









目前基于深度学习的漏洞检测中性能最高的方法使用的是基于 token 的 transformer 模型,这对于捕捉漏洞检测所需的代码语义来说并不是最有效的。文中设计了一个受数据流分析启发的图学习框架 DeepDFA,以及一种能让图学习模拟数据流计算的嵌入技术。其训练时间为 9 分钟,比性能最高的基线模型快 75 倍。在仅使用 50 多个易受攻击和数百个示例作为训练数据的情况下,该模型保持了与使用 100% 数据集相同的性能。DeepDFA 还适用于 DbgBench 中的真实世界漏洞;它平均能从 17 个漏洞中检测出 8.7 个,并能区分已打补丁的版本和有漏洞的版本,而性能最高的基线模型未检测出任何漏洞。
1 问题描述
最近,基于大语言模型(LLMs) 的漏洞检测工具的性能已经超过了传统的静态分析,如 LineVul,最近一个基于 CodeBERT的模型,在一个常用的真实世界漏洞数据集上报告了高达 91 的 F1 分数。然而,LLMs 需要大量的训练数据和计算资源来进行训练和推理,现实情况中很难获得大量高质量的漏洞数据。它们也可能无法检测到训练数据集之外的漏洞;例如,性能最好的 Transformer 模型 LineVul 和 UniXcoder 无法检测到 DbgBench 中的任何真实漏洞。此外,由于只使用文本 tokens,这些模型可能无法有效地学习程序语义,例如程序值流路径、污点值的传播以及沿控制流路径的安全敏感 API 调用。
2 解决方案
文中探讨了数据流分析(DFA) 与 GNN 消息传递机制之间的类比关系,并设计了一种在 CFG 的每个节点上编码数据流信息的嵌入技术。具体来说,利用数据流的有效位向量表征来编码变量的定义和用途。在这种嵌入上进行图学习,可以传播和聚合数据流信息,从而模拟 DFA 中的数据流计算。利用这种方法,学习到的图表示法能更好地编码程序语义信息,如 reaching definitions。
