







1、mysql逻辑架构
1.1、连接层:与客户端(如JDBC)打交道,用户认证及授权
1.2、服务层:
-
DML/DDL/事务
-
优化器:对于本次查询,分析多个索引分析,得到使用哪一个索引最性能最优
-
缓存(会对查询的结果作成key-value存储到缓存中,key是sql及参数,value是数据)
-
解析器:对sql进行语法分析,判断是否有错误
1.3、引擎层:数据的存储及读取方案(InnoDB,MyISAM)。
1.4、存储层:将数据存储在文件系统上,数据的存储路径为/var/lib/mysql/数据库名
2、存储引擎
2.1、 引擎是什么?
引擎是数据库底层组件,数据库系统使用引擎进行增删改查。不同的存储引擎提供不同的存储机制、索引技巧,还可以获得特定的功能
2.2、 Myisam与InnoDb区别:重点
1)查看支持哪些引擎
show engines; 列表方式查看
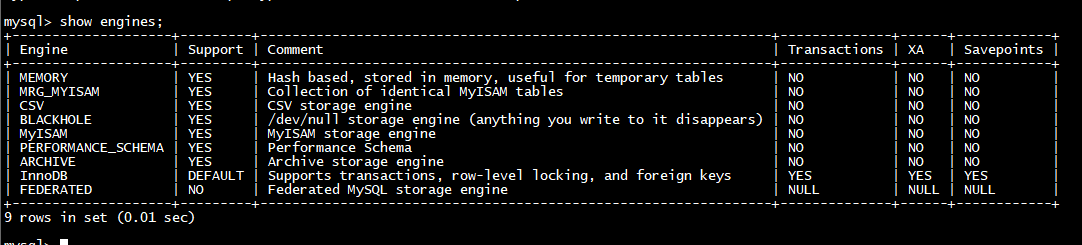
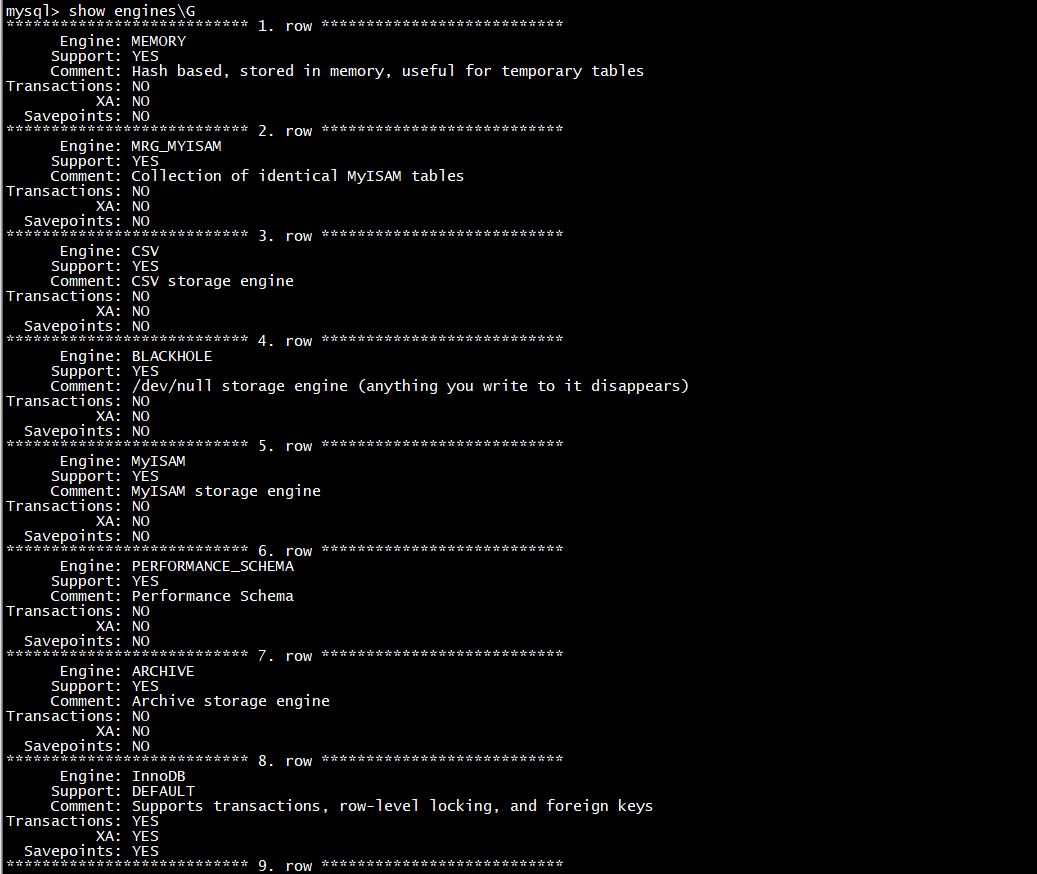
show engines \G 注意没有分号";" ,每一行都单独显示
2)区别
| 功能 | Myisam | Innodb |
| 外键 | No | Yes |
| 事务 | No | Yes |
| 锁 | 仅支持表锁 | 支持行锁表锁 |
| 缓存 | 只对索引缓存 | 对索引和数据都会缓存 |
| 性能 | 强调读写效率高 | 强调数据安全 |
| 主键索引 | 非聚集索引 | 聚集索引(索引与数据放一个引文件idb) |
| 数据文件结构 | 每张表有三个文件: frm文件描述该表的元数据, myd存储表的具体数据, myi存储该表的索引 | 每张表有两个文件: frm也是表的元数据, ibd存储数据和索引数据 |
3、数据库锁
1.1、为什么需要锁
java代码中可加锁,但不彻底,因为在集群环境下,服务器1和2中虽然都对同样代码加锁,只在一个服务器中是串行,对于数据库来说却是两个并发执行。
1.2、 锁种类
-
表锁(一次会将整个表上锁)
特点:
-
锁粒度大,必然会冲突高,进而并发度低
-
不死锁,上锁和解锁速度快
应用场景:
-
适用于读多写少场景。
表锁种类
-
读表锁 :lock table test read;---给test 表加表锁,此时任何线程都不能再对test表增删改,但都可读,,当前线程(cmd客户端窗口)也不能操作其……。
