







1、后缀树的定义
后缀树(Suffix tree)是一种数据结构,能快速解决很多关于字符串的问题。后缀树的概念最早由Weiner 于1973年提出,既而由McCreight 在1976年和Ukkonen在1992年和1995年加以改进完善。
后缀,顾名思义,甚至通俗点来说,就是所谓后缀就是后面尾巴的意思。比如说给定一长度为n的字符串S=S1S2..Si..Sn,和整数i,1 <= i <= n,子串SiSi+1...Sn便都是字符串S的后缀。
以字符串S=MISSISSIPPI为例,它的长度为11,所以S[1..11], S[2..11], ... , S[11..11]都算S的后缀,我们一般还把空字串也算成后缀。这样,我们一共有如下后缀。对于后缀S[i..n],我们说这项后缀起始于i。
S[1..11], MISSISSIPPI
S[2..11], ISSISSIPPI
S[3..11], SSISSIPPI
S[4..11], SISSIPPI
S[5..11], ISSIPPI
S[6..11], SSIPPI
S[7..11], SIPPI
S[8..11], IPPI
S[9..11], PPI
S[10..11], PI
S[11..11], I
空字串,记为$。
而将这些后缀全部插入前面提到的trie树中并压缩,就得到后缀树啦


两种方法在平方时间内构件后缀树
所谓的平方时间是指O(|T|*|T|),|T|是指字符串的长度。
第一种方法非常显然,就是直接按照后缀树的定义来就可以了,将各个后缀依次插入trie树中,再压缩,总的时间复杂度显然是平方级别的。
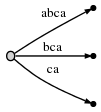
这里给出的是另外一种方法。对照上面MISSISSIPPI的所有后缀,我们注意到第一种方法就是从左到右扫描完一个后缀再从上到下扫描所有的后缀。那么另外一种思路就是,先安位对齐,然后从上到下扫描完每个位,再从左到右扫描下一位。举个例子吧,第一种方法相当于先扫描完后缀1:MISSISSIPPI ,再往下扫描后缀2:ISSISSIPPI 以此类推;而第二种方法相当于从上到下先插入第一个字符M,然后再从上到下插入第二个字符I(有两个),然后再从上到下插入字符S(有三个)以此类推,参见下图。

但是具体怎么操作呢?因为显然每次操作不能是简简单单的插入字符而已!
我们再后头来看看上述过程,形式化一点,我们将原先的字符串表示为
T = t1t2 … tn$,其中ti表示第i个字符
Pi = t1t2 … ti , i:th prefix of T
那么,我们每次插入字符ti,相当于完成一个从Trie(Pi-1)到Trie(Pi)的过程,当所有字符插入完毕的时候我们整个后缀树也就构建出来了。参见下图:插入第二个字符b相当于完成了从Trie(a)到Trie(ab)的过程。。。

那我们怎么做呢?
上图中也提示了,其实我们需要额外保留一个尾部链表,连接着当前的“尾部”节点--也就是对应着Pi的一个后缀的那些个点。我们注意到尾部链表实际上是从表示T[0 .. i]后缀的点指向表示T[1 .. i]后缀的点再指向表示T[2 .. i]后缀的点,以此类推。
也可以看得出来,每次插入一个字符都需要遍历一下链表,第一次遍历的时候链表长度为1(就是根节点),第二次遍历的时候链表长度为2(点a,和根节点,参见Trie(a) ),以此类推,可知遍历的总复杂度是O(|T|*|T|),建立链表也需要O(|T|*|T|),后续压缩Trie也需要O(|T|*|T|),故而整个算法复杂度就是O(|T|*|T|)。
现在说明一下为什么算法是正确的?Trie(Pi-1)存储的是Pi-1的所有后缀,Trie(Pi)存储的是Pi的所有后缀。Pi的后缀可以由Pi-1所有后缀后面插入字符ti,以及后缀ti所构成。那么我们沿着Trie(Pi-1)尾部链表插入字符ti的过程也就是插入Pi的所有后缀的过程,所有算法是正确的。
但是,有没有小失望,毕竟干了这么久发现跟第一种方法相比没有收益)。
其实不用失望,我们做这么多的目的在于通过改进,整个算法可以实现线性的,下面就一步步介绍这种改进算法。
改进第二种算法以实现线性时间建立后缀树
首先一点我们必须直接在后缀树上操作了,不能先建立Trie树再压缩,因为遍历Trie树的复杂度就已经是平方级别了。