基于此,论文开发了一种抽象的数据流嵌入,它可以将单个程序的变量定义映射到一个共同的空间,从而使模型可以比较和概括与跨程序漏洞相关的数据使用模式(数据流),并选择了一种图学习架构,其聚合和更新功能对数据流传播更为有效。
论文的主要贡献如下:
- 设计了一种抽象数据流嵌入,使深度学习能够概括不同程序的漏洞语义/数据流模式;
- 在程序的控制流图(CFG)和抽象数据流嵌入上应用图学习,模拟 reaching definitions 的数据流分析;
- 实现了 DeepDFA,并通过实验证明 DeepDFA 在漏洞检测的有效性、效率和对未见项目的泛化方面优于基线;
- 提供了有助于理解 DeepDFA 为何表现出色且高效的理由;
- 通过结合 DeepDFA 和 UniXcoder 超越了最先进的漏洞检测性能。
3 方法设计
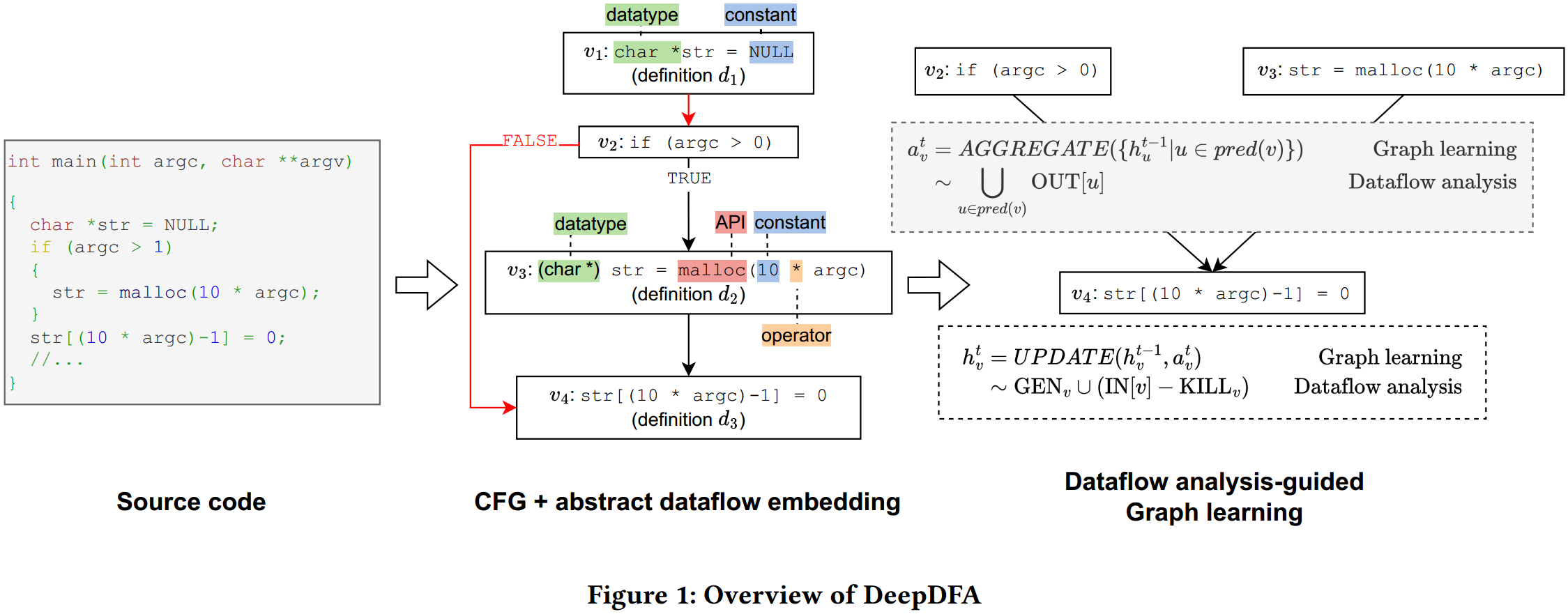
DeepDFA的大致流程为:给定潜在漏洞程序的源代码,将其转换为 CFG,并使用设计的抽象数据流嵌入对节点进行编码。具体来说,考虑定义变量的数据类型、API 调用、常量和用于定义变量的操作符,并以紧凑、高效的方式对抽象定义进行了编码。然后应用图学习,像数据流分析中的 “合并 ”操作那样聚合来自节点的抽象数据流信息,并利用每个节点的信息进行更新。最后利用图学习直接传播数据流信息,向分类器呈现一种程序表示,其中编码了与漏洞直接相关的有用信息,从而实现高效、有效的漏洞检测。
3.1 一些基本概念
数据流分析的一个实例称为 “到达定义分析”(reaching definition analysis),它报告特定变量定义可以到达哪些程序节点。当 CFG 中存在连接定义和节点的路径,且变量在路径上未被重新定义时,定义就会到达节点。当识别出 NULL 指针的定义到达指针的取消引用时,到达定义分析就能根据其根本原因检测到空指针取消引用漏洞。同样,它也是检测许多其他漏洞(如缓冲区溢出、整数溢出、未初始化变量、双重释放和释放后重引用)的因果步骤。
