









文章目录
1.采集任务分析
1.1 信息源选取
采集信息目标:大学生实习信息
采集目标网站:实习网 https://www.shixi.com/
采集结果: json格式
robots.txt检查
https://www.shixi.com/robots.txt
User-agent: *
Disallow: http://us.shixi.com
Disallow: http://eboler.com
Disallow: http://www.eboler.com
Disallow: http://shixigroup.com
Disallow: http://www.shixi.com/%7B%7B_HTTP_HOST%7D%7D
Disallow: http://www.shixi.com/index/index
Disallow: http://www.shixi.com/index
Disallow: https://api.app.shixi.com
Disallow: https://api.wechat.shixi.com
大概浏览了一下,发现里面直接把后台登录的网站…app的请求接口直接列了出来?
最终,发现该协议并未禁止我们采集search页面的数据。
1.2 采集策略
选择爬取入口,找到了search的主页面,发现该处的实习信息分布十分有规律,因此选择从此入手。
https://www.shixi.com/search/index
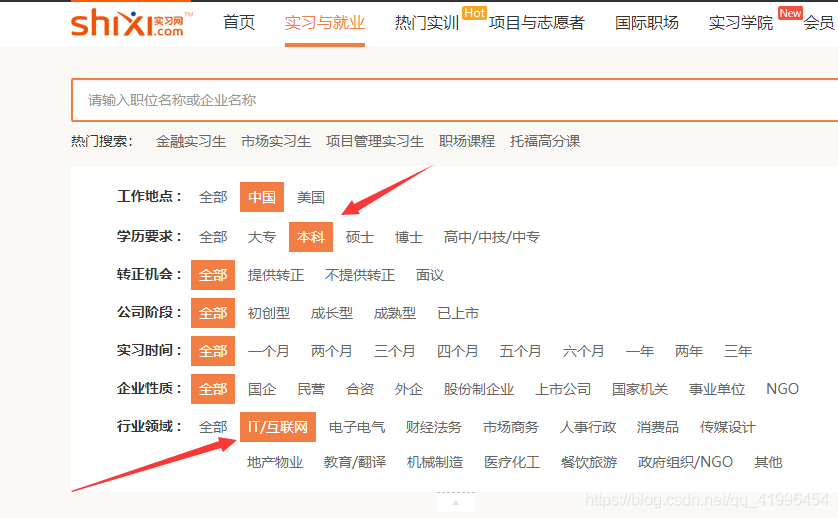
第一页:
https://www.shixi.com/search/index?key=&districts=0&education=70&full_opportunity=0&stage=0&/%20practice_days=0&nature=0&trades=317&lang=zh_cn&page=1
第二页:
https://www.shixi.com/search/index?key=&districts=0&education=70&full_opportunity=0&stage=0&/%20practice_days=0&nature=0&trades=317&lang=zh_cn&page=2
第1000页
https://www.shixi.com/search/index?key=&districts=0&education=70&full_opportunity=0&stage=0&/%20practice_days=0&nature=0&trades=317&lang=zh_cn&page=1000
很明显,url中的param的page决定了当前页数,其他的param则是用于筛选等。
经过观察,且该网站没有使用ajax等异步加载信息的技术,使用request,加上合适的请求头就能成功获取到包含有目标信息的response。
因此决定使用scrapy框架来进行爬取,采集思路如下:
①按照page参数生成待爬取主页index_url的列表,例如生成1-100页的index_url;
②对列表中的每一个index_url,进行GET请求,得到对应的index_response(状态码为2xx或3xx);
③对每一个index_response,解析出详情工作链接detail_url,按照实习网的布局看,每页有10条岗位信息,即一个index_response可以解析出10条detail_url;
④对每个detail_url进行GET请求,然后对detail_response进行解析,获取每个岗位的各种信息;
⑤对每个岗位,将其对应信息写入json文件,一个岗位为一个json对象{}
2.网页结构与内容解析
2.1 网页结构
首先查看请求的目标网址
