







概述
该文作者是德国萨尔大学的Thorsten Brants,作者认为Tri-Grams’n’Tages(TnT)可以作为一种有效的词性标记统计方法,并且作者认为基于马尔科夫(Markov model)的标记器理论上性能是和其他模型相当的,此外使用平滑的方法(Smoothing)处理了未出现词的概率。下面我们就来看看该文作者具体是怎么实现的。
内容背景介绍
语言处理系统都会使用词性标记器进行预处理。标记器为输入中的每个标记分配一部分(唯一或不明确的)语音标记,并将其输出传递到下一个处理级别,通常是解析器。
当时的时间点下,基于最大熵框架的统计方法表现出了很强的应用性。但是,作者认为马尔可夫模型和良好的平滑技术对未知单词的处理可以获得了很高的准确度,而且在训练和标记方面都是最快的。
模型体系架构
目标函数推导
TnT使用二阶Markov模型进行词性标注。模型隐含层为词性标注,观测值为句中单词,转换概率取决于隐含层的状态矩阵。此外,输出概率仅取决于最近的类别。目标函数可以表示为(文献中):

该公式我不太了解作者是怎么推导的,我按照他的Tri-Grams进行了重新推导,推导过程如下:
如图所示为HMM模型的概率图结构,其中x标签为观测值在词性标注中为观测到的单词,y为隐含层在词性标注中为需要预测的单词词性。

HMM是一种生成模型其目标概率是最大化x和y的联合概率:
a
r
g
m
a
x
(
p
(
x
1
,
x
2
.
.
.
x
n
,
y
1
,
y
2
.
.
.
y
n
)
)
argmax (p(x_1,x_2...x_n,y_1,y_2...y_n))
argmax(p(x1,x2...xn,y1,y2...yn))
使用条件概率将上述公式展开:
a
r
g
m
a
x
[
p
(
x
1
,
x
2
.
.
.
x
n
∣
y
1
,
y
2
.
.
.
y
n
)
∗
p
(
y
1
,
y
2
.
.
.
y
n
)
]
argmax[p(x_1,x_2...x_n|y_1,y_2...y_n)*p(y_1,y_2...y_n)]
argmax[p(x1,x2...xn∣y1,y2...yn)∗p(y1,y2...yn)]
基于观测独立假设上述公式简化为:
a
r
g
m
a
x
[
p
(
x
1
∣
y
1
,
y
2
.
.
.
y
n
)
∗
p
(
x
2
∣
y
1
,
y
2
.
.
.
y
n
)
.
.
.
p
(
x
n
∣
y
1
,
y
2
.
.
.
y
n
)
∗
p
(
y
1
,
y
2
.
.
.
y
n
)
]
argmax[p(x_1|y_1,y_2...y_n)*p(x_2|y_1,y_2...y_n)...p(x_n|y_1,y_2...y_n)*p(y_1,y_2...y_n)]
argmax[p(x1∣y1,y2...yn)∗p(x2∣y1,y2...yn)...p(xn∣y1,y2...yn)∗p(y1,y2...yn)]
进一步简化为:
a
r
g
m
a
x
[
p
(
x
1
∣
y
1
,
)
∗
p
(
x
2
∣
y
2
)
.
.
.
p
(
x
n
∣
y
n
)
∗
p
(
y
1
,
y
2
.
.
.
y
n
)
]
argmax[p(x_1|y_1,)*p(x_2|y_2)...p(x_n|y_n)*p(y_1,y_2...y_n)]
argmax[p(x1∣y1,)∗p(x2∣y2)...p(xn∣yn)∗p(y1,y2...yn)]
即:
a
r
g
m
a
x
[
∏
i
=
0
n
[
p
(
x
i
∣
y
i
)
]
∗
p
(
y
1
,
y
2
.
.
.
y
n
)
]
argmax[\prod \limits_{i=0}^n[p(x_i|y_i)]*p(y_1,y_2...y_n)]
argmax[i=0∏n[p(xi∣yi)]∗p(y1,y2...yn)]
继续使用条件概率将上述公式转化为:
a
r
g
m
a
x
[
∏
i
=
1
n
[
p
(
x
i
∣
y
i
)
]
∗
p
(
y
n
∣
y
1
,
y
2
.
.
.
y
n
−
1
)
∗
p
(
y
n
−
1
∣
y
1
,
y
2
.
.
.
y
n
−
2
)
.
.
.
p
(
y
1
)
)
]
argmax[\prod \limits_{i=1}^n[p(x_i|y_i)]*p(y_n|y_1,y_2...y_{n-1})*p(y_{n-1}|y_1,y_2...y_{n-2})...p(y_1))]
argmax[i=1∏n[p(xi∣yi)]∗p(yn∣y1,y2...yn−1)∗p(yn−1∣y1,y2...yn−2)...p(y1))]
使用Tri-Grams假设,当前x只与前两个x有关,上述公式简化为:
a
r
g
m
a
x
[
∏
i
=
1
n
[
p
(
x
i
∣
y
i
)
]
∗
∏
i
=
2
n
[
p
(
y
i
∣
y
i
−
1
,
y
i
−
2
)
]
∗
p
(
y
1
)
]
argmax[\prod \limits_{i=1}^n[p(x_i|y_i)]*\prod \limits_{i=2}^n[p(y_i|y_{i-1},y_{i-2})] *p(y_1)]
argmax[i=1∏n[p(xi∣yi)]∗i=2∏n[p(yi∣yi−1,yi−2)]∗p(y1)]
上述公式与该文献中的略有区别,这是由于该文作者将首单词概率并到连乘内部了,这样做的好处是可以考虑标点符号的影响。
Smoothing 处理
由语料库生成的三元概率通常不能直接使用,这是由于没有足够的实例可以让每个trigrams组都能得到可靠的估计概率。总会存在未能包含在语料库的trigrams组,但是又不能直接将该单词的概率直接设置为0.
作者采用unigrams、bigrams和trigrams的线性插值作为平滑范式。因此,trigrams概率计算如下:
三个系数相加和为1,公式中的三个系数的计算采用如下算法得到:

注:减去1意味着将未看到的数据考虑在内,如果没有这个减法,模型会过拟合训练数据,通常会产生更差的结果。
未知词的处理
文章对未知词的词性标记的处理是通过计算后缀名相似概率得到的,对于一个有m个字母 l 的单词其词性概率的计算通过如下公式得到,公式中i为单子的尾字母个数。
P
(
t
∣
l
n
−
i
+
1
,
.
.
.
l
n
)
P(t|l_{n-i+1},...l_n)
P(t∣ln−i+1,...ln)
该概率的计算在文章中使用了一种递归的求解方法:
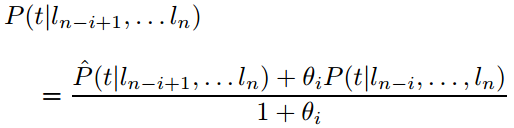
通过最大似然估计法计算

将所有θi设置为训练集中标签的无条件最大似然概率的标准偏差,即:

大小写问题
这一部分是专门针对有大小写区分的语言(中文就没有),在Tri-Grams概率中增加了一个bool的C标记,以此标记单词是否为大写,转化后概率为:

定向搜索
这部分是求解的方法,内容要是展开的话还是比较多的,有感兴趣的小伙伴可以仔细研究,时间有限,这里我就不详细展开了。
总结
这篇文章阐述了二阶HMM的实现方法和一些细节处理,有兴趣的同学可以自己阅读该论文,毕竟写博客的时间有限很多也没有解释特别清楚。
注:isnowfy大神在项目Snownlp实现TnT与Character-Based Discriminative Model;并且在博文中给出两者与最大匹配、Word-based Unigram模型的准确率比较,可以看出Generative Model的准确率较高。Snownlp的默认分词方案采用的是CharacterBasedGenerativeModel。
hankcs, 基于HMM2-Trigram字符序列标注的中文分词器Java实现.















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