DFA 使用两个等式,即满足算子(meet operator)和转移函数(transfer function),通过 CFG 中的相邻节点传播数据流信息。满足算子汇总来自其相邻节点的数据流集。传递函数利用节点 𝑣 中的可用信息更新数据流集。执行 DFA 的一种简单方法是 Kildall 方法。该方法将数据流信息迭代传播到 CFG 中 𝑣 的邻域,每次传播一步。当所有节点的数据流信息停止变化时,算法终止,表示为一个固定点。终止时,所有节点都将包含来自所有其他相关节点的数据流信息。当用于漏洞检测时,这些信息会与用户指定的漏洞条件进行比较,以确定程序中是否出现了漏洞。
图学习从初始节点表示开始,然后执行固定次数的消息传递算法迭代,在图中传播信息。初始节点表示通常是一个固定大小的连续向量,代表节点的内容。在每次迭代中,每个节点都会聚合来自其邻居的信息,然后更新其状态以整合这些信息。这两个步骤是通过聚合(AGGREGATE)和更新(UPDATE) 函数完成的,类似于满足算子和转移函数的两个数据流方程
3.2 抽象数据流嵌入
在数据流分析中,使用比特向量来表示每个节点的数据流集。位向量由 𝑛 个 0 和 1 位组成,其长度为域的大小。如果集合中存在相应的元素,位就会被设置为 1。在达到定义分析中,域由程序中的所有定义组成,如果相应的定义达到了节点,则位被置为 “1”。例如,在图 1 中,程序在节点𝑣1、𝑣3 和𝑣4 上包含三个定义,因此在分析开始时,达到定义分析使用一个位向量 [0 0 0] 来初始化每个节点。这个位向量表示数据流方程中的𝑂𝑈𝑇 [𝑣]。它在每一步传播过程中都会更新,当分析结束时,每个节点的位向量代表了能到达该节点的所有可能定义。
然而,在图学习中,不能直接使用定义的位向量作为节点嵌入。这是因为数据流分析和定义域都是针对程序的。换句话说,不同的程序有不同的变量定义;每个程序的位向量长度不同,元素(每个定义)也不具有可比性。因此,需要一个 “全局 ”定义集,用于指定不同程序的定义。
