息 * metadataReaderFactory:可以获取到任何其他类的信息 */ //加载的类满足要求,匹配成功 public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException { //获取当前类注解的信息 AnnotationMetadata am = metadataReader.getAnnotationMetadata(); //获取当前正在扫描的类的类信息 ClassMetadata classMetadata = metadataReader.getClassMetadata(); //获取当前类资源(类的路径) Resource resource = metadataReader.getResource(); //通过类的元数据获取类的名称 String className = classMetadata.getClassName(); //如果加载的类名满足过滤器要求,返回匹配成功 if(className.equals("service.impl.UserServiceImpl")){ //返回true表示匹配成功,返回false表示匹配失败。此处仅确认匹配结果,不会确认是排除还是加入,排除/加入由配置项决定,与此处无关 return true; } return false; } } -
SpringConfig
@Configuration //设置排除bean,排除的规则是自定义规则(FilterType.CUSTOM),具体的规则定义为MyTypeFilter @ComponentScan( value = {"dao","service"}, excludeFilters = @ComponentScan.Filter( type= FilterType.CUSTOM, classes = MyTypeFilter.class ) ) public class SpringConfig { }
导入器
bean 只有通过配置才可以进入 Spring 容器,被 Spring 加载并控制
-
配置 bean 的方式如下:
- XML 文件中使用 标签配置
- 使用 @Component 及衍生注解配置
导入器可以快速高效导入大量 bean,替代 @Import({a.class,b.class}),无需在每个类上添加 @Bean
名称: ImportSelector
类型:接口
作用:自定义bean导入器
-
selector / MyImportSelector
public class MyImportSelector implements ImportSelector{ @Override public String[] selectImports(AnnotationMetadata importingClassMetadata) { // 1.编程形式加载一个类 // return new String[]{"dao.impl.BookDaoImpl"}; // 2.加载import.properties文件中的单个类名 // ResourceBundle bundle = ResourceBundle.getBundle("import"); // String className = bundle.getString("className"); // 3.加载import.properties文件中的多个类名 ResourceBundle bundle = ResourceBundle.getBundle("import"); String className = bundle.getString("className"); return className.split(","); } } -
import.properties
#2.加载import.properties文件中的单个类名 #className=dao.impl.BookDaoImpl #3.加载import.properties文件中的多个类名 #className=dao.impl.BookDaoImpl,dao.impl.AccountDaoImpl #4.导入包中的所有类 path=dao.impl.* -
SpringConfig
@Configuration @ComponentScan({"dao","service"}) @Import(MyImportSelector.class) public class SpringConfig { }
注册器
可以取代 ComponentScan 扫描器
名称:ImportBeanDefinitionRegistrar
类型:接口
作用:自定义 bean 定义注册器
-
registrar / MyImportBeanDefinitionRegistrar
public class MyImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar { /** * AnnotationMetadata:当前类的注解信息 * BeanDefinitionRegistry:BeanDefinition注册类,把所有需要添加到容器中的bean调用registerBeanDefinition手工注册进来 */ @Override public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) { //自定义注册器 //1.开启类路径bean定义扫描器,需要参数bean定义注册器BeanDefinitionRegistry,需要制定是否使用默认类型过滤器 ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(registry,false); //2.添加包含性加载类型过滤器(可选,也可以设置为排除性加载类型过滤器) scanner.addIncludeFilter(new TypeFilter() { @Override public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException { //所有匹配全部成功,此处应该添加实际的业务判定条件 return true; } }); //设置扫描路径 scanner.addExcludeFilter(tf);//排除 scanner.scan("dao","service"); } } -
SpringConfig
@Configuration @Import(MyImportBeanDefinitionRegistrar.class) public class SpringConfig { }
处理器
通过创建类继承相应的处理器的接口,重写后置处理的方法,来实现拦截 Bean 的生命周期来实现自己自定义的逻辑
BeanPostProcessor:bean 后置处理器,bean 创建对象初始化前后进行拦截工作的
BeanFactoryPostProcessor:beanFactory 的后置处理器
-
加载时机:在 BeanFactory 初始化之后调用,来定制和修改 BeanFactory 的内容;所有的 bean 定义已经保存加载到 beanFactory,但是 bean 的实例还未创建 -
执行流程:- ioc 容器创建对象
- invokeBeanFactoryPostProcessors(beanFactory):执行 BeanFactoryPostProcessor
- 在 BeanFactory 中找到所有类型是 BeanFactoryPostProcessor 的组件,并执行它们的方法
- 在初始化创建其他组件前面执行
BeanDefinitionRegistryPostProcessor:
-
加载时机:在所有 bean 定义信息将要被加载,但是 bean 实例还未创建,优先于 BeanFactoryPostProcessor 执行;利用 BeanDefinitionRegistryPostProcessor 给容器中再额外添加一些组件
-
执行流程:
- ioc 容器创建对象
- refresh() → invokeBeanFactoryPostProcessors(beanFactory)
- 从容器中获取到所有的 BeanDefinitionRegistryPostProcessor 组件
- 依次触发所有的 postProcessBeanDefinitionRegistry() 方法
- 再来触发 postProcessBeanFactory() 方法
监听器
基本概述
ApplicationListener:监听容器中发布的事件,完成事件驱动模型开发
public interface ApplicationListener<E extends ApplicationEvent>
所以监听 ApplicationEvent 及其下面的子事件
应用监听器步骤:
- 写一个监听器(ApplicationListener实现类)来监听某个事件(ApplicationEvent及其子类)
- 把监听器加入到容器 @Component
- 只要容器中有相关事件的发布,就能监听到这个事件;
-
ContextRefreshedEvent:容器刷新完成(所有 bean 都完全创建)会发布这个事件 -
ContextClosedEvent:关闭容器会发布这个事件
-
- 发布一个事件:
applicationContext.publishEvent()
@Component
public class MyApplicationListener implements ApplicationListener<ApplicationEvent> {
//当容器中发布此事件以后,方法触发
@Override
public void onApplicationEvent(ApplicationEvent event) {
System.out.println("收到事件:" + event);
}
}
实现原理
ContextRefreshedEvent 事件:
-
容器初始化过程中执行
initApplicationEventMulticaster():初始化事件多播器- 先去容器中查询
id = applicationEventMulticaster的组件,有直接返回 - 没有就执行
this.applicationEventMulticaster = new SimpleApplicationEventMulticaster(beanFactory)并且加入到容器中 - 以后在其他组件要派发事件,自动注入这个 applicationEventMulticaster
- 先去容器中查询
-
容器初始化过程执行 registerListeners() 注册监听器
- 从容器中获取所有监听器:
getBeanNamesForType(ApplicationListener.class, true, false) - 将 listener 注册到 ApplicationEventMulticaster
- 从容器中获取所有监听器:
-
容器刷新完成:finishRefresh() → publishEvent(new ContextRefreshedEvent(this))
发布 ContextRefreshedEvent 事件:
- 获取事件的多播器(派发器):getApplicationEventMulticaster()
- multicastEvent 派发事件
- 获取到所有的 ApplicationListener
- 遍历 ApplicationListener
- 如果有 Executor,可以使用 Executor 异步派发
Executor executor = getTaskExecutor() - 没有就同步执行 listener 方法
invokeListener(listener, event),拿到 listener 回调 onApplicationEvent
- 如果有 Executor,可以使用 Executor 异步派发
容器关闭会发布 ContextClosedEvent
注解实现
注解:@EventListener
基本使用:
@Service
public class UserService{
@EventListener(classes={ApplicationEvent.class})
public void listen(ApplicationEvent event){
System.out.println("UserService。。监听到的事件:" + event);
}
}
原理:使用 EventListenerMethodProcessor 处理器来解析方法上的 @EventListener,Spring 扫描使用注解的方法,并为之创建一个监听对象
SmartInitializingSingleton 原理:afterSingletonsInstantiated()
-
IOC 容器创建对象并 refresh() -
finishBeanFactoryInitialization(beanFactory):初始化剩下的单实例 bean * 先创建所有的单实例 bean:getBean() * 获取所有创建好的单实例 bean,判断是否是 SmartInitializingSingleton 类型的,如果是就调用 afterSingletonsInstantiated()
AOP
基本概述
AOP(Aspect Oriented Programing):面向切面编程,一种编程范式,指导开发者如何组织程序结构
AOP 弥补了 OOP 的不足,基于 OOP 基础之上进行横向开发:
-
uOOP 规定程序开发以类为主体模型,一切围绕对象进行,完成某个任务先构建模型
-
uAOP 程序开发主要关注基于 OOP 开发中的共性功能,一切围绕共性功能进行,完成某个任务先构建可能遇到的所有共性功能(当所有功能都开发出来也就没有共性与非共性之分),将软件开发由手工制作走向半自动化/全自动化阶段,实现“插拔式组件体系结构”搭建
AOP 作用:
-
提高代码的可重用性
-
业务代码编码更简洁
-
业务代码维护更高效
-
业务功能扩展更便捷
核心概念
概念详解
-
Joinpoint(连接点):就是方法
-
Pointcut(切入点):就是挖掉共性功能的方法
-
Advice(通知):就是共性功能,最终以一个方法的形式呈现
-
Aspect(切面):就是共性功能与挖的位置的对应关系
-
Target(目标对象):就是挖掉功能的方法对应的类产生的对象,这种对象是无法直接完成最终工作的
-
Weaving(织入):就是将挖掉的功能回填的动态过程
-
Proxy(代理):目标对象无法直接完成工作,需要对其进行功能回填,通过创建原始对象的代理对象实现
-
Introduction(引入/引介):就是对原始对象无中生有的添加成员变量或成员方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pObvoZno-1686861880269)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP连接点.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tHHsHl31-1686861880270)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP切入点切面通知.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UEgS5tZE-1686861880270)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP织入.png)]
入门项目
开发步骤:
-
开发阶段
-
制作程序
-
将非共性功能开发到对应的目标对象类中,并制作成切入点方法
-
将共性功能独立开发出来,制作成通知
-
在配置文件中,声明切入点
-
在配置文件中,声明切入点与通知间的关系(含通知类型),即切面
-
-
运行阶段(AOP 完成)
-
Spring 容器加载配置文件,监控所有配置的切入点方法的执行
-
当监控到切入点方法被运行,使用代理机制,动态创建目标对象的代理对象,根据通知类别,在代理对象的对应位置将通知对应的功能织入,完成完整的代码逻辑并运行
-
-
导入坐标 pom.xml
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.1.9.RELEASE</version> </dependency> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.9.4</version> </dependency> -
业务层抽取通用代码 service / UserServiceImpl
public interface UserService { public void save(); }public class UserServiceImpl implements UserService { @Override public void save() { //System.out.println("共性功能"); System.out.println("user service running..."); } }aop.AOPAdvice
//1.制作通知类,在类中定义一个方法用于完成共性功能 public class AOPAdvice { //共性功能抽取后职称独立的方法 public void function(){ System.out.println("共性功能"); } } -
把通知加入spring容器管理,配置aop applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation=" http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd "> <!--原始Spring控制资源--> <bean id="userService" class= "service.impl.UserServiceImpl"/> <!--2.配置共性功能成功spring控制的资源--> <bean id="myAdvice" class="aop.AOPAdvice"/> <!--3.开启AOP命名空间: beans标签内--> <!--4.配置AOP--> <aop:config> <!--5.配置切入点--> <aop:pointcut id="pt" expression="execution(* *..*(..))"/> <!--6.配置切面(切入点与通知的关系)--> <aop:aspect ref="myAdvice"> <!--7.配置具体的切入点对应通知中那个操作方法--> <aop:before method="function" pointcut-ref="pt"/> </aop:aspect> </aop:config> </beans> -
测试类
public class App { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); UserService userService = (UserService) ctx.getBean("userService"); userService.save();//先输出共性功能,然后 user service running... } }
XML开发
AspectJ
Aspect(切面)用于描述切入点与通知间的关系,是 AOP 编程中的一个概念
AspectJ 是基于 java 语言对 Aspect 的实现
AOP
config
标签:aop:config, 的子标签
作用:设置 AOP
格式:
<beans>
<aop:config>……</aop:config>
<aop:config>……</aop:config>
<!--一个beans标签中可以配置多个aop:config标签-->
</beans>
pointcut
标签:aop:pointcut,归属于 aop:config 标签和 aop:aspect 标签
作用:设置切入点
格式:
<aop:config>
<aop:pointcut id="pointcutId" expression="……"/>
<aop:aspect>
<aop:pointcut id="pointcutId" expression="……"/>
</aop:aspect>
</aop:config>
说明:
- 一个 aop:config 标签中可以配置多个 aop:pointcut 标签,且该标签可以配置在 aop:aspect 标签内
属性:
-
id :识别切入点的名称
-
expression :切入点表达式
aspect
标签:aop:aspect,aop:config 的子标签
作用:设置具体的 AOP 通知对应的切入点(切面)
格式:
<aop:config>
<aop:aspect ref="beanId">……</aop:aspect>
<aop:aspect ref="beanId">……</aop:aspect>
<!--一个aop:config标签中可以配置多个aop:aspect标签-->
</aop:config>
属性:
- ref :通知所在的 bean 的 id
Pointcut
切入点
切入点描述的是某个方法
切入点表达式是一个快速匹配方法描述的通配格式,类似于正则表达式
表达式
格式:
关键字(访问修饰符 返回值 包名.类名.方法名(参数)异常名)
示例:
//匹配UserService中只含有一个参数的findById方法
execution(public User service.UserService.findById(int))
格式解析:
- 关键字:描述表达式的匹配模式(参看关键字列表)
- 访问修饰符:方法的访问控制权限修饰符
- 类名:方法所在的类(此处可以配置接口名称)
- 异常:方法定义中指定抛出的异常
关键字:
-
execution :匹配执行指定方法
-
args :匹配带有指定参数类型的方法
-
within、this、target、@within、@target、@args、@annotation、bean、reference pointcut等
通配符:
-
*:单个独立的任意符号,可以独立出现,也可以作为前缀或者后缀的匹配符出现
//匹配com.seazean包下的任意包中的UserService类或接口中所有find开头的带有一个任意参数的方法 execution(public * com.seazean.*.UserService.find*(*) -
… :多个连续的任意符号,可以独立出现,常用于简化包名与参数
//匹配com包下的任意包中的UserService类或接口中所有名称为findById参数任意数量和类型的方法 execution(public User com..UserService.findById(..)) -
+:专用于匹配子类类型
//匹配任意包下的Service结尾的类或者接口的子类或者实现类 execution(* *..*Service+.*(..))
逻辑运算符:
- &&:连接两个切入点表达式,表示两个切入点表达式同时成立的匹配
- ||:连接两个切入点表达式,表示两个切入点表达式成立任意一个的匹配
- ! :连接单个切入点表达式,表示该切入点表达式不成立的匹配
示例:
execution(* *(..)) //前三个都是匹配全部
execution(* *..*(..))
execution(* *..*.*(..))
execution(public * *..*.*(..))
execution(public int *..*.*(..))
execution(public void *..*.*(..))
execution(public void com..*.*(..))
execution(public void com..service.*.*(..))
execution(public void com.seazean.service.*.*(..))
execution(public void com.seazean.service.User*.*(..))
execution(public void com.seazean.service.*Service.*(..))
execution(public void com.seazean.service.UserService.*(..))
execution(public User com.seazean.service.UserService.find*(..)) //find开头
execution(public User com.seazean.service.UserService.*Id(..)) //I
execution(public User com.seazean.service.UserService.findById(..))
execution(public User com.seazean.service.UserService.findById(int))
execution(public User com.seazean.service.UserService.findById(int,int))
execution(public User com.seazean.service.UserService.findById(int,*))
execution(public User com.seazean.service.UserService.findById())
execution(List com.seazean.service.*Service+.findAll(..))