我们定义几种节点:
- 叶节点: 出现在后缀树叶子上的节点;
- 显式节点:所有出现在后缀树中的节点。显然叶节点也是显示节点;
- 内部节点:显示节点中不是叶子节点的所有节点;
- 隐式节点:出现在Trie树中但是没有出现在后缀树中的点;(因为路径压缩)
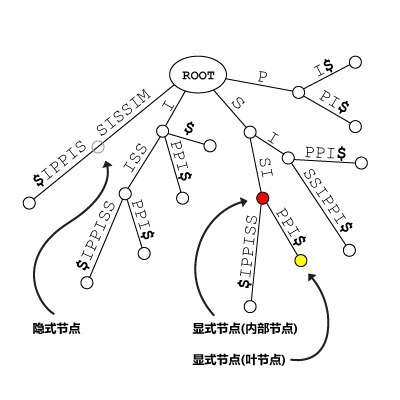
接下来我们来看看前面提到的尾部链表,尾部链表显然包含了当前后缀树中的叶节点以及部分的显式/隐式节点。沿着尾部链表更新:
- 遇到叶子节点时只需往叶子所在的边上面的字符串后面插入字符就好了,不用改变树的结构;
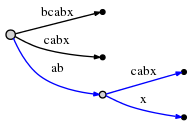
- 遇到显式节点的时候,先看看插入的字符是否出现在显式节点后紧跟的字符集合中(比如上图中红色的显式节点后紧跟的字符集和就是{s,p}),如果插入的字符出现在集合中,那么什么也不要做(是指不用改变树的结构),因为已经存在了;如果没有出现,在显式节点后面增加一个叶子,边上标注为这个字符。
- 遇到隐式节点时,一样,先看看隐式节点后面的字符是不是当前将要插入的字符,如果有则不用管了,没有则需要将当前隐式节点变为显式节点,再增加新叶子。
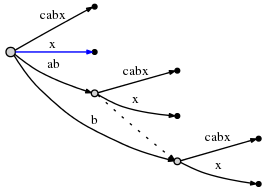
我们用个例子来说明一下怎么操作,为了便于说明隐式节点,我采用Trie树表示:
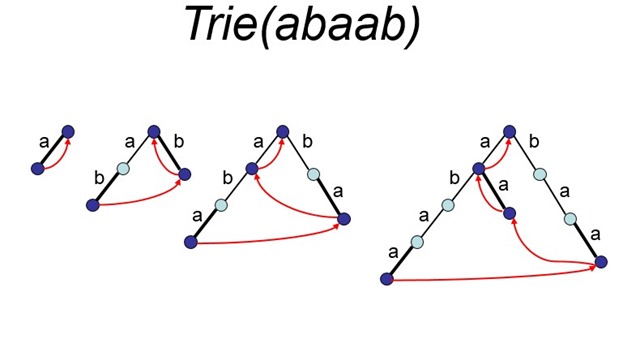

从第三个图到第四个图,沿着尾部链表插入字符a,那么链表第一个节点为叶节点,故而直接在边上插入这个字符就好了;链表第二个节点还是叶子,在边上插入字符就好了;第三个节点是隐式节点,看看紧跟着隐式节点后面的字符,不是a,故而将这个隐式节点变为显式节点,再增加一个叶子;第四个是显式节点(根节点),其紧跟的字符集和为{a,b},a出现在这个集合中,故而不用改变结构了。当然了,链表还是要维护的啊,O(∩_∩)O哈哈~
好了,到此,我们实现了直接在后缀树上操作而完全撇开Trie树了,小有进步啦,~\(≧▽≦)/~啦啦啦,现在开始优化啦!
自动更新叶节点
首先一点,在后缀树上直接操作的时候,边上的字符串就没必要直接存储啦,我们可以存这个字符串对于在原先总的字符串T中的坐标。如上方右边那个图就是将左边第四个图,压缩之后得到的后缀树。[2,4]就表示baa。
这样一来啊,存储后缀树的空间就大大减小了。
接着,我们来看一下啊,后缀树S(Pi-1)中的叶子节点在S(Pi)中也是叶子节点,也就是说”一朝为叶,终身为叶“。而且我们还可以注意到尾部链表的前半部分全是叶子。也就是说如果S(Pi)有k个叶子,那么表示T[0 .. i],……,T[k-1 .. i]后缀的点全是叶子。
我们首先来看一下什么时候后缀会不在叶子上:T[j .. i-1]不在S(Pi-1)叶子上,表明代表该后缀的点之后还有点存在,也就是说T[0 .. i-1]中存在子串S=T[j .. i-1] + c’ ,其中c’不为空。注意一下这是充分必要条件,因为叶子节点后面是不可能还存在点的。
现在我们来证明一下:(ti加入到 S(Pi-1) 的过程)
- 首先,T[0 .. i-1]肯定在叶子上。为什么呢,因为在S(Pi-1)中T[0 .. i-1]是最长的,如果它不在叶子上,那么必然存在比T[0 - i-1]还长的串,矛盾,故而T[0 .. i-1]一定在叶子上。
- 其次,对于任何 j < i-1, 如果 T[j .. i-1] 不在树叶上,那么 T[j+1 .. i-1] 更不可能在树叶上;为什么呢,因为T[j .. i-1]不在叶子上表明T[0 .. i-1]中存在子串S=T[j .. i-1] + c’ ,其中c’不为空。那么T[0 .. i-1]中y也必然存在子串S‘=T[j+1 .. i-1] + c’,因为S’是S的后缀。故而 T[j+1 .. i-1]也不在叶子上
- 于是我们知道k个叶子一定是T[0 .. i],……,T[k-1 .. i]
我们来利用一下上述性质。叶节点每次更新都是把ti插入到叶子所在边的后缀字符串中,所以表示字符串的区间就变成了[ , i]。那么我们还有必要每次都沿着尾部链表去更新么?