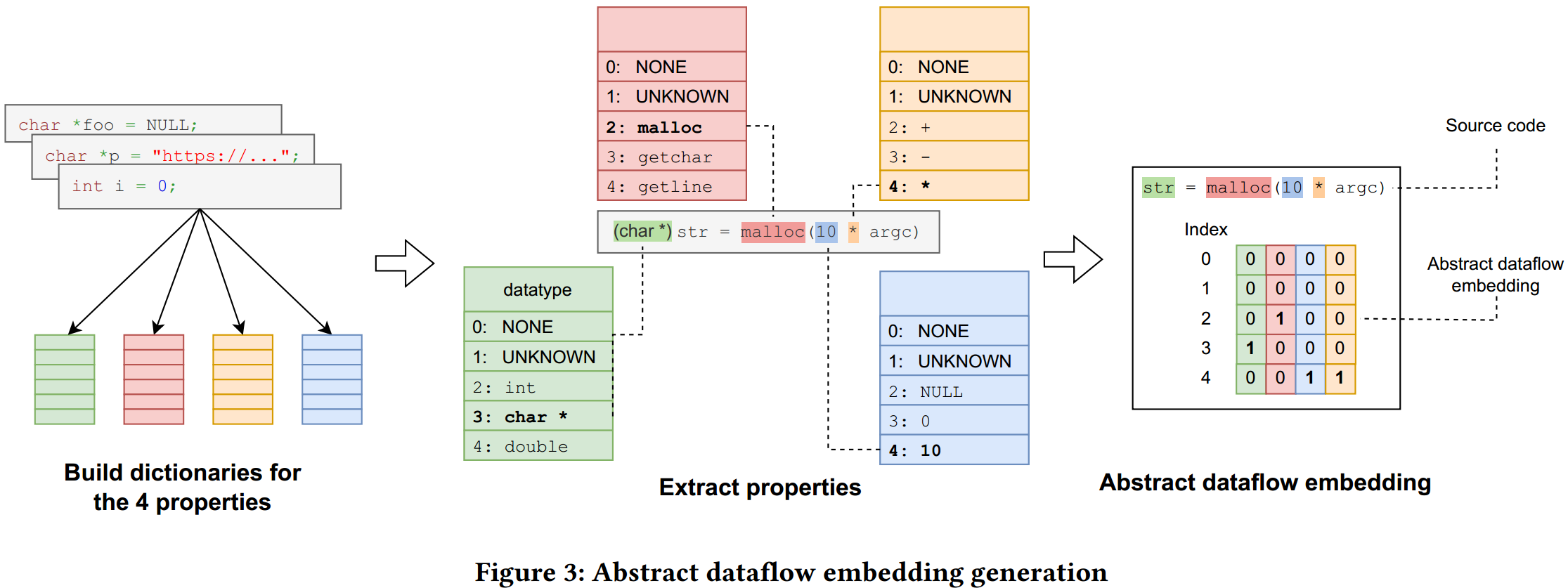
因此,文中将程序中的具体定义表示为抽象定义,并基于定义的属性设计了以下四种可涵盖漏洞攻击面的属性:
- API 调用(API call):用于定义变量的库函数或系统函数的调用,如 malloc 和 strlen。
- 数据类型(Data type):变量被赋值的数据类型,例如int、char* 和 float。
- 常量(Constant):定义中指定的常量值,例如NULL、-1 和硬编码字符串 “foo”。
- 运算符(Operator):用于定义变量的运算符,如 + 和 *。
通过分析大量程序(如训练集),收集前 k 个最常用的 API 调用、数据类型、常量和运算符,从而分别构建 4 个长度为 k 的全局定义字典。如图 3 所示,定义语句 (char*) str = malloc (10 * argc) 包含数据类型 char*,API 调用 malloc,常量 10 和运算符 *,它们在各自的全局定义字典中分别对应索引 3,2,4,4,将嵌入向量中相应位置置为 1,从而得到该定义语句对应的一个大小为 5*4 的向量,其中 k=5,而 4 表示一个定义语句中考虑的 4 个属性。 由于编码抽象数据流嵌入的向量大小固定,该嵌入方法可以扩展到数据集中的任何程序大小,而不会影响模型的效率。不同程序中的向量编码了定义的共同属性,因此模型可以捕捉不同程序的数据流模式。
3.3 图学习聚合数据流信息
图学习的大致流程为:首先构建程序的 CFG。其次,执行静态分析以识别 CFG 中的所有定义。然后,根据节点是否为定义,使用抽象数据流嵌入对 CFG 的每个节点进行初始化。应用图学习中的消息传递算法在整个 CFG 中传播数据流信息,与 Kildall 的方法类似。主要区别在于:(1) 文中传播的是 CFG 节点的抽象数据流嵌入;(2) 没有使用传递函数和相遇算子的数据流方程,而是交替使用了图学习中定义的 AGGREGATE 和 UPDATE 函数。采用门控图序列神经网络 (GGNN) 作为图学习的模型,其中 AGGREGATE 是多层感知器 (MLP),UPDATE 是门控递归单元 (GRU)。