配置方式
XML 配置规则:
-
企业开发命名规范严格遵循规范文档进行
-
先为方法配置局部切入点,再抽取类中公共切入点,最后抽取全局切入点
-
代码走查过程中检测切入点是否存在越界性包含
-
代码走查过程中检测切入点是否存在非包含性进驻
-
设定 AOP 执行检测程序,在单元测试中监控通知被执行次数与预计次数是否匹配(不绝对正确:加进一个不该加的,删去一个不该删的相当于结果不变)
-
设定完毕的切入点如果发生调整务必进行回归测试
<aop:config>
<!--1.配置公共切入点-->
<aop:pointcut id="pt1" expression="execution(* *(..))"/>
<aop:aspect ref="myAdvice">
<!--2.配置局部切入点-->
<aop:pointcut id="pt2" expression="execution(* *(..))"/>
<!--引用公共切入点-->
<aop:before method="logAdvice" pointcut-ref="pt1"/>
<!--引用局部切入点-->
<aop:before method="logAdvice" pointcut-ref="pt2"/>
<!--3.直接配置切入点-->
<aop:before method="logAdvice" pointcut="execution(* *(..))"/>
</aop:aspect>
</aop:config>
Advice
通知类型
AOP 的通知类型共5种:前置通知,后置通知、返回后通知、抛出异常后通知、环绕通知
before
标签:aop:before,aop:aspect的子标签
作用:设置前置通知
- 前置通知:原始方法执行前执行,如果通知中抛出异常,阻止原始方法运行
- 应用:数据校验
格式:
<aop:aspect ref="adviceId">
<aop:before method="methodName" pointcut="execution(* *(..))"/>
<!--一个aop:aspect标签中可以配置多个aop:before标签-->
</aop:aspect>
基本属性:
-
method:在通知类中设置当前通知类别对应的方法
-
pointcut:设置当前通知对应的切入点表达式,与pointcut-ref属性冲突
-
pointcut-ref:设置当前通知对应的切入点id,与pointcut属性冲突
after
标签:aop:after,aop:aspect的子标签
作用:设置后置通知
-
后置通知:原始方法执行后执行,无论原始方法中是否出现异常,都将执行通知
-
应用:现场清理
格式:
<aop:aspect ref="adviceId">
<aop:after method="methodName" pointcut="execution(* *(..))"/>
<!--一个aop:aspect标签中可以配置多个aop:after标签-->
</aop:aspect>
基本属性:
-
method:在通知类中设置当前通知类别对应的方法
-
pointcut:设置当前通知对应的切入点表达式,与pointcut-ref属性冲突
-
pointcut-ref:设置当前通知对应的切入点id,与pointcut属性冲突
after-r
标签:aop:after-returning,aop:aspect的子标签
作用:设置返回后通知
-
返回后通知:原始方法正常执行完毕并返回结果后执行,如果原始方法中抛出异常,无法执行
-
应用:返回值相关数据处理
格式:
<aop:aspect ref="adviceId">
<aop:after-returning method="methodName" pointcut="execution(* *(..))"/>
<!--一个aop:aspect标签中可以配置多个aop:after-returning标签-->
</aop:aspect>
基本属性:
- method:在通知类中设置当前通知类别对应的方法
- pointcut:设置当前通知对应的切入点表达式,与pointcut-ref属性冲突
- pointcut-ref:设置当前通知对应的切入点id,与pointcut属性冲突
- returning:设置接受返回值的参数,与通知类中对应方法的参数一致
after-t
标签:aop:after-throwing,aop:aspect的子标签
作用:设置抛出异常后通知
- 抛出异常后通知:原始方法抛出异常后执行,如果原始方法没有抛出异常,无法执行
- 应用:对原始方法中出现的异常信息进行处理
格式:
<aop:aspect ref="adviceId">
<aop:after-throwing method="methodName" pointcut="execution(* *(..))"/>
<!--一个aop:aspect标签中可以配置多个aop:after-throwing标签-->
</aop:aspect>
基本属性:
- method:在通知类中设置当前通知类别对应的方法
- pointcut:设置当前通知对应的切入点表达式,与pointcut-ref属性冲突
- pointcut-ref:设置当前通知对应的切入点id,与pointcut属性冲突
- throwing:设置接受异常对象的参数,与通知类中对应方法的参数一致
around
标签:aop:around,aop:aspect的子标签
作用:设置环绕通知
-
环绕通知:在原始方法执行前后均有对应执行执行,还可以阻止原始方法的执行
-
应用:功能强大,可以做任何事情
格式:
<aop:aspect ref="adviceId">
<aop:around method="methodName" pointcut="execution(* *(..))"/>
<!--一个aop:aspect标签中可以配置多个aop:around标签-->
</aop:aspect>
基本属性:
-
method :在通知类中设置当前通知类别对应的方法
-
pointcut :设置当前通知对应的切入点表达式,与pointcut-ref属性冲突
-
pointcut-ref :设置当前通知对应的切入点id,与pointcut属性冲突
环绕通知的开发方式(参考通知顺序章节):
-
环绕通知是在原始方法的前后添加功能,在环绕通知中,存在对原始方法的显式调用
public Object around(ProceedingJoinPoint pjp) throws Throwable { Object ret = pjp.proceed(); return ret; } -
环绕通知方法相关说明:
-
方法须设定 Object 类型的返回值,否则会拦截原始方法的返回。如果原始方法返回值类型为 void,通知方法也可以设定返回值类型为 void,最终返回 null
-
方法需在第一个参数位置设定 ProceedingJoinPoint 对象,通过该对象调用 proceed() 方法,实现对原始方法的调用。如省略该参数,原始方法将无法执行
-
使用 proceed() 方法调用原始方法时,因无法预知原始方法运行过程中是否会出现异常,强制抛出 Throwable 对象,封装原始方法中可能出现的异常信息
-
通知顺序
当同一个切入点配置了多个通知时,通知会存在运行的先后顺序,该顺序以通知配置的顺序为准。
-
AOPAdvice
public class AOPAdvice { public void before(){ System.out.println("before...); } public void after(){ System.out.println("after..."); } public void afterReturing(){ System.out.println("afterReturing..."); } public void afterThrowing(){ System.out.println("afterThrowing..."); } public Object around(ProceedingJoinPoint pjp) { System.out.println("around before..."); //对原始方法的调用 Object ret = pjp.proceed(); System.out.println("around after..."+ret); return ret; } } -
applicationContext.xml 顺序执行
<aop:config> <aop:pointcut id="pt" expression="execution(* *..*(..))"/> <aop:aspect ref="myAdvice"> <aop:before method="before" pointcut-ref="pt"/> <aop:after method="after" pointcut-ref="pt"/> <aop:after-returning method="afterReturing" pointcut-ref="pt"/> <aop:after-throwing method="afterThrowing" pointcut-ref="pt"/> <aop:around method="around" pointcut-ref="pt"/> </aop:aspect> </aop:config>
获取数据
参数
第一种方式:
-
设定通知方法第一个参数为 JoinPoint,通过该对象调用 getArgs() 方法,获取原始方法运行的参数数组
public void before(JoinPoint jp) throws Throwable { Object[] args = jp.getArgs(); } -
所有的通知均可以获取参数,环绕通知使用ProceedingJoinPoint.getArgs()方法
第二种方式:
-
设定切入点表达式为通知方法传递参数(锁定通知变量名)
-
流程图:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vE0RGYGB-1686861880271)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP通知获取参数方式二.png)]
-
解释:
&代表并且 &- 输出结果:a = param1 b = param2
第三种方式:
-
设定切入点表达式为通知方法传递参数(改变通知变量名的定义顺序)
-
流程图:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RUoynDmV-1686861880272)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP通知获取参数方式三.png)]
-
解释:输出结果 a = param2 b = param1
返回值
环绕通知和返回后通知可以获取返回值,后置通知不一定,其他类型获取不到
第一种方式:适用于返回后通知(after-returning)
-
设定返回值变量名
-
原始方法:
public class UserServiceImpl implements UserService { @Override public int save() { System.out.println("user service running..."); return 100; } } -
AOP 配置:
<aop:aspect ref="myAdvice"> <aop:pointcut id="pt" expression="execution(* *(..))"/> <aop:after-returning method="afterReturning" pointcut-ref="pt" returning="ret"/> </aop:aspect> -
通知类:
public class AOPAdvice { public void afterReturning(Object ret) { System.out.println("return:" + ret); } }
第二种:适用于环绕通知(around)
-
在通知类的方法中调用原始方法获取返回值
-
原始方法:
public class UserServiceImpl implements UserService { @Override public int save() { System.out.println("user service running..."); return 100; } } -
AOP 配置:
<aop:aspect ref="myAdvice"> <aop:pointcut id="pt" expression="execution(* *(..)) "/> <aop:around method="around" pointcut-ref="pt" /> </aop:aspect> -
通知类:
public class AOPAdvice { public Object around(ProceedingJoinPoint pjp) throws Throwable { Object ret = pjp.proceed(); return ret; } } -
测试类:
public class App { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); UserService userService = (UserService) ctx.getBean("userService"); int ret = userService.save(); System.out.println("app....." + ret); } }
异常
环绕通知和抛出异常后通知可以获取异常,后置通知不一定,其他类型获取不到
第一种:适用于返回后通知(after-throwing)
-
设定异常对象变量名
-
原始方法
public class UserServiceImpl implements UserService { @Override public void save() { System.out.println("user service running..."); int i = 1/0; } } -
AOP 配置
<aop:aspect ref="myAdvice"> <aop:pointcut id="pt" expression="execution(* *(..)) "/> <aop:after-throwing method="afterThrowing" pointcut-ref="pt" throwing="t"/> </aop:aspect> -
通知类
public void afterThrowing(Throwable t){ System.out.println(t.getMessage()); }
第二种:适用于环绕通知(around)
- 在通知类的方法中调用原始方法捕获异常
-
原始方法:
public class UserServiceImpl implements UserService { @Override public void save() { System.out.println("user service running..."); int i = 1/0; } } -
AOP 配置:
<aop:aspect ref="myAdvice"> <aop:pointcut id="pt" expression="execution(* *(..)) "/> <aop:around method="around" pointcut-ref="pt" /> </aop:aspect> -
通知类:try……catch……捕获异常后,ret为null
public Object around(ProceedingJoinPoint pjp) throws Throwable { Object ret = pjp.proceed(); //对此处调用进行try……catch……捕获异常,或抛出异常 /* try { ret = pjp.proceed(); } catch (Throwable throwable) { System.out.println("around exception..." + throwable.getMessage()); }*/ return ret; }
-
测试类
userService.delete();
获取全部
-
UserService
public interface UserService { public void save(int i, int m); public int update(); public void delete(); }public class UserServiceImpl implements UserService { @Override public void save(int i, int m) { System.out.println("user service running..." + i + "," + m); } @Override public int update() { System.out.println("user service update running..."); return 100; } @Override public void delete() { System.out.println("user service delete running..."); int i = 1 / 0; } } -
AOPAdvice
public class AOPAdvice { public void before(JoinPoint jp){ //通过JoinPoint参数获取调用原始方法所携带的参数 Object[] args = jp.getArgs(); System.out.println("before..."+args[0]); } public void after(JoinPoint jp){ Object[] args = jp.getArgs(); System.out.println("after..."+args[0]); } public void afterReturing(Object ret){ System.out.println("afterReturing..."+ret); } public void afterThrowing(Throwable t){ System.out.println("afterThrowing..."+t.getMessage()); } public Object around(ProceedingJoinPoint pjp) { System.out.println("around before..."); Object ret = null; try { //对原始方法的调用 ret = pjp.proceed(); } catch (Throwable throwable) { System.out.println("around...exception...."+throwable.getMessage()); } System.out.println("around after..."+ret); return ret; } } -
applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation=" http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd "> <bean id="userService" class="service.impl.UserServiceImpl"/> <bean id="myAdvice" class="aop.AOPAdvice"/> <aop:config> <aop:pointcut id="pt" expression="execution(* *..*(..))"/> <aop:aspect ref="myAdvice"> <aop:before method="before" pointcut="pt"/> <aop:around method="around" pointcut-ref="pt"/> <aop:after method="after" pointcut="pt"/> <aop:after-returning method="afterReturning" pointcut-ref="pt" returning="ret"/> <aop:after-throwing method="afterThrowing" pointcut-ref="pt" throwing="t"/> </aop:aspect> </aop:config> </beans> -
测试类
public class App { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); UserService userService = (UserService) ctx.getBean("userService"); // userService.save(666, 888); // int ret = userService.update(); // System.out.println("app....." + ret); userService.delete(); } }
注解开发
AOP注解
AOP 注解简化 XML:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s4jlzbDp-1686861880272)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP注解开发.png)]
注意事项:
-
切入点最终体现为一个方法,无参无返回值,无实际方法体内容,但不能是抽象方法
-
引用切入点时必须使用方法调用名称,方法后面的 () 不能省略
-
切面类中定义的切入点只能在当前类中使用,如果想引用其他类中定义的切入点使用“类名.方法名()”引用
-
可以在通知类型注解后添加参数,实现 XML 配置中的属性,例如 after-returning 后的 returning 性
启动注解
XML
开启 AOP 注解支持:
<aop:aspectj-autoproxy/>
<context:component-scan base-package="aop,config,service"/><!--启动Spring扫描-->
开发步骤:
- 导入坐标(伴随 spring-context 坐标导入已经依赖导入完成)
- 开启 AOP 注解支持
- 配置切面 @Aspect
- 定义专用的切入点方法,并配置切入点 @Pointcut
- 为通知方法配置通知类型及对应切入点 @Before
纯注解
注解:@EnableAspectJAutoProxy
位置:Spring 注解配置类定义上方
作用:设置当前类开启 AOP 注解驱动的支持,加载 AOP 注解
格式:
@Configuration
@ComponentScan("com.seazean")
@EnableAspectJAutoProxy
public class SpringConfig {
}
基本注解
Aspect
注解:@Aspect
位置:类定义上方
作用:设置当前类为切面类
格式:
@Aspect
public class AopAdvice {
}
Pointcut
注解:@Pointcut
位置:方法定义上方
作用:使用当前方法名作为切入点引用名称
格式:
@Pointcut("execution(* *(..))")
public void pt() {
}
说明:被修饰的方法忽略其业务功能,格式设定为无参无返回值的方法,方法体内空实现(非抽象)
Before
注解:@Before
位置:方法定义上方
作用:标注当前方法作为前置通知
格式:
@Before("pt()")
public void before(JoinPoint joinPoint){
//joinPoint.getArgs();
}
注意:多个参数时,JoinPoint参数一定要在第一位
After
注解:@After
位置:方法定义上方
作用:标注当前方法作为后置通知
格式:
@After("pt()")
public void after(){
}
AfterR
注解:@AfterReturning
位置:方法定义上方
作用:标注当前方法作为返回后通知
格式:
@AfterReturning(value="pt()", returning = "result")
public void afterReturning(Object result) {
}
特殊参数:
- returning :设定使用通知方法参数接收返回值的变量名
AfterT
注解:@AfterThrowing
位置:方法定义上方
作用:标注当前方法作为异常后通知
格式:
@AfterThrowing(value="pt()", throwing = "t")
public void afterThrowing(Throwable t){
}
特殊参数:
- throwing :设定使用通知方法参数接收原始方法中抛出的异常对象名
Around
注解:@Around
位置:方法定义上方
作用:标注当前方法作为环绕通知
格式:
@Around("pt()")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
Object ret = pjp.proceed();
return ret;
}
执行顺序
AOP 使用 XML 配置情况下,通知的执行顺序由配置顺序决定,在注解情况下由于不存在配置顺序的概念,参照通知所配置的方法名字符串对应的编码值顺序,可以简单理解为字母排序
-
同一个通知类中,相同通知类型以方法名排序为准
@Before("aop.AOPPointcut.pt()") public void aop001Log(){} @Before("aop.AOPPointcut.pt()") public void aop002Exception(){} -
不同通知类中,以类名排序为准
-
使用 @Order 注解通过变更 bean 的加载顺序改变通知的加载顺序
@Component @Aspect @Order(1) //先执行 public class AOPAdvice2 { }@Component @Aspect @Order(2) public class AOPAdvice1 {//默认执行此通知 }
AOP 原理
静态代理
装饰者模式(Decorator Pattern):在不惊动原始设计的基础上,为其添加功能
public class UserServiceDecorator implements UserService{
private UserService userService;
public UserServiceDecorator(UserService userService) {
this.userService = userService;
}
public void save() {
//原始调用
userService.save();
//增强功能(后置)
System.out.println("后置增强功能");
}
}
Proxy
JDKProxy 动态代理是针对对象做代理,要求原始对象具有接口实现,并对接口方法进行增强,因为代理类继承Proxy
静态代理和动态代理的区别:
- 静态代理是在编译时就已经将接口、代理类、被代理类的字节码文件确定下来
- 动态代理是程序在运行后通过反射创建字节码文件交由 JVM 加载
public class UserServiceJDKProxy {
public static UserService createUserServiceJDKProxy(UserService userService) {
UserService service = (UserService) Proxy.newProxyInstance(
userService.getClass().getClassLoader(),//获取被代理对象的类加载器
userService.getClass().getInterfaces(), //获取被代理对象实现的接口
new InvocationHandler() { //对原始方法执行进行拦截并增强
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals("save")) {
System.out.println("前置增强");
Object ret = method.invoke(userService, args);
System.out.println("后置增强");
return ret;
}
return null;
}
});
return service;
}
}
CGLIB
CGLIB(Code Generation Library):Code 生成类库
CGLIB 特点:
- CGLIB 动态代理不限定是否具有接口,可以对任意操作进行增强
- CGLIB 动态代理无需要原始被代理对象,动态创建出新的代理对象
- CGLIB 继承被代理类,如果代理类是 final 则不能实现
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2hDSx3R8-1686861880273)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP底层原理-cglib.png)]
-
CGLIB 类
- JDKProxy 仅对接口方法做增强,CGLIB 对所有方法做增强,包括 Object 类中的方法(toString、hashCode)
- 返回值类型采用多态向下转型,所以需要设置父类类型
需要对方法进行判断是否是 save,来选择性增强
public class UserServiceImplCglibProxy { public static UserService createUserServiceCglibProxy(Class cls){ //1.创建Enhancer对象(可以理解为内存中动态创建了一个类的字节码) Enhancer enhancer = new Enhancer(); //2.设置Enhancer对象的父类是指定类型UserServerImpl enhancer.setSuperclass(cls); //3.设置回调方法 enhancer.setCallback(new MethodInterceptor() { @Override public Object intercept(Object o, Method m, Object[] args, MethodProxy mp) throws Throwable { //o是被代理出的类创建的对象,所以使用MethodProxy调用,并且是调用父类 //通过调用父类的方法实现对原始方法的调用 Object ret = methodProxy.invokeSuper(o, args); //后置增强内容,需要判断是都是save方法 if (method.getName().equals("save")) { System.out.println("I love Java"); } return ret; } }); //使用Enhancer对象创建对应的对象 return (UserService)enhancer.create(); } } -
Test类
public class App { public static void main(String[] args) { UserService userService = UserServiceCglibProxy.createUserServiceCglibProxy(UserServiceImpl.class); userService.save(); } }
代理选择
Spirng 可以通过配置的形式控制使用的代理形式,Spring 会先判断是否实现了接口,如果实现了接口就使用 JDK 动态代理,如果没有实现接口则使用 CGLIB 动态代理,通过配置可以修改为使用 CGLIB
-
XML 配置
<!--XML配置AOP--> <aop:config proxy-target-class="false"></aop:config> -
XML 注解支持
<!--注解配置AOP--> <aop:aspectj-autoproxy proxy-target-class="false"/> -
注解驱动
//修改为使用 cglib 创建代理对象 @EnableAspectJAutoProxy(proxyTargetClass = true)
-
JDK 动态代理和 CGLIB 动态代理的区别:
- JDK 动态代理只能对实现了接口的类生成代理,没有实现接口的类不能使用。
- CGLIB 动态代理即使被代理的类没有实现接口也可以使用,因为 CGLIB 动态代理是使用继承被代理类的方式进行扩展
- CGLIB 动态代理是通过继承的方式,覆盖被代理类的方法来进行代理,所以如果方法是被 final 修饰的话,就不能进行代理
织入时机
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KecHKpgF-1686861880273)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/AOP织入时机.png)]
事务
事务机制
事务介绍
事务:数据库中多个操作合并在一起形成的操作序列,事务特征(ACID)
作用:
- 当数据库操作序列中个别操作失败时,提供一种方式使数据库状态恢复到正常状态(A),保障数据库即使在异常状态下仍能保持数据一致性(C)(要么操作前状态,要么操作后状态)
- 当出现并发访问数据库时,在多个访问间进行相互隔离,防止并发访问操作结果互相干扰(I)
Spring 事务一般加到业务层,对应着业务的操作,Spring 事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,Spring 是无法提供事务功能的,Spring 只提供统一事务管理接口
Spring 在事务开始时,根据当前环境中设置的隔离级别,调整数据库隔离级别,由此保持一致。程序是否支持事务首先取决于数据库 ,比如 MySQL ,如果是 Innodb 引擎,是支持事务的;如果 MySQL 使用 MyISAM 引擎,那从根上就是不支持事务的
保证原子性:
- 要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行回滚
- 在 MySQL 中,恢复机制是通过回滚日志(undo log) 实现,所有事务进行的修改都会先先记录到这个回滚日志中,然后再执行相关的操作。如果执行过程中遇到异常的话,直接利用回滚日志中的信息将数据回滚到修改之前的样子即可
- 回滚日志会先于数据持久化到磁盘上,这样保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务
隔离级别
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
- TransactionDefinition.ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,MySQL 默认采用的 REPEATABLE_READ 隔离级别,Oracle 默认采用的 READ_COMMITTED隔离级别.