我们可以这样,将叶子那个边上的表示字符串的区间用[ , #]来表示,#表示当前插入字符在T中的下标。那么这样一来,叶子节点就自动更新啦。
再利用第二个性质,我们完全就可以不管尾部链表的前k个节点啦。
这是又一大进步!
当新后缀出现在原先后缀树中
我们来看,根据沿尾部链表更新的算法,无论是显式节点还是隐式节点,当带插入字符ti出现在节点的紧跟字符集合的时候,我们就不用管了。也就是说如果T[j .. i]出现在S(Pi-1),也就是S(T[0 .. i-1]),中的时候,我们就不用改变树的结构了(当然需要还调整一些参数)。
我们再来看,对于任何 j < i-1,如果T[j .. i]出现在S(T[0 .. i-1])中,那么T[j+1 .. i]也必然出现在S(T[0 .. i-1])中。下面给出证明:
- 首先我们知道T[0..i-1] 的所有后缀都在后缀树中。
- 其次,T[0..i-1] 的任意子串都可以表示为它的某一个后缀的前缀。
- 所以 T[0..i-1] 的所有子串都在后缀树中。
- T[j+1 .. i] 是 T[j..i] 的子串, T[j..i] 又是 T[0..i-1] 的子串(因为T[j .. i]出现在S(T[0 .. i-1])中),所以 T[j+1 .. i] 也是 T[0..i-1] 的子串。
- 所以后缀树中存在 T[j+1 .. i]
这也就是说如果尾部链表中某一个节点所代表的后缀加上ti,也就是T[j .. i],出现在S(T[0 .. i-1])中,那么链表后面的所有节点代表的后缀加上ti也都出现在S(T[0 .. i-1])中。
故而所有这些点,无论是显式还是隐式节点都可以不用管了。
这又是一个大优化!
综合上面两个优化,我们知道事实上我们只需要处理原先尾部链表的中间一段节点就可以了,对于这些节点而言,每处理一次必定增加一个新叶子(为什么呢,因为这些节点既不是叶子节点,又不满足显或是隐式节点不用增加叶子的条件)。而”一朝为叶,终身为叶“,我们最终的后缀树S(T[0 .. n])只有n个叶子(其中tn=)。(为什么呢,因为不可能存在子串S = T[j .. n]+c’,因为这要求子串中之后还有字符,这是办不到的),这也就是说整个建树过程中我们一共只需要在尾部链表上处理n次就可以了,这是一个好兆头!
种种迹象表明我们快到O(|T|)时间了,原理就先说这么多了。
2、后缀树实现
上文中提到我们最终只是需要沿着去除头尾之后的“尾部链表”以及根节点更新增加节点就好了。但是我们怎么来做呢?带着这个问题,正式进入我们的实现环节!
首先引入两个概念:
- 当前活跃点active point:这是一个三元组包含了三个信息(活跃点,活跃边,活跃半径)。初始值为(root,’\0x’,0),代表活跃点为根节点,没有活跃边,活跃长度为0;
- 计数器remainder: 记录我们在当前阶段需要插入的叶子节点数目。注意到我们每次插入都会增加新的叶子节点,具体原因见上一篇文章。初始值为1,每次进入新阶段增加1,每次从活跃点新增一个叶子节点减少1。
我们每一阶段的目标都是把当前阶段的所有后缀插入到后缀树中。至于叶子节点,我们跟上文所说的一样,采用 [ , #]格式,每到一个新的阶段自动更新。
好了,下面给出构建后缀树的三个定理:
规则一(活跃点为根节点时候的插入):
- 插入叶子之后,活跃节点依旧为根节点;
- 活跃边更新为我们接下来要更新的后缀的首字母;
- 活跃半径减1;
规则二(后缀链表):
- 每个阶段,当我们建立新的内部节点并且不是该阶段第一次建立内部节点的时候,我们需要用指针从当前内部节点指向本阶段最近一次建立的内部节点
规则三(活跃点不为根节点时候的插入):
- 如果当前活跃点不是根节点,那么我们每次从活跃点新增一个叶子之后,就要沿着后缀链表到达新的点,并更新活跃节点;如果不存在后缀链表了,我们就转移到根节点,将活跃节点更新为根节点。活跃半径以及活跃边不变。
是不是感觉这里面的“后缀链表”跟我们之前谈到的尾部链表非常相似啊,而且这个活跃点的概念是不是跟之前的尾部链表也有千丝万缕的关系呢,哈哈。留这些疑问!待会儿再说。我们先来通过一个例子来具体体验一把怎么建立后缀树。例子来自上文中提到的那篇原文。
我们为字符串abcabxabcd建立后缀树吧。
一开始活跃点三元组为(root,’\0’,0),计数器remainder为1;