DFA 中的满足算子和转移函数:
![]()
图学习中的聚合和更新函数:
![]()
当数据流信息到达 CFG 分支的合并点时,图学习会应用 AGGREGATE 函数。具体来说,在 GGNN 中,MLP 会计算多个相邻前代的表示的加权和,得到一个单一向量;这与 meet 运算符的功能相同。当数据流信息到达一个新节点时,图学习中的 UPDATE 函数会将当前节点的信息与前节点的 AGGREGATE 输出相结合,从而计算出下一个状态。具体来说,在 GGNN 中,GRU 会选择性地遗忘前一状态的部分内容,并整合当前节点和邻近状态的新信息,这与转移函数中执行的集合联合/差分与 GEN/KILL 类似。通过应用 AGGREGATE 和 UPDATE,初始嵌入将根据邻近节点的数据流信息进行更新,这与数据流分析的效果类似。
DFA 会迭代到一个固定点,从而在整个图中传播信息,而图学习会执行固定数量的迭代 𝑡,从而传播到距离 𝑡 的邻居。将 𝑡 设为验证集性能最大化的设置。最后,利用全局注意力池(Global Attention Pooling)将学习到的抽象节点嵌入结合起来,生成图层表示,并将其传递给分类器,以预测函数是脆弱还是非脆弱。AGGREGATE 和 UPDATE 函数是在训练过程中从标注数据中学习的,而不是像数据流分析那样使用固定公式。通过从训练示例中学习,分类器可以捕捉到代表各种类型漏洞的数据流信息模式,并选择相关的数据流信息进行漏洞检测。
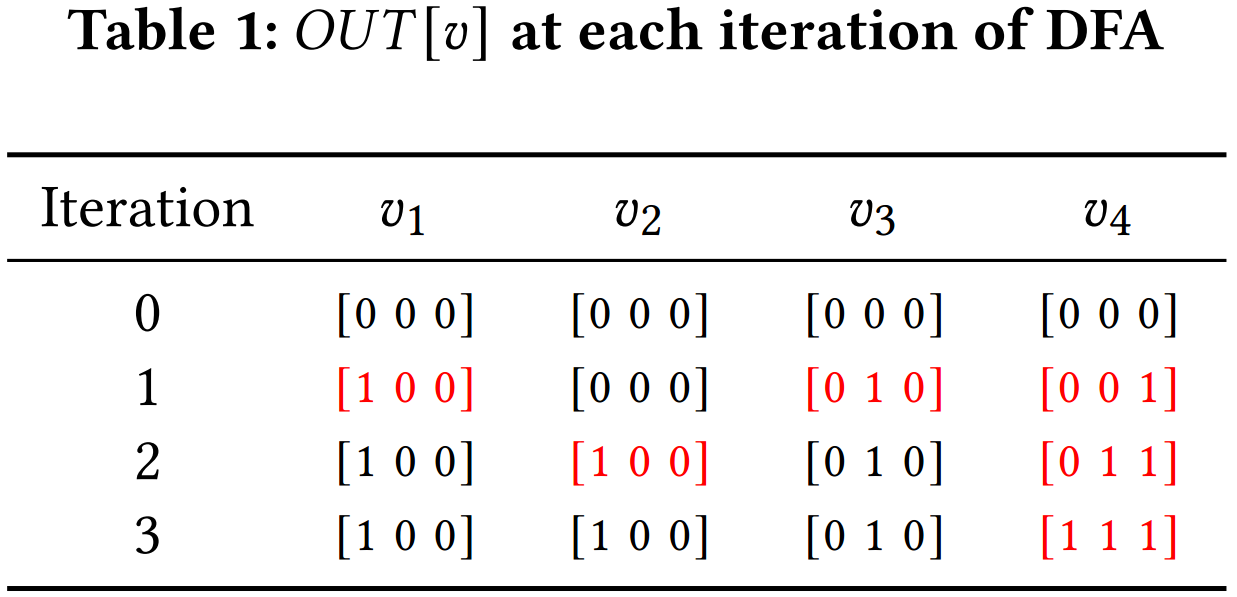