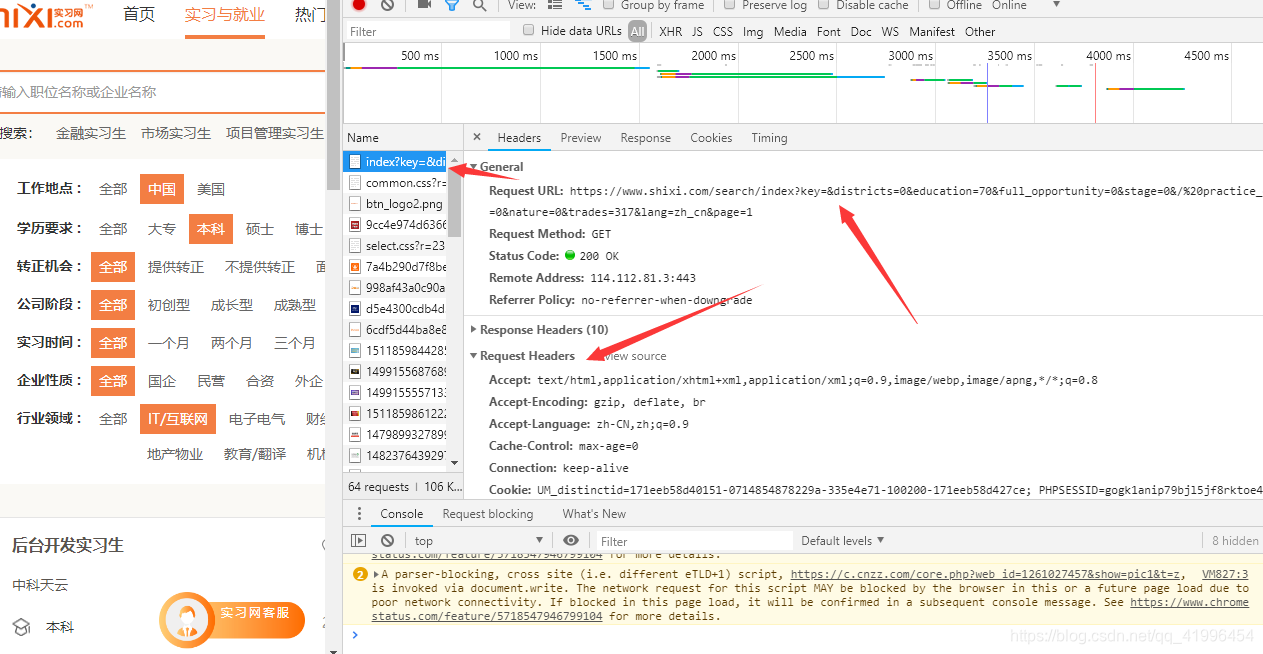
确定目标url如下
https://www.shixi.com/search/index?key=&districts=0&education=70&full_opportunity=0&stage=0&/%20practice_days=0&nature=0&trades=317&lang=zh_cn&page=1
使用requests库请求
def get_html():
'''
可以尝试去掉headers中的某些参数来查看哪些参数是多余的
'''
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "UM_distinctid=171eeb58d40151-0714854878229a-335e4e71-100200-171eeb58d427ce; PHPSESSID=3us0g85ngmh6fv12qech489ce3; \
Hm_lvt_536f42de0bcce9241264ac5d50172db7=1588847808,1588999500; \
CNZZDATA1261027457=1718251162-1588845770-https%253A%252F%252Fwww.baidu.com%252F%7C1589009349; \
Hm_lpvt_536f42de0bcce9241264ac5d50172db7=1589013570",
"Host": "www.shixi.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400",
}
url = "https://www.shixi.com/search/index?key=&districts=0&education=70&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=317&lang=zh_cn&page=1"
response = requests.get(url=url, headers=headers)
print(response.text)
在渲染好的html代码中,一个岗位对应一个<div class="job-pannel-list">
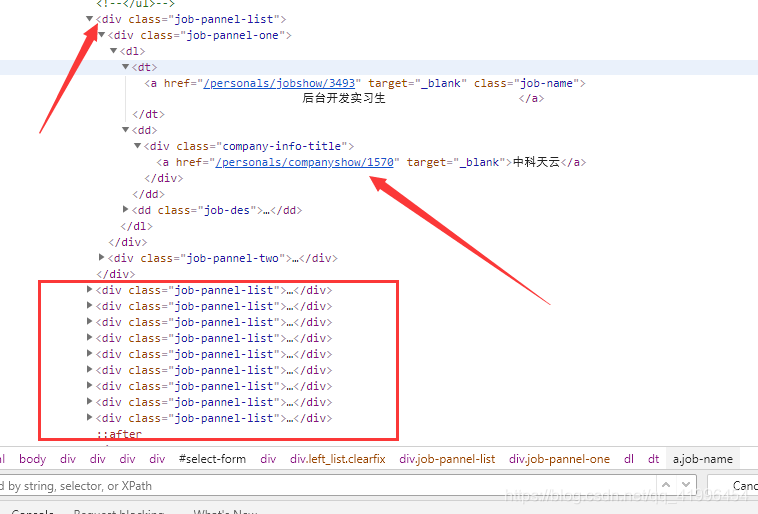
2.2 内容解析
def my_parser():
etree = lxml_html.etree
with open('./shixiw01.html', 'r', encoding='utf-8') as fp:
html = fp.read()
html_parser_01 = etree.HTML(text=html)
html_parser_02 = lxml_html.fromstring(html) # 将字符串转成Element类
page_num = int(html_parser_01.xpath('//li[@jp-role="last"]/@jp-data')[0])
print(page_num)
jobs = html_parser_02.cssselect(".left_list.clearfix .job-pannel-list")
print(jobs)
# 输出结果 得到总共有2520页 一个有10个job
2520
[<Element div at 0x2500bb6da48>, <Element div at 0x2500c394f98>, <Element div at 0x2500c394c28>, <Element div at 0x2500c394e08>, <Element div at 0x2500c394e58>, <Element div at 0x2500c394ea8>, <Element div at 0x2500c394ef8>, <Element div at 0x2500c394f48>, <Element div at 0x2500c39c048>, <Element div at 0x2500c39c098>]