第一阶段,插入字符a,#=1。
我们从当前活跃节点(根节点)出发看看有没有那个边的第 0(活跃半径) 个字母是a,发现没有,于是按照规则一插入叶子节点。活跃边更新为接下来要插入的后缀首字母,但是由于已经没有需要插入的了,故而活跃边也不变便;由于活跃半径已经是0,故而不用减1了;计数器remainder减少1变成0。我们获得了这样一棵树
![]()
因为当前#=1,故而上图的这个后缀树就是下图(注意一下,区间[0,1]的含义是第一个字符,这点跟之前的表示方法不太一样)
此时三元组为(root,’\0’,0),remainder为0;
第二阶段,插入字符b,#=2; 三元组不变仍为(root,’\0’,0),remainder增加1,等于1;
我们从当前活跃节点(根节点)出发看看有没有哪个边的第 0(活跃半径) 个字母是b,发现没有,于是按照规则一插入叶子节点。情况同上,三元组为(root,’\0’,0),remainder为0;我们获得了这样一棵树:

因为#=2,故而左图等同于右图。
第三阶段,插入字符c;#=3;三元组不变仍为(root,’\0’,0),remainder增加1,等于1;
跟第二阶段类似,三元组为(root,’\0’,0),remainder为0;我们获得了这样一棵树:


因为#=3,故而左图等同于右图。
第四阶段,插入字符a; #=4; 三元组为(root,’\0’,0),remainder增加1,等于1;
这时,我们从当前活跃节点(根节点)出发看看有没有哪个边的第 0(活跃半径) 个字母是a。结果发现了!!!那么此时,我们更新三元组为(root, ‘a’, 1), remainder不变。更新完系数之后,我们就进入下一阶段了。
为什么?还记得上一篇文章中,”当新后缀出现在原先后缀树中”是怎么办么?哈哈,就是更新系数后不管了。
我们获得了这样一棵树:
![clip_image005[1]](https://images0.cnblogs.com/blog/465162/201312/21153127-15ae3e05ddee4e7b91cb3a895a31ef5d.png)
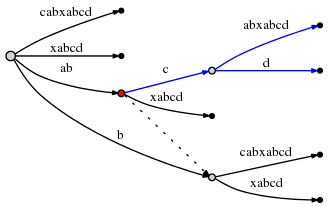
看出来了吧,树的形状没有变,但是叶子节点的边自动更新了。这也就是上一篇文章中提到了自动更新叶节点。按上文的说法这里应该有尾部链表从第一个点(边为abca)指向第二个点(边为bca),第二个点指向第三个点(边为ca),第三个点指向根节点,但是呢,显然这个链表上除了根节点都是叶节点,没有保存的必要啊。所以这里没有看到“尾部链表”的痕迹。这也是一种优化,但是,后面你会见到它的。哈哈,所谓神龙见首不见尾!我们接着来看。
第五阶段,插入字符b;#=5; 三元组为(root,’a’,1),remainder增加1,等于2;
这时,我们从当前活跃点(根节点)出发看看边首字母为a(活跃边)的第1(活跃半径)个字母是b。结果又发现了!!
注意一下,之前因为没有明确的活跃边,故而可以随便找边,但是确定了活跃边之后就只能沿着活跃边来找了。
因为这一次我们需要插入的后缀除了b之外,还有上次剩余的,故而我们需要插入的后缀是ab ,b。活跃边不变,只是活跃半径需要增加1,等于2。于是三元组变成了(root,’a’,2),计数器remainder不变,仍然为2。
我们获得了这样一棵树:

第六阶段,插入字符x; #=6; 三元组为(root,’a’,2), remainder增加1,等于3;我们需要插入的后缀有abx,bx,x
这时,我们从当前活跃点(根节点)出发看看沿着活跃边(边首字母为a)的第2(活跃半径)个字母是不是x。结果没发现!
于是我们按照规则一,从当前生长点(活跃点沿着活跃边走活跃半径个字符)增加一个叶子,插入x,也就是代表了abx。
获得了这个树:
插入完abx之后我们需要插入bx了,但是我们需要先调整三元组。活跃边首字母就应该变成b了,活跃半径减少1,于是我们的三元组变成了(root,’b’,1),remainder减少1,等于2。根据规则一,我们再从当前活跃点(根节点)出发看看沿着活跃边(边首字母为b)的第1(活跃半径)个字母是不是x。结果不是!于是再按照规则一,从当前生长点(活跃点沿着活跃边走活跃半径个字符)增加一个叶子,插入x,也就代表了bx。