在表 1 中,文中对图 1 中的 CFG 示例进行了达到定义分析,以展示数据流信息如何在图中传播,以及如何利用数据流信息进行漏洞检测。在第 0 次迭代中,4 个节点的初始状态均为 [ 0 0 0 ];在第 1 次迭代中,由于新定义,DFA 通过传递函数更新节点 𝑣1 [1 0 0], 𝑣3 [0 1 0], 𝑣4 [0 0 1]; 在第 2 次迭代中, 𝑣1(定义 𝑑1)通过 CFG 边传播到 𝑣2 [1 0 0],𝑣3(定义 𝑑2)传播到 𝑣4 [0 1 1];在第 3 次迭代中,满足算子用于合并 𝑣2 和 𝑣3,得到 [1 0 0] V [0 1 0] = [1 1 0];最终传递函数结合第 2 次迭代中的 𝑣4 [0 1 1],得到 [1 1 1]。DFA 算法结束后,节点的最终状态将用于检测漏洞。𝑣4 的状态是[1 1 1],这表明 𝑑1 和 𝑑2 都可能到达 𝑣4,这取决于程序值。由于定义 𝑑1 : str = NULL 可以到达 𝑣4 处的引用,可以得出结论,该程序存在空指针解引用漏洞。同样,在图学习中,经过固定次数的迭代后,所有节点的表示都会通过图读出操作结合起来,生成图级表示,用于漏洞检测预测。存在空指针解引用漏洞的程序将具有相同的抽象定义,其特征是使用 char* 类型和常量 NULL 来实现指针解引用语句。
4 实验评估
4.1 有效性
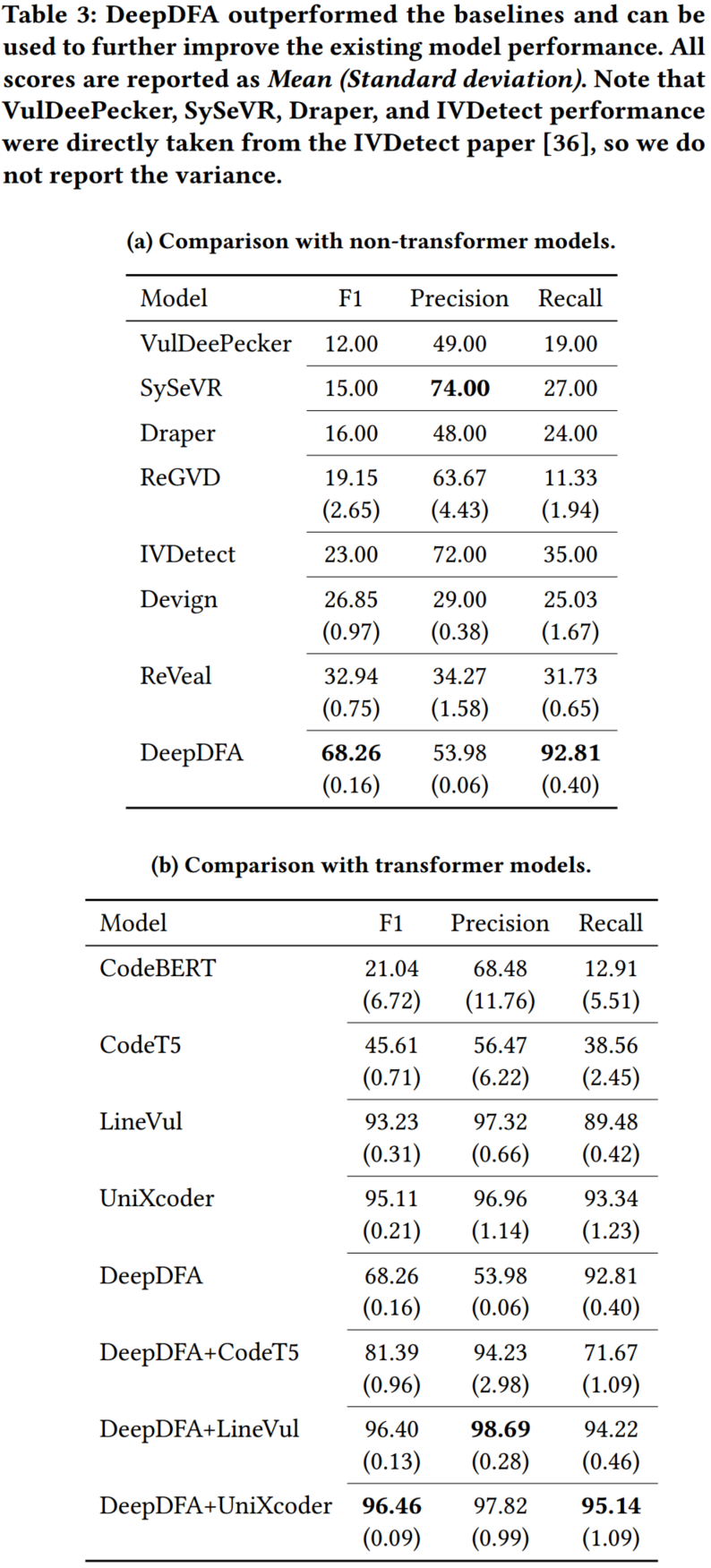
与非 Transformer 模型的比较:表 3(a) 显示,DeepDFA 在 F1 分数和召回率方面的表现远远优于基线模型。DeepDFA 的得分比所有基线模型的平均 F1 得分高出 47.51。与 Transformer 模型的比较: 将 DeepDFA 与 CodeBERT、LineVul、UniXcoder 和 CodeT5(评估过的转换器语言模型中最先进的)进行了比较。表 3b 显示,在 F1 分数上,DeepDFA 的表现要比 CodeBERT 和 CodeT5 好得多,而且运行之间的方差也最小(在所有模型中)。
4.2 效率
