







论文题目:Prototypical contrastive learning of unsupervised representations
论文链接:https://arxiv.org/pdf/2005.04966.pdf
1. 背景与动机
无监督视觉表示学习的目的是在不依赖语义注释的情况下从像素本身学习图像表示,最近的进展主要是由实例判别任务(instance discrimination task)驱动的。这些方法通常包含两个关键成分:图像变换和对比损失。它们旨在于学习一个嵌入空间,在这个空间中,所有的实例都被很好地分离,每个实例都是局部平滑的(即具有扰动的输入具有类似的表示)。
尽管实例对比学习已经取得了许多进展,但现有方法通常将两个来自不同实例的样本看作负样本对,忽略了它们之间的语义相似性,导致许多具有相似语义的负样本对,在嵌入空间中被推开。
为了解决这一问题,作者提出原型对比学习(Prototypical contrastive learning, PCL)将数据的语义结构编码到嵌入空间。“原型”被定义为一组语义相似实例的代表性表示,每个实例被分配不同粒度的若干个原型,并构建对比损失让一个样本与其对应的原型最相似,而与其他原型不相似。
2. 方法实现
2.1 总体思路
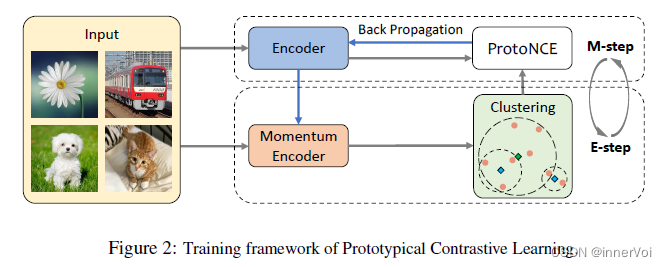
PCL的执行像EM算法(Expectaion-Maximization)一样,通过迭代的估计和最大化似然函数,来学习深度神经网络的参数以最好的描述数据分布。
- E步:通过K-means聚类得到原型并将其作为一个额外的隐变量,估计它的概率。
- M步:最小化对比损失ProtoNCE来更新网络参数。
2.2 预备知识
给定n个图像的训练集
X
=
{
x
1
,
x
2
,
⋯
,
x
n
}
X=\{x_{1}, x_{2}, \cdots, x_{n}\}
X={x1,x2,⋯,xn},无监督视觉表示学习旨在于学习一个映射函数将
X
X
X映射到
V
=
{
v
1
,
v
2
,
⋯
,
v
n
}
,
v
i
=
f
θ
(
x
i
)
V=\{v_{1}, v_{2}, \cdots, v_{n}\}, v_{i}=f_{\theta}(x_{i})
V={v1,v2,⋯,vn},vi=fθ(xi)。实例对比学习利用一个如InfoNCE的对比损失函数来实现这一目标。
L
InfoNCE
=
∑
i
=
1
n
−
log
exp
(
v
i
⋅
v
i
′
/
τ
)
∑
j
=
0
r
exp
(
v
i
⋅
v
j
′
/
τ
)
(1)
\mathcal{L}_{\text {InfoNCE }}=\sum_{i=1}^n-\log \frac{\exp \left(v_i \cdot v_i^{\prime} / \tau\right)}{\sum_{j=0}^r \exp \left(v_i \cdot v_j^{\prime} / \tau\right)} \tag{1}
LInfoNCE =i=1∑n−log∑j=0rexp(vi⋅vj′/τ)exp(vi⋅vi′/τ)(1)
其中,
v
i
v_i
vi和
v
i
′
v_i^{\prime}
vi′是实例
i
i
i的正嵌入,
v
j
′
v_j^{\prime}
vj′包含一个正嵌入和
r
r
r个负嵌入,
τ
\tau
τ是温度超参数。在MoCo中,这些嵌入通过将
x
i
x_{i}
xi喂给一个由参数
θ
′
\theta^{\prime}
θ′参数化的动量编码器得到,
v
i
′
=
f
θ
′
(
x
i
)
v_{i}^{\prime}=f_{\theta^{\prime}}(x_{i})