我们获得了这个树:

但是还没完,因为这已经是我们在此阶段建立的第二个内部节点了,根据规则二,故而我们需要建立”后缀链表”。此时三元组变成(root,’x’,0), remainder减少1,等于1。

接下来就要插入x了。此时活跃半径已经是0了,于是活跃边一定是空的了,我们查看根节点所有边中首字母有没有是x的,结果没有,于是插入x。从当前生长点(此时因为活跃半径是0,活跃点就是生长点)增加叶子,插入x。得到下面这颗树。根据规则一,此时的三元组变成了(root, ‘\0’, 0),remainder减少1,等于0。此阶段顺利结束了。
第七阶段,插入字符a;#=7;三元组为(root, ‘\0’, 0),remainder增加1,等于1。需要增加的后缀只有一个就是a;
还是一样,鉴于活跃半径为0,我们从看看根节点有那个边的首字母为a,结果发现了。于是我们调整三元组为(root,’a’,1)。结束
第八阶段,插入字符b;#=8;三元组为(root, ‘a’, 1),remainder增加1,等于2。需要增加的后缀有两个ab,b;
我们先从当前活跃节点(根节点)出发,沿着活跃边的第1(活跃半径)个字符是不是b,结果是!于是我们调整三元组为(root, ‘a’, 2)。
注意了,我们已经来到了一个内部节点而不再跟以前一样停留在边上,于是我们再次调整三元组(类似于初始化)为(node1,’\0’,0)。这里,node1代表了上图中从根节点出发经过边ab,到达的那个点。
第九阶段,插入字符c;#=9;三元组为(node1,’\0’,0),remainder增加1,等于3。需要增加的后缀有三个abc,bc,c;
鉴于活跃半径为0,我们直接看看当前活跃点(也就是node1)的边有没有以c为首字母的。结果有,于是更新三元组(node1,’c’,1)。注意一下虽然此时应该最先插入后缀abc,但是由于活跃点已经变化了,我们以当前活跃点为基准,故而活跃边以’c’标志。
第十阶段,插入字符s;;#=10;三元组为(node1,’c’,1),remainder增加1,等于4。需要增加的后缀有四个abcd,bcd,cd,d;
我们从当前活跃点node1出发沿着活跃边c,第1个字符是否是d,发现不是!于是在当前生长点(活跃点沿着活跃边前进活跃半径个字符)增加一个叶子,得到下图的树。
由于当前活跃点不是根节点,所以按照规则三,我们沿着后缀链表前进,更新三元组为(node2,’c’,1),remainder减少1,等于3。node2为下图中的红色点。
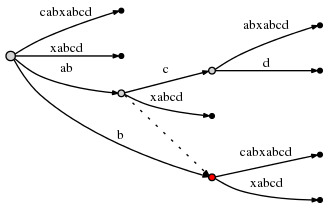
从node2出发沿着活跃边c出发,第1个字符是不是d,发现不是,于是在当前生长点增加叶子。注意此时要按照规则二建立新的后缀链表了。
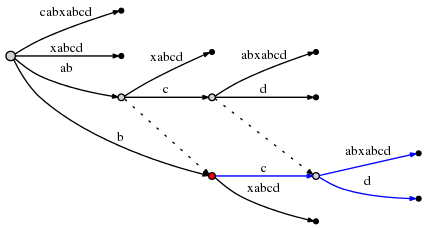
按照规则三,沿着后缀链表,由于已经没有下一个节点了,于是跳回到根节点,更新三元组(root,’c’,1)。remainder减少1,等于2.
从根节点出发沿着活跃边c,第1个字符是不是d?发现不是,于是在当前生长点增加叶子,注意仍按按照规则二建立后缀链表
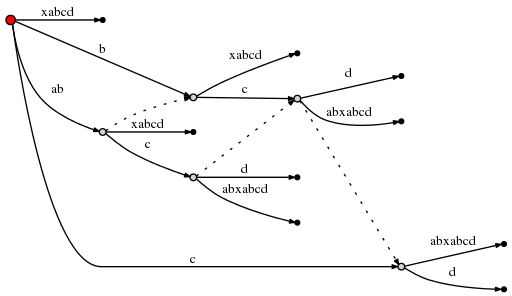
之后按照规则一更新三元组,活跃点不变,当前带插入的后缀是d,故而修改活跃边为d,活跃半径减少1变成0。remainder减少1,等于1。
现在插入后缀d,鉴于活跃半径为0,看看根节点有没有边是以d为首字母的,发现没有!于是增加叶子。

至此,全都结束了!后缀树建立完毕
看完上面的建树过程,有点晕吧,哈哈,其实我也是。现在来说说上述算法跟上一篇文章提到的方法之间的关联吧。
上一篇文章中我们提到的方法是每次沿着优化后的尾部链表更新,增加叶节点。其实我们这么来看,整个尾部链表是由三部分组成的,第一部分是叶子节点;第二部分是“除根节点外会增加叶子的节点”;第三部分是会导致 新后缀出现在原先后缀树中 的节点,这部分节点对树结构没有影响;所谓优化后的尾部链表是指去除第一部分和第三部分。当然喽第二部分第三部分都可能是空的。这样一来其实优化后的尾部链表由两部分组成:“尾部链表”的一部分(在本算法中就是后缀链表)。但是理论上这么说就可以了,实际上怎么来实现呢?
