







概述
2003 年的Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network是由斯坦福大学的Kristina Toutanova发表的。 在他的文章中提出了一个新的词性标注方法,主要实现了三个层面的改进:
首先是概率图的方法综合考虑了词性的前向和后向状态矩阵;
其次是采用更为先进的词汇特征工程,广泛地使用多维度的词汇特征;
再者是在条件对数概率模型中使用更为有效的先验项;
最后对未知单词特征能够进行细粒度建模。
内容背景介绍
对于序列问题,如词性标注,几乎所有的方法都采用单向的方法沿着序列进行条件推理。无论是使用HMM、最大熵条件序列模型,还是决策树等其他技术,大多数系统都是通过序列朝一个方向工作的。所以本文作者觉得这种方法对序列问题的处理不够充分,基于此作者在这个方面进行了改进。
双向概率图网络介绍
在构建标签序列的概率模型时,通常使用有向图模型(例如,HMM(Brants,2000)或条件马尔可夫模型(CMM)(Ratnaparkhi,1996))分解序列的全局概率。例如,在图a所示的从左到右的单向图上,CMM的概率计算可以表示为:
p
(
t
,
w
)
=
∏
i
p
(
t
i
∣
t
i
−
1
,
w
i
)
p(t,w)=∏_ip(t_i|t_{i-1},w_i)
p(t,w)=i∏p(ti∣ti−1,wi)
图b所示的从右到左的单线图概率计算可以表示为:
p
(
t
,
w
)
=
∏
i
p
(
t
i
∣
t
i
+
1
,
w
i
)
p(t,w)=∏_ip(t_i|t_{i+1},w_i)
p(t,w)=i∏p(ti∣ti+1,wi)
图c所示的双向图则综合考虑了前向和后项的两个特征,概率的计算公式以下列公式为基准:
p
(
t
i
∣
t
i
+
1
,
t
i
−
1
,
w
i
)
p(t_i|t_{i+1},t_{i-1},w_i)
p(ti∣ti+1,ti−1,wi)

语言图模型
图(a)和(b)中的结构是比较好理解的Bayes图模型,图(c)并不是标准的Bayes网,正是因为该图具有循环。由于图是循环的,因此并不能将大的联合概率估计分解为局部条件因子。

链式法则不允许通过乘以这两个量来构建图©所示的P(a,b)。所以,在适当的条件下,我们可以用吉布斯抽样的方法构建P(a,b)。作者在后续的实例中使用了最大熵模型构建了这个联合概率。
线性依存网络的推理
不管是不是循环概率图,都可以通过如下公式来定义score:
s
c
o
r
e
=
∏
i
p
(
x
i
∣
p
a
(
x
i
)
)
score=∏_ip(x_i|pa(x_i))
score=i∏p(xi∣pa(xi))
采用维特比(Viterbi)算法求上述score的最大值(作者文章中给出了伪代码,可以参考一下),所以这个求解过程和Tri-Grams是类似的,只是观察窗口大小不一样而已。这种方法总能找到精确的最大化序列,但只有在非循环网络的情况下,它才保证是最大似然序列。
词汇化
词汇化是统计句法分析模型发展的一个关键因素,但用于标注的研究较少。作者在最大熵模型中,观察周围词及其标记的联合特征,以及当前词和周围词的联合特征。
未知词特征
本文作者对未知词的处理任然沿用了词汇特征的处理方法,通过分析单词的前缀后缀等特征去估计词性。
平滑处理
为了防止过拟合,文章采用高斯分布作为正则项对参数估计进行处理,计算公式为:
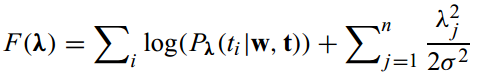
总结
这篇文章阐述了基于循环概率图的词性标注算法,有兴趣的同学可以自己阅读该论文,毕竟写博客的时间有限很多也没有解释特别清楚。
文章链接:Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network (2003)















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









