







从插入开始分析
这是插入的源码,网上有很多分析插入的帖子,但是代码都只贴了一半,总觉得哪里不完整,
因为我学艺不精,所以分析有错误请见谅,先贴源码(只分析了插入部分,全流程这里有个博主写的不错https://blog.csdn.net/qq_35703848/article/details/103055440)
源码后附有对hash冲突后的一点理解
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
//算hash
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
//找出具体的桶,实际上就是B的低2的B次方位。
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
//找出具体的桶
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
//计算顶部hash
top := tophash(hash)
//待插入的位置、k、v
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
//loop会一直循环到所有溢出桶遍历完成
bucketloop:
for {
//8个位置遍历
for i := uintptr(0); i < bucketCnt; i++ {
//如果i不等于tophash
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
//如果tophash[i]是空的,结束循环,是新增加数据
if b.tophash[i] == emptyRest {
break bucketloop
}
//如果不是空的继续
continue
}
//tophash等于hash
//获取当前位置对应的key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
continue
}
// already have a mapping for key. Update it.
//更新这个key value
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// *******啥都没找到,插入是新增操作
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
//桶满了,新申请一个桶
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/elem at insert position
// 插入新k
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
// 插入新v
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
总结:(可能我的理解有问题,需要各位大神指教)
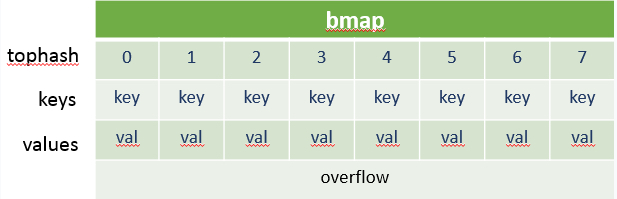
贴一个网上的bmap的原型
插入过程如下
假如插入 A["aaa"] = "aaa"
1 算出aaa的hash
2 用低2^b找出具体桶
3 用高8位遍历tophash,
3.1 如果tophash和key的hash不同 有emptyRest,代表是空桶,结束遍历 通过break bucketloop,到106行直接在目标位置插入kv
3.2 如果tophash和key的hash不同 continue
4 如果找到了==tophash,并且key相等,就更新
--------------------------------------------------
接下来是我自己的看代码的一个推断,如果是错的希望留言改正
接下来插入 A["aaaaa"] = "aaa"
假设 aaaaa和hash 和aaa相同
1 算出aaa的hash
2 用低2^b找出具体桶
3 用高8位遍历tophash,
4 如果找到了==tophash,但是key不同
if !t.key.equal(key, k) {
continue
}
继续下一个次,直到找出一个新的空位,插入
也就是说,一个bucket中可以包含8个tophash,但是8个tophash可能出现是相同的,只要k,v不同就好了















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