vi′=fθ′(xi)
在PCL中,作者使用原型 c c c替代 v ′ v^{\prime} v′,使用每个原型的聚合度估计 ϕ \phi ϕ替代 τ \tau τ。
2.3 实现细节
目标:找到网络参数来最大化观测到的
n
n
n个样本的似然函数。
θ
∗
=
arg
max
θ
∑
i
=
1
n
log
p
(
x
i
;
θ
)
(2)
\theta^*=\underset{\theta}{\arg \max } \sum_{i=1}^n \log p\left(x_i ; \theta\right) \tag{2}
θ∗=θargmaxi=1∑nlogp(xi;θ)(2)
假设观测数据
{
x
i
}
i
=
1
n
\{x_{i}\}_{i=1}^{n}
{xi}i=1n与原型变量
C
=
{
c
i
}
i
=
1
k
C=\{c_{i}\}_{i=1}^{k}
C={ci}i=1k相关,则似然函数可以被重写为:
θ
∗
=
arg
max
θ
∑
i
=
1
n
log
p
(
x
i
;
θ
)
=
arg
max
θ
∑
i
=
1
n
log
∑
c
i
∈
C
p
(
x
i
,
c
i
;
θ
)
(3)
\theta^*=\underset{\theta}{\arg \max } \sum_{i=1}^n \log p\left(x_i ; \theta\right)=\underset{\theta}{\arg \max } \sum_{i=1}^n \log \sum_{c_i \in C} p\left(x_i, c_i ; \theta\right) \tag{3}
θ∗=θargmaxi=1∑nlogp(xi;θ)=θargmaxi=1∑nlogci∈C∑p(xi,ci;θ)(3)
由于该函数难以优化,因此作者对该函数取另一个下界,得到函数:
∑
i
=
1
n
log
∑
c
i
∈
C
p
(
x
i
,
c
i
;
θ
)
=
∑
i
=
1
n
log
∑
c
i
∈
C
Q
(
c
i
)
p
(
x
i
,
c
i
;
θ
)
Q
(
c
i
)
≥
∑
i
=
1
n
∑
c
i
∈
C
Q
(
c
i
)
log
p
(
x
i
,
c
i
;
θ
)
Q
(
c
i
)
(4)
\sum_{i=1}^n \log \sum_{c_i \in C} p\left(x_i, c_i ; \theta\right)=\sum_{i=1}^n \log \sum_{c_i \in C} Q\left(c_i\right) \frac{p\left(x_i, c_i ; \theta\right)}{Q\left(c_i\right)} \geq \sum_{i=1}^n \sum_{c_i \in C} Q\left(c_i\right) \log \frac{p\left(x_i, c_i ; \theta\right)}{Q\left(c_i\right)} \tag{4}
i=1∑nlogci∈C∑p(xi,ci;θ)=i=1∑nlogci∈C∑Q(ci)Q(ci)p(xi,ci;θ)≥i=1∑nci∈C∑Q(ci)logQ(ci)p(xi,ci;θ)(4)
其中,
Q
(
c
i
)
Q\left(c_i\right)
Q(ci)表示
c
c
c的分布,
∑
c
i
∈
C
Q
(
c
i
)
=
1
\sum_{c_i\in C}Q(c_i)=1
∑ci∈CQ(ci)=1。当
p
(
x
i
,
c
i
;
θ
)
Q
(
c
i
)
\frac{p\left(x_i, c_i ; \theta\right)}{Q\left(c_i\right)}