-
写表锁:lock table test write;--此时其他线程不能对该表读和写,当前线程(cmd客户端窗口)可读可写,同时当前窗口与不能操作其他表。
解表锁
-
unlock tables---解锁
-
行锁
独占锁,排他锁,写锁
1. 特点:当一个事物加入排他锁后,当前线程可读可写,不允许其他事务加任何种类锁,也不许修改,但可以读
2. 演示
set autocommit=0;---关闭自动提交,也就是开事务,可用begin;
update test set num=120 where id=1;把这一行加了锁,在提交之前,其他线程只能读,不能写这一行
select * from test where id=1 for update;---作用同上,区别:读取数据,并加锁
注意:如果where后面的条件字段如果没有索引,则相当于整张表加索
3. 排他锁的死锁。表锁不会死锁,只有行锁会发生
A窗口:
set autocommit=0;
select * from test where id=1 for update;
B窗口:
set autocommit=0;
select * from test where id=2 for update;
A窗口:
update test set num=50 where id=2;‐‐‐等待....
B窗口:
update test set num=50 where id=1; ‐‐‐报死锁错误,并让A窗口提交,如何避免?对一行加锁后,就只修改这一行,不要修改其他行
共享锁又称读锁,多个事务对同一行数据共享同一把锁
1. 特点
-
允许其它事务也增加共享锁读取,但不能加排它锁
-
当事务同时增加共享锁时候,事务的更新必须等待先加锁的事务 commit 后才可修改,如果同时并发太大可能造成死锁
2. 共享锁演示
开两个窗口
1窗口执行
begin;
select * from test where id=1 lock in share mode;‐‐‐加行读锁,此时1窗口加了共享锁可读可写,其它线程在不加锁的状态下可读不可写
2窗口执行
update test set num=70 where id=1;此时两2窗口都不能执行写操作。死锁,如何避免?如果加共享锁就不要写,只用来读。

关注快乐程序员公众号,每日分享一点小知识。爱编程,爱生活!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