对job信息的提取,这里使用的是css选择器
for job in jobs:
item = dict()
# 工作名称
item['work_name'] = job.css("div.job-pannel-one > dl > dt > a::text").get().strip()
# 所在城市
item['city'] = job.css(".job-pannel-two > div.company-info > span:nth-child(1) > a::text").get().strip()
# 公司名称
item['company'] = job.css(".job-pannel-one > dl > dd:nth-child(2) > div > a::text").get().strip()
# 工资
item['salary'] = job.css(".job-pannel-two > div.company-info > div::text").get().strip().replace(' ','')
# 学历要求
item['degree'] = job.css(".job-pannel-one > dl > dd.job-des > span::text").get().strip()
# 发布时间
item['publish_time'] = job.css(".job-pannel-two > div.company-info > span.job-time::text").get().strip()
# 详情链接
next = job.css(".job-pannel-one > dl > dt > a::attr('href')").get()
url = response.urljoin(next)
item['detail_url'] = url
'''
岗位描述则要进入到detail_url中解析
# 岗位描述
description = response.css("div.work.padding_left_30 > div.work_b::text").get().split()
description = ''.join(description)
'''
3.采集过程与实现
本次采集过程中,我使用的是scrapy爬虫框架,版本为Version: 1.6.0。
3.1 编写Item
首先要明确,该爬取那些信息,经过之前的观察,明确了有如下的信息可以被爬取到
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ShiXiWangItem(scrapy.Item):
# 详情链接
detail_url = scrapy.Field()
# 工作名称
work_name = scrapy.Field()
# 所在城市
city = scrapy.Field()
# 公司名
company = scrapy.Field()
# 工资
salary = scrapy.Field()
# 学历要求
degree = scrapy.Field()
# 发布时间
publish_time = scrapy.Field()
# 职位描述
description = scrapy.Field()
3.2 编写spider
# -*- coding: utf-8 -*-
import scrapy
from ..items import ShiXiWangItem