Q(ci)p(xi,ci;θ)是一个常数时,等式成立。
Q
(
c
i
)
Q\left(c_i\right)
Q(ci)可以改写为:
Q
(
c
i
)
=
p
(
x
i
,
c
i
;
θ
)
∑
c
i
∈
C
p
(
x
i
,
c
i
;
θ
)
=
p
(
x
i
,
c
i
;
θ
)
p
(
x
i
;
θ
)
=
p
(
c
i
;
x
i
,
θ
)
(5)
Q\left(c_i\right)=\frac{p\left(x_i, c_i ; \theta\right)}{\sum_{c_i \in C} p\left(x_i, c_i ; \theta\right)}=\frac{p\left(x_i, c_i ; \theta\right)}{p\left(x_i ; \theta\right)}=p\left(c_i ; x_i, \theta\right) \tag{5}
Q(ci)=∑ci∈Cp(xi,ci;θ)p(xi,ci;θ)=p(xi;θ)p(xi,ci;θ)=p(ci;xi,θ)(5)
忽略式(4)中的常数项
−
∑
i
=
1
n
∑
c
i
∈
C
Q
(
c
i
)
log
Q
(
c
i
)
-\sum_{i=1}^{n}\sum_{c_{i}\in C}Q\left(c_i\right)\log Q\left(c_i\right)
−∑i=1n∑ci∈CQ(ci)logQ(ci),最大化似然函数变成:
∑
i
=
1
n
∑
c
i
∈
C
Q
(
c
i
)
log
p
(
x
i
,
c
i
;
θ
)
(6)
\sum_{i=1}^{n}\sum_{c_{i}\in C}Q\left(c_i\right)\log p\left(x_i, c_i ; \theta\right) \tag{6}
i=1∑nci∈C∑Q(ci)logp(xi,ci;θ)(6)
E-step
估计 p ( c i ; x i , θ ) p\left(c_i ; x_i, \theta\right) p(ci;xi,θ),对经过动量编码器后的特征执行k-means聚类得到 k k k类。第 i i i类的中心被定义为 c i c_i ci,然后计算 p ( c i ; x i , θ ) = I ( x I ∈ c i ) p\left(c_i ; x_i, \theta\right) = \mathbb{I}(x_I\in c_i) p(ci;xi,θ)=I(xI∈ci),如果样本属于该类则 I ( x I ∈ c i ) = 1 \mathbb{I}(x_I\in c_i)=1 I(xI∈ci)=1,否则 I ( x I ∈ c i ) = 0 \mathbb{I}(x_I\in c_i)=0 I(xI∈ci)=0。
M-step
基于E步,式(6)可以写成:
∑
i
=
1
n
∑
c
i
∈
C
Q
(
c
i
)
log
p
(
x
i
,
c
i
;
θ
)
=
∑
i
=
1
n
∑
c
i
∈
C
p
(
c
i
;
x
i
,
θ
)
log
p
(
x
i
,
c
i
;
θ
)
=
∑
i
=
1
n
∑
c
i
∈
C
I
(
x
i
∈
c
i
)
log
p
(
x
i
,
c
i
;
θ
)
(7)
