







前言
其实,单纯从我们的实用来看,前面的所有章节都无需理解,本节才是关键,就像绝大部分人不会去追究1+1为什么等于2,我们只需要知道它等于2即可
hanlp分词主要有两个,对应前面章节学习的双数组字典树和基于双数组的AC树。
类名分别为:
DoubleArrayTireSegment和AhoCorasickDoubleArrayTireSegment
一、java版实战
我们之间去调用hanlp已经写好的类即可,这里只演示DoubleArrayTrieSegment,因为另一个没区别(只是类调用,无关实现,使用的方法是完全一样的)
下面三点记住,实战戳手可得:
- 对象.seg(“文本”)
- HanLP.Config.ShowTermNature = false; // 分词结果不显示词性
- 对象.enablePartOfSpeechTagging(true); // 激活数词和英文识别
先上代码:
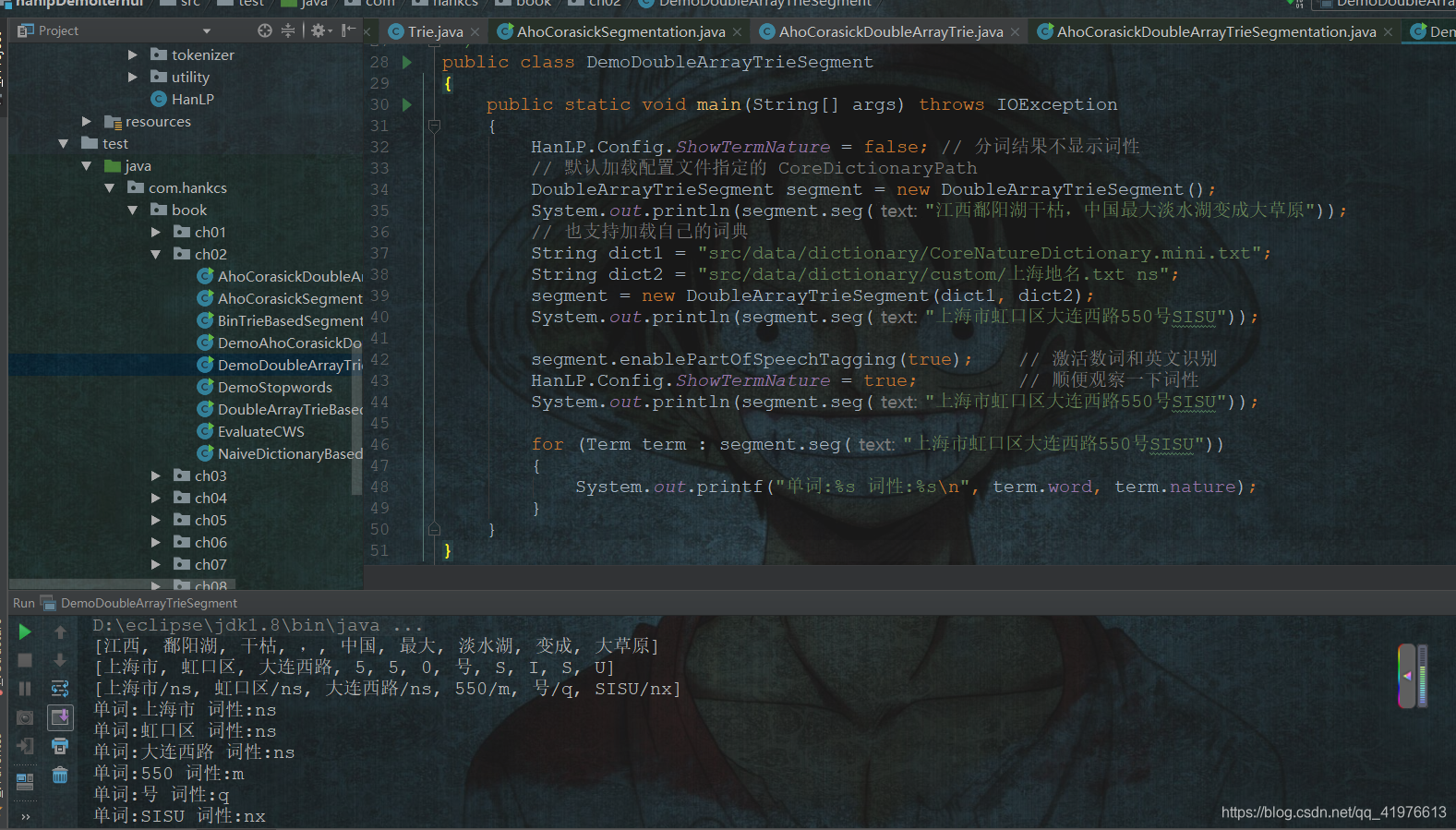
public class DemoDoubleArrayTrieSegment
{
public static void main(String[] args) throws IOException
{
HanLP.Config.ShowTermNature = false; // 分词结果不显示词性
// 默认加载配置文件指定的 CoreDictionaryPath
DoubleArrayTrieSegment segment = new DoubleArrayTrieSegment();
System.out.println(segment.seg("江西鄱阳湖干枯,中国最大淡水湖变成大草原"));
// 也支持加载自己的词典
String dict1 = "src/data/dictionary/CoreNatureDictionary.mini.txt";
String dict2 = "src/data/dictionary/custom/上海地名.txt ns";
segment = new DoubleArrayTrieSegment(dict1, dict2);
System.out.println(segment.seg("上海市虹口区大连西路550号SISU"));
segment.enablePartOfSpeechTagging(true); // 激活数词和英文识别
HanLP.Config.ShowTermNature = true; // 顺便观察一下词性
System.out.println(segment.seg("上海市虹口区大连西路550号SISU"));
for (Term term : segment.seg("上海市虹口区大连西路550号SISU"))
{
System.out.printf("单词:%s 词性:%s\n", term.word, term.nature);
}
}
}
二、Python版实战
Python版其实一样,但要熟悉一点,数据在pyhanlp.static下
此外:
java的segment传入文本直接放入多个参数即可,Python的是转为列表放入。
from pyhanlp import *
from pyhanlp.static import HANLP_DATA_PATH
HanLP.Config.ShowTermNature = False
segment = DoubleArrayTrieSegment()
print(segment.seg('江西鄱阳湖干枯,中国最大淡水湖变成大草原'))
dict1 = HANLP_DATA_PATH + "/dictionary/CoreNatureDictionary.mini.txt"
dict2 = HANLP_DATA_PATH + "/dictionary/custom/上海地名.txt ns"
segment = DoubleArrayTrieSegment([dict1, dict2])
print(segment.seg('上海市虹口区大连西路550号SISU'))
segment.enablePartOfSpeechTagging(True)
HanLP.Config.ShowTermNature = True
print(segment.seg('上海市虹口区大连西路550号SISU'))
for term in segment.seg('上海市虹口区大连西路550号SISU'):
print("单词:%s 词性:%s" % (term.word, term.nature))
总结
本章节的东西其实并不多,但却是最关键的,一定要熟练掌握并运用。
补充一个细节:
路径的后面有个 ns,意思为词典的词语默认词性为ns,默认词性的存在,用户就不需要逐个标记词性了,比如:你自己写了两个文本,一个是人名,一个是地名,那你只需要在读取的时候前者写nr后者写个ns即可。 不需要再在文本中每个人名或者地名后面标注nr ns。
此外:本人创建了QQ交流群,希望大家来交流学习(新群人少,不是假群o(╥﹏╥)o…)



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











