







Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象算子如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。

在 Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是Spark Streaming的核心概念和关键参数,它决定了Spark Streaming提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。
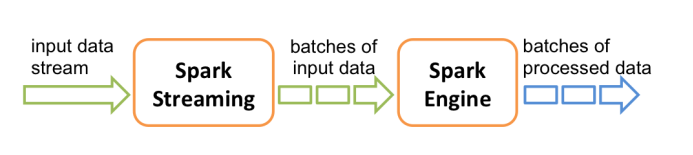
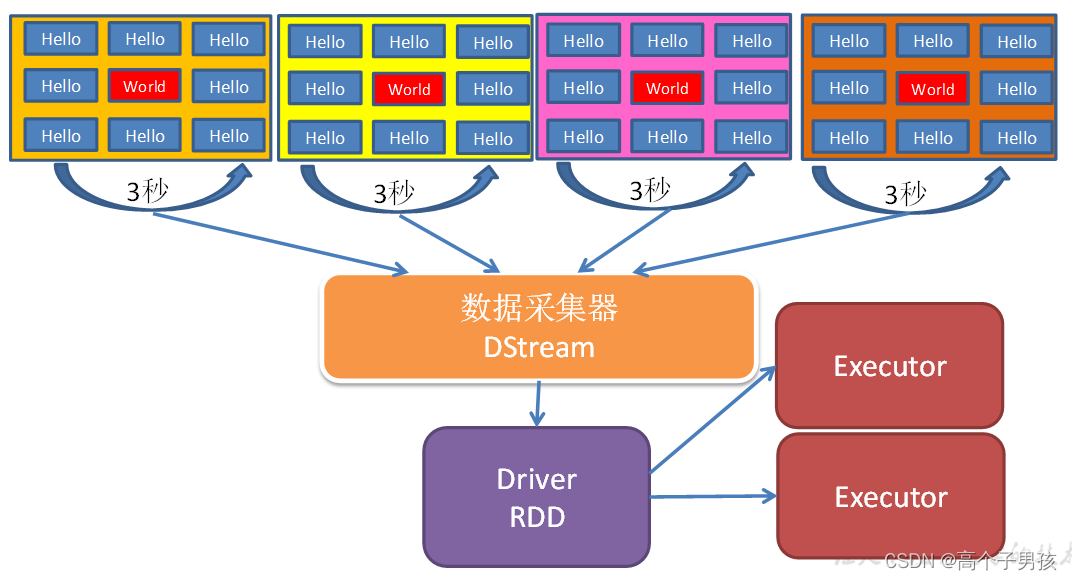
和Spark基于RDD的概念很相似,Spark Streaming使用了一个高级抽象离散化流(discretized stream),叫作DStreams。DStreams是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStreams是由这些RDD所组成的序列(因此得名“离散化”)。DStreams可以由来自数据源的输入数据流来创建, 也可以通过在其他的 DStreams上应用一些高阶操作来得到。
Spark Streaming是什么















 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