- TransactionDefinition.ISOLATION_READ_UNCOMMITTED:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
- TransactionDefinition.ISOLATION_READ_COMMITTED:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
- TransactionDefinition.ISOLATION_REPEATABLE_READ:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- TransactionDefinition.ISOLATION_SERIALIZABLE:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)
分布式事务:允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源,全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的 ACID 要求又有了提高
在使用分布式事务时,InnoDB 存储引擎的事务隔离级别必须设置为 SERIALIZABLE
传播行为
事务传播行为是为了解决业务层方法之间互相调用的事务问题,也就是方法嵌套:
-
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。
-
例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行
//外层事务 Service A 的 aMethod 调用内层 Service B 的 bMethod class A { @Transactional(propagation=propagation.xxx) public void aMethod { B b = new B(); b.bMethod(); } } class B { @Transactional(propagation=propagation.xxx) public void bMethod {} }
支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务则加入该事务;如果当前没有事务则创建一个新的事务
- 内外层是相同的事务,在 aMethod 或者在 bMethod 内的任何地方出现异常,事务都会被回滚
- 工作流程:
- 线程执行到 serviceA.aMethod() 时,其实是执行的代理 serviceA 对象的 aMethod
- 首先执行事务增强器逻辑(环绕增强),提取事务标签属性,检查当前线程是否绑定 connection 数据库连接资源,没有就调用 datasource.getConnection(),设置事务提交为手动提交 autocommit(false)
- 执行其他增强器的逻辑,然后调用 target 的目标方法 aMethod() 方法,进入 serviceB 的逻辑
- serviceB 也是先执行事务增强器的逻辑,提取事务标签属性,但此时会检查到线程绑定了 connection,检查注解的传播属性,所以调用 DataSourceUtils.getConnection(datasource) 共享该连接资源,执行完相关的增强和 SQL 后,发现事务并不是当前方法开启的,可以直接返回上层
- serviceA.aMethod() 继续执行,执行完增强后进行提交事务或回滚事务
- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行
- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常
不支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起
- 内外层是不同的事务,如果 bMethod 已经提交,如果 aMethod 失败回滚 ,bMethod 不会回滚
- 如果 bMethod 失败回滚,ServiceB 抛出的异常被 ServiceA 捕获,如果 B 抛出的异常是 A 会回滚的异常,aMethod 事务需要回滚,否则仍然可以提交
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起
- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常
其他情况:
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务(两个事务没有关系)来运行
- 如果 ServiceB 异常回滚,可以通过 try-catch 机制执行 ServiceC
- 如果 ServiceB 提交, ServiceA 可以根据具体的配置决定是 commit 还是 rollback
- 应用场景:在查询数据的时候要向数据库中存储一些日志,系统不希望存日志的行为影响到主逻辑,可以使用该传播
requied:必须的、supports:支持的、mandatory:强制的、nested:嵌套的
超时属性
事务超时,指一个事务所允许执行的最长时间,如果超过该时间限制事务还没有完成,则自动回滚事务。在 TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒,默认值为 -1
只读属性
对于只有读取数据查询的事务,可以指定事务类型为 readonly,即只读事务;只读事务不涉及数据的修改,数据库会提供一些优化手段,适合用在有多条数据库查询操作的方法中
读操作为什么需要启用事务支持:
- MySQL 默认对每一个新建立的连接都启用了
autocommit模式,在该模式下,每一个发送到 MySQL 服务器的 SQL 语句都会在一个单独的事务中进行处理,执行结束后会自动提交事务,并开启一个新的事务 - 执行多条查询语句,如果方法加上了
@Transactional注解,这个方法执行的所有 SQL 会被放在一个事务中,如果声明了只读事务的话,数据库就会去优化它的执行,并不会带来其他的收益。如果不加@Transactional,每条 SQL 会开启一个单独的事务,中间被其它事务修改了数据,比如在前条 SQL 查询之后,后条 SQL 查询之前,数据被其他用户改变,则这次整体的统计查询将会出现读数据不一致的状态
核心对象
事务对象
J2EE 开发使用分层设计的思想进行,对于简单的业务层转调数据层的单一操作,事务开启在业务层或者数据层并无太大差别,当业务中包含多个数据层的调用时,需要在业务层开启事务,对数据层中多个操作进行组合并归属于同一个事务进行处理
Spring 为业务层提供了整套的事务解决方案:
-
PlatformTransactionManager
-
TransactionDefinition
-
TransactionStatus
PTM
PlatformTransactionManager,平台事务管理器实现类:
-
DataSourceTransactionManager 适用于 Spring JDBC 或 MyBatis
-
HibernateTransactionManager 适用于 Hibernate3.0 及以上版本
-
JpaTransactionManager 适用于 JPA
-
JdoTransactionManager 适用于 JDO
-
JtaTransactionManager 适用于 JTA
管理器:
-
JPA(Java Persistence API)Java EE 标准之一,为 POJO 提供持久化标准规范,并规范了持久化开发的统一 API,符合 JPA 规范的开发可以在不同的 JPA 框架下运行
非持久化一个字段:
static String transient1; // not persistent because of static final String transient2 = “Satish”; // not persistent because of final transient String transient3; // not persistent because of transient @Transient String transient4; // not persistent because of @Transient -
JDO(Java Data Object)是 Java 对象持久化规范,用于存取某种数据库中的对象,并提供标准化 API。JDBC 仅针对关系数据库进行操作,JDO 可以扩展到关系数据库、XML、对象数据库等,可移植性更强
-
JTA(Java Transaction API)Java EE 标准之一,允许应用程序执行分布式事务处理。与 JDBC 相比,JDBC 事务则被限定在一个单一的数据库连接,而一个 JTA 事务可以有多个参与者,比如 JDBC 连接、JDO 都可以参与到一个 JTA 事务中
此接口定义了事务的基本操作:
| 方法 | 说明 |
|---|---|
| TransactionStatus getTransaction(TransactionDefinition definition) | 获取事务 |
| void commit(TransactionStatus status) | 提交事务 |
| void rollback(TransactionStatus status) | 回滚事务 |
Definition
TransactionDefinition 此接口定义了事务的基本信息:
| 方法 | 说明 |
|---|---|
| String getName() | 获取事务定义名称 |
| boolean isReadOnly() | 获取事务的读写属性 |
| int getIsolationLevel() | 获取事务隔离级别 |
| int getTimeout() | 获取事务超时时间 |
| int getPropagationBehavior() | 获取事务传播行为特征 |
Status
TransactionStatus 此接口定义了事务在执行过程中某个时间点上的状态信息及对应的状态操作:
| 方法 | 说明 |
|---|---|
| boolean isNewTransaction() | 获取事务是否处于新开始事务状态 |
| voin flush() | 刷新事务状态 |
| boolean isCompleted() | 获取事务是否处于已完成状态 |
| boolean hasSavepoint() | 获取事务是否具有回滚储存点 |
| boolean isRollbackOnly() | 获取事务是否处于回滚状态 |
| void setRollbackOnly() | 设置事务处于回滚状态 |
编程式
控制方式
编程式、声明式(XML)、声明式(注解)
环境准备
银行转账业务
-
包装类
public class Account implements Serializable { private Integer id; private String name; private Double money; ..... } -
DAO层接口:AccountDao
public interface AccountDao { //入账操作 name:入账用户名 money:入账金额 void inMoney(@Param("name") String name, @Param("money") Double money); //出账操作 name:出账用户名 money:出账金额 void outMoney(@Param("name") String name, @Param("money") Double money); } -
业务层接口提供转账操作:AccountService
public interface AccountService { //转账操作 outName:出账用户名 inName:入账用户名 money:转账金额 public void transfer(String outName,String inName,Double money); } -
业务层实现提供转账操作:AccountServiceImpl
public class AccountServiceImpl implements AccountService { private AccountDao accountDao; public void setAccountDao(AccountDao accountDao) { this.accountDao = accountDao; } @Override public void transfer(String outName,String inName,Double money){ accountDao.inMoney(outName,money); accountDao.outMoney(inName,money); } } -
映射配置文件:dao / AccountDao.xml
<mapper namespace="dao.AccountDao"> <update id="inMoney"> UPDATE account SET money = money + #{money} WHERE name = #{name} </update> <update id="outMoney"> UPDATE account SET money = money - #{money} WHERE name = #{name} </update> </mapper> -
jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://192.168.2.185:3306/spring_db jdbc.username=root jdbc.password=1234 -
核心配置文件:applicationContext.xml
<context:property-placeholder location="classpath:*.properties"/> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"> <property name="driverClassName" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </bean> <bean id="accountService" class="service.impl.AccountServiceImpl"> <property name="accountDao" ref="accountDao"/> </bean> <bean class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="typeAliasesPackage" value="domain"/> </bean> <!--扫描映射配置和Dao--> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="dao"/> </bean> -
测试类
ApplicationContext ctx = new ClassPathXmlApplicationContext("ap...xml"); AccountService accountService = (AccountService) ctx.getBean("accountService"); accountService.transfer("Jock1", "Jock2", 100d);
编程式
编程式事务就是代码显式的给出事务的开启和提交
-
修改业务层实现提供转账操作:AccountServiceImpl
public void transfer(String outName,String inName,Double money){ //1.创建事务管理器, DataSourceTransactionManager dstm = new DataSourceTransactionManager(); //2.为事务管理器设置与数据层相同的数据源 dstm.setDataSource(dataSource); //3.创建事务定义对象 TransactionDefinition td = new DefaultTransactionDefinition(); //4.创建事务状态对象,用于控制事务执行,【开启事务】 TransactionStatus ts = dstm.getTransaction(td); accountDao.inMoney(inName,money); int i = 1/0; //模拟业务层事务过程中出现错误 accountDao.outMoney(outName,money); //5.提交事务 dstm.commit(ts); } -
配置 applicationContext.xml
<!--添加属性注入--> <bean id="accountService" class="service.impl.AccountServiceImpl"> <property name="accountDao" ref="accountDao"/> <property name="dataSource" ref="dataSource"/> </bean>
AOP改造
-
将业务层的事务处理功能抽取出来制作成 AOP 通知,利用环绕通知运行期动态织入
public class TxAdvice { private DataSource dataSource; public void setDataSource(DataSource dataSource) { this.dataSource = dataSource; } public Object tx(ProceedingJoinPoint pjp) throws Throwable { //开启事务 PlatformTransactionManager ptm = new DataSourceTransactionManager(dataSource); //事务定义 TransactionDefinition td = new DefaultTransactionDefinition(); //事务状态 TransactionStatus ts = ptm.getTransaction(td); //pjp.getArgs()标准写法,也可以不加,同样可以传递参数 Object ret = pjp.proceed(pjp.getArgs()); //提交事务 ptm.commit(ts); return ret; } } -
配置 applicationContext.xml,要开启 AOP 空间
<!--修改bean的属性注入--> <bean id="accountService" class="service.impl.AccountServiceImpl"> <property name="accountDao" ref="accountDao"/> </bean> <!--配置AOP通知类,并注入dataSource--> <bean id="txAdvice" class="aop.TxAdvice"> <property name="dataSource" ref="dataSource"/> </bean> <!--使用环绕通知将通知类织入到原始业务对象执行过程中--> <aop:config> <aop:pointcut id="pt" expression="execution(* *..transfer(..))"/> <aop:aspect ref="txAdvice"> <aop:around method="tx" pointcut-ref="pt"/> </aop:aspect> </aop:config> -
修改业务层实现提供转账操作:AccountServiceImpl
public class AccountServiceImpl implements AccountService { private AccountDao accountDao; public void setAccountDao(AccountDao accountDao) { this.accountDao = accountDao; } @Override public void transfer(String outName,String inName,Double money){ accountDao.inMoney(outName,money); //int i = 1 / 0; accountDao.outMoney(inName,money); } }
声明式
XML
tx使用
删除 TxAdvice 通知类,开启 tx 命名空间,配置 applicationContext.xml
<!--配置平台事务管理器-->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--定义事务管理的通知类-->
<tx:advice id="txAdvice" transaction-manager="txManager">
<!--定义控制的事务-->
<tx:attributes>
<tx:method name="transfer" read-only="false"/>
</tx:attributes>
</tx:advice>
<!--使用aop:advisor在AOP配置中引用事务专属通知类,底层invoke调用-->
<aop:config>
<aop:pointcut id="pt" expression="execution(* service.*Service.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="pt"/>
</aop:config>
- aop:advice 与 aop:advisor 区别
-
aop:advice 配置的通知类可以是普通 Java 对象,不实现接口,也不使用继承关系
-
aop:advisor 配置的通知类必须实现通知接口,底层 invoke 调用
-
MethodBeforeAdvice
-
AfterReturningAdvice
-
ThrowsAdvice
-
-
pom.xml 文件引入依赖:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.1.9.RELEASE</version>
</dependency>
tx配置
advice
标签:tx:advice,beans 的子标签
作用:专用于声明事务通知
格式:
<beans>
<tx:advice id="txAdvice" transaction-manager="txManager">
</tx:advice>
</beans>
基本属性:
- id:用于配置 aop 时指定通知器的 id
- transaction-manager:指定事务管理器 bean
attributes
类型:tx:attributes,tx:advice 的子标签
作用:定义通知属性
格式:
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
</tx:attributes>
</tx:advice>
method
标签:tx:method,tx:attribute 的子标签
作用:设置具体的事务属性
格式:
<tx:attributes>
<!--标准格式-->
<tx:method name="*" read-only="false"/>
<tx:method name="get*" read-only="true"/>
<tx:method name="find*" read-only="true"/>
</tx:attributes>
<aop:pointcut id="pt" expression="execution(* service.*Service.*(..))"/><!--标准-->
说明:通常事务属性会配置多个,包含 1 个读写的全事务属性,1 个只读的查询类事务属性
属性:
- name:待添加事务的方法名表达式(支持 * 通配符)
- read-only:设置事务的读写属性,true 为只读,false 为读写
- timeout:设置事务的超时时长,单位秒,-1 为无限长
- isolation:设置事务的隔离界别,该隔离级设定是基于 Spring 的设定,非数据库端
- no-rollback-for:设置事务中不回滚的异常,多个异常使用
,分隔 - rollback-for:设置事务中必回滚的异常,多个异常使用
,分隔 - propagation:设置事务的传播行为
注解
开启注解
XML
标签:tx:annotation-driven
归属:beans 标签
作用:开启事务注解驱动,并指定对应的事务管理器
范例:
<tx:annotation-driven transaction-manager="txManager"/>
纯注解
名称:@EnableTransactionManagement
类型:类注解,Spring 注解配置类上方
作用:开启注解驱动,等同 XML 格式中的注解驱动
范例:
@Configuration
@ComponentScan("com.seazean")
@PropertySource("classpath:jdbc.properties")
@Import({JDBCConfig.class,MyBatisConfig.class,TransactionManagerConfig.class})
@EnableTransactionManagement
public class SpringConfig {
}
public class TransactionManagerConfig {
@Bean //自动装配
public PlatformTransactionManager getTransactionManager(@Autowired DataSource dataSource){
return new DataSourceTransactionManager(dataSource);
}
}
配置注解
名称:@Transactional
类型:方法注解,类注解,接口注解
作用:设置当前类/接口中所有方法或具体方法开启事务,并指定相关事务属性
范例:
@Transactional(
readOnly = false,
timeout = -1,
isolation = Isolation.DEFAULT,
rollbackFor = {ArithmeticException.class, IOException.class},
noRollbackFor = {},
propagation = Propagation.REQUIRES_NEW
)
public void addAccount{}
说明:
-
@Transactional注解只有作用到 public 方法上事务才生效 -
不推荐在接口上使用
@Transactional注解原因:在接口上使用注解,只有在使用基于接口的代理(JDK)时才会生效,因为注解是不能继承的,这就意味着如果正在使用基于类的代理(CGLIB)时,那么事务的设置将不能被基于类的代理所识别
-
正确的设置
@Transactional的 rollbackFor 和 propagation 属性,否则事务可能会回滚失败 -
默认情况下,事务只有遇到运行期异常 和 Error 会导致事务回滚,但是在遇到检查型(Checked)异常时不会回滚
- 继承自 RuntimeException 或 error 的是非检查型异常,比如空指针和索引越界,而继承自 Exception 的则是检查型异常,比如 IOException、ClassNotFoundException,RuntimeException 本身继承 Exception
- 非检查型类异常可以不用捕获,而检查型异常则必须用 try 语句块把异常交给上级方法,这样事务才能有效
事务不生效的问题
-
情况 1:确认创建的 MySQL 数据库表引擎是 InnoDB,MyISAM 不支持事务
-
情况 2:注解到 protected,private 方法上事务不生效,但不会报错
原因:理论上而言,不用 public 修饰,也可以用 aop 实现事务的功能,但是方法私有化让其他业务无法调用
AopUtils.canApply:
methodMatcher.matches(method, targetClass) --true--> return true
