









最近在复现 LineVul 这篇文章的实验,本文主要用于简化文章复现流程和记录复现过程中出现的问题。
1 安装依赖环境
pip install gdown
pip install transformers
pip install captum
pip install torch torchvision torchaudio
pip install numpy
pip install tqdm
pip install scikit-learn
pip install pandas
pip install tokenizers2 下载数据
#### 下载数据集 #### (需要科学上网)
cd data/big-vul_dataset
gdown https://drive.google.com/uc?id=1h0iFJbc5DGXCXXvvR6dru_Dms_b2zW4V
gdown https://drive.google.com/uc?id=1ldXyFvHG41VMrm260cK_JEPYqeb6e6Yw
gdown https://drive.google.com/uc?id=1yggncqivMcP0tzbh8-8Eu02Edwcs44WZ
cd ../..
#### 下载模型 ####
cd linevul/saved_models/checkpoint-best-f1
gdown https://drive.google.com/uc?id=1oodyQqRb9jEcvLMVVKILmu8qHyNwd-zH
cd ../../..
#### 下载 codebert-base ####
cd linevul
mkdir microsoft
cd microsoft
git lfs install
git clone https://huggingface.co/microsoft/codebert-base3 实验复现
根据GPU显存大小合理设置batchsize。
3.1 RQ1复现
cd linevul
python linevul_main.py \
--output_dir=./saved_models \
--model_type=roberta \
--tokenizer_name=microsoft/codebert-base \
--model_name_or_path=microsoft/codebert-base \
--do_train \
--do_test \
--train_data_file=../data/big-vul_dataset/train.csv \
--eval_data_file=../data/big-vul_dataset/val.csv \
--test_data_file=../data/big-vul_dataset/test.csv \
--epochs 10 \
--block_size 512 \
--train_batch_size 16 \
--eval_batch_size 16 \
--learning_rate 2e-5 \
--max_grad_norm 1.0 \
--evaluate_during_training \
--seed 123456 2>&1 | tee train.log3.2 RQ2复现
cd linevul
python linevul_main.py \
--model_name=12heads_linevul_model.bin \
--output_dir=./saved_models \
--model_type=roberta \
--tokenizer_name=microsoft/codebert-base \
--model_name_or_path=microsoft/codebert-base \
--do_test \
--do_local_explanation \
--top_k_constant=10 \
--reasoning_method=all \
--train_data_file=../data/big-vul_dataset/train.csv \
--eval_data_file=../data/big-vul_dataset/val.csv \
--test_data_file=../data/big-vul_dataset/test.csv \
--block_size 512 \
--eval_batch_size 5123.3 RQ3复现
cd linevul
python linevul_main.py \
--model_name=12heads_linevul_model.bin \
--output_dir=./saved_models \
--model_type=roberta \
--tokenizer_name=microsoft/codebert-base \
--model_name_or_path=microsoft/codebert-base \
--do_test \
--do_sorting_by_line_scores \
--effort_at_top_k=0.2 \
--top_k_recall_by_lines=0.01 \
--top_k_recall_by_pred_prob=0.2 \
--reasoning_method=all \
--train_data_file=../data/big-vul_dataset/train.csv \
--eval_data_file=../data/big-vul_dataset/val.csv \
--test_data_file=../data/big-vul_dataset/test.csv \
--block_size 512 \
--eval_batch_size 5124 报错及解决办法
1. 出现 Unexpected key(s) in state_dict: "roberta.embeddings.position_ids", "encoder.roberta.embeddings.position_ids" 错误。
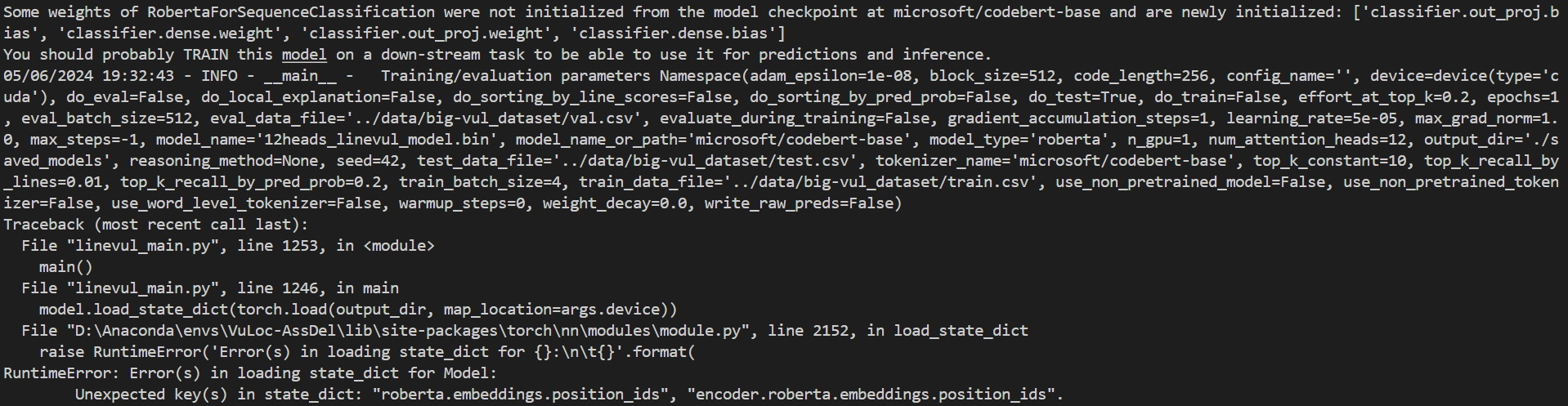
报错原因:transformers库的版本过高,回退版本。
2. 出现 ImportError: cannot import name 'SAVE_STATE_WARNING' from 'torch.optim.lr_scheduler' 错误。

报错原因:transformers库的版本过低,更新版本。
经实际测试,版本为 transformers==4.30.0 时可正常运行。
5 参考
GitHub - awsm-research/LineVul: A Transformer-based Line-Level Vulnerability Prediction















 2099
2099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