表 5 为 DeepDFA、LineVul 和 UniXcoder 的运行时间对比。与 UniXcoder 相比,DeepDFA 的训练时间缩短了 75 倍,在 GPU 上的推理速度提高了 2 倍,在 CPU 上的推理速度提高了 84 倍。在所有模型中,DeepDFA 的参数最少,相当于最小模型(ReVeal)的 67%,性能最高的基线模型(UniXcoder)的 0.3%。
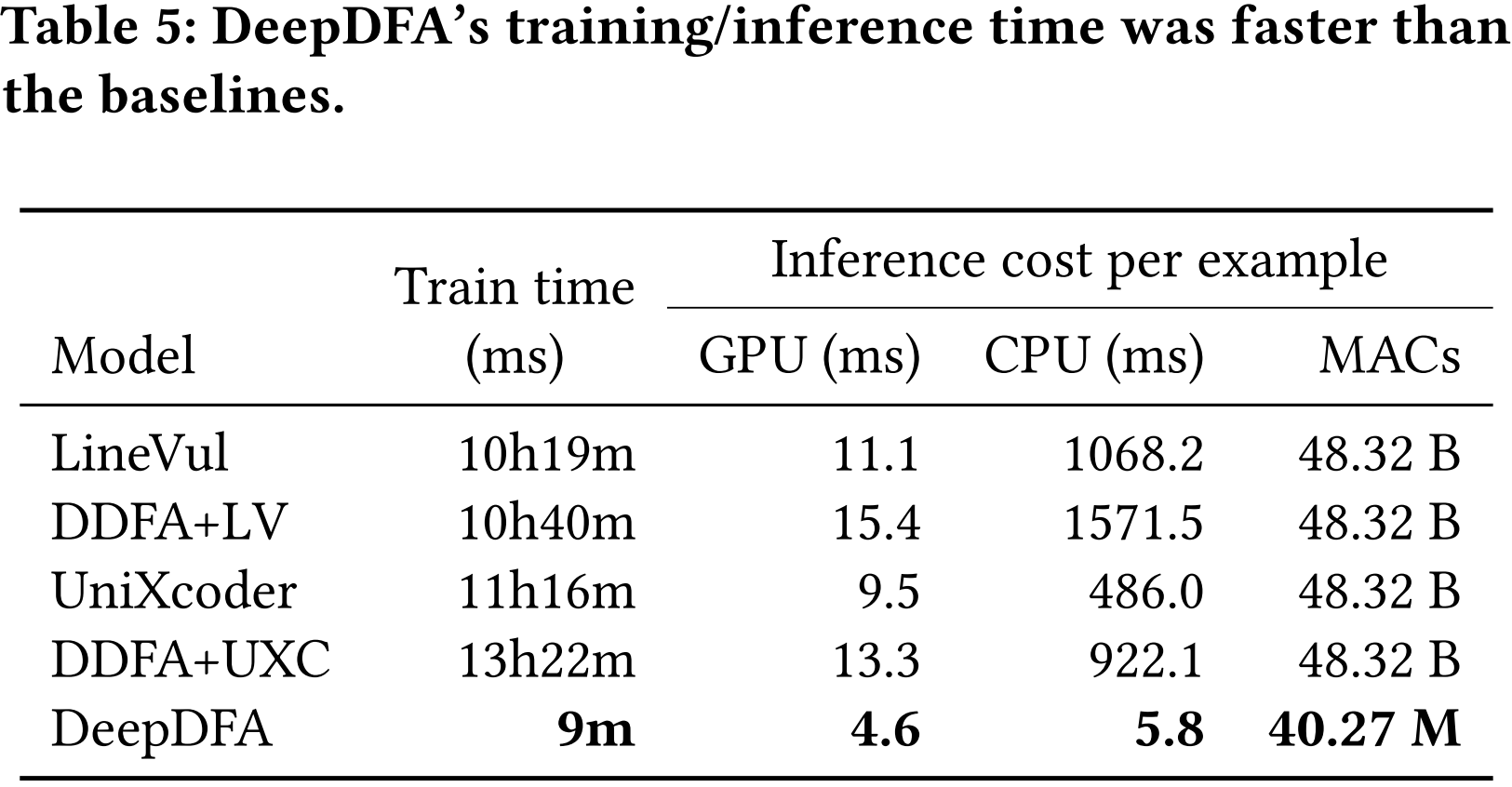
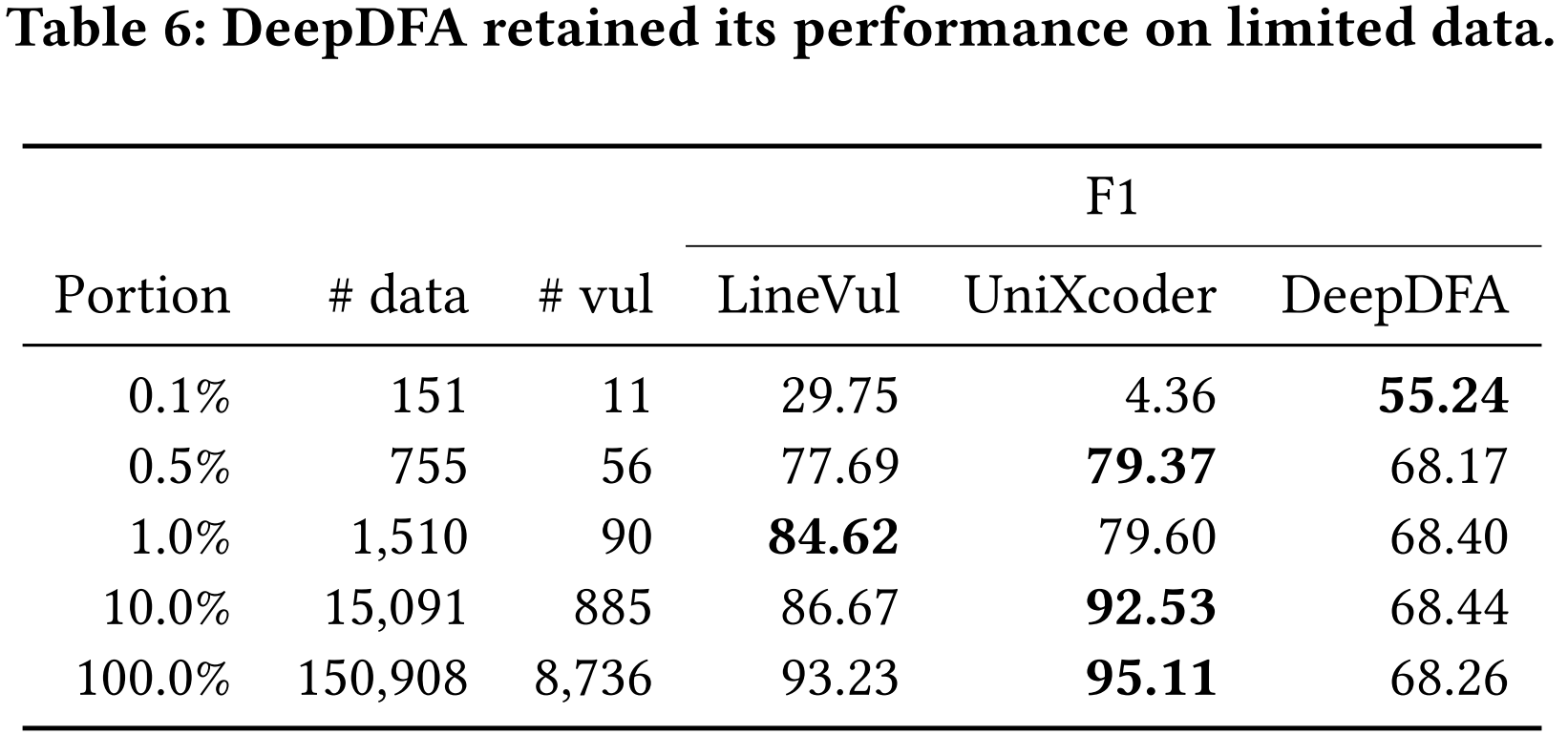
在表 6 中,报告了 DeepDFA 与 SOTA 模型 LineVul 和 UniXcoder 相比,在训练数据集规模缩小后的性能表现。列 “#data” 和 “#vul” 列出了每个子集中训练示例的数量,以及其中易受攻击的示例的数量。结果表明,DeepDFA 在小数据集规模上保持稳定的性能,即使只有 0.1% 的训练数据集,只使用 151 个训练样例。相比之下,LineVul 和 UniXcoder 随着训练数据集的减小,性能下降。
4.3 泛化性
表 7 展示了在 Big-Vul 数据集上的跨项目评估的结果。
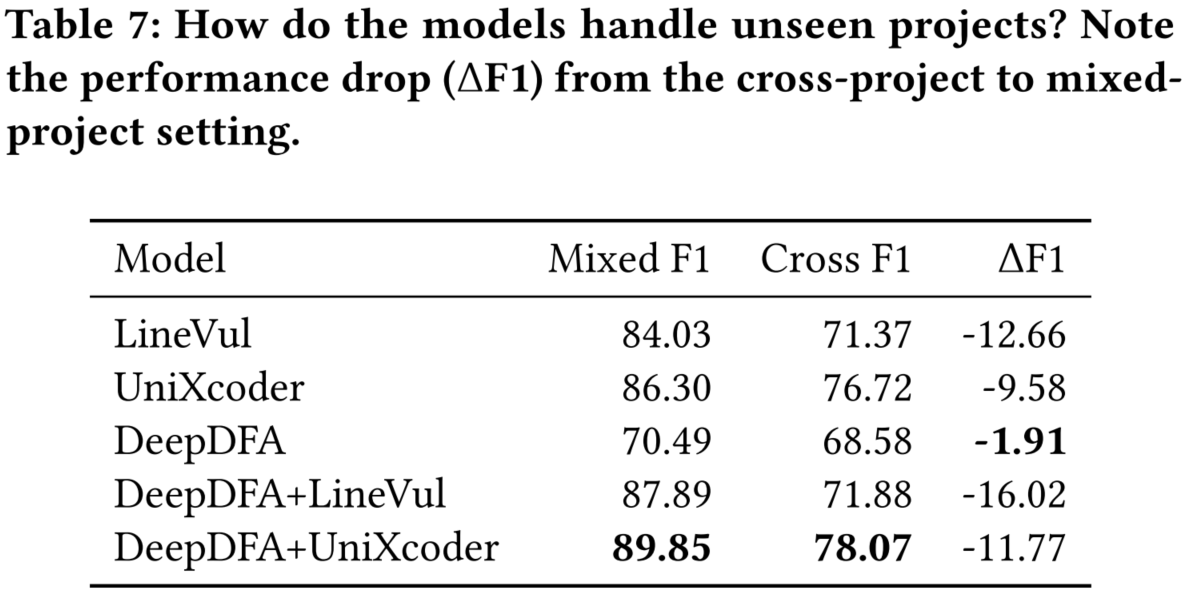
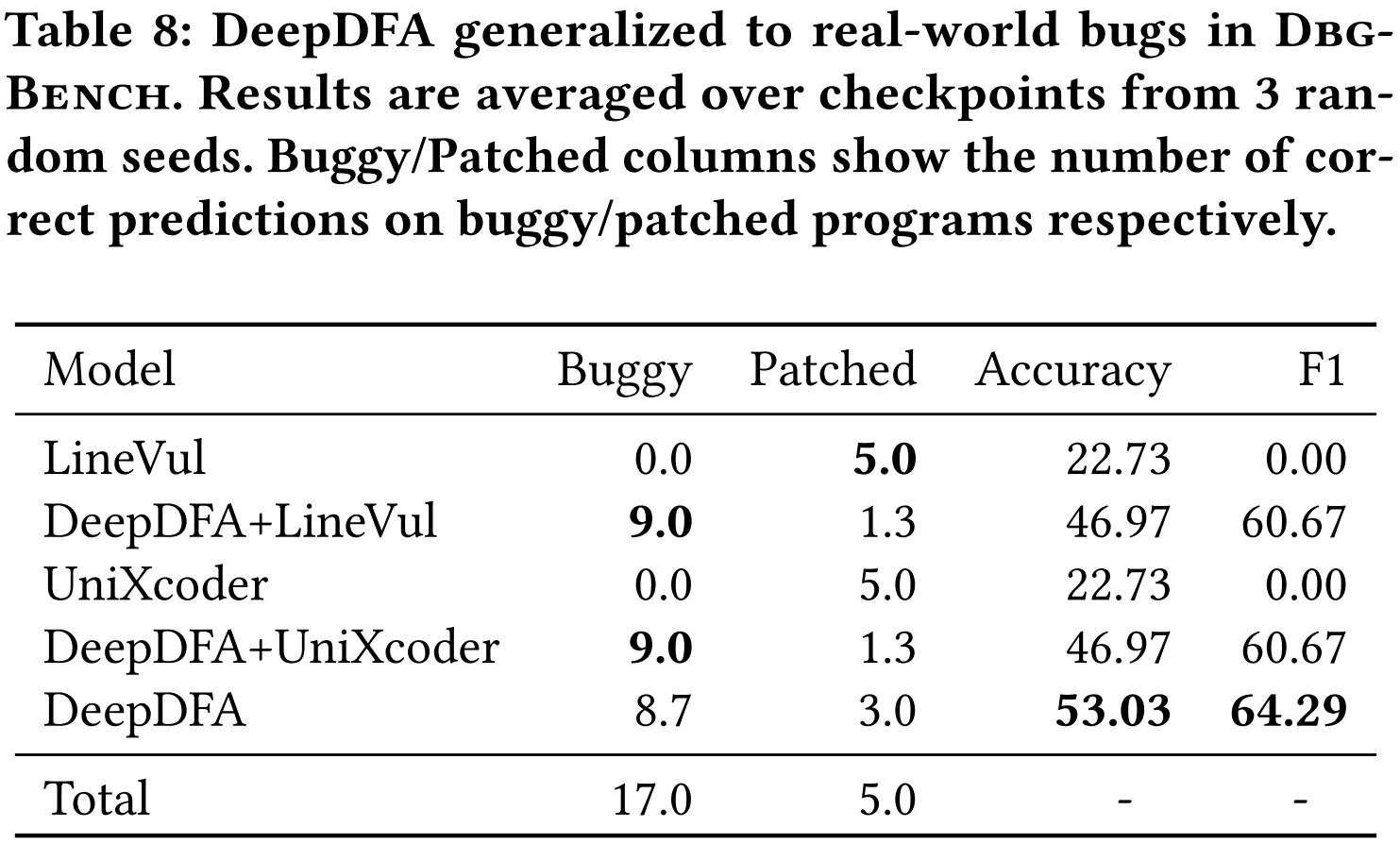
表 8 报告了将深度学习工具应用于实际缺陷基准的经验。在 3 次运行中,DeepDFA 在 17 个错误中的平均检测到 8.7,DeepDFA 还正确预测了 5 个打补丁程序中的 3 个不存在漏洞。
4.4 消融实验
表 9 显示了模型在 DbgBench 上的性能。与其他消融设置相比,该模型在使用所有四个特征时检测到的错误最多。当一次只使用一个特征时,模型总是漏掉 DeepDFA 检测到的 1-2 个错误。当同时使用三个特征时,模型仍始终未能检测到 DeepDFA 检测到的 1 个错误。
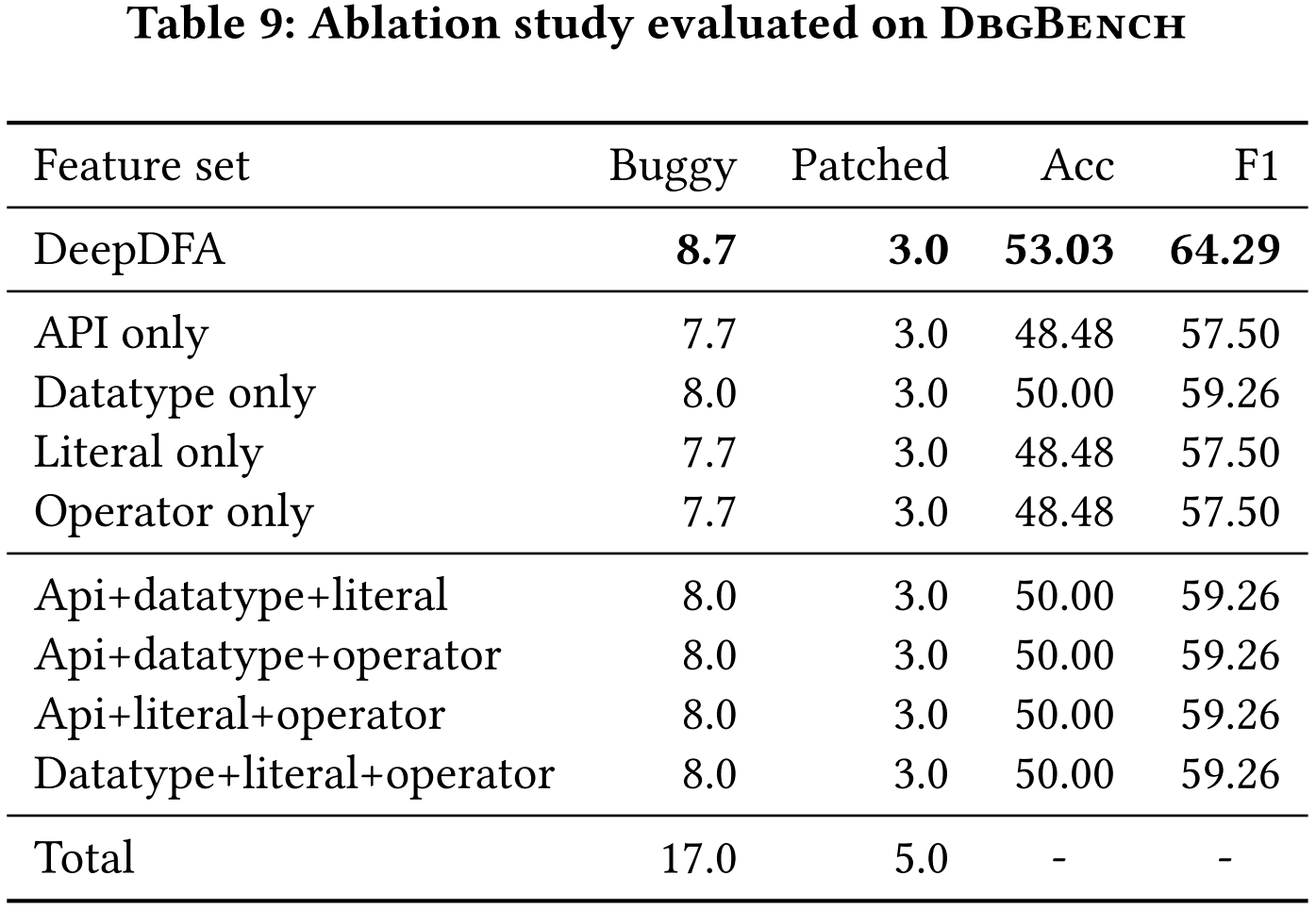
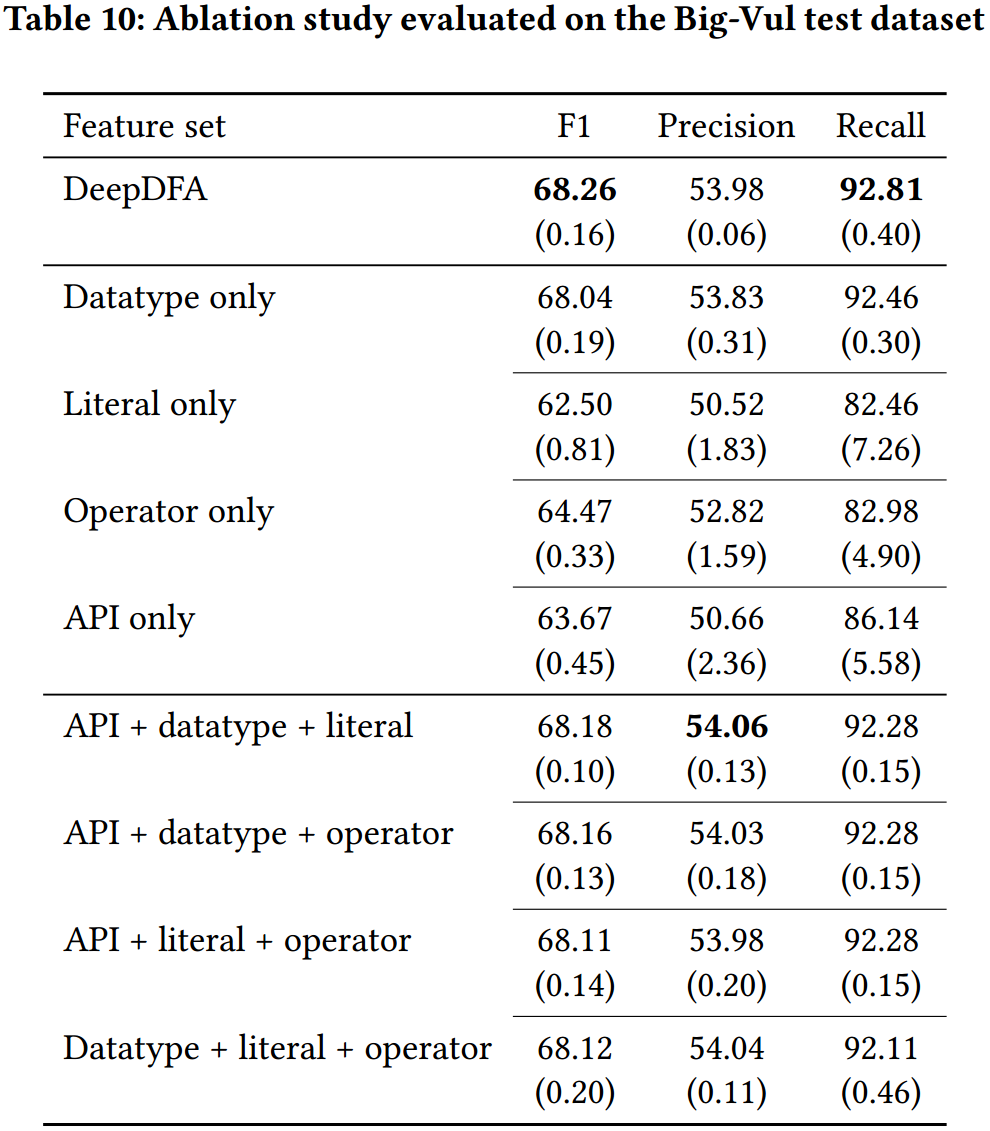