我们看一下,因为”一朝为叶,终身为叶”,而每次遍历后缀链表的时候都会增加一个叶子,而最终的后缀树也只有|T|个叶子,所以我们一共需要遍历后缀链表|T|次。显然了,后缀链表是很“少”的。故而我们再去保留尾部链表,然后去定位第一个非叶子节点就很划不来了。于是,尾部链表作为一个理解上面的工具,在实践中(上述算法)就不维护啦,我们直接采用后缀链表。
于是乎,我们回过头来看看上述算法。
remainder是计数器,表明到当前阶段还需插入几个后缀,每个阶段增加1,是代表了后缀–从当前将要被插入的字符开始到原始串尾的这个后缀。当也叶子被插入的时候,rremainder减少1。
首先初始化的时候活跃点是根节点,活跃半径是0。于是我们开始准备插入一个字符,如果字符没在根节点的任何一条边(默认为链接各个儿子的边)中出现,那么表明什么意思?表明当前生长点(根节点,所谓生长点就是准备长叶子的点),就是我们“尾部列表中”第二部分的节点,而remainder为1,代表当前只需插入一个叶子,于是插入即可,remainder减少1;如果字符在根节点的某一条边中出现,那么这是什么意思?这表明当前生长点(根节点),是我们第三部分的点,于是我们调整一下当前生长点的位置,这是为什么呢?因为,假设当前要插入的字符是a,下一次要插入b,那么我们这一阶段没插入叶子,下一阶段多了一个“欠债“,就要还要插入ab。那么我们将生长点挪到树中字符a的后面,就意味着我们下一阶段只需要在生长点后面插入字符b就可以了,一步到位,方便快捷。鉴于本阶段没有插叶子,所以remainder不变。调整三元组也是为了”挪动生长点“。
下一次,我们要插入字符b的时候,我们在当前生长点后面找一找有没有b(其实就是为了验证当前生长点是不是后缀链表中的第三部分的点),如果没有,意味着是第二部分的点(因为肯定不是叶节点,又不是第三部分的点),那么就插入叶节点吧,remainder减少1,调整活跃边为下一个需要插入后缀的首字母,也就是b,活跃半径减少1。这也是为了调整生长点(快速找到下一个插入叶子的点)。于是看看根节点哪个边首字母为b,如果没有就插入新节点,如果有就调整生长点(这一块跟前面类似,不再多说)。我们说说另一种情况,就是我们在生长点(root,’a’,1)之后还找到了b,这说明当前生长点是第三部分的点,那么怎么办呢,继续调整生长点为(root,’a’,2)。
假设上一次之后,调整生长点为(root,’a’,2),这一次再插入字符c,remainder增加1,等于3。如果当前生长点后没有c,意味着当前生长点是第二部分的点,于是插入叶子c就好了,代表着”欠债“后缀abc。remaidner减少1,调整生长点为(root,’b’,1),为什么如此确定根节点有某条边是以b为首字母呢?原因是这样的,你看啊,我们活跃半径是2,必然是因为我们刚刚插入的那个后缀abc的前两个字符出现在后缀树中,既然ab出现在了后缀树中,那么依据前文中的原理,b也一定出现在后缀树中。大家发现没有,这个调整生长点的过程是不是太迅速啦。
事实上来说我们就凭借上述的这个过程似乎已经建立后缀树了,但是我们仔细看看,如果定位生长点的时候的这个(root,’a’,2)中的活跃半径不是2,而是一个很大的数字,比如100,那么就算我们知道下一个生长点是(root,’b’,99),真的能定位到准确的生长点么??不一定吧,根节点沿着一条特定的边走99步,可不一定只能到一个点啊,哈哈!
这就是问题所在,所以我们调整生长点为(root,’a’,2)的时候,如果从当前活跃点开始,沿着活跃边走了活跃半径个距离,我们停在活跃边上面一个隐式节点那就没事,要是停到了内部节点node1,那我们就要更新活跃点为这个内部节点啦!然后调整三元组为(node1,’\0’,0)了。这里假设我们将(root,’a’,2)更新为(node1,’\0’,0)。我们再来看一下,假设下一个字符是c,且node1后面有一个边是以c为首字母的,于是更新三元组为(node1,’c’,1);假设我们之后要插入字符x,而从node1开始没有那个边是以x为首字母的,这时候就要插入叶子x了,代表了后缀abcx,我们下一个就要插入后缀bx了,但是怎么定位到下一个生长点?跟前面一样更新生长点为(node1,’b’,0)?
肯定不行啊,因为下一个生长点根本就不在node1的子树里面。为什么?因为node1的子树里面任何一个点代表的字符串都是以ab(也就是根节点到node1那个边),而我们插入的是bcx。那么下一个生长点是什么呢?我们猜测一下啊,应该是(node2,’c’,1)其中根节点到node2的路径上面的字符是b!这样就可以啦。首先我们来明确一下存不存在这样一个结果node2的生长点?是存在的,因为既然后缀树中有ab这个内部节点(注意我的用词,ab已经成为i类不节点了,而不是刚刚建立的),那么必然有b这个内部节点(因为假设node1后面的两个儿子分别为x,y,那么后缀树中存在abx,和aby那么也必然存在bx,by所以也必然存在node2);同时后缀树中有字符串abc,那么必然也有串bc,于是证明是有的!下一个问题是,我们怎么快速将生长点从(node1,’c’,1)定位到(node2,’c’,1),所以我们想要是有一条指针从node1指向node2就好了,所以我们应该之前建立这个后缀链表这样下次就方便了。
什么时候建立呢?我们来看啊,当初我们建立ab这个内部节点的时候,内部节点或者是已经存在了或者下一步就存在(注意跟上面的对比啊,这次是说我们当初建立ab内部节点的时候,所以这个内部节点是刚建立的,故而内部节点b暂时还不一定存在)为什么说下一步就存在呢?(因为: 如果 aS 停在一个内部节点上面,也就是 aS 后有分支,那么当前的 T[0 .. i-1] 肯定有子串 aS+c 以及aS+d ( c 和 d 是不同的两个字符) 这两个不同的子串,于是肯定也有 S+c 以及 S+d 两个子串了。至于“下次扩展时产生”的这种情况,则发生在已经有 aS+c 、 S+c ,刚加入 aS+d (于是产生了新的内部节点),正要加入 S+d 的时候。)下面我们来看啊,既然”下一步”内部节点b一定存在了,那就在”下一步”的时候建立指针从内部节点ab指向内部节点b。
当我们走到后缀链表的尾部时候,意味着我们已经处理完毕remainder的前两个(就是从根节点到node1的边长,这两个后缀意味着abcx,bcx)”欠债”。于是我们回到根节点,当然了,活跃边和活跃半径不变。那么为什么此时从根节点出发沿着活跃边走活跃半径个字符就能唯一锁定生长点呢?