\begin{aligned} \sum_{i=1}^n \sum_{c_i \in C} Q\left(c_i\right) \log p\left(x_i, c_i ; \theta\right) & =\sum_{i=1}^n \sum_{c_i \in C} p\left(c_i ; x_i, \theta\right) \log p\left(x_i, c_i ; \theta\right) \\ & =\sum_{i=1}^n \sum_{c_i \in C} \mathbb{I}\left(x_i \in c_i\right) \log p\left(x_i, c_i ; \theta\right) \end{aligned} \tag{7}
i=1∑nci∈C∑Q(ci)logp(xi,ci;θ)=i=1∑nci∈C∑p(ci;xi,θ)logp(xi,ci;θ)=i=1∑nci∈C∑I(xi∈ci)logp(xi,ci;θ)(7)
假设聚类质心均匀,则有:
p
(
x
i
,
c
i
;
θ
)
=
p
(
x
i
;
c
i
,
θ
)
p
(
c
i
;
θ
)
=
1
k
⋅
p
(
x
i
;
c
i
,
θ
)
(8)
p\left(x_i, c_i ; \theta\right)=p\left(x_i ; c_i, \theta\right) p\left(c_i ; \theta\right)=\frac{1}{k} \cdot p\left(x_i ; c_i, \theta\right) \tag{8}
p(xi,ci;θ)=p(xi;ci,θ)p(ci;θ)=k1⋅p(xi;ci,θ)(8)
设置每个
c
i
c_i
ci的先验概率
p
(
c
i
;
θ
)
p(c_i;\theta)
p(ci;θ)为
1
/
k
1/k
1/k,并假设每个原型周围的分布满足各向同性高斯(isotropic Gaussian),则
p
(
x
i
;
c
i
,
θ
)
=
e
x
p
(
−
(
v
i
−
c
s
)
2
2
σ
s
2
)
/
∑
j
=
1
k
e
x
p
(
−
(
v
j
−
c
j
)
2
2
σ
j
2
)
p\left(x_i ; c_i, \theta\right)=exp(\frac{-(v_i-c_s)^2}{2\sigma_s^2})/\sum_{j=1}^{k}exp(\frac{-(v_j-c_j)^2}{2\sigma_j^2})
p(xi;ci,θ)=exp(2σs2−(vi−cs)2)/j=1∑kexp(2σj2−(vj−cj)2)
如果对
v
v
v和
c
c
c都进行
l
2
l_2
l2归一化,则
(
v
−
c
)
2
=
2
−
2
v
⋅
c
(v-c)^2 =2-2v\cdot c
(v−c)2=2−2v⋅c。结合式(3-4,6-9),参数的最大似然估计可以被写为:
θ
∗
=
arg
min
θ
∑
i
=
1
n
−
log
exp
(
v
i
⋅
c
s
/
ϕ
s
)
∑
j
=
1
k
exp
(
v
i
⋅
c
j
/
ϕ
j
)
(9)
\theta^*=\underset{\theta}{\arg \min } \sum_{i=1}^n-\log \frac{\exp \left(v_i \cdot c_s / \phi_s\right)}{\sum_{j=1}^k \exp \left(v_i \cdot c_j / \phi_j\right)} \tag{9}
θ∗=θargmini=1∑n−log∑j=1kexp(vi⋅cj/ϕj)exp(vi⋅cs/ϕs)(9)
最终损失函数ProtoNCE被定义为:
L
ProtoNCE
=
∑
i
=
1
n
−
(
log
exp
(
v
i
⋅
v
i
′
/
τ
)
∑
j
=
0
r
exp
(
v
i
⋅
v
j
′
/
τ
)
+
1
M
∑
m
=
1
M
log
exp
(
v
i
⋅
c
s
m
/
ϕ
s
m
)
∑
j
=
0
r
exp
(
v
i