表 10 显示了模型在 Big-Vul 测试数据集上的性能。在所有配置中,DeepDFA(集成了所有四个特征)的表现最好。在一次测试一个特征时,数据类型本身的性能要好于单独测试其他 3 个特征,使用组合特征集时,模型的表现比只使用一个特征更好。
5 论文总结
文中提出了用于漏洞检测的高效图学习框架和嵌入技术 DeepDFA。通过抽象数据流嵌入利用数据流分析中的位向量思想,并整合了语义特征中的数据使用模式:常用的 API 调用、操作、常量和数据类型,这些都有可能捕捉到漏洞的成因。DeepDFA 使用类似的消息传递算法模拟数据流分析的 Kildall 方法。实验结果表明,DeepDFA 非常高效。它只用了 9 分钟就完成了训练,只用了 50 个漏洞示例就实现了最高性能。同时,它的性能仍然优于所有非 Transformer 基线,并且在所有模型中泛化效果最好。DeepDFA 在 DbgBench 的实际程序中发现了漏洞,而性能最高的基线 LineVul 和 UniXcoder 都没有检测到任何漏洞。重要的是,DeepDFA 与性能最高的模型相结合,其漏洞检测性能超过了目前最先进的水平。
6 原文链接
论文题目:Dataflow Analysis-Inspired Deep Learning for Efficient Vulnerability Detection
论文出处:2024 IEEE/ACM 46th International Conference on Software Engineering ( ICSE 2024 )
项目地址:Dataflow Analysis-Inspired Deep Learning for Efficient Vulnerability Detection (figshare.com)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