TransactionAttributeSourcePointcut.matches(),AbstractFallbackTransactionAttributeSource 中 getTransactionAttribute 方法调用了其本身的 computeTransactionAttribute 方法,当加了事务注解的方法不是 public 时,该方法直接返回 null,所以造成增强不匹配private TransactionAttribute computeTransactionAttribute(Method method, Class<?> targetClass) { // Don't allow no-public methods as required. if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) { return null; } } -
情况 3:注解所在的类没有被加载成 Bean
-
情况 4:在业务层捕捉异常后未向上抛出,事务不生效
原因:在业务层捕捉并处理了异常(try…catch)等于把异常处理掉了,Spring 就不知道这里有错,也不会主动去回滚数据,推荐做法是在业务层统一抛出异常,然后在控制层统一处理
-
情况 5:遇到检测异常时,也无法回滚
原因:Spring 的默认的事务规则是遇到运行异常(RuntimeException)和程序错误(Error)才会回滚。想针对检测异常进行事务回滚,可以在 @Transactional 注解里使用 rollbackFor 属性明确指定异常
-
情况 6:Spring 的事务传播策略在内部方法调用时将不起作用,在一个 Service 内部,事务方法之间的嵌套调用,普通方法和事务方法之间的嵌套调用,都不会开启新的事务,事务注解要加到调用方法上才生效
原因:Spring 的事务都是使用 AOP 代理的模式,动态代理 invoke 后会调用原始对象,而原始对象在去调用方法时是不会触发拦截器,就是一个方法调用本对象的另一个方法,所以事务也就无法生效
@Transactional public int add(){ update(); } //注解添加在update方法上无效,需要添加到add()方法上 public int update(){} -
情况 7:注解在接口上,代理对象是 CGLIB
使用注解
-
Dao 层
public interface AccountDao { @Update("update account set money = money + #{money} where name = #{name}") void inMoney(@Param("name") String name, @Param("money") Double money); @Update("update account set money = money - #{money} where name = #{name}") void outMoney(@Param("name") String name, @Param("money") Double money); } -
业务层
public interface AccountService { //对当前方法添加事务,该配置将替换接口的配置 @Transactional( readOnly = false, timeout = -1, isolation = Isolation.DEFAULT, rollbackFor = {},//java.lang.ArithmeticException.class, IOException.class noRollbackFor = {}, propagation = Propagation.REQUIRED ) public void transfer(String outName, String inName, Double money); }public class AccountServiceImpl implements AccountService { @Autowired private AccountDao accountDao; public void transfer(String outName, String inName, Double money) { accountDao.inMoney(outName,money); //int i = 1/0; accountDao.outMoney(inName,money); } } -
添加文件 Spring.config、Mybatis.config、JDBCConfig (参考ioc_Mybatis)、TransactionManagerConfig
@Configuration @ComponentScan({"","",""}) @PropertySource("classpath:jdbc.properties") @Import({JDBCConfig.class,MyBatisConfig.class}) @EnableTransactionManagement public class SpringConfig { }
模板对象
Spring 模板对象:TransactionTemplate、JdbcTemplate、RedisTemplate、RabbitTemplate、JmsTemplate、HibernateTemplate、RestTemplate
-
JdbcTemplate:提供标准的 sql 语句操作API
-
NamedParameterJdbcTemplate:提供标准的具名 sql 语句操作API
-
RedisTemplate:
public void changeMoney(Integer id, Double money) { redisTemplate.opsForValue().set("account:id:"+id,money); } public Double findMondyById(Integer id) { Object money = redisTemplate.opsForValue().get("account:id:" + id); return new Double(money.toString()); }

原理
XML
三大对象:
-
BeanDefinition:是 Spring 中极其重要的一个概念,存储了 bean 对象的所有特征信息,如是否单例、是否懒加载、factoryBeanName 等,和 bean 的关系就是类与对象的关系,一个不同的 bean 对应一个 BeanDefinition
-
BeanDefinationRegistry:存放 BeanDefination 的容器,是一种键值对的形式,通过特定的 Bean 定义的 id,映射到相应的 BeanDefination,BeanFactory 的实现类同样继承 BeanDefinationRegistry 接口,拥有保存 BD 的能力
-
BeanDefinitionReader:读取配置文件,XML 用 Dom4j 解析,注解用 IO 流加载解析
程序:
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("applicationContext.xml"));
UserService userService1 = (UserService)bf.getBean("userService");
源码解析:
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
public int loadBeanDefinitions(Resource resource) {
//将 resource 包装成带编码格式的 EncodedResource
//EncodedResource 中 getReader()方法,调用java.io包下的 转换流 创建指定编码的输入流对象
return loadBeanDefinitions(new EncodedResource(resource));
}
-
XmlBeanDefinitionReader.loadBeanDefinitions():把 Resource 解析成 BeanDefinition 对象currentResources = this.resourcesCurrentlyBeingLoaded.get():拿到当前线程已经加载过的所有 EncodedResoure 资源,用 ThreadLocal 保证线程安全if (currentResources == null):判断 currentResources 是否为空,为空则进行初始化if (!currentResources.add(encodedResource)):如果已经加载过该资源会报错,防止重复加载inputSource = new InputSource(inputStream):资源对象包装成 InputSource,InputSource 是 SAX 中的资源对象,用来进行 XML 文件的解析return doLoadBeanDefinitions():加载返回currentResources.remove(encodedResource):加载完成移除当前 encodedResourceresourcesCurrentlyBeingLoaded.remove():ThreadLocal 为空时移除元素,防止内存泄露
-
XmlBeanDefinitionReader.doLoadBeanDefinitions(inputSource, resource):真正的加载函数Document doc = doLoadDocument(inputSource, resource):转换成有层次结构的 Document 对象-
getEntityResolver():获取用来解析 DTD、XSD 约束的解析器 -
getValidationModeForResource(resource):获取验证模式
int count = registerBeanDefinitions(doc, resource):将 Document 解析成 BD 对象,注册(添加)到 BeanDefinationRegistry 中,返回新注册的数量createBeanDefinitionDocumentReader():创建 DefaultBeanDefinitionDocumentReader 对象getRegistry().getBeanDefinitionCount():获取解析前 BeanDefinationRegistry 中的 bd 数量registerBeanDefinitions(doc, readerContext):注册 BDthis.readerContext = readerContext:保存上下文对象doRegisterBeanDefinitions(doc.getDocumentElement()):真正的注册 BD 函数doc.getDocumentElement():拿出顶层标签
return getRegistry().getBeanDefinitionCount() - countBefore:返回新加入的数量
-
-
DefaultBeanDefinitionDocumentReader.doRegisterBeanDefinitions():注册 BD 到 BRcreateDelegate(getReaderContext(), root, parent):beans 是标签的解析器对象delegate.isDefaultNamespace(root):判断 beans 标签是否是默认的属性root.getAttribute(PROFILE_ATTRIBUTE):解析 profile 属性preProcessXml(root):解析前置处理,自定义实现parseBeanDefinitions(root, this.delegate):解析 beans 标签中的子标签parseDefaultElement(ele, delegate):如果是默认的标签,用该方法解析子标签- 判断标签名称,进行相应的解析
processBeanDefinition(ele, delegate):
delegate.parseCustomElement(ele):解析自定义的标签
postProcessXml(root):解析后置处理
-
DefaultBeanDefinitionDocumentReader.processBeanDefinition():解析 bean 标签并注册到注册中心-
delegate.parseBeanDefinitionElement(ele):解析 bean 标签封装为 BeanDefinitionHolder-
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()):条件一成立说明 name 没有值,条件二成立说明别名有值beanName = aliases.remove(0):拿别名列表的第一个元素当作 beanName -
parseBeanDefinitionElement(ele, beanName, containingBean):解析 bean 标签parseState.push(new BeanEntry(beanName)):当前解析器的状态设置为 BeanEntry- class 和 parent 属性存在一个,parent 是作为父标签为了被继承
createBeanDefinition(className, parent):设置了class 的 GenericBeanDefinition对象parseBeanDefinitionAttributes():解析 bean 标签的属性- 接下来解析子标签
-
beanName = this.readerContext.generateBeanName(beanDefinition):生成 className + # + 序号的名称赋值给 beanName -
return new BeanDefinitionHolder(beanDefinition, beanName, aliases):包装成 BeanDefinitionHolder
-
-
registerBeanDefinition(bdHolder, getReaderContext().getRegistry()):注册到容器beanName = definitionHolder.getBeanName():获取beanNamethis.beanDefinitionMap.put(beanName, beanDefinition):添加到注册中心
-
getReaderContext().fireComponentRegistered():发送注册完成事件
-
说明:源码部分的笔记不一定适合所有人阅读,作者采用流水线式去解析重要的代码,解析的结构类似于树状,如果视觉疲劳可以去网上参考一些博客和流程图学习源码。
IOC
容器启动
Spring IOC 容器是 ApplicationContext 或者 BeanFactory,使用多个 Map 集合保存单实例 Bean,环境信息等资源,不同层级有不同的容器,比如整合 SpringMVC 的父子容器(先看 Bean 部分的源码解析再回看容器)
ClassPathXmlApplicationContext 与 AnnotationConfigApplicationContext 差不多:
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
this();
register(annotatedClasses);// 解析配置类,封装成一个 BeanDefinitionHolder,并注册到容器
refresh();// 加载刷新容器中的 Bean
}
public AnnotationConfigApplicationContext() {
// 注册 Spring 的注解解析器到容器
this.reader = new AnnotatedBeanDefinitionReader(this);
// 实例化路径扫描器,用于对指定的包目录进行扫描查找 bean 对象
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
AbstractApplicationContext.refresh():
-
prepareRefresh():刷新前的预处理
this.startupDate = System.currentTimeMillis():设置容器的启动时间initPropertySources():初始化一些属性设置,可以自定义个性化的属性设置方法getEnvironment().validateRequiredProperties():检查环境变量earlyApplicationEvents= new LinkedHashSet<ApplicationEvent>():保存容器中早期的事件
-
obtainFreshBeanFactory():获取一个全新的 BeanFactory 接口实例,如果容器中存在工厂实例直接销毁
refreshBeanFactory():创建 BeanFactory,设置序列化 ID、读取 BeanDefinition 并加载到工厂if (hasBeanFactory()):applicationContext 内部拥有一个 beanFactory 实例,需要将该实例完全释放销毁destroyBeans():销毁原 beanFactory 实例,将 beanFactory 内部维护的单实例 bean 全部清掉,如果哪个 bean 实现了 Disposablejie接口,还会进行 bean distroy 方法的调用处理this.singletonsCurrentlyInDestruction = true:设置当前 beanFactory 状态为销毁状态String[] disposableBeanNames:获取销毁集合中的 bean,如果当前 bean 有析构函数就会在销毁集合destroySingleton(disposableBeanNames[i]):遍历所有的 disposableBeans,执行销毁方法removeSingleton(beanName):清除三级缓存和 registeredSingletons 中的当前 beanName 的数据this.disposableBeans.remove(beanName):从销毁集合中清除,每个 bean 只能 destroy 一次destroyBean(beanName, disposableBean):销毁 bean- dependentBeanMap 记录了依赖当前 bean 的其他 bean 信息,因为依赖的对象要被回收了,所以依赖当前 bean 的其他对象都要执行 destroySingleton,遍历 dependentBeanMap 执行销毁
bean.destroy():解决完成依赖后,执行 DisposableBean 的 destroy 方法this.dependenciesForBeanMap.remove(beanName):保存当前 bean 依赖了谁,直接清除
- 进行一些集合和缓存的清理工作
closeBeanFactory():将容器内部的 beanFactory 设置为空,重新创建beanFactory = createBeanFactory():创建新的 DefaultListableBeanFactory 对象beanFactory.setSerializationId(getId()):进行 ID 的设置,可以根据 ID 获取 BeanFactory 对象customizeBeanFactory(beanFactory):设置是否允许覆盖和循环引用loadBeanDefinitions(beanFactory):加载 BeanDefinition 信息,注册 BD注册到 BeanFactory 中this.beanFactory = beanFactory:把 beanFactory 填充至容器中
getBeanFactory():返回创建的 DefaultListableBeanFactory 对象,该对象继承 BeanDefinitionRegistry -
prepareBeanFactory(beanFactory):BeanFactory 的预准备工作,向容器中添加一些组件
setBeanClassLoader(getClassLoader()):给当前 bf 设置一个类加载器,加载 bd 的 class 信息setBeanExpressionResolver():设置 EL 表达式解析器addPropertyEditorRegistrar:添加一个属性编辑器,解决属性注入时的格式转换addBeanPostProcessor():添加后处理器,主要用于向 bean 内部注入一些框架级别的实例ignoreDependencyInterface():设置忽略自动装配的接口,bean 内部的这些类型的字段 不参与依赖注入registerResolvableDependency():注册一些类型依赖关系addBeanPostProcessor():将配置的监听者注册到容器中,当前 bean 实现 ApplicationListener 接口就是监听器事件beanFactory.registerSingleton():添加一些系统信息
-
postProcessBeanFactory(beanFactory):BeanFactory 准备工作完成后进行的后置处理工作,扩展方法
-
invokeBeanFactoryPostProcessors(beanFactory):执行 BeanFactoryPostProcessor 的方法
-
processedBeans = new HashSet<>():存储已经执行过的 BeanFactoryPostProcessor 的 beanName -
if (beanFactory instanceof BeanDefinitionRegistry):当前 BeanFactory 是 bd 的注册中心,bd 全部注册到 bf -
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors):遍历所有的 bf 后置处理器 -
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor):是 Registry 类的后置处理器registryProcessor.postProcessBeanDefinitionRegistry(registry):向 bf 中注册一些 bdregistryProcessors.add(registryProcessor):添加到 BeanDefinitionRegistryPostProcessor 集合 -
regularPostProcessors.add(postProcessor):添加到 BeanFactoryPostProcessor 集合 -
逻辑到这里已经获取到所有 BeanDefinitionRegistryPostProcessor 和 BeanFactoryPostProcessor 接口类型的后置处理器
-
首先回调 BeanDefinitionRegistryPostProcessor 类的后置处理方法 postProcessBeanDefinitionRegistry()
-
获取实现了 PriorityOrdered(主排序接口)接口的 bdrpp,进行 sort 排序,然后全部执行并放入已经处理过的集合
-
再执行实现了 Ordered(次排序接口)接口的 bdrpp
-
最后执行没有实现任何优先级或者是顺序接口 bdrpp,
boolean reiterate = true控制 while 是否需要再次循环,循环内是查找并执行 bdrpp 后处理器的 registry 相关的接口方法,接口方法执行以后会向 bf 内注册 bd,注册的 bd 也有可能是 bdrpp 类型,所以需要该变量控制循环 -
processedBeans.add(ppName):已经执行过的后置处理器存储到该集合中,防止重复执行 -
invokeBeanFactoryPostProcessors():bdrpp 继承了 BeanFactoryPostProcessor,有 postProcessBeanFactory 方法
-
-
执行普通 BeanFactoryPostProcessor 的相关 postProcessBeanFactory 方法,按照主次无次序执行
if (processedBeans.contains(ppName)):会过滤掉已经执行过的后置处理器
-
beanFactory.clearMetadataCache():清除缓存中合并的 Bean 定义,因为后置处理器可能更改了元数据
-
以上是 BeanFactory 的创建及预准备工作,接下来进入 Bean 的流程
-
registerBeanPostProcessors(beanFactory):注册 Bean 的后置处理器,为了干预 Spring 初始化 bean 的流程,这里仅仅是向容器中注入而非使用
-
beanFactory.getBeanNamesForType(BeanPostProcessor.class):获取配置中实现了 BeanPostProcessor 接口类型 -
int beanProcessorTargetCount:后置处理器的数量,已经注册的 + 未注册的 + 即将要添加的一个 -
beanFactory.addBeanPostProcessor(new BeanPostProcessorChecker()):添加一个检查器BeanPostProcessorChecker.postProcessAfterInitialization():初始化后的后处理器方法!(bean instanceof BeanPostProcessor):当前 bean 类型是普通 bean,不是后置处理器!isInfrastructureBean(beanName):成立说明当前 beanName 是用户级别的 bean 不是 Spring 框架的this.beanFactory.getBeanPostProcessorCount() < this.beanPostProcessorTargetCount:BeanFactory 上面注册后处理器数量 < 后处理器数量,说明后处理框架尚未初始化完成
-
for (String ppName : postProcessorNames):遍历 PostProcessor 集合,根据实现不同的顺序接口添加到不同集合 -
sortPostProcessors(priorityOrderedPostProcessors, beanFactory):实现 PriorityOrdered 接口的后处理器排序registerBeanPostProcessors(beanFactory, priorityOrderedPostProcessors):注册到 beanFactory 中 -
接着排序注册实现 Ordered 接口的后置处理器,然后注册普通的( 没有实现任何优先级接口)后置处理器
-
最后排序 MergedBeanDefinitionPostProcessor 类型的处理器,根据实现的排序接口,排序完注册到 beanFactory 中
-
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(applicationContext)):重新注册 ApplicationListenerDetector 后处理器,用于在 Bean 创建完成后检查是否属于 ApplicationListener 类型,如果是就把 Bean 放到监听器容器中保存起来
-
-
initMessageSource():初始化 MessageSource 组件,主要用于做国际化功能,消息绑定与消息解析
if (beanFactory.containsLocalBean(MESSAGE_SOURCE_BEAN_NAME)):容器是否含有名称为 messageSource 的 beanbeanFactory.getBean(MESSAGE_SOURCE_BEAN_NAME, MessageSource.class):如果有证明用户自定义了该类型的 bean,获取后直接赋值给 this.messageSourcedms = new DelegatingMessageSource():容器中没有就新建一个赋值
-
initApplicationEventMulticaster():初始化事件传播器,在注册监听器时会用到
if (beanFactory.containsLocalBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME)):条件成立说明用户自定义了事件传播器,可以实现 ApplicationEventMulticaster 接口编写自己的事件传播器,通过 bean 的方式提供给 Spring- 如果有就直接从容器中获取;如果没有则创建一个 SimpleApplicationEventMulticaster 注册
-
onRefresh():留给用户去实现,可以硬编码提供一些组件,比如提供一些监听器