⋅
c
j
m
/
ϕ
j
m
)
)
(10)
\mathcal{L}_{\text {ProtoNCE }}=\sum_{i=1}^n-\left(\log \frac{\exp \left(v_i \cdot v_i^{\prime} / \tau\right)}{\sum_{j=0}^r \exp \left(v_i \cdot v_j^{\prime} / \tau\right)}+\frac{1}{M} \sum_{m=1}^M \log \frac{\exp \left(v_i \cdot c_s^m / \phi_s^m\right)}{\sum_{j=0}^r \exp \left(v_i \cdot c_j^m / \phi_j^m\right)}\right) \tag{10}
LProtoNCE =i=1∑n−(log∑j=0rexp(vi⋅vj′/τ)exp(vi⋅vi′/τ)+M1m=1∑Mlog∑j=0rexp(vi⋅cjm/ϕjm)exp(vi⋅csm/ϕsm))(10)
其中,原型的聚合度
ϕ
\phi
ϕ由下式衡量得到:
ϕ
=
∑
z
=
1
Z
∥
v
z
′
−
c
∥
2
Z
log
(
Z
+
α
)
(11)
\phi=\frac{\sum_{z=1}^Z\left\|v_z^{\prime}-c\right\|_2}{Z \log (Z+\alpha)} \tag{11}
ϕ=Zlog(Z+α)∑z=1Z∥vz′−c∥2(11)
PCL的实现流程如算法1所示:

3. 实验设置
3.1 数据集
- ImageNet-1M
3.2 Baselines
- Low-shot image classification
- SimCLR; MoCo; Jigsaw;
- Semi-supervised image classification
- Pseudolaels; VAT+Entropy; S 4 S^4 S4L Rotation; Instance Discrimination; Jigsaw; MoCo; PIRL; SimCLR; BYOL;
- Linear classification
- Jigsaw; Rotation; DeepCluster; BigBiGAN; InstDisc; MoCo; SimCLR; LocalAgg; SelfLabel; CPC; CMC; PIRL; AMDIM; BYOL; SwAV;
3.3 实验结果
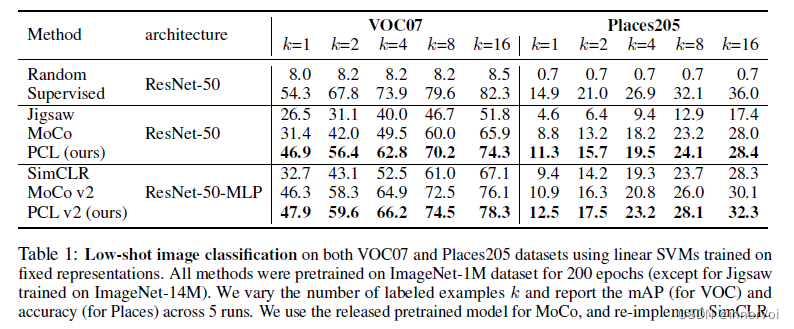
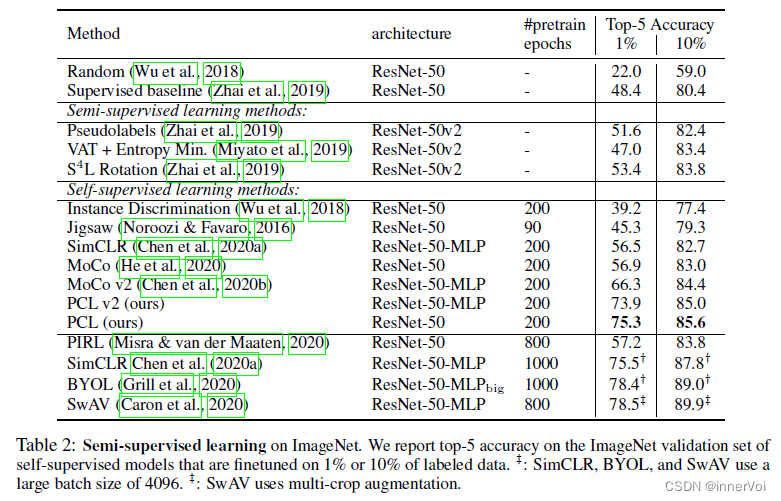
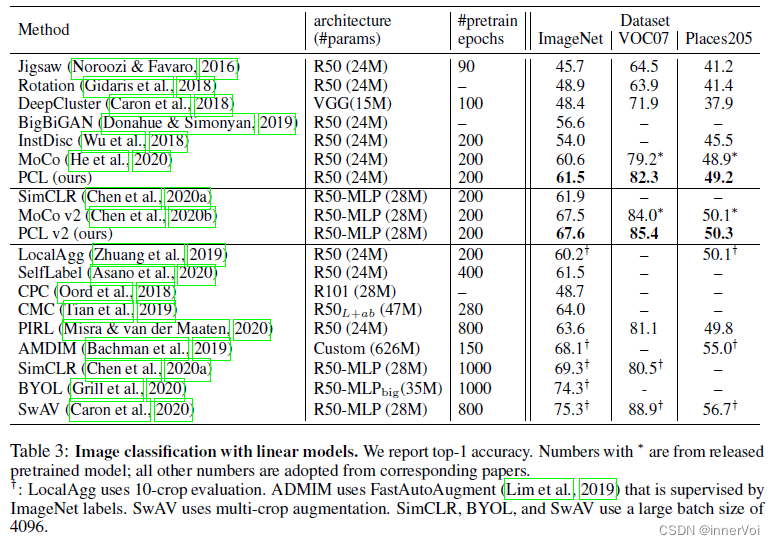
4. 总结
这篇文章提出了原型对比学习(PCL),一种最大化可观测数据似然来发现网络参数的通用无监督表示学习框架。PCL将引入的原型作为隐变量,利用基于EM算法的框架执行迭代的聚类和表示学习,并且可以通过对比损失ProtoNCE能够编码数据的语义结构。
参考文献
[1] Li J, Zhou P, Xiong C, et al. Prototypical Contrastive Learning of Unsupervised Representations[C]//International Conference on Learning Representations. 2021.
更多论文分享欢迎关注微信公众号 Efficient AI



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