答案是这样的,因为啊,我们之前将活跃点更新为node1之后可能还是会更新活跃点,我们将最后更新的活跃点命名为nodeN,此时的三元组为(nodeN,active_edge,active_length),我们知道这个三元组确定的生长点位于nodeN的某条边上的一个隐式节点。我们知道我们路过nodeN这个活跃点的时候,nodeN那边已经存在后缀链接了,所以当我们沿着后缀链接插入叶子,在最终回到根节点时候三元组变为nodeN(root,active_edge,active_length)。一步定位!而且在沿着后缀链表定位生长点的时候也是一步定位!
下面说明一下为什么上述算法是线性的。首先啊,我们来看上面一共涉及到了几个操作:插入叶节点(每次插入消耗常数时间,总叶节点|T|个,故而总时间为O(|T|),建立后缀链表(每次建立一个指针只需要沿着前面建好的后缀链表走一下,然后一步定位,所以每次建立一个指针只需要常数时间;而每次我们沿着后缀链表走都会插入新叶子,故而后缀链表一共也只有|T|这么长,故而一共需要插入O(|T|)次),更新三元组(因为涉及到活跃点的移动,故而我们这么看,没有更新活跃点的时候是常数时间,而更新活跃点的情况有点复杂,我们这么理解:每次更新活跃点都会导致活跃半径相应减小,而活跃半径始在整个建树的过程中最多增加|T|,故而整个更新活跃点所需时间为O(|T|)),其他诸如remainder的调整等等,每次花费常数时间,总和为O(|T|)。综上所述,线性算法如下:
#include <iostream>
#include <stdio.h>
#include <string>
const int oo = 1<<25;
const int ALPHABET_SIZE = 256;
const int MAXN = 5000;
using namespace std;
int root, last_added, pos, needSL, remainder,
active_node, active_e, active_len;
struct node {
/*
There is no need to create an "Edge" struct.
Information about the edge is stored right in the node.
[start; end) interval specifies the edge,
by which the node is connected to its parent node.
*/
int start, end, slink;
int next[ALPHABET_SIZE];
int edge_length() {
return min(end, pos + 1) - start;
}
};
node tree[2*MAXN];
char text[MAXN];
int new_node(int start, int end = oo) {
node nd;
nd.start = start;
nd.end = end;
nd.slink = 0;
for (int i = 0; i < ALPHABET_SIZE; i++)
nd.next[i] = 0;
tree[++last_added] = nd;
return last_added;
}
char active_edge() {
return text[active_e];
}
void add_SL(int node) {
if (needSL > 0) tree[needSL].slink = node;
needSL = node;
}
bool walk_down(int node) {
if (active_len >= tree[node].edge_length()) {
active_e += tree[node].edge_length();
active_len -= tree[node].edge_length();
active_node = node;
return true;
}
return false;
}
void st_init() {
needSL = 0, last_added = 0, pos = -1,
remainder = 0, active_node = 0, active_e = 0, active_len = 0;
root = active_node = new_node(-1, -1);
}
void st_extend(char c) {
text[++pos] = c;
needSL = 0;
remainder++;
while(remainder > 0) {
if (active_len == 0) active_e = pos;
if (tree[active_node].next[active_edge()] == 0) {
int leaf = new_node(pos);
tree[active_node].next[active_edge()] = leaf;
add_SL(active_node); //rule 2
} else {
int nxt = tree[active_node].next[active_edge()];
if (walk_down(nxt)) continue; //observation 2
if (text[tree[nxt].start + active_len] == c) { //observation 1
active_len++;
add_SL(active_node); //observation 3
break;
}
int split = new_node(tree[nxt].start, tree[nxt].start + active_len);
tree[active_node].next[active_edge()] = split;
int leaf = new_node(pos);
tree[split].next[c] = leaf;
tree[nxt].start += active_len;
tree[split].next[text[tree[nxt].start]] = nxt;
add_SL(split); //rule 2
}
remainder--;
if (active_node == root && active_len > 0) { //rule 1
active_len--;
active_e = pos - remainder + 1;
} else
active_node = tree[active_node].slink > 0 ? tree[active_node].slink : root; //rule 3
}
}
int main() {
//
return 0;
}最长回文问题的解决
有了上面的概念,本文引言中提出的查找最长回文问题就相对简单了。咱们来回顾下引言中提出的回文问题的具体描述:找出给定字符串里的最长回文。例如输入XMADAMYX,则输出MADAM。
思维的突破点在于考察回文的半径,而不是回文本身。所谓半径,就是回文对折后的字串。比如回文MADAM 的半径为MAD,半径长度为3,半径的中心是字母D。显然,最长回文必有最长半径,且两条半径相等。还是以MADAM为例,以D为中心往左,我们得到半径 DAM;以D为中心向右,我们得到半径DAM。二者肯定相等。因为MADAM已经是单词XMADAMYX里的最长回文,我们可以肯定从D往左数的字串 DAMX与从D往右数的子串DAMYX共享最长前缀DAM。而这,正是解决回文问题的关键。现在我们有后缀树,怎么把从D向左数的字串DAMX变成后缀 呢?