# from scrapy.linkextractors import LinkExtractor
# from scrapy.spiders import CrawlSpider, Rule
class ShixiwangSpider(scrapy.Spider):
name = 'shixiwang'
# 设置允许爬取的域
# allowed_domains = ['https://www.shixi.com/']
# spider启动时第一个爬取的url
# start_urls = ['https://www.shixi.com/search/index']
def __init__(self):
super().__init__()
# 起始网页
self.base_url = 'https://www.shixi.com/search/index?key=&districts=0&education=70&full_opportunity=0&stage=0&\
practice_days=0&nature=0&trades=317&lang=zh_cn&page={page}'
# 计数器
self.item_count = 0
def closed(self, reason):
print(f'爬取结束,总共有{self.item_count}条实习岗位数据')
def start_requests(self):
# base_url = "https://www.shixi.com/search/index?key=大数据&page={}"
# dont_filter=True : 避免第一页的请求因为重复而被过滤掉
yield scrapy.Request(url=self.base_url.format(page=1), callback=self.set_page, dont_filter=True)
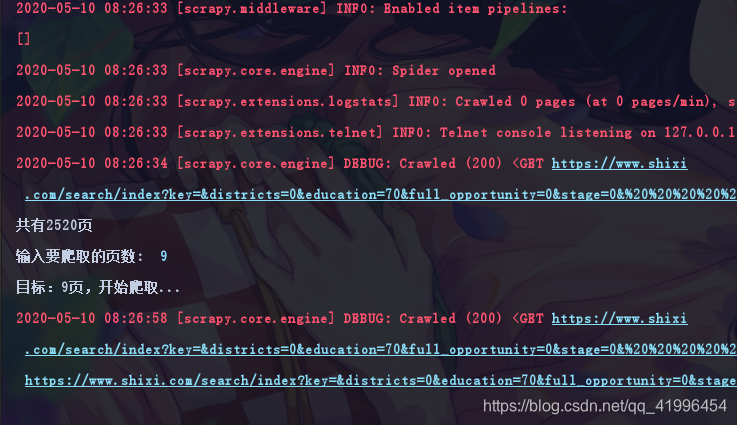
def set_page(self, response):
page_num = int(response.xpath('//ul[@id="shixi-pagination"]/@data-pages').get())
print(f'共有{page_num}页')
targe_page = int(input('输入要爬取的页数: ').strip())
print(f'目标:{targe_page}页,开始爬取...')
for page in range(1, targe_page + 1):
yield scrapy.Request(url=self.base_url.format(page=page), callback=self.parse_index)
def parse_index(self, response):
try:
# 该页面上的所有工作列表
jobs = response.css(".left_list.clearfix .job-pannel-list")
for job in jobs:
item = dict()
# 工作名称
item['work_name'] = job.css("div.job-pannel-one > dl > dt > a::text").get().strip()
# 所在城市
item['city'] = job.css(".job-pannel-two > div.company-info > span:nth-child(1) > a::text").get().strip()
# 公司名称
item['company'] = job.css(".job-pannel-one > dl > dd:nth-child(2) > div > a::text").get().strip()
