









问题描述
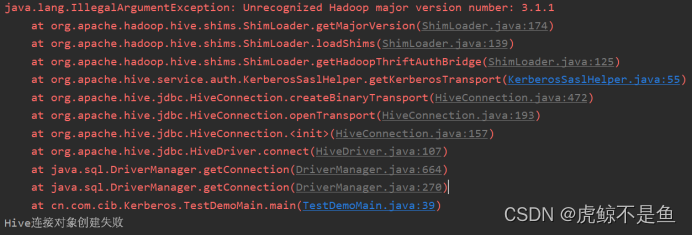
CDP7.1.6版本自带的Hive版本为3.1.3000.7.1.6.0-297,Hadoop为3.1.1,启用Kerberos认证。在调用Hive的某些方法连接JDBC时,顶层堆栈报错:
java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.1.1
如下图所示:

问题复现
环境与工具
Idea、Secure CRT、VMware虚拟机集群。
过程记录
开发机分别使用Hive3.1.2(最新的Apache Hive版本)和Hive2.1.0(开发机用的老版本)复现问题。Hadoop也分别使用2.7.5的老版本和3.1.3(与云端相同的版本),共进行了4次测验。复现了和云端JUP类似的错误。
当Hive版本是Hive2.1.0且Hadoop是3.1.3版本时,idea显式的堆栈报错与Eclipse的报错一致:
其它3种情况的报错均与之不同。
从下到上进行排查,Hive3.1.2与Hive2.1.0在调用到createBinaryTransport方法前都是一致的,之后调用KerberosSaslHelper类的getKerberosTransport方法获取HadoopThriftAuthBridge.Client类型、名称为authBridge的实例对象时,源码出现了分歧(将涉及的Jar包、类单独取出):
Hive3.1.2的相关源码是这样:
HadoopThriftAuthBridge.Client authBridge =
HadoopThriftAuthBridge.getBridge().createClientWithConf("kerberos");
return authBridge.createClientTransport(principal, host, "KERBEROS", null,
underlyingTransport, saslProps);
Hive2.1.0的相关源码是这样:
HadoopThriftAuthBridge.Client authBridge =
ShimLoader.getHadoopThriftAuthBridge().createClientWithConf("kerberos");
return authBridge.createClientTransport(principal, host, "KERBEROS", null,
underlyingTransport, saslProps);
当然只有Hive2.1.0的源码还有继续看下去的必要。顶层堆栈报错的源码:
public static String getMajorVersion() {
String vers = VersionInfo.getVersion();
String[] parts = vers.split("\\.");
if (parts.length < 2) {
throw new RuntimeException("Illegal Hadoop Version: " + vers +
" (expected A.B.* format)");
}
switch (Integer.parseInt(parts[0])) {
case 2:
return HADOOP23VERSIONNAME;
default:
throw new IllegalArgumentException("Unrecognized Hadoop major version number: " + vers);
}
}
问题显然出在这里,当识别到Hadoop版本号是3.x.x这种情况时,就根据首位的3匹配default报错,Hadoop版本号是2.x.x这种情况时,就根据首位的2匹配返回个这种对象。
尝试解决
于是暂时性的解决方案是限制Hadoop为2.x.x版本,云端Maven仓库能用的只有2.7.4,降低后问题暂时解决。不排除后续出现Hadoop版本差距过大导致新问题的可能性。
Apache版本的Hive可以采取补充case3并重新编译,让Hive低版本支持高版本Hadoop3。由于环境问题,CDP版本无法使用Eclipse查看源码及反编译、重编译,这种做法无法实现。
最终方案
总不能一直凑合。后来经过反复排查,手速足够快的一次,找到了可能导致问题的原因。
多次打断点运行后,终于发现,是因为调用了一个非常老的spark-hive的jar包,当然这个Hive1只能支持Hadoop1或者Hadoop2,估计当时的开发者也没想过后来会出现Hadoop3。
但是明明引用的是Hive3的POM,出现这种情况还是很神奇。为了验证猜测,单独构建了一个Maven工程,使用相同的代码及POM,发现不再有该报错。显然并不是Hive版本和HDFS版本冲突导致的问题,而且集群的Hive和HDFS都灰常正常,这就很神奇。分别使用CDP和Apache的Pom也不会出现调包错误的问题。那么问题就锁定在Eclipse的所谓“分布式项目”。
逐一屏蔽依赖后,发现Euraka的starter屏蔽掉之后就不再出现这种调包错误的问题。。。
虽说Euraka保证AP,Zookeeper保证CP,根据分布式的CAP理论,C(一致性)、A(可用性)和P(分区容错性)只能3选2,P是必选的,那么Euraka和Zookeeper显然是冲突的,但是这不应该只和RPC那类通讯、选举之类的玩意儿有关系么?为神马会导致调错Jar包?
后端Spring Boot的注册中心是Euraka,坚决不同意更换Zookeeper,大数据的各种组件API又必须使用到Zookeeper。无奈的妥协方式是大数据依旧保持“分布式项目”而非Maven项目,后端冲突的部分单独放置到Maven项目或者干脆编译好调Jar包,变成了四不像。能凑合着跑起来,问题最终也就不了了之了,毕竟甲方爸爸魔改的Eclipse【号称Java Unified Platform到底封装了什么不为人知的秘密】能凑合着用就行,咱也不敢多想,咱也不敢多问,打探太多不合适。自带的汤姆猫还是老掉牙的5,现在已经出到Tomcat10了吧,经常喜欢和虎鲸Logo的HBase因为Log4J日志版本冲突,一步一个坑。
开源还是有好处的,起码能快速定位问题,尤其是可以修改Bug重新编译。闭源就没这么方便了。
谨以此文纪念笔者差点被开除的Bug,以及鏖战凌晨的艰苦时光。现在不用天天被乙方爸爸督促着“今天搞不定就开除”,还是幸福的。















 4708
4708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