-
registerListeners():注册通过配置提供的 Listener,这些监听器最终注册到 ApplicationEventMulticaster 内
-
for (ApplicationListener<?> listener : getApplicationListeners()):注册编码实现的监听器 -
getBeanNamesForType(ApplicationListener.class, true, false):注册通过配置提供的 Listener -
multicastEvent(earlyEvent):发布前面步骤产生的事件 applicationEventsExecutor executor = getTaskExecutor():获取线程池,有线程池就异步执行,没有就同步执行
-
-
finishBeanFactoryInitialization():实例化非懒加载状态的单实例
-
beanFactory.freezeConfiguration():冻结配置信息,就是冻结 BD 信息,冻结后无法再向 bf 内注册 bd -
beanFactory.preInstantiateSingletons():实例化 non-lazy-init singletons-
for (String beanName : beanNames):遍历容器内所有的 beanDefinitionNames -
getMergedLocalBeanDefinition(beanName):获取与父类合并后的对象(Bean → 获取流程部分详解此函数) -
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()):BD 对应的 Class 满足非抽象、单实例,非懒加载,需要预先实例化if (isFactoryBean(beanName)):BD 对应的 Class 是 factoryBean 对象getBean(FACTORY_BEAN_PREFIX + beanName):获取工厂 FactoryBean 实例本身isEagerInit:控制 FactoryBean 内部管理的 Bean 是否也初始化getBean(beanName):初始化 Bean,获取 Bean 详解此函数
getBean(beanName):不是工厂 bean 直接获取 -
for (String beanName : beanNames):检查所有的 Bean 是否实现 SmartInitializingSingleton 接口,实现了就执行 afterSingletonsInstantiated(),进行一些创建后的操作
-
-
-
finishRefresh():完成刷新后做的一些事情,主要是启动生命周期clearResourceCaches():清空上下文缓存initLifecycleProcessor():初始化和生命周期有关的后置处理器,容器的生命周期if (beanFactory.containsLocalBean(LIFECYCLE_PROCESSOR_BEAN_NAME)):成立说明自定义了生命周期处理器defaultProcessor = new DefaultLifecycleProcessor():Spring 默认提供的生命周期处理器beanFactory.registerSingleton():将生命周期处理器注册到 bf 的一级缓存和注册单例集合中
getLifecycleProcessor().onRefresh():获取该生命周期后置处理器回调 onRefresh(),调用startBeans(true)lifecycleBeans = getLifecycleBeans():获取到所有实现了 Lifecycle 接口的对象包装到 Map 内,key 是beanName, value 是 Lifecycle 对象int phase = getPhase(bean):获取当前 Lifecycle 的 phase 值,当前生命周期对象可能依赖其他生命周期对象的执行结果,所以需要 phase 决定执行顺序,数值越低的优先执行LifecycleGroup group = phases.get(phase):把 phsae 相同的 Lifecycle 存入 LifecycleGroupif (group == null):group 为空则创建,初始情况下是空的group.add(beanName, bean):将当前 Lifecycle 添加到当前 phase 值一样的 group 内Collections.sort(keys):从小到大排序,按优先级启动phases.get(key).start():遍历所有的 Lifecycle 对象开始启动doStart(this.lifecycleBeans, member.name, this.autoStartupOnly):底层调用该方法启动bean = lifecycleBeans.remove(beanName): 确保 Lifecycle 只被启动一次,在一个分组内被启动了在其他分组内就看不到 Lifecycle 了dependenciesForBean = getBeanFactory().getDependenciesForBean(beanName):获取当前即将被启动的 Lifecycle 所依赖的其他 beanName,需要先启动所依赖的 bean,才能启动自身if ():传入的参数 autoStartupOnly 为 true 表示启动 isAutoStartUp 为 true 的 SmartLifecycle 对象,不会启动普通的生命周期的对象;false 代表全部启动- bean.start():调用启动方法
publishEvent(new ContextRefreshedEvent(this)):发布容器刷新完成事件liveBeansView.registerApplicationContext(this):暴露 Mbean
补充生命周期 stop() 方法的调用
-
DefaultLifecycleProcessor.stop():调用 DefaultLifecycleProcessor.stopBeans()
-
获取到所有实现了 Lifecycle 接口的对象并按 phase 数值分组的
-
keys.sort(Collections.reverseOrder()):按 phase 降序排序 Lifecycle 接口,最先启动的最晚关闭(责任链?) -
phases.get(key).stop():遍历所有的 Lifecycle 对象开始停止-
latch = new CountDownLatch(this.smartMemberCount):创建 CountDownLatch,设置 latch 内部的值为当前分组内的 smartMemberCount 的数量 -
countDownBeanNames = Collections.synchronizedSet(new LinkedHashSet<>()):保存当前正在处理关闭的smartLifecycle 的 BeanName -
for (LifecycleGroupMember member : this.members):处理本分组内需要关闭的 LifecycledoStop(this.lifecycleBeans, member.name, latch, countDownBeanNames):真正的停止方法-
getBeanFactory().getDependentBeans(beanName):获取依赖当前 Lifecycle 的其他对象的 beanName,因为当前的 Lifecycle 即将要关闭了,所有的依赖了当前 Lifecycle 的 bean 也要关闭 -
countDownBeanNames.add(beanName):将当前 SmartLifecycle beanName 添加到 countDownBeanNames 集合内,该集合表示正在关闭的 SmartLifecycle -
bean.stop():调用停止的方法
-
-
-
获取Bean
单实例:在容器启动时创建对象
多实例:在每次获取的时候创建对象
获取流程:获取 Bean 时先从单例池获取,如果没有则进行第二次获取,并带上工厂类去创建并添加至单例池
Java 启动 Spring 代码:
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService = (UserService) context.getBean("userService");
AbstractBeanFactory.doGetBean():获取 Bean,context.getBean() 追踪到此
-
beanName = transformedBeanName(name):name 可能是一个别名,重定向出来真实 beanName;也可能是一个 & 开头的 name,说明要获取的 bean 实例对象,是一个 FactoryBean 对象(IOC 原理 → 核心类)BeanFactoryUtils.transformedBeanName(name):判断是哪种 name,返回截取 & 以后的 name 并放入缓存transformedBeanNameCache.computeIfAbsent:缓存是并发安全集合,key == null || value == null 时 put 成功- do while 循环一直去除 & 直到不再含有 &
canonicalName(name):aliasMap 保存别名信息,其中的 do while 逻辑是迭代查找,比如 A 别名叫做 B,但是 B 又有别名叫 C, aliasMap 为 {“C”:“B”, “B”:“A”},get© 最后返回的是 A
-
DefaultSingletonBeanRegistry.getSingleton():第一次获取从缓存池获取(循环依赖详解此代码)- 缓存中有数据进行 getObjectForBeanInstance() 获取可使用的 Bean(本节结束部分详解此函数)
- 缓存中没有数据进行下面的逻辑进行创建
-
if(isPrototypeCurrentlyInCreation(beanName)):检查 bean 是否在原型(Prototype)正在被创建的集合中,如果是就报错,说明产生了循环依赖,原型模式解决不了循环依赖原因:先加载 A,把 A 加入集合,A 依赖 B 去加载 B,B 又依赖 A,去加载 A,发现 A 在正在创建集合中,产生循环依赖
-
markBeanAsCreated(beanName):把 bean 标记为已经创建,防止其他线程重新创建 Bean -
mbd = getMergedLocalBeanDefinition(beanName):获取合并父 BD 后的 BD 对象,BD 是直接继承的,合并后的 BD 信息是包含父类的 BD 信息-
this.mergedBeanDefinitions.get(beanName):从缓存中获取 -
if(bd.getParentName()==null):beanName 对应 BD 没有父 BD 就不用处理继承,封装为 RootBeanDefinition 返回 -
parentBeanName = transformedBeanName(bd.getParentName()):处理父 BD 的 name 信息 -
if(!beanName.equals(parentBeanName)):一般情况父子 BD 的名称不同pbd = getMergedBeanDefinition(parentBeanName):递归调用,最终返回父 BD 的父 BD 信息 -
mbd = new RootBeanDefinition(pbd):按照父 BD 信息创建 RootBeanDefinition 对象 -
mbd.overrideFrom(bd):子 BD 信息覆盖 mbd,因为是要以子 BD 为基准,不存在的才去父 BD 寻找(类似 Java 继承) -
this.mergedBeanDefinitions.put(beanName, mbd):放入缓存
-
-
checkMergedBeanDefinition():判断当前 BD 是否为抽象 BD,抽象 BD 不能创建实例,只能作为父 BD 被继承 -
mbd.getDependsOn():获取 bean 标签 depends-on -
if(dependsOn != null):遍历所有的依赖加载,解决不了循环依赖isDependent(beanName, dep):判断循环依赖,出现循环依赖问题报错-
两个 Map:
<bean name="A" depends-on="B" ...>- dependentBeanMap:记录依赖了当前 beanName 的其他 beanName(谁依赖我,我记录谁)
- dependenciesForBeanMap:记录当前 beanName 依赖的其它 beanName
- 以 B 为视角 dependentBeanMap {“B”:{“A”}},以 A 为视角 dependenciesForBeanMap {“A” :{“B”}}
-
canonicalName(beanName):处理 bean 的 name -
dependentBeans = this.dependentBeanMap.get(canonicalName):获取依赖了当前 bean 的 name -
if (dependentBeans.contains(dependentBeanName)):依赖了当前 bean 的集合中是否有该 name,有就产生循环依赖 -
进行递归处理所有的引用:假如
<bean name="A" dp="B"> <bean name="B" dp="C"> <bean name="C" dp="A">dependentBeanMap={A:{C}, B:{A}, C:{B}} // C 依赖 A 判断谁依赖了C 递归判断 谁依赖了B isDependent(C, A) → C#dependentBeans={B} → isDependent(B, A); → B#dependentBeans={A} //返回true
registerDependentBean(dep, beanName):把 bean 和依赖注册到两个 Map 中,注意参数的位置,被依赖的在前getBean(dep):先加载依赖的 Bean,又进入 doGetBean() 的逻辑 -
-
if (mbd.isSingleton()):判断 bean 是否是单例的 beangetSingleton(String, ObjectFactory<?>):第二次获取,传入一个工厂对象,这个方法更倾向于创建实例并返回sharedInstance = getSingleton(beanName, () -> { return createBean(beanName, mbd, args);//创建,跳转生命周期 //lambda表达式,调用了ObjectFactory的getObject()方法,实际回调接口实现的是 createBean()方法进行创建对象 });-
singletonObjects.get(beanName):从一级缓存检查是否已经被加载,单例模式复用已经创建的 bean -
this.singletonsCurrentlyInDestruction:容器销毁时会设置这个属性为 true,这时就不能再创建 bean 实例了 -
beforeSingletonCreation(beanName):检查构造注入的依赖,构造参数注入产生的循环依赖无法解决!this.singletonsCurrentlyInCreation.add(beanName):将当前 beanName 放入到正在创建中单实例集合,放入成功说明没有产生循环依赖,失败则产生循环依赖,进入判断条件内的逻辑抛出异常原因:加载 A,向正在创建集合中添加了 {A},根据 A 的构造方法实例化 A 对象,发现 A 的构造方法依赖 B,然后加载 B,B 构造方法的参数依赖于 A,又去加载 A 时来到当前方法,因为创建中集合已经存在 A,所以添加失败
-
singletonObject = singletonFactory.getObject():创建 bean(生命周期部分详解) -
创建完成以后,Bean 已经初始化好,是一个完整的可使用的 Bean
-
afterSingletonCreation(beanName):从正在创建中的集合中移出 -
addSingleton(beanName, singletonObject):添加一级缓存单例池中,从二级三级缓存移除
bean = getObjectForBeanInstance:单实例可能是普通单实例或者 FactoryBean,如果是 FactoryBean 实例,需要判断 name 是带 & 还是不带 &,带 & 说明 getBean 获取 FactoryBean 对象,否则是获取 FactoryBean 内部管理的实例-
参数 name 是未处理 & 的 name,beanName 是处理过 & 和别名后的 name
-
if(BeanFactoryUtils.isFactoryDereference(name)):判断 doGetBean 中参数 name 前是否带 &,不是处理后的 -
if(!(beanInstance instanceof FactoryBean) || BeanFactoryUtils.isFactoryDereference(name)):Bean 是普通单实例或者是 FactoryBean 就可以直接返回,否则进入下面的获取 FactoryBean 内部管理的实例的逻辑 -
getCachedObjectForFactoryBean(beanName):尝试到缓存获取,获取到直接返回,获取不到进行下面逻辑 -
if (mbd == null && containsBeanDefinition(beanName)):Spring 中有当前 beanName 的 BeanDefinition 信息mbd = getMergedLocalBeanDefinition(beanName):获取合并后的 BeanDefinition -
mbd.isSynthetic():默认值是 false 表示这是一个用户对象,如果是 true 表示是系统对象 -
object = getObjectFromFactoryBean(factory, beanName, !synthetic):从工厂内获取实例factory.isSingleton() && containsSingleton(beanName):工厂内部维护的对象是单实例并且一级缓存存在该 bean- 首先去缓存中获取,获取不到就使用工厂获取然后放入缓存,进行循环依赖判断
-
-
else if (mbd.isPrototype()):bean 是原型的 beanbeforePrototypeCreation(beanName):当前线程正在创建的原型对象 beanName 存入 prototypesCurrentlyInCreationcurVal = this.prototypesCurrentlyInCreation.get():获取当前线程的正在创建的原型类集合this.prototypesCurrentlyInCreation.set(beanName):集合为空就把当前 beanName 加入if (curVal instanceof String):已经有线程相关原型类创建了,把当前的创建的加进去
createBean(beanName, mbd, args):创建原型类对象,不需要三级缓存afterPrototypeCreation(beanName):从正在创建中的集合中移除该 beanName, 与 beforePrototypeCreation逻辑相反 -
convertIfNecessary():依赖检查,检查所需的类型是否与实际 bean 实例的类型匹配 -
return (T) bean:返回创建完成的 bean
生命周期
四个阶段
Bean 的生命周期:实例化 instantiation,填充属性 populate,初始化 initialization,销毁 destruction
AbstractAutowireCapableBeanFactory.createBean():进入 Bean 生命周期的流程
-
resolvedClass = resolveBeanClass(mbd, beanName):判断 mdb 中的 class 是否已经加载到 JVM,如果未加载则使用类加载器将 beanName 加载到 JVM中并返回 class 对象 -
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null):条件成立封装 mbd 并把 resolveBeanClass 设置到 bd 中- 条件二:mbd 在 resolveBeanClass 之前是否有 class
- 条件三:mbd 有 className
-
bean = resolveBeforeInstantiation(beanName, mbdToUse):实例化前的后置处理器返回一个代理实例对象(不是 AOP)- 自定义类继承 InstantiationAwareBeanPostProcessor,重写 postProcessBeforeInstantiation 方法,方法逻辑为创建对象
- 并配置文件
<bean class="intefacePackage.MyInstantiationAwareBeanPostProcessor">导入为 bean - 条件成立,短路操作,直接 return bean
-
Object beanInstance = doCreateBean(beanName, mbdToUse, args):Do it
AbstractAutowireCapableBeanFactory.doCreateBean(beanName, RootBeanDefinition, Object[] args):创建 Bean
-
BeanWrapper instanceWrapper = null:Spring 给所有创建的 Bean 实例包装成 BeanWrapper,内部最核心的方法是获取实例,提供了一些额外的接口方法,比如属性访问器 -
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName):单例对象尝试从缓存中获取,会移除缓存 -
createBeanInstance():缓存中没有实例就进行创建实例(逻辑复杂,下一小节详解) -
if (!mbd.postProcessed):每个 bean 只进行一次该逻辑applyMergedBeanDefinitionPostProcessors():后置处理器,合并 bd 信息,接下来要属性填充了AutowiredAnnotationBeanPostProcessor.postProcessMergedBeanDefinition():后置处理逻辑(@Autowired)-
metadata = findAutowiringMetadata(beanName, beanType, null):提取当前 bean 整个继承体系内的 @Autowired、@Value、@Inject 信息,存入一个 InjectionMetadata 对象,保存着当前 bean 信息和要自动注入的字段信息private final Class<?> targetClass; //当前 bean private final Collection<InjectedElement> injectedElements; //要注入的信息集合-
metadata = buildAutowiringMetadata(clazz):查询当前 clazz 感兴趣的注解信息-
ReflectionUtils.doWithLocalFields():提取字段的注解的信息findAutowiredAnnotation(field):代表感兴趣的注解就是那三种注解,获取这三种注解的元数据 -
ReflectionUtils.doWithLocalMethods():提取方法的注解的信息 -
do{} while (targetClass != null && targetClass != Object.class):循环从父类中解析,直到 Object 类
-
-
this.injectionMetadataCache.put(cacheKey, metadata):存入缓存
-
mbd.postProcessed = true:设置为 true,下次访问该逻辑不会再进入 -
-
earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName):单例、解决循环引用、是否在单例正在创建集合中if (earlySingletonExposure) { // 【放入三级缓存一个工厂对象,用来获取提前引用】 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); // lamda 表达式,用来获取提前引用,循环依赖部分详解该逻辑 } -
populateBean(beanName, mbd, instanceWrapper):**属性填充,依赖注入,整体逻辑是先处理标签再处理注解,填充至 pvs 中,最后通过 apply 方法最后完成属性依赖注入到 BeanWrapper **-
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)):实例化后的后置处理器,默认返回 true,可以自定义类继承 InstantiationAwareBeanPostProcessor 修改后置处理方法的返回值为 false,使 continueWithPropertyPopulation 为 false,会导致直接返回,不进行属性的注入 -
if (!continueWithPropertyPopulation):自定义方法返回值会造成该条件成立,逻辑为直接返回,不进行依赖注入 -
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null):处理依赖注入逻辑开始 -
mbd.getResolvedAutowireMode() == ?:根据 bean 标签配置的 autowire 判断是 BY_NAME 或者 BY_TYPEautowireByName(beanName, mbd, bw, newPvs):根据字段名称去获取依赖的 bean,还没注入,只是添加到 pvs-
propertyNames = unsatisfiedNonSimpleProperties(mbd, bw):bean 实例中有该字段和该字段的 setter 方法,但是在 bd 中没有 property 属性-
拿到配置的 property 信息和 bean 的所有字段信息
-
pd.getWriteMethod() != null:当前字段是否有 set 方法,配置类注入的方式需要 set 方法!isExcludedFromDependencyCheck(pd):当前字段类型是否在忽略自动注入的列表中!pvs.contains(pd.getName():当前字段不在 xml 或者其他方式的配置中,也就是 bd 中不存在对应的 property!BeanUtils.isSimpleProperty(pd.getPropertyType():是否是基本数据类型和内置的几种数据类型,基本数据类型不允许自动注入
-
-
if (containsBean(propertyName)):BeanFactory 中存在当前 property 的 bean 实例,说明找到对应的依赖数据 -
getBean(propertyName):拿到 propertyName 对应的 bean 实例 -
pvs.add(propertyName, bean):填充到 pvs 中 -
registerDependentBean(propertyName, beanName)):添加到两个依赖 Map(dependsOn)中
autowireByType(beanName, mbd, bw, newPvs):根据字段类型去查找依赖的 beandesc = new AutowireByTypeDependencyDescriptor(methodParam, eager):依赖描述信息resolveDependency(desc, beanName, autowiredBeanNames, converter):根据描述信息,查找依赖对象,容器中没有对应的实例但是有对应的 BD,会调用 getBean(Type) 获取对象
pvs = newPvs:newPvs 是处理了依赖数据后的 pvs,所以赋值给 pvs -
-
hasInstAwareBpps:表示当前是否有 InstantiationAwareBeanPostProcessors 的后置处理器(Autowired) -
pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName):@Autowired 注解的注入,这个传入的 pvs 对象,最后原封不动的返回,不会添加东西-
findAutowiringMetadata():包装着当前 bd 需要注入的注解信息集合,三种注解的元数据,直接缓存获取 -
InjectionMetadata.InjectedElement.inject():遍历注解信息解析后注入到 Bean,方法和字段的注入实现不同以字段注入为例:
-
value = resolveFieldValue(field, bean, beanName):处理字段属性值value = beanFactory.resolveDependency():解决依赖result = doResolveDependency():真正处理自动注入依赖的逻辑-
Object shortcut = descriptor.resolveShortcut(this):默认返回 null -
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor):获取 @Value 的值 -
converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor()):如果 value 不是 null,就直接进行类型转换返回数据 -
matchingBeans = findAutowireCandidates(beanName, type, descriptor):如果 value 是空说明字段是引用类型,获取 @Autowired 的 Bean// addCandidateEntry() → Object beanInstance = descriptor.resolveCandidate() public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory) throws BeansException { // 获取 bean return beanFactory.getBean(beanName); }
-
-
ReflectionUtils.makeAccessible(field):修改访问权限 -
field.set(bean, value):获取属性访问器为此 field 对象赋值
-
-
-
applyPropertyValues():将所有解析的 PropertyValues 的注入至 BeanWrapper 实例中(深拷贝)if (pvs.isEmpty()):注解 @Autowired 和 @Value 标注的信息在后置处理的逻辑注入完成,此处为空直接返回- 下面的逻辑进行 XML 配置的属性的注入,首先获取转换器进行数据转换,然后获取 WriteMethod (set) 方法进行反射调用,完成属性的注入
-
-
initializeBean(String,Object,RootBeanDefinition):初始化,分为配置文件和实现接口两种方式-
invokeAwareMethods(beanName, bean):根据 bean 是否实现 Aware 接口执行初始化的方法 -
wrappedBean = applyBeanPostProcessorsBeforeInitialization:初始化前的后置处理器,可以继承接口重写方法processor.postProcessBeforeInitialization():执行后置处理的方法,默认返回 bean 本身if (current == null) return result:重写方法返回 null,会造成后置处理的短路,直接返回
-
invokeInitMethods(beanName, wrappedBean, mbd):反射执行初始化方法-
isInitializingBean = (bean instanceof InitializingBean):初始化方法的定义有两种方式,一种是自定义类实现 InitializingBean 接口,另一种是配置文件配置 <bean id=“…” class=“…” init-method=“init”/ > -
isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet")):-
条件一:当前 bean 是不是实现了 InitializingBean
-
条件二:InitializingBean 接口中的方法 afterPropertiesSet,判断该方法是否是容器外管理的方法
-
-
if (mbd != null && bean.getClass() != NullBean.class):成立说明是配置文件的方式if(!(接口条件))表示如果通过接口实现了初始化方法的话,就不会在调用配置类中 init-method 定义的方法((InitializingBean) bean).afterPropertiesSet():调用方法invokeCustomInitMethod:执行自定义的方法initMethodName = mbd.getInitMethodName():获取方法名Method initMethod = ():根据方法名获取到 init-method 方法methodToInvoke = ClassUtils.getInterfaceMethodIfPossible(initMethod):将方法转成从接口层面获取ReflectionUtils.makeAccessible(methodToInvoke):访问权限设置成可访问methodToInvoke.invoke(bean):反射调用初始化方法,以当前 bean 为角度去调用
-
-
wrappedBean = applyBeanPostProcessorsAfterInitialization:初始化后的后置处理器-
AbstractAutoProxyCreator.postProcessAfterInitialization():如果 Bean 被子类标识为要代理的 bean,则使用配置的拦截器创建代理对象,AOP 部分详解 -
如果不存在循环依赖,创建动态代理 bean 在此处完成;否则真正的创建阶段是在属性填充时获取提前引用的阶段,循环依赖详解,源码分析:
// 该集合用来避免重复将某个 bean 生成代理对象, private final Map<Object, Object> earlyProxyReferences = new ConcurrentHashMap<>(16); public Object postProcessAfterInitialization(@Nullable Object bean,String bN){ if (bean != null) { // cacheKey 是 beanName 或者加上 & Object cacheKey = getCacheKey(bean.getClass(), beanName);y if (this.earlyProxyReferences.remove(cacheKey) != bean) { // 去提前代理引用池中寻找该key,不存在则创建代理 // 如果存在则证明被代理过,则判断是否是当前的 bean,不是则创建代理 return wrapIfNecessary(bean, bN, cacheKey); } } return bean; }
-
-
-
if (earlySingletonExposure):是否允许提前引用earlySingletonReference = getSingleton(beanName, false):从二级缓存获取实例,放入一级缓存是在 doGetBean 中的sharedInstance = getSingleton() 逻辑中,此时在 createBean 的逻辑还没有返回,所以一级缓存没有if (earlySingletonReference != null):当前 bean 实例从二级缓存中获取到了,说明产生了循环依赖,在属性填充阶段会提前调用三级缓存中的工厂生成 Bean 的代理对象(或原始实例),放入二级缓存中,然后使用原始 bean 继续执行初始化-
if (exposedObject == bean):初始化后的 bean == 创建的原始实例,条件成立的两种情况:当前的真实实例不需要被代理;当前实例存在循环依赖已经被提前代理过了,初始化时的后置处理器直接返回 bean 原实例exposedObject = earlySingletonReference:把代理后的 Bean 传给 exposedObject 用来返回,因为只有代理对象才封装了拦截器链,main 方法中用代理对象调用方法时会进行增强,代理是对原始对象的包装,所以这里返回的代理对象中含有完整的原实例(属性填充和初始化后的),是一个完整的代理对象,返回后外层方法会将当前 Bean 放入一级缓存 -
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)):是否有其他 bean 依赖当前 bean,执行到这里说明是不存在循环依赖、存在增强代理的逻辑,也就是正常的逻辑-
dependentBeans = getDependentBeans(beanName):取到依赖当前 bean 的其他 beanName -
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)):判断 dependentBean 是否创建完成if (!this.alreadyCreated.contains(beanName)):成立当前 bean 尚未创建完成,当前 bean 是依赖exposedObject 的 bean,返回 true
-
return false:创建完成返回 falseactualDependentBeans.add(dependentBean):创建完成的 dependentBean 加入该集合 -
if (!actualDependentBeans.isEmpty()):条件成立说明有依赖于当前 bean 的 bean 实例创建完成,但是当前的 bean 还没创建完成返回,依赖当前 bean 的外部 bean 持有的是不完整的 bean,所以需要报错
-
-
-
registerDisposableBeanIfNecessary:判断当前 bean 是否需要注册析构函数回调,当容器销毁时进行回调-
if (!mbd.isPrototype() && requiresDestruction(bean, mbd))-
如果是原型 prototype 不会注册析构回调,不会回调该函数,对象的回收由 JVM 的 GC 机制完成
-
requiresDestruction():
-
DisposableBeanAdapter.hasDestroyMethod(bean, mbd):bd 中定义了 DestroyMethod 返回 true -
hasDestructionAwareBeanPostProcessors():后处理器框架决定是否进行析构回调
-
-
-
registerDisposableBean():条件成立进入该方法,给当前单实例注册回调适配器,适配器内根据当前 bean 实例是继承接口(DisposableBean)还是自定义标签来判定具体调用哪个方法实现
-
-
this.disposableBeans.put(beanName, bean):向销毁集合添加实例
创建实例
AbstractAutowireCapableBeanFactory.createBeanInstance(beanName, RootBeanDefinition, Object[] args)
-
resolveBeanClass(mbd, beanName):确保 Bean 的 Class 真正的被加载 -
判断类的访问权限是不是 public,不是进入下一个判断,是否允许访问类的 non-public 的构造方法,不允许则报错
-
Supplier<?> instanceSupplier = mbd.getInstanceSupplier():获取创建实例的函数,可以自定义,没有进入下面的逻辑 -
if (mbd.getFactoryMethodName() != null):判断 bean 是否设置了 factory-method 属性,优先使用,设置了该属性进入 factory-method 方法创建实例
-
resolved = false:代表 bd 对应的构造信息是否已经解析成可以反射调用的构造方法 -
autowireNecessary = false:是否自动匹配构造方法 -
if(mbd.resolvedConstructorOrFactoryMethod != null):获取 bd 的构造信息转化成反射调用的 method 信息- method 为 null 则 resolved 和 autowireNecessary 都为默认值 false
autowireNecessary = mbd.constructorArgumentsResolved:构造方法有参数,设置为 true
-
bd 对应的构造信息解析完成,可以直接反射调用构造方法了:
-
return autowireConstructor(beanName, mbd, null, null):有参构造,根据参数匹配最优的构造器创建实例 -
return instantiateBean(beanName, mbd):无参构造方法通过反射创建实例-
SimpleInstantiationStrategy.instantiate():真正用来实例化的函数(无论如何都会走到这一步)-
if (!bd.hasMethodOverrides()):没有方法重写覆盖BeanUtils.instantiateClass(constructorToUse):调用Constructor.newInstance()实例化 -
instantiateWithMethodInjection(bd, beanName, owner):有方法重写采用 CGLIB 实例化
-
-
BeanWrapper bw = new BeanWrapperImpl(beanInstance):包装成 BeanWrapper 类型的对象 -
return bw:返回实例
-
-
-
ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName):@Autowired 注解,对应的后置处理器 AutowiredAnnotationBeanPostProcessor 逻辑-
配置了 lookup 的相关逻辑
-
this.candidateConstructorsCache.get(beanClass):从缓存中获取构造方法,第一次获取为 null,进入下面逻辑 -
rawCandidates = beanClass.getDeclaredConstructors():获取所有的构造器 -
Constructor<?> requiredConstructor = null:唯一的选项构造器,@Autowired(required = “true”) 时有值 -
for (Constructor<?> candidate : rawCandidates):遍历所有的构造器:ann = findAutowiredAnnotation(candidate):有三种注解中的一个会返回注解的属性-
遍历 this.autowiredAnnotationTypes 中的三种注解:
this.autowiredAnnotationTypes.add(Autowired.class);//!!!!!!!!!!!!!! this.autowiredAnnotationTypes.add(Value.class); this.autowiredAnnotationTypes.add(...ClassUtils.forName("javax.inject.Inject")); -
AnnotatedElementUtils.getMergedAnnotationAttributes(ao, type):获取注解的属性 -
if (attributes != null) return attributes:任意一个注解属性不为空就注解返回
if (ann == null):注解属性为空userClass = ClassUtils.getUserClass(beanClass):如果当前 beanClass 是代理对象,方法上就已经没有注解了,所以获取原始的用户类型重新获取该构造器上的注解属性(事务注解失效也是这个原理)
if (ann != null):注解属性不为空了-
required = determineRequiredStatus(ann):获取 required 属性的值!ann.containsKey(this.requiredParameterName) ||:判断属性是否包含 required,不包含进入后面逻辑this.requiredParameterValue == ann.getBoolean(this.requiredParameterName):获取属性值返回
-
if (required):代表注解 @Autowired(required = true)if (!candidates.isEmpty()):true 代表只能有一个构造方法,构造集合不是空代表可选的构造器不唯一,报错requiredConstructor = candidate:把构造器赋值给 requiredConstructor -
candidates.add(candidate):把当前构造方法添加至 candidates 集合
if(candidate.getParameterCount() == 0):当前遍历的构造器的参数为 0 代表没有参数,是默认构造器,赋值给 defaultConstructor -
-
candidateConstructors = candidates.toArray(new Constructor<?>[0]):将构造器转成数组返回
-
-
if(ctors != null):条件成立代表指定了构造方法数组mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR: 标签内 autowiremode 的属性值,默认是 no,AUTOWIRE_CONSTRUCTOR 代表选择最优的构造方法mbd.hasConstructorArgumentValues():bean 信息中是否配置了构造参数的值!ObjectUtils.isEmpty(args):getBean 时,指定了参数 arg -
return autowireConstructor(beanName, mbd, ctors, args):选择最优的构造器进行创建实例(复杂,不建议研究)-
beanFactory.initBeanWrapper(bw):向 BeanWrapper 中注册转换器,向工厂中注册属性编辑器 -
Constructor<?> constructorToUse = null:实例化反射构造器ArgumentsHolder argsHolderToUse:实例化时真正去用的参数,并持有对象- rawArguments 是转换前的参数,arguments 是类型转换完成的参数
Object[] argsToUse:参数实例化时使用的参数 -
Object[] argsToResolve:表示构造器参数做转换后的参数引用 -
if (constructorToUse != null && mbd.constructorArgumentsResolved):- 条件一成立说明当前 bd 生成的实例不是第一次,缓存中有解析好的构造器方法可以直接拿来反射调用
- 条件二成立说明构造器参数已经解析过了
-
argsToUse = resolvePreparedArguments():argsToResolve 不是完全解析好的,还需要继续解析 -
if (constructorToUse == null || argsToUse == null):条件成立说明缓存机制失败,进入构造器匹配逻辑 -
Constructor<?>[] candidates = chosenCtors:chosenCtors 只有在构造方法上有 autowaire 三种注解时才有数据 -
if (candidates == null):candidates 为空就根据 beanClass 是否允许访问非公开的方法来获取构造方法 -
if (candidates.length == 1 && explicitArgs == null && !mbd.hasConstructorArgumentValues()):默认无参bw.setBeanInstance(instantiate()):使用无参构造器反射调用,创建出实例对象,设置到 BeanWrapper 中去 -
boolean autowiring:需要选择最优的构造器 -
cargs = mbd.getConstructorArgumentValues():获取参数值resolvedValues = new ConstructorArgumentValues():获取已经解析后的构造器参数值final Map<Integer, ValueHolder> indexedArgumentValues:key 是 index, value 是值final List<ValueHolder> genericArgumentValues:没有 index 的值
minNrOfArgs = resolveConstructorArguments(..,resolvedValues):从 bd 中解析并获取构造器参数的个数valueResolver.resolveValueIfNecessary():将引用转换成真实的对象resolvedValueHolder.setSource(valueHolder):将对象填充至 ValueHolder 中resolvedValues.addIndexedArgumentValue():将参数值封装至 resolvedValues 中
-
AutowireUtils.sortConstructors(candidates):排序规则 public > 非公开的 > 参数多的 > 参数少的 -
int minTypeDiffWeight = Integer.MAX_VALUE:值越低说明构造器参数列表类型和构造参数的匹配度越高 -
Set<Constructor<?>> ambiguousConstructors:模棱两可的构造器,两个构造器匹配度相等时放入 -
for (Constructor<?> candidate : candidates):遍历筛选出 minTypeDiffWeight 最低的构造器 -
Class<?>[] paramTypes = candidate.getParameterTypes():获取当前处理的构造器的参数类型 -
if():candidates 是排过序的,当前筛选出来的构造器的优先级一定是优先于后面的 constructor -
if (paramTypes.length < minNrOfArgs):需求的小于给的,不匹配 -
int typeDiffWeight:获取匹配度mbd.isLenientConstructorResolution():true 表示 ambiguousConstructors 允许有数据,false 代表不允许有数据,有数据就报错(LenientConstructorResolution:宽松的构造函数解析)argsHolder.getTypeDifferenceWeight(paramTypes):选择参数转换前和转换后匹配度最低的,循环向父类中寻找该方法,直到寻找到 Obejct 类
-
if (typeDiffWeight < minTypeDiffWeight):条件成立说明当前循环处理的构造器更优 -
else if (constructorToUse != null && typeDiffWeight == minTypeDiffWeight):当前处理的构造器的计算出来的 DiffWeight 与上一次筛选出来的最优构造器的值一致,说明有模棱两可的情况 -
if (constructorToUse == null):未找到可以使用的构造器,报错 -
else if (ambiguousConstructors != null && !mbd.isLenientConstructorResolution()):模棱两可有数据,LenientConstructorResolution == false,所以报错 -
argsHolderToUse.storeCache(mbd, constructorToUse):匹配成功,进行缓存,方便后来者使用该 bd 实例化 -
bw.setBeanInstance(instantiate(beanName, mbd, constructorToUse, argsToUse)):匹配成功调用 instantiate 创建出实例对象,设置到 BeanWrapper 中去
-
-
return instantiateBean(beanName, mbd):默认走到这里
循环依赖
循环引用
循环依赖:是一个或多个对象实例之间存在直接或间接的依赖关系,这种依赖关系构成一个环形调用
Spring 循环依赖有四种:
- DependsOn 依赖加载【无法解决】(两种 Map)
- 原型模式 Prototype 循环依赖【无法解决】(正在创建集合)
- 单例 Bean 循环依赖:构造参数产生依赖【无法解决】(正在创建集合,getSingleton() 逻辑中)
- 单例 Bean 循环依赖:setter 产生依赖【可以解决】
解决循环依赖:提前引用,提前暴露创建中的 Bean
- Spring 先实例化 A,拿到 A 的构造方法反射创建出来 A 的早期实例对象,这个对象被包装成 ObjectFactory 对象,放入三级缓存
- 处理 A 的依赖数据,检查发现 A 依赖 B 对象,所以 Spring 就会去根据 B 类型到容器中去 getBean(B),这里产生递归
- 拿到 B 的构造方法,进行反射创建出来 B 的早期实例对象,也会把 B 包装成 ObjectFactory 对象,放到三级缓存,处理 B 的依赖数据,检查发现 B 依赖了 A 对象,然后 Spring 就会去根据 A 类型到容器中去 getBean(A.class)
- 这时从三级缓存中获取到 A 的早期对象进入属性填充
循环依赖的三级缓存:
//一级缓存:存放所有初始化完成单实例 bean,单例池,key是beanName,value是对应的单实例对象引用
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
//二级缓存:存放实例化未进行初始化的 Bean,提前引用池
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/** Cache of singleton factories: bean name to ObjectFactory. 3*/
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
-
为什么需要三级缓存?
- 循环依赖解决需要提前引用动态代理对象,AOP 动态代理是在 Bean 初始化后的后置处理中进行,这时的 bean 已经是成品对象。因为需要提前进行动态代理,三级缓存的 ObjectFactory 提前产生需要代理的对象,把提前引用放入二级缓存
- 如果只有二级缓存,提前引用就直接放入了一级缓存,然后 Bean 初始化完成后又会放入一级缓存,产生数据覆盖,导致提前引用的对象和一级缓存中的并不是同一个对象
- 一级缓存只能存放完整的单实例,为了保证 Bean 的生命周期不被破坏,不能将未初始化的 Bean 暴露到一级缓存
- 若存在循环依赖,后置处理不创建代理对象,真正创建代理对象的过程是在 getBean(B) 的阶段中
-
三级缓存一定会创建提前引用吗?
- 出现循环依赖就会去三级缓存获取提前引用,不出现就不会,走正常的逻辑,创建完成直接放入一级缓存
- 存在循环依赖,就创建代理对象放入二级缓存,如果没有增强方法就返回 createBeanInstance 创建的实例,因为 addSingletonFactory 参数中传入了实例化的 Bean,在 singletonFactory.getObject() 中返回给 singletonObject,所以存在循环依赖就一定会使用工厂,但是不一定创建的是代理对象,不需要增强就是原始对象
-
wrapIfNecessary 一定创建代理对象吗?(AOP 动态代理部分有源码解析)
- 存在增强器会创建动态代理,不需要增强就不需要创建动态代理对象
- 存在循环依赖会提前增强,初始化后不需要增强
-
什么时候将 Bean 的引用提前暴露给第三级缓存的 ObjectFactory 持有?