# 工资
item['salary'] = job.css(".job-pannel-two > div.company-info > div::text").get().strip().replace(' ',
'')
# 学历要求
item['degree'] = job.css(".job-pannel-one > dl > dd.job-des > span::text").get().strip()
# 发布时间
item['publish_time'] = job.css(".job-pannel-two > div.company-info > span.job-time::text").get().strip()
# 详情链接
next = job.css(".job-pannel-one > dl > dt > a::attr('href')").get()
url = response.urljoin(next)
item['detail_url'] = url
yield scrapy.Request(
url=url,
callback=self.parse_detail,
meta={'item': item},
)
except:
print('解析失败')
def parse_detail(self, response):
# print(response.request.headers['User-Agent'], '\n')
self.item_count += 1
item = response.meta['item']
try:
# 岗位描述
description = response.css("div.work.padding_left_30 > div.work_b::text").get().split()
description = ''.join(description)
except:
description = ''
item['description'] = description
# 完成一个item
yield ShiXiWangItem(**item)
3.3 编写pipeline
pipeline是对item加工处理的地方,通常用于数据清洗和数据保存等。
例如,使用JsonItemExporter导出json格式的数据文件。
from scrapy.exporters import CsvItemExporter, JsonItemExporter, JsonLinesItemExporter
from scrapy import signals
import os
class JSONPipeline(object):
def __init__(self):
self.fp = open("data/data.json", "wb")
self.exporter = JsonItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
self.exporter.start_exporting()
def open_spider(self, spider):
pass
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.exporter.finish_exporting()
self.fp.close()
3.4 设置settings
# 一些主要配置
# 默认使用的请求头
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "UM_distinctid=171eeb58d40151-0714854878229a-335e4e71-100200-171eeb58d427ce; PHPSESSID=3us0g85ngmh6fv12qech489ce3; \