到这个地步,答案应该明显:把单词XMADAMYX翻转(XMADAMYX=>XYMADAMX,DAMX就变成后缀了)就行了。于是我们把寻找回文的问题转换成了寻找两坨后缀的LCA的问题。当然,我们还需要知道 到底查询那些后缀间的LCA。很简单,给定字符串S,如果最长回文的中心在i,那从位置i向右数的后缀刚好是S(i),而向左数的字符串刚好是翻转S后得到的字符串S‘的后缀S'(n-i+1)。这里的n是字符串S的长度。
可能上面的阐述还不够直观,我再细细说明下:
1、首先,还记得本第二部分开头关于后缀树的定义么: “先说说后缀的定义,顾名思义,甚至通俗点来说,就是所谓后缀就是后面尾巴的意思。比如说给定一长度为n的字符串S=S1S2..Si..Sn,和整数i,1 <= i <= n,子串SiSi+1...Sn便都是字符串S的后缀。”。以字符串S=XMADAMYX为例,它的长度为8,所以S[1..8], S[2..8], ... , S[8..8]都算S的后缀,我们一般还把空字串也算成后缀。这样,我们一共有如下后缀。对于后缀S[i..n],我们说这项后缀起始于i。
S[1..8], XMADAMYX,也就是字符串本身,起始位置为1
S[2..8], MADAMYX,起始位置为2
S[3..8], ADAMYX,起始位置为3
S[4..8], DAMYX,起始位置为4
S[5..8], AMYX,起始位置为5
S[6..8], MYX,起始位置为6
S[7..8], YX,起始位置为7
S[8..8], X,起始位置为8
空字串,记为$。
2、对单词XMADAMYX而言,回文中心为D,那么D向右的后缀DAMYX假设是S(i)(当N=8,i从1开始计数,i=4时,便是S(4..8));而对于翻转后的单词XYMADAMX而言,回文中心D向右对应的后缀为DAMX,也就是S'(N-i+1)((N=8,i=4,便是S‘(5..8)) 。此刻已经可以得出,它们共享最长前缀,即LCA(DAMYX,DAMX)=DAM。有了这套直观解释,算法自然呼之欲出:
- 预处理后缀树,使得查询LCA的复杂度为O(1)。这步的开销是O(N),N是单词S的长度 ;
- 对单词的每一位置i(也就是从0到N-1),获取LCA(S(i), S‘(N-i+1)) 以及LCA(S(i+1), S’(n-i+1))。查找两次的原因是我们需要考虑奇数回文和偶数回文的情况。这步要考察每坨i,所以复杂度是O(N) ;
- 找到最大的LCA,我们也就得到了回文的中心i以及回文的半径长度,自然也就得到了最长回文。总的复杂度O(n)。
用上图做例子,i为4时,LCA(4$, 5#)为DAM,正好是最长半径。当然,这只是直观的叙述。
上面大致描述了后缀树的基本思路。要想写出实用代码,至少还得知道下面的知识:
- 创建后缀树的O(n)算法。此算法有很多种,无论Peter Weiner的73年年度最佳算法,还是Edward McCreight1976的改进算法,还是1995年E. Ukkonen大幅简化的算法(本文第4部分将重点阐述这种方法),还是Juha Kärkkäinen 和 Peter Sanders2003年进一步简化的线性算法,都是O(n)的时间复杂度。至于实际中具体选择哪一种算法,可依实际情况而定。
- 实现后缀树用的数据结构。比如常用的子结点加兄弟节点列表,Directed 优化后缀树空间的办法。比如不存储子串,而存储读取子串必需的位置。以及Directed Acyclic Word Graph,常缩写为黑哥哥们挂在嘴边的DAWG。
3、后缀树的应用
后缀树的用途,总结起来大概有如下几种
- 查找字符串o是否在字符串S中。
方案:用S构造后缀树,按在trie中搜索字串的方法搜索o即可。
原理:若o在S中,则o必然是S的某个后缀的前缀。
例如S: leconte,查找o: con是否在S中,则o(con)必然是S(leconte)的后缀之一conte的前缀.有了这个前提,采用trie搜索的方法就不难理解了。。 - 指定字符串T在字符串S中的重复次数。
方案:用S+’$'构造后缀树,搜索T节点下的叶节点数目即为重复次数
原理:如果T在S中重复了两次,则S应有两个后缀以T为前缀,重复次数就自然统计出来了。。 - 字符串S中的最长重复子串
方案:原理同2,具体做法就是找到最深的非叶节点。
这个深是指从root所经历过的字符个数,最深非叶节点所经历的字符串起来就是最长重复子串。
为什么要非叶节点呢?因为既然是要重复,当然叶节点个数要>=2。 - 两个字符串S1,S2的最长公共部分
方案:将S1#S2$作为字符串压入后缀树,找到最深的非叶节点,且该节点的叶节点既有#也有$(无#)。
本文转载自:















 2102
2102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