-
实例化之后,依赖注入之前
createBeanInstance -> addSingletonFactory -> populateBean
-
源码解析
假如 A 依赖 B,B 依赖 A
-
当 A 创建实例后填充属性前,执行:
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))// 添加给定的单例工厂以构建指定的单例 protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) { Assert.notNull(singletonFactory, "Singleton factory must not be null"); synchronized (this.singletonObjects) { // 单例池包含该Bean说明已经创建完成,不需要循环依赖 if (!this.singletonObjects.containsKey(beanName)) { //加入三级缓存 this.singletonFactories.put(beanName,singletonFactory); this.earlySingletonObjects.remove(beanName); // 从二级缓存移除,因为三个Map中都是一个对象,不能同时存在! this.registeredSingletons.add(beanName); } } } -
填充属性时 A 依赖 B,这时需要 getBean(B),也会把 B 的工厂放入三级缓存,接着 B 填充属性时发现依赖 A,去进行**第一次 ** getSingleton(A)
public Object getSingleton(String beanName) { return getSingleton(beanName, true);//为true代表允许拿到早期引用。 } protected Object getSingleton(String beanName, boolean allowEarlyReference) { // 在一级缓存中获取 beanName 对应的单实例对象。 Object singletonObject = this.singletonObjects.get(beanName); // 单实例确实尚未创建;单实例正在创建,发生了循环依赖 if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this.singletonObjects) { // 从二级缓存获取 singletonObject = this.earlySingletonObjects.get(beanName); // 二级缓存不存在,并且允许获取早期实例对象,去三级缓存查看 if (singletonObject == null && allowEarlyReference) { ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { // 从三级缓存获取工厂对象,并得到 bean 的提前引用 singletonObject = singletonFactory.getObject(); // 【缓存升级】,放入二级缓存,提前引用池 this.earlySingletonObjects.put(beanName, singletonObject); // 从三级缓存移除该对象 this.singletonFactories.remove(beanName); } } } } return singletonObject; } -
从三级缓存获取 A 的 Bean:
singletonFactory.getObject(),调用了 lambda 表达式的 getEarlyBeanReference 方法:public Object getEarlyBeanReference(Object bean, String beanName) { Object cacheKey = getCacheKey(bean.getClass(), beanName); // 【向提前引用代理池 earlyProxyReferences 中添加该 Bean,防止对象被重新代理】 this.earlyProxyReferences.put(cacheKey, bean); // 创建代理对象,createProxy return wrapIfNecessary(bean, beanName, cacheKey); } -
B 填充了 A 的提前引用后会继续初始化直到完成,返回原始 A 的逻辑继续执行
AOP
注解原理
@EnableAspectJAutoProxy:AOP 注解驱动,给容器中导入 AspectJAutoProxyRegistrar
@Import(AspectJAutoProxyRegistrar.class)
public @interface EnableAspectJAutoProxy {
// 是否强制使用 CGLIB 创建代理对象
// 配置文件方式:<aop:aspectj-autoproxy proxy-target-class="true"/>
boolean proxyTargetClass() default false;
// 将当前代理对象暴露到上下文内,方便代理对象内部的真实对象拿到代理对象
// 配置文件方式:<aop:aspectj-autoproxy expose-proxy="true"/>
boolean exposeProxy() default false;
}
AspectJAutoProxyRegistrar 在用来向容器中注册 AnnotationAwareAspectJAutoProxyCreator,以 BeanDefiantion 形式存在,在容器初始化时加载。AnnotationAwareAspectJAutoProxyCreator 间接实现了 InstantiationAwareBeanPostProcessor,Order 接口,该类会在 Bean 的实例化和初始化的前后起作用
工作流程:创建 IOC 容器,调用 refresh() 刷新容器,registerBeanPostProcessors(beanFactory) 阶段,通过 getBean() 创建 AnnotationAwareAspectJAutoProxyCreator 对象,在生命周期的初始化方法中执行回调 initBeanFactory() 方法初始化注册三个工具类:BeanFactoryAdvisorRetrievalHelperAdapter、ReflectiveAspectJAdvisorFactory、BeanFactoryAspectJAdvisorsBuilderAdapter
后置处理
Bean 初始化完成的执行后置处理器的方法:
public Object postProcessAfterInitialization(@Nullable Object bean,String bN){
if (bean != null) {
// cacheKey 是 【beanName 或者加上 & 的 beanName】
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
// 去提前代理引用池中寻找该 key,不存在则创建代理
// 如果存在则证明被代理过,则判断是否是当前的 bean,不是则创建代理
return wrapIfNecessary(bean, bN, cacheKey);
}
}
return bean;
}
AbstractAutoProxyCreator.wrapIfNecessary():根据通知创建动态代理,没有通知直接返回原实例
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 条件一般不成立,很少使用 TargetSourceCreator 去创建对象 BeforeInstantiation 阶段,doCreateBean 之前的阶段
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
// advisedBeans 集合保存的是 bean 是否被增强过了
// 条件成立说明当前 beanName 对应的实例不需要被增强处理,判断是在 BeforeInstantiation 阶段做的
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
// 条件一:判断当前 bean 类型是否是基础框架类型,这个类的实例不能被增强
// 条件二:shouldSkip 判断当前 beanName 是否是 .ORIGINAL 结尾,如果是就跳过增强逻辑,直接返回
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// 【查找适合当前 bean 实例的增强方法】(下一节详解)
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
// 条件成立说明上面方法查询到适合当前class的通知
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 根据查询到的增强创建代理对象(下一节详解)
// 参数一:目标对象
// 参数二:beanName
// 参数三:匹配当前目标对象 clazz 的 Advisor 数据
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
// 保存代理对象类型
this.proxyTypes.put(cacheKey, proxy.getClass());
// 返回代理对象
return proxy;
}
// 执行到这里说明没有查到通知,当前 bean 不需要增强
this.advisedBeans.put(cacheKey, Boolean.FALSE);
// 【返回原始的 bean 实例】
return bean;
}
获取通知
AbstractAdvisorAutoProxyCreator.getAdvicesAndAdvisorsForBean():查找适合当前类实例的增强,并进行排序
protected Object[] getAdvicesAndAdvisorsForBean(Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
// 查询适合当前类型的增强通知
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
// 增强为空直接返回 null,不需要创建代理
return DO_NOT_PROXY;
}
// 不是空,转成数组返回
return advisors.toArray();
}
AbstractAdvisorAutoProxyCreator.findEligibleAdvisors():
-
candidateAdvisors = findCandidateAdvisors():获取当前容器内可以使用(所有)的 advisor,调用的是 AnnotationAwareAspectJAutoProxyCreator 类的方法,每个方法对应一个 Advisor-
advisors = super.findCandidateAdvisors():查询出 XML 配置的所有 Advisor 类型advisorNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors():通过 BF 查询出来 BD 配置的 class 中 是 Advisor 子类的 BeanNameadvisors.add():使用 Spring 容器获取当前这个 Advisor 类型的实例
-
advisors.addAll(....buildAspectJAdvisors()):获取所有添加 @Aspect 注解类中的 AdvisorbuildAspectJAdvisors():构建的方法,把 Advice 封装成 Advisor-
beanNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(this.beanFactory, Object.class, true, false):获取出容器内 Object 所有的 beanName,就是全部的 -
for (String beanName : beanNames):遍历所有的 beanName,判断每个 beanName 对应的 Class 是否是 Aspect 类型,就是加了 @Aspect 注解的类-
factory = new BeanFactoryAspectInstanceFactory(this.beanFactory, beanName):使用工厂模式管理 Aspect 的元数据,关联的真实 @Aspect 注解的实例对象 -
classAdvisors = this.advisorFactory.getAdvisors(factory):添加了 @Aspect 注解的类的通知信息-
aspectClass:@Aspect 标签的类的 class
-
for (Method method : getAdvisorMethods(aspectClass)):遍历不包括 @Pointcut 注解的方法Advisor advisor = getAdvisor(method, lazySingletonAspectInstanceFactory, advisors.size(), aspectName):将当前 method 包装成 Advisor 数据-
AspectJExpressionPointcut expressionPointcut = getPointcut():获取切点表达式 -
return new InstantiationModelAwarePointcutAdvisorImpl():把 method 中 Advice 包装成 Advisor,Spring 中每个 Advisor 内部一定是持有一个 Advice 的,Advice 内部最重要的数据是当前 method 和aspectInstanceFactory,工厂用来获取实例this.instantiatedAdvice = instantiateAdvice(this.declaredPointcut):实例化 Advice 对象,逻辑是获取注解信息,根据注解的不同生成对应的 Advice 对象
-
-
-
advisors.addAll(classAdvisors):保存通过 @Aspect 注解定义的 Advisor 数据
-
-
this.aspectBeanNames = aspectNames:将所有 @Aspect 注解 beanName 缓存起来,表示提取 Advisor 工作完成 -
return advisors:返回 Advisor 列表
-
-
-
eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, ...):选出匹配当前类的增强-
if (candidateAdvisors.isEmpty()):条件成立说明当前 Spring 没有可以操作的 Advisor -
List<Advisor> eligibleAdvisors = new ArrayList<>():存放匹配当前 beanClass 的 Advisors 信息 -
for (Advisor candidate : candidateAdvisors):遍历所有的 Advisorif (canApply(candidate, clazz, hasIntroductions)):判断遍历的 advisor 是否匹配当前的 class,匹配就加入集合-
if (advisor instanceof PointcutAdvisor):创建的 advisor 是 InstantiationModelAwarePointcutAdvisorImpl 类型PointcutAdvisor pca = (PointcutAdvisor) advisor:封装当前 Advisorreturn canApply(pca.getPointcut(), targetClass, hasIntroductions):重载该方法if (!pc.getClassFilter().matches(targetClass)):类不匹配 Pointcut 表达式,直接返回 falsemethodMatcher = pc.getMethodMatcher():获取 Pointcut 方法匹配器,类匹配进行类中方法的匹配Set<Class<?>> classes:保存目标对象 class 和目标对象父类超类的接口和自身实现的接口if (!Proxy.isProxyClass(targetClass)):判断当前实例是不是代理类,确保 class 内存储的数据包括目标对象的class 而不是代理类的 classfor (Class<?> clazz : classes):检查目标 class 和上级接口的所有方法,查看是否会被方法匹配器匹配,如果有一个方法匹配成功,就说明目标对象 AOP 代理需要增强specificMethod = AopUtils.getMostSpecificMethod(method, targetClass):方法可能是接口的,判断当前类有没有该方法return (specificMethod != method && matchesMethod(specificMethod)):类和方法的匹配,不包括参数
-
-
-
extendAdvisors(eligibleAdvisors):在 eligibleAdvisors 列表的索引 0 的位置添加 DefaultPointcutAdvisor,封装了 ExposeInvocationInterceptor 拦截器 -
eligibleAdvisors = sortAdvisors(eligibleAdvisors):对拦截器进行排序,数值越小优先级越高,高的排在前面- 实现 Ordered 或 PriorityOrdered 接口,PriorityOrdered 的级别要优先于 Ordered,使用 OrderComparator 比较器
- 使用 @Order(Spring 规范)或 @Priority(JDK 规范)注解,使用 AnnotationAwareOrderComparator 比较器
- ExposeInvocationInterceptor 实现了 PriorityOrdered ,所以总是排在第一位,MethodBeforeAdviceInterceptor 没实现任何接口,所以优先级最低,排在最后
-
return eligibleAdvisors:返回拦截器链
创建代理
AbstractAutoProxyCreator.createProxy():根据增强方法创建代理对象
-
ProxyFactory proxyFactory = new ProxyFactory():无参构造 ProxyFactory,此处讲解一下两种有参构造方法:-
public ProxyFactory(Object target):
public ProxyFactory(Object target) { // 将目标对象封装成 SingletonTargetSource 保存到父类的字段中 setTarget(target); // 获取目标对象 class 所有接口保存到 AdvisedSupport 中的 interfaces 集合中 setInterfaces(ClassUtils.getAllInterfaces(target)); }ClassUtils.getAllInterfaces(target) 底层调用 getAllInterfacesForClassAsSet(java.lang.Class<?>, java.lang.ClassLoader):
if (clazz.isInterface() && isVisible(clazz, classLoader)):- 条件一:判断当前目标对象是接口
- 条件二:检查给定的类在给定的 ClassLoader 中是否可见
Class<?>[] ifcs = current.getInterfaces():拿到自己实现的接口,拿不到接口实现的接口current = current.getSuperclass():递归寻找父类的接口,去获取父类实现的接口
-
public ProxyFactory(Class<?> proxyInterface, Interceptor interceptor):
public ProxyFactory(Class<?> proxyInterface, Interceptor interceptor) { // 添加一个代理的接口 addInterface(proxyInterface); // 添加通知,底层调用 addAdvisor addAdvice(interceptor); }addAdvisor(pos, new DefaultPointcutAdvisor(advice)):Spring 中 Advice 对应的接口就是 Advisor,Spring 使用 Advisor 包装 Advice 实例
-
-
proxyFactory.copyFrom(this):填充一些信息到 proxyFactory -
if (!proxyFactory.isProxyTargetClass()):条件成立说明 proxyTargetClass 为 false(默认),两种配置方法:<aop:aspectj-autoproxy proxy-target-class="true"/>:强制使用 CGLIB@EnableAspectJAutoProxy(proxyTargetClass = true)
if (shouldProxyTargetClass(beanClass, beanName)):如果 bd 内有 preserveTargetClass = true ,那么这个 bd 对应的 class 创建代理时必须使用 CGLIB,条件成立设置 proxyTargetClass 为 trueevaluateProxyInterfaces(beanClass, proxyFactory):根据目标类判定是否可以使用 JDK 动态代理targetInterfaces = ClassUtils.getAllInterfacesForClass():获取当前目标对象 class 和父类的全部实现接口boolean hasReasonableProxyInterface = false:实现的接口中是否有一个合理的接口if (!isConfigurationCallbackInterface(ifc) && !isInternalLanguageInterface(ifc) && ifc.getMethods().length > 0):遍历所有的接口,如果有任意一个接口满足条件,设置 hRPI 变量为 true- 条件一:判断当前接口是否是 Spring 生命周期内会回调的接口
- 条件二:接口不能是 GroovyObject、Factory、MockAccess 类型的
- 条件三:找到一个可以使用的被代理的接口
if (hasReasonableProxyInterface):有合理的接口,将这些接口设置到 proxyFactory 内proxyFactory.setProxyTargetClass(true):没有合理的代理接口,强制使用 CGLIB 创建对象
-
advisors = buildAdvisors(beanName, specificInterceptors):匹配目标对象 clazz 的 Advisors,填充至 ProxyFactory -
proxyFactory.setPreFiltered(true):设置为 true 表示传递给 proxyFactory 的 Advisors 信息做过基础类和方法的匹配 -
return proxyFactory.getProxy(getProxyClassLoader()):创建代理对象public Object getProxy() { return createAopProxy().getProxy(); }DefaultAopProxyFactory.createAopProxy(AdvisedSupport config):参数是一个配置对象,保存着创建代理需要的生产资料,会加锁创建,保证线程安全
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException { // 条件二为 true 代表强制使用 CGLIB 动态代理 if (config.isOptimize() || config.isProxyTargetClass() || // 条件三:被代理对象没有实现任何接口或者只实现了 SpringProxy 接口,只能使用 CGLIB 动态代理 hasNoUserSuppliedProxyInterfaces(config)) { Class<?> targetClass = config.getTargetClass(); if (targetClass == null) { throw new AopConfigException(""); } // 条件成立说明 target 【是接口或者是已经被代理过的类型】,只能使用 JDK 动态代理 if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) { return new JdkDynamicAopProxy(config); // 使用 JDK 动态代理 } return new ObjenesisCglibAopProxy(config); // 使用 CGLIB 动态代理 } else { return new JdkDynamicAopProxy(config); // 【有接口的情况下只能使用 JDK 动态代理】 } }JdkDynamicAopProxy.getProxy(java.lang.ClassLoader):获取 JDK 的代理对象
public JdkDynamicAopProxy(AdvisedSupport config) throws AopConfigException { // 配置类封装到 JdkDynamicAopProxy.advised 属性中 this.advised = config; } public Object getProxy(@Nullable ClassLoader classLoader) { // 获取需要代理的接口数组 Class<?>[] proxiedInterfaces = AopProxyUtils.completeProxiedInterfaces(this.advised, true); // 查找当前所有的需要代理的接口,看是否有 equals 方法和 hashcode 方法,如果有就做一个标记 findDefinedEqualsAndHashCodeMethods(proxiedInterfaces); // 该方法最终返回一个代理类对象 return Proxy.newProxyInstance(classLoader, proxiedInterfaces, this); // classLoader:类加载器 proxiedInterfaces:生成的代理类,需要实现的接口集合 // this JdkDynamicAopProxy 实现了 InvocationHandler }AopProxyUtils.completeProxiedInterfaces(this.advised, true):获取代理的接口数组,并添加 SpringProxy 接口
-
specifiedInterfaces = advised.getProxiedInterfaces():从 ProxyFactory 中拿到所有的 target 提取出来的接口if (specifiedInterfaces.length == 0):如果没有实现接口,检查当前 target 是不是接口或者已经是代理类,封装到 ProxyFactory 的 interfaces 集合中
-
addSpringProxy = !advised.isInterfaceProxied(SpringProxy.class):判断目标对象所有接口中是否有 SpringProxy 接口,没有的话需要添加,这个接口标识这个代理类型是 Spring 管理的addAdvised = !advised.isOpaque() && !advised.isInterfaceProxied(Advised.class):判断目标对象的所有接口,是否已经有 Advised 接口addDecoratingProxy = (decoratingProxy && !advised.isInterfaceProxied(DecoratingProxy.class)):判断目标对象的所有接口,是否已经有 DecoratingProxy 接口int nonUserIfcCount = 0:非用户自定义的接口数量,接下来要添加上面的三个接口了proxiedInterfaces = new Class<?>[specifiedInterfaces.length + nonUserIfcCount]:创建一个新的 class 数组,长度是原目标对象提取出来的接口数量和 Spring 追加的数量,然后进行 System.arraycopy 拷贝到新数组中int index = specifiedInterfaces.length:获取原目标对象提取出来的接口数量,当作 indexif(addSpringProxy):根据上面三个布尔值把接口添加到新数组中return proxiedInterfaces:返回追加后的接口集合
JdkDynamicAopProxy.findDefinedEqualsAndHashCodeMethods():查找在任何定义在接口中的 equals 和 hashCode 方法
for (Class<?> proxiedInterface : proxiedInterfaces):遍历所有的接口-
Method[] methods = proxiedInterface.getDeclaredMethods():获取接口中的所有方法 -
for (Method method : methods):遍历所有的方法if (AopUtils.isEqualsMethod(method)):当前方法是 equals 方法,把 equalsDefined 置为 trueif (AopUtils.isHashCodeMethod(method)):当前方法是 hashCode 方法,把 hashCodeDefined 置为 true
-
if (this.equalsDefined && this.hashCodeDefined):如果有一个接口中有这两种方法,直接返回
-
-
方法增强
main() 函数中调用用户方法,会进入代理对象的 invoke 方法
JdkDynamicAopProxy 类中的 invoke 方法是真正执行代理方法
// proxy:代理对象,method:目标对象的方法,args:目标对象方法对应的参数
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object oldProxy = null;
boolean setProxyContext = false;
// advised 就是初始化 JdkDynamicAopProxy 对象时传入的变量
TargetSource targetSource = this.advised.targetSource;
Object target = null;
try {
// 条件成立说明代理类实现的接口没有定义 equals 方法,并且当前 method 调用 equals 方法,
// 就调用 JdkDynamicAopProxy 提供的 equals 方法
if (!this.equalsDefined && AopUtils.isEqualsMethod(method)) {
return equals(args[0]);
} //.....