Hm_lvt_536f42de0bcce9241264ac5d50172db7=1588847808,1588999500; \
CNZZDATA1261027457=1718251162-1588845770-https%253A%252F%252Fwww.baidu.com%252F%7C1589009349; \
Hm_lpvt_536f42de0bcce9241264ac5d50172db7=1589013570",
"Host": "www.shixi.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400",
}
# 让蜘蛛在访问网址中间休息xxx秒, 设置请求延迟(间隔)
DOWNLOAD_DELAY = 1
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 最大并发请求数
CONCURRENT_REQUESTS = 10
# 下载器中间件 更换代理 ip cookies等等,在request发送之前进行处理
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'MySpider01.middlewares.Myspider01DownloaderMiddleware': 543,
'MySpider01.middlewares.RandomUserAgentMiddlware': 543,
}
# item处理管道
ITEM_PIPELINES = {
# 'MySpider01.pipelines.Myspider01Pipeline': 300,
# 'MySpider01.pipelines.JsonLinesPipeline': 301,
'MySpider01.pipelines.JsonLinesPipeline': 302,
}
3.5 启动爬虫
# main.py
from scrapy.cmdline import execute
import sys
import os
if __name__ == '__main__':
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(['scrpy', 'crawl', 'shixiwang'])
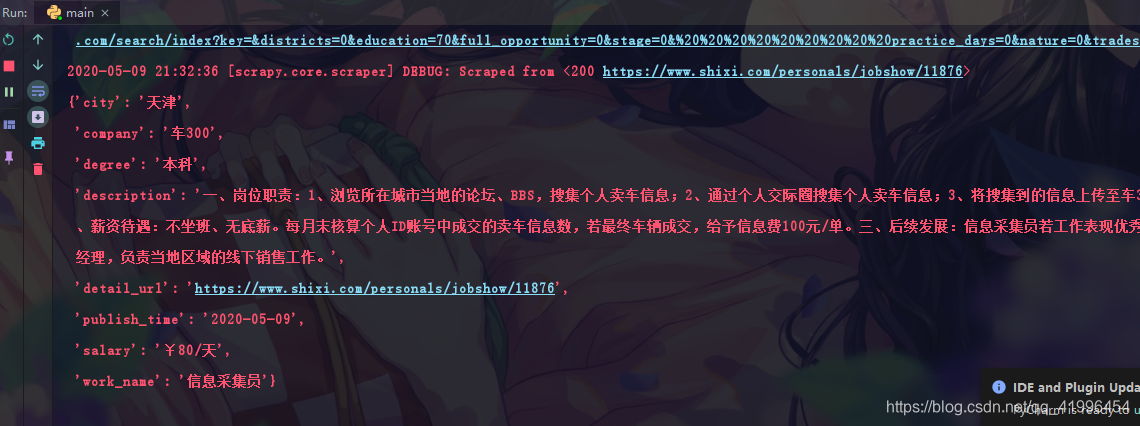
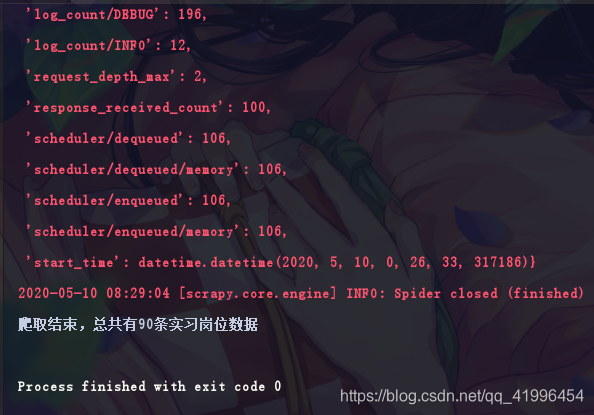
4.采集结果数据分析
4.1 采集结果
得到的部分json如下:
{
"work_name": ".Net软件开发工程师",
"city": "江苏省/苏州市",
"company": "苏州麦粒信息科技有限公司",
"salary": "¥5000/月",
"degree": "本科",
"publish_time": "2020-04-08",
"detail_url": "https://www.shixi.com/personals/jobshow/73974",
"description": "根据产品设计要求,按期完成量化开发任务;"
},
{
"work_name": "业务员",
"city": "广东省/江门市",
"company": "江门市满红网络科技有限公司",
"salary": "¥8000/月",
"degree": "本科",
"publish_time": "2020-03-31",
"detail_url": "https://www.shixi.com/personals/jobshow/74682",