Object retVal;
// 需不需要暴露当前代理对象到 AOP 上下文内
if (this.advised.exposeProxy) {
// 【把代理对象设置到上下文环境】
oldProxy = AopContext.setCurrentProxy(proxy);
setProxyContext = true;
}
// 根据 targetSource 获取真正的代理对象
target = targetSource.getTarget();
Class<?> targetClass = (target != null ? target.getClass() : null);
// 查找【适合该方法的增强】,首先从缓存中查找,查找不到进入主方法【下文详解】
List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
// 拦截器链是空,说明当前 method 不需要被增强
if (chain.isEmpty()) {
Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
retVal = AopUtils.invokeJoinpointUsingReflection(target, method, argsToUse);
}
else {
// 有匹配当前 method 的方法拦截器,要做增强处理,把方法信息封装到方法调用器里
MethodInvocation invocation =
new ReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
// 【拦截器链驱动方法,核心】
retVal = invocation.proceed();
}
Class<?> returnType = method.getReturnType();
if (retVal != null && retVal == target &&
returnType != Object.class && returnType.isInstance(proxy) &&
!RawTargetAccess.class.isAssignableFrom(method.getDeclaringClass())) {
// 如果目标方法返回目标对象,这里做个普通替换返回代理对象
retVal = proxy;
}
// 返回执行的结果
return retVal;
}
finally {
if (target != null && !targetSource.isStatic()) {
targetSource.releaseTarget(target);
}
// 如果允许了提前暴露,这里需要设置为初始状态
if (setProxyContext) {
// 当前代理对象已经完成工作,【把原始对象设置回上下文】
AopContext.setCurrentProxy(oldProxy);
}
}
}
this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass):查找适合该方法的增强,首先从缓存中查找,获取通知时是从全部增强中获取适合当前类的,这里是从当前类的中获取适合当前方法的增强
-
AdvisorAdapterRegistry registry = GlobalAdvisorAdapterRegistry.getInstance():向容器注册适配器,可以将非 Advisor 类型的增强,包装成为 Advisor,将 Advisor 类型的增强提取出来对应的 MethodInterceptor-
instance = new DefaultAdvisorAdapterRegistry():该对象向容器中注册了 MethodBeforeAdviceAdapter、AfterReturningAdviceAdapter、ThrowsAdviceAdapter 三个适配器 -
Advisor 中持有 Advice 对象
public interface Advisor { Advice getAdvice(); }
-
-
advisors = config.getAdvisors():获取 ProxyFactory 内部持有的增强信息 -
interceptorList = new ArrayList<>(advisors.length):拦截器列表有 5 个,1 个 ExposeInvocation和 4 个增强器 -
actualClass = (targetClass != null ? targetClass : method.getDeclaringClass()):真实的目标对象类型 -
Boolean hasIntroductions = null:引介增强,不关心 -
for (Advisor advisor : advisors):遍历所有的 advisor 增强 -
if (advisor instanceof PointcutAdvisor):条件成立说明当前 Advisor 是包含切点信息的,进入匹配逻辑pointcutAdvisor = (PointcutAdvisor) advisor:转成可以获取到切点信息的接口if(config.isPreFiltered() || pointcutAdvisor.getPointcut().getClassFilter().matches(actualClass)):当前代理被预处理,或者当前被代理的 class 对象匹配当前 Advisor 成功,只是 class 匹配成功-
mm = pointcutAdvisor.getPointcut().getMethodMatcher():获取切点的方法匹配器,不考虑引介增强 -
match = mm.matches(method, actualClass):静态匹配成功返回 true,只关注于处理类及其方法,不考虑参数 -
if (match):如果静态切点检查是匹配的,在运行的时候才进行动态切点检查,会考虑参数匹配(代表传入了参数)。如果静态匹配失败,直接不需要进行参数匹配,提高了工作效率interceptors = registry.getInterceptors(advisor):提取出当前 advisor 内持有的 advice 信息-
Advice advice = advisor.getAdvice():获取增强方法 -
if (advice instanceof MethodInterceptor):当前 advice 是 MethodInterceptor 直接加入集合 -
for (AdvisorAdapter adapter : this.adapters):遍历三个适配器进行匹配(初始化时创建的),匹配成功创建对应的拦截器返回,以 MethodBeforeAdviceAdapter 为例if (adapter.supportsAdvice(advice)):判断当前 advice 是否是对应的 MethodBeforeAdviceinterceptors.add(adapter.getInterceptor(advisor)):条件成立就往拦截器链中添加 advisoradvice = (MethodBeforeAdvice) advisor.getAdvice():获取增强方法return new MethodBeforeAdviceInterceptor(advice):封装成 MethodBeforeAdviceInterceptor 返回
interceptorList.add(new InterceptorAndDynamicMethodMatcher(interceptor, mm)):向拦截器链添加动态匹配器interceptorList.addAll(Arrays.asList(interceptors)):将当前 advisor 内部的方法拦截器追加到 interceptorList -
-
-
interceptors = registry.getInterceptors(advisor):进入 else 的逻辑,说明当前 Advisor 匹配全部 class 的全部 method,全部加入到 interceptorList -
return interceptorList:返回 method 方法的拦截器链
retVal = invocation.proceed():拦截器链驱动方法
-
if (this.currentInterceptorIndex == this.interceptorsAndDynamicMethodMatchers.size() - 1):条件成立说明方法拦截器全部都已经调用过了(index 从 - 1 开始累加),接下来需要执行目标对象的目标方法return invokeJoinpoint():调用连接点(目标)方法 -
this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex):获取下一个方法拦截器 -
if (interceptorOrInterceptionAdvice instanceof InterceptorAndDynamicMethodMatcher):需要运行时匹配if (dm.methodMatcher.matches(this.method, targetClass, this.arguments)):判断是否匹配成功return dm.interceptor.invoke(this):匹配成功,执行方法return proceed():匹配失败跳过当前拦截器
-
return ((MethodInterceptor) interceptorOrInterceptionAdvice).invoke(this):一般方法拦截器都会执行到该方法,此方法内继续执行 proceed() 完成责任链的驱动,直到最后一个 MethodBeforeAdviceInterceptor 调用前置通知,然后调用 mi.proceed(),发现是最后一个拦截器就直接执行连接点(目标方法),return 到上一个拦截器的 mi.proceed() 处,依次返回到责任链的上一个拦截器执行通知方法
图示先从上往下建立链,然后从下往上依次执行,责任链模式
-
正常执行:(环绕通知)→ 前置通知 → 目标方法 → 后置通知 → 返回通知
-
出现异常:(环绕通知)→ 前置通知 → 目标方法 → 后置通知 → 异常通知
-
MethodBeforeAdviceInterceptor 源码:
public Object invoke(MethodInvocation mi) throws Throwable { // 先执行通知方法,再驱动责任链 this.advice.before(mi.getMethod(), mi.getArguments(), mi.getThis()); // 开始驱动目标方法执行,执行完后返回到这,然后继续向上层返回 return mi.proceed(); }AfterReturningAdviceInterceptor 源码:没有任何异常处理机制,直接抛给上层
public Object invoke(MethodInvocation mi) throws Throwable { // 先驱动责任链,再执行通知方法 Object retVal = mi.proceed(); this.advice.afterReturning(retVal, mi.getMethod(), mi.getArguments(), mi.getThis()); return retVal; }AspectJAfterThrowingAdvice 执行异常处理:
public Object invoke(MethodInvocation mi) throws Throwable { try { // 默认直接驱动责任链 return mi.proceed(); } catch (Throwable ex) { // 出现错误才执行该方法 if (shouldInvokeOnThrowing(ex)) { invokeAdviceMethod(getJoinPointMatch(), null, ex); } throw ex; } }
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h3ZS9ckX-1686861880275)(https://seazean.oss-cn-beijing.aliyuncs.com/img/Frame/Spring-AOP动态代理执行方法.png)]
参考视频:https://www.bilibili.com/video/BV1gW411W7wy
事务
解析方法
标签解析
<tx:annotation-driven transaction-manager="txManager"/>
容器启动时会根据注解注册对应的解析器:
public class TxNamespaceHandler extends NamespaceHandlerSupport {
public void init() {
registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());
// 注册解析器
registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser());
registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser());
}
}
protected final void registerBeanDefinitionParser(String elementName, BeanDefinitionParser parser) {
this.parsers.put(elementName, parser);
}
获取对应的解析器 NamespaceHandlerSupport#findParserForElement:
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
String localName = parserContext.getDelegate().getLocalName(element);
// 获取对应的解析器
BeanDefinitionParser parser = this.parsers.get(localName);
// ...
return parser;
}
调用解析器的方法对 XML 文件进行解析:
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 向Spring容器注册了一个 BD -> TransactionalEventListenerFactory.class
registerTransactionalEventListenerFactory(parserContext);
String mode = element.getAttribute("mode");
if ("aspectj".equals(mode)) {
// mode="aspectj"
registerTransactionAspect(element, parserContext);
if (ClassUtils.isPresent("javax.transaction.Transactional", getClass().getClassLoader())) {
registerJtaTransactionAspect(element, parserContext);
}
}
else {
// mode="proxy",默认逻辑,不配置 mode 时
// 用来向容器中注入一些 BeanDefinition,包括事务增强器、事务拦截器、注解解析器
AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);
}
return null;
}
注解解析
@EnableTransactionManagement 导入 TransactionManagementConfigurationSelector,该类给 Spring 容器中两个组件:
protected String[] selectImports(AdviceMode adviceMode) {
switch (adviceMode) {
// 导入 AutoProxyRegistrar 和 ProxyTransactionManagementConfiguration(默认)
case PROXY:
return new String[] {AutoProxyRegistrar.class.getName(),
ProxyTransactionManagementConfiguration.class.getName()};
// 导入 AspectJTransactionManagementConfiguration(与声明式事务无关)
case ASPECTJ:
return new String[] {determineTransactionAspectClass()};
default:
return null;
}
}
AutoProxyRegistrar:给容器中注册 InfrastructureAdvisorAutoProxyCreator,利用后置处理器机制拦截 bean 以后包装并返回一个代理对象,代理对象中保存所有的拦截器,利用拦截器的链式机制依次进入每一个拦截器中进行拦截执行(就是 AOP 原理)
ProxyTransactionManagementConfiguration:是一个 Spring 的事务配置类,注册了三个 Bean:
- BeanFactoryTransactionAttributeSourceAdvisor:事务驱动,利用注解 @Bean 把该类注入到容器中,该增强器有两个字段:
- TransactionAttributeSource:解析事务注解的相关信息,真实类型是 AnnotationTransactionAttributeSource,构造方法中注册了三个注解解析器,解析 Spring、JTA、Ejb3 三种类型的事务注解
- TransactionInterceptor:事务拦截器,代理对象执行拦截器方法时,调用 TransactionInterceptor 的 invoke 方法,底层调用TransactionAspectSupport.invokeWithinTransaction(),通过 PlatformTransactionManager 控制着事务的提交和回滚,所以事务的底层原理就是通过 AOP 动态织入,进行事务开启和提交
注解解析器 SpringTransactionAnnotationParser 解析 @Transactional 注解:
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
// 从注解信息中获取传播行为
Propagation propagation = attributes.getEnum("propagation");
rbta.setPropagationBehavior(propagation.value());
// 获取隔离界别
Isolation isolation = attributes.getEnum("isolation");
rbta.setIsolationLevel(isolation.value());
rbta.setTimeout(attributes.getNumber("timeout").intValue());
// 从注解信息中获取 readOnly 参数
rbta.setReadOnly(attributes.getBoolean("readOnly"));
// 从注解信息中获取 value 信息并且设置 qualifier,表示当前事务指定使用的【事务管理器】
rbta.setQualifier(attributes.getString("value"));
// 【存放的是 rollback 条件】,回滚规则放在这个集合
List<RollbackRuleAttribute> rollbackRules = new ArrayList<>();
// 表示事务碰到哪些指定的异常才进行回滚,不指定的话默认是 RuntimeException/Error 非检查型异常菜回滚
for (Class<?> rbRule : attributes.getClassArray("rollbackFor")) {
rollbackRules.add(new RollbackRuleAttribute(rbRule));
}
// 与 rollbackFor 功能相同
for (String rbRule : attributes.getStringArray("rollbackForClassName")) {
rollbackRules.add(new RollbackRuleAttribute(rbRule));
}
// 表示事务碰到指定的 exception 实现对象不进行回滚,否则碰到其他的class就进行回滚
for (Class<?> rbRule : attributes.getClassArray("noRollbackFor")) {
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
}
for (String rbRule : attributes.getStringArray("noRollbackForClassName")) {
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
}
// 设置回滚规则
rbta.setRollbackRules(rollbackRules);
return rbta;
}
驱动方法
TransactionInterceptor 事务拦截器的核心驱动方法:
public Object invoke(MethodInvocation invocation) throws Throwable {
// targetClass 是需要被事务增强器增强的目标类,invocation.getThis() → 目标对象 → 目标类
Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
// 参数一是目标方法,参数二是目标类,参数三是方法引用,用来触发驱动方法
return invokeWithinTransaction(invocation.getMethod(), targetClass, invocation::proceed);
}
protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass,
final InvocationCallback invocation) throws Throwable {
// 事务属性源信息
TransactionAttributeSource tas = getTransactionAttributeSource();
// 提取 @Transactional 注解信息,txAttr 是注解信息的承载对象
final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);
// 获取 Spring 配置的事务管理器
// 首先会检查是否通过XML或注解配置 qualifier,没有就尝试去容器获取,一般情况下为 DatasourceTransactionManager
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
// 权限定类名.方法名,该值用来当做事务名称使用
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
// 条件成立说明是【声明式事务】
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// 用来【开启事务】
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal;
try {
// This is an 【around advice】: Invoke the next interceptor in the chain.
// 环绕通知,执行目标方法(方法引用方式,invocation::proceed,还是调用 proceed)
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// 执行业务代码时抛出异常,执行回滚逻辑
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
// 清理事务的信息
cleanupTransactionInfo(txInfo);
}
// 提交事务的入口
commitTransactionAfterReturning(txInfo);
return retVal;
}
else {
// 编程式事务,省略
}
}
开启事务
事务绑定
创建事务的方法:
protected TransactionInfo createTransactionIfNecessary(@Nullable PlatformTransactionManager tm,
@Nullable TransactionAttribute txAttr,
final String joinpointIdentification) {
// If no name specified, apply method identification as transaction name.
if (txAttr != null && txAttr.getName() == null) {
// 事务的名称: 类的权限定名.方法名
txAttr = new DelegatingTransactionAttribute(txAttr) {
@Override
public String getName() {
return joinpointIdentification;
}
};
}
TransactionStatus status = null;
if (txAttr != null) {
if (tm != null) {
// 通过事务管理器根据事务属性创建事务状态对象,事务状态对象一般情况下包装着 事务对象,当然也有可能是null
// 方法上的注解为 @Transactional(propagation = NOT_SUPPORTED || propagation = NEVER) 时
// 【下一小节详解】
status = tm.getTransaction(txAttr);
}
else {
if (logger.isDebugEnabled()) {
logger.debug("Skipping transactional joinpoint [" + joinpointIdentification +
"] because no transaction manager has been configured");
}
}
}
// 包装成一个上层的事务上下文对象
return prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
}
TransactionAspectSupport#prepareTransactionInfo:为事务的属性和状态准备一个事务信息对象
TransactionInfo txInfo = new TransactionInfo(tm, txAttr, joinpointIdentification):创建事务信息对象txInfo.newTransactionStatus(status):填充事务的状态信息txInfo.bindToThread():利用 ThreadLocal 把当前事务信息绑定到当前线程,不同的事务信息会形成一个栈的结构this.oldTransactionInfo = transactionInfoHolder.get():获取其他事务的信息存入 oldTransactionInfotransactionInfoHolder.set(this):将当前的事务信息设置到 ThreadLocalMap 中
事务创建
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException {
// 获取事务的对象
Object transaction = doGetTransaction();
boolean debugEnabled = logger.isDebugEnabled();
if (definition == null) {
// Use defaults if no transaction definition given.
definition = new DefaultTransactionDefinition();
}
// 条件成立说明当前是事务重入的情况,事务中有 ConnectionHolder 对象
if (isExistingTransaction(transaction)) {
// a方法开启事务,a方法内调用b方法,b方法仍然加了 @Transactional 注解,需要检查传播行为
return handleExistingTransaction(definition, transaction, debugEnabled);
}
// 逻辑到这说明当前线程没有连接资源,一个连接对应一个事务,没有连接就相当于没有开启事务
// 检查事务的延迟属性
if (definition.getTimeout() < TransactionDefinition.TIMEOUT_DEFAULT) {
throw new InvalidTimeoutException("Invalid transaction timeout", definition.getTimeout());
}
// 传播行为是 MANDATORY,没有事务就抛出异常
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException();
}
// 需要开启事务的传播行为
else if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
// 什么也没挂起,因为线程并没有绑定事务
SuspendedResourcesHolder suspendedResources = suspend(null);
try {
// 是否支持同步线程事务,一般是 true
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
// 新建一个事务状态信息
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
// 【启动事务】
doBegin(transaction, definition);
// 设置线程上下文变量,方便程序运行期间获取当前事务的一些核心的属性,initSynchronization() 启动同步
prepareSynchronization(status, definition);
return status;
}
catch (RuntimeException | Error ex) {
// 恢复现场
resume(null, suspendedResources);
throw ex;
}
}
// 不支持事务的传播行为
else {
// Create "empty" transaction: no actual transaction, but potentially synchronization.
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
// 创建事务状态对象
// 参数2 transaction 是 null 说明当前事务状态是未手动开启事,线程上未绑定任何的连接资源,业务程序执行时需要先去 datasource 获取的 conn,是自动提交事务的,不需要 Spring 再提交事务
// 参数6 suspendedResources 是 null 说明当前事务状态未挂起任何事务,当前事务执行到后置处理时不需要恢复现场
return prepareTransactionStatus(definition, null, true, newSynchronization, debugEnabled, null);
}
}
DataSourceTransactionManager#doGetTransaction:真正获取事务的方法
-
DataSourceTransactionObject txObject = new DataSourceTransactionObject():创建事务对象 -
txObject.setSavepointAllowed(isNestedAllowed()):设置事务对象是否支持保存点,由事务管理器控制(默认不支持) -
ConnectionHolder conHolder = TransactionSynchronizationManager.getResource(obtainDataSource()):-
从 ThreadLocal 中获取 conHolder 资源,可能拿到 null 或者不是 null
-
是 null:举例
@Transaction public void a() {...b.b()....} -
不是 null:执行 b 方法事务增强的前置逻辑时,可以拿到 a 放进去的 conHolder 资源
@Transaction public void b() {....}
-
-
txObject.setConnectionHolder(conHolder, false):将 ConnectionHolder 保存到事务对象内,参数二是 false 代表连接资源是上层事务共享的,不是新建的连接资源 -
return txObject:返回事务的对象
DataSourceTransactionManager#doBegin:事务开启的逻辑
-
txObject = (DataSourceTransactionObject) transaction:强转为事务对象 -
事务中没有数据库连接资源就要分配:
Connection newCon = obtainDataSource().getConnection():获取 JDBC 原生的数据库连接对象txObject.setConnectionHolder(new ConnectionHolder(newCon), true):代表是新开启的事务,新建的连接对象 -
previousIsolationLevel = DataSourceUtils.prepareConnectionForTransaction(con, definition):修改连接属性-
if (definition != null && definition.isReadOnly()):注解(或 XML)配置了只读属性,需要设置 -
if (..definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT):注解配置了隔离级别int currentIsolation = con.getTransactionIsolation():获取连接的隔离界别previousIsolationLevel = currentIsolation:保存之前的隔离界别,返回该值con.setTransactionIsolation(definition.getIsolationLevel()):将当前连接设置为配置的隔离界别
-
-
txObject.setPreviousIsolationLevel(previousIsolationLevel):将 Conn 原来的隔离级别保存到事务对象,为了释放 Conn 时重置回原状态 -
`if (con















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