"description": "岗位职责:1、负责公司产品的推广;2、收集客户意见及信息;3、为客户提供准确专业的销售及咨询服务;4、根据市场计划完成销售指标;5、维护客户关系以及客户间长期战略合作计划;6、跟进未成交的客户,促进客户转介绍;7、负责管辖区市场信息的收集8、为客户提供优质的服务职位要求:1、语言表达能力强,语言表达清晰、流畅;2、思维清晰,反应敏捷,具有较强的沟通能力及交际技巧,有亲和力;3、具备一定的市场分析及判断能力,有良好的客户意识;4、有责任心,有团队精神,善于挑战;5、有理想有目标,敢于挑战高薪。待遇:1、每天工作8小时,月休4天,2、有法定假期,3、加班补贴,4、五险一金,5、年终分红"
},
{
"work_name": "产品运营实习生",
"city": "北京市/海淀区",
"company": "北京七视野文化创意发展有限公司",
"salary": "面议",
"degree": "本科",
"publish_time": "2020-04-01",
"detail_url": "https://www.shixi.com/personals/jobshow/22904",
"description": "【岗位职责】"
},
{
"work_name": "数据内容编辑实习生",
"city": "北京市/海淀区",
"company": "北京岁月桔子科技有限公司",
"salary": "¥120/月",
"degree": "本科",
"publish_time": "2020-04-10",
"detail_url": "https://www.shixi.com/personals/jobshow/64212",
"description": "职位描述:"
},
{
"work_name": "人力实习生",
"city": "北京市/海淀区",
"company": "北京职业梦科技有限公司",
"salary": "¥2000/月",
"degree": "本科",
"publish_time": "2020-04-17",
"detail_url": "https://www.shixi.com/personals/jobshow/22980",
"description": "职位描述:"
},
{
"work_name": "内容电商运营",
"city": "北京市/海淀区",
"company": "爱天教育科技(北京)有限公司",
"salary": "¥120/天",
"degree": "本科",
"publish_time": "2020-04-19",
"detail_url": "https://www.shixi.com/personals/jobshow/23020",
"description": ""
}
4.2 简要分析
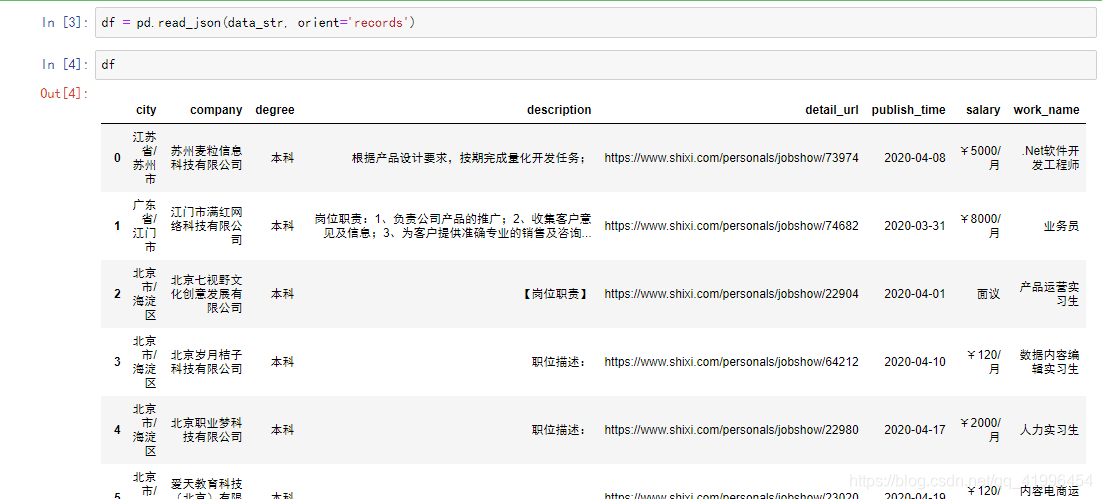
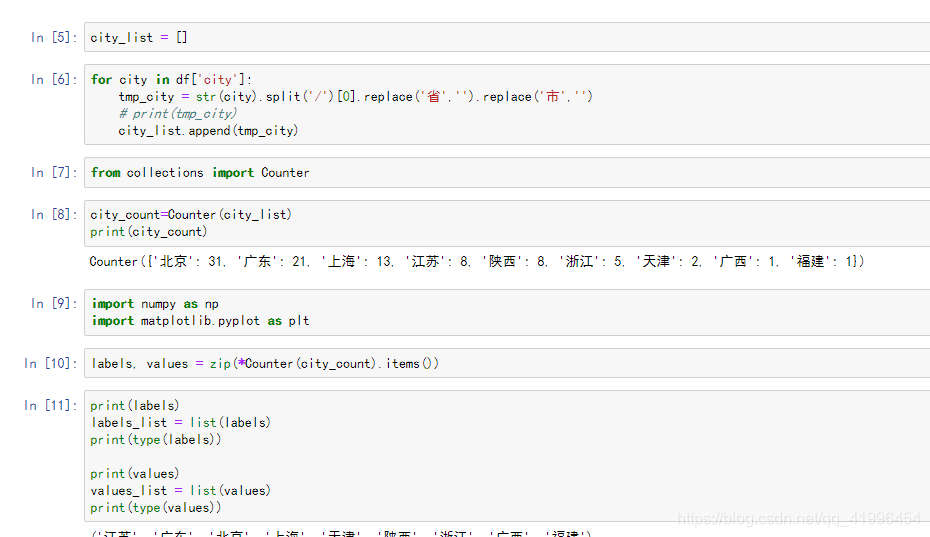

可以看到,互联网相关的工作中,大部分都集中在北上广。
5.总结与收获
-
进一步熟悉了scrapy框架,弄清楚了下载中间件和爬虫中间件的作用,加深了理解,并提高了对应的实践能力;
-
明白了dont_filter参数的使用,可以避免scrapy自动去除掉重复的request;
scrapy.Request(url=self.base_url.format(page=1), callback=self.set_page, dont_filter=True)
- 深入理解了css选择器的使用方法,这对于js+css的网页编写能力提高有很大的帮助;
- 了解了大量的实习信息,对今后的工作有了更多认知和理解。














 1602
1602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









