







Web
- DNS:(Domain Name System,域名系统),用于把域名转换为对应的IP地址。
Linux
-
格式组成: 命令主体 -命令选项 命令参数
-
命令主体 --help : 可以查看命令具备哪些选项及选项含义
-
man 命令主体 : 查看命令的手册信息
-
ls : 查看当前路径下有哪些文件 –a,l
-
pwd : 查看当前所在的路径位置
-
touch : 创建普通文件(单文件: touch 文件名 多文件: touch 文件名1 文件名2 …)
-
mkdir : 创建目录文件
-
cp -i/-r : 复制文件/文件夹
-
mv [选项] 源⽂件或⽬录 ⽬标⽂件或⽬录:移动文件/文件夹(也可以用来改名)
-
rm : 删除文件/文件夹(rm 文件名 / rm -r 文件夹名)
-
clear : 清空屏幕操作, 快捷键: Ctrl + L
-
dpkg --list显示所有安装软件
卸载list中所列出来的软件apt-get --purge remove nginx-common
-
>:重定向符号
-
>>:追加重定向符号
-
more : 以分屏形式查看文件内容(格式: more 文件名)
-
| : 管道符号(将左侧命令的结果传递给右侧命令当数据源) | : 例如: ls -al /usr/bin | grep mysql (从左侧命令的结果中查找mysql)
-
Linux三剑客
grep 简介:文本过滤工具,用于查找文件里符合条件的字符串 语法:grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文 件>][--help][范本样式][文件或目录...] 可选参数: -a 或 --text : 不要忽略二进制的数据。 -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。 -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。 -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。 -c 或 --count : 计算符合样式的列数。 -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。 -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止 动作。 -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。 -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。 -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格 式为每行一个规则样式。 -F 或 --fixed-regexp : 将样式视为固定字符串的列表。 -G 或 --basic-regexp : 将样式视为普通的表示法来使用。 -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。 -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。 -i 或 --ignore-case : 忽略字符大小写的差别。 -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。 -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。 -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。 -o 或 --only-matching : 只显示匹配PATTERN 部分。 -q 或 --quiet或--silent : 不显示任何信息。 -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。 -s 或 --no-messages : 不显示错误信息。 -v 或 --invert-match : 显示不包含匹配文本的所有行。 -V 或 --version : 显示版本信息。 -w 或 --word-regexp : 只显示全字符合的列。 -x --line-regexp : 只显示全列符合的列。 -y : 此参数的效果和指定"-i"参数相同。 awk 简介:强大的文本分析工具 语法:awk [选项参数] 'script' var=value file(s) 或 awk [选项参数] -f scriptfile var=value file(s) 可选参数: ·-F fs or --field-separator fs指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 -v var=value or --asign var=value赋值一个用户定义变量。 -f scripfile or --file scriptfile从脚本文件中读取awk命令。 -mf nnn and -mr nnn对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是 Bell实验室版awk的扩展功能,在标准awk中不适用。 -W compact or --compat, -W traditional or --traditional在兼容模式下运行awk。所以gawk的行为和标准的awk完全 一样,所有的awk扩展都被忽略。 -W copyleft or --copyleft, -W copyright or --copyright打印简短的版权信息。 -W help or --help, -W usage or --usage打印全部awk选项和每个选项的简短说明。 -W lint or --lint打印不能向传统unix平台移植的结构的警告。 -W lint-old or --lint-old打印关于不能向传统unix平台移植的结构的警告。 -W posix打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔 符;操作符**和**=不能代替^和^=;fflush无效。 -W re-interval or --re-inerval允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 -W source program-text or --source program-text使用program-text作为源代码,可与-f命令混用。 -W version or --version打印bug报告信息的版本。 sed 简介:利用脚本来处理文本文件 语法:sed [-hnV][-e<script>][-f<script文件>][文本文件] 可选参数: -e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。 -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。 -i直接修改文件内容(危险操作) -h或--help 显示帮助。 -n或--quiet或--silent 仅显示script处理后的结果。 -V或--version 显示版本信息。 a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚; i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); 可通过[sed -i "行数+i+空格+想要插入的语句" 想要插入的文件名]来插入 p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~ s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦! sed内容替换:sed -i 's#原始内容#替换后内容#g' file 原文链接:https://blog.csdn.net/u011328843/article/details/110095395 -
head:可以查看文件开头内容(head文件名:查看文件的前10行内容;head-行数文件名:查看文件的前x行内容)
-
tail:可以查看文件结尾内容(tail文件名:查看文件的后10行内容;tail-行数文件名:查看文件的后x行内容)
tail-f:动态查看日志文件内容(格式:tail-f日志文件名)
-
reboot:重启
-
shutdown -h now:关机
-
cat : 查看文件内容(格式: cat 文件名)
cat /proc/version:查看内核版本
cat /etc/redhat-release:查看发行版本
-
ps -aux:查看当前系统下所有的进程信息,常用用法:ps -aux | grep程序名。能够获取目标程序的进程ID**
-
kill-9进程ID:通过进程ID关闭对应程序(-9:强制关闭)
-
top可以调用Linux系统下的"任务管理器",可以动态查看所有的进程信息
-
netstat-anptu:可以获取当前系统的网络相关信息(获取端口号信息)
-
netstat -tunlp ⽤于显⽰ tcp,udp 的端⼝和进程等相关情况
-
lsof-i:端口号:查看占用某一端口的的程序名称及进程ID(需要root用户权限)
-
文件权限修改命令
命令格式:chmod 权限 文件名 字母法 1.组别代表字母:u:拥有者g:用户组o:其他人a:以上所有 2.赋权代表符号:+:增加,-:撤销,=:赋予 3.权限代表字母:r:读取w:写入x:执行 4.根据需求组合以上三个部分,再设置权限即可例如:chmod a=rwx demo或 chmod u-r,g-w,o=x demo 数字法 1.权限对应的数字:r:4 w:2 x:1 2.分别累加每一个组别的权限值之和,再设置权限即可例如:chmod 755 demo -
修改文件夹所属用户
chown [-R] 所有者 文件或目录 eg:chown user file -
which程序名:可以查看程序安装位置
-
su - 用户名:切换至用户(su -:切换到root用户)(切换哪个用户,输入用户对应密码,密码没有提示)
-
who-u:查看用户登录信息
-
exit:退出终端窗口(退出用户)
-
find 路径 - name’目标文件名’ :在给出的路径下查找目标文件
-
ln -s源文件/文件夹链接文件名:给源文件/文件夹创建链接文件(软链接:等价于Windows系统的快捷方式)
-
压缩与解压
1、tar和gzip tar - zcvf压缩包名.tar.gz目标文件/文件夹 解包和解压:tar -zxvf压缩包名.tar.gz 扩展-指定解压位置:tar-zxvf压缩包名.tar.gz目标文件/文件夹-C解压位置文件夹 2、tar和bzip2 打包和压缩:tar-jcvf压缩包名.tar.bz2目标文件/文件夹 解包和解压:tar-jxvf压缩包名.tar.bz2 指定解压位置:tar-jxvf压缩包名.tar.bz2目标文件/文件夹-C解压位置文件夹 3、选项含义 -z:gzip(压缩/解压) -j:bzip2(压缩/解压) -c:打包 -x:解包 -v:显示过程 -f:指向文件 -C:指定解压路径 4、zip和unzip 压缩:zip -r 压缩包名目标文件/文件夹 解压:unzip -d 解压位置文件夹 压缩包名 -
passwd 系统账号名。修改系统密码需要在root权限下
-
vi模式
1、插入模式 i: 插入光标前一个字符 I: 插入行首 a: 插入光标后一个字符 A: 插入行未 o: 向下新开一行,插入行首 O: 向上新开一行,插入行首 2、命令模式 ESC: 从插入模式或者底线命令模式回到命令模式 移动光标: h: 光标向左 j: 光标向下 k: 光标向上 l: 光标向右 L: 光标移动到屏幕最后一行行首 gg: 光标移动到文件开头 G: 移动到指定行,行号 -G G: 光标移动到文件末尾 shift+^: 移动到行头 shift+$: 移动到行尾 shift+g: 移动到页尾 数字+shift+g: 移动到目标行: 复制粘贴: yy: 复制光标当前一行 y数字y: 复制光标(含)后多少行 p: 在光标所在位置向下新开辟一行,箭头移动到目的行,粘贴 yw: 复制一个词 删除命令: dd: 删除光标当前行 d数字d: 删除光标(含)后多少行 x: 删除光标后一个字符,相当于 Del X: 删除光标前一个字符,相当于 Backspace dw: 删除一个词,删除光标开始位置的字,包含光标所在字符 撤销命令: u: 一步一步撤销 Ctr-r: 反撤销 重复命令: .: 重复上一次操作的命令 可视模式: v: 按字符移动,选中文本 V: 按行移动,选中文本可视模式可以配合 d, y, >>, <<实现对文本块的删除,复制,左右移动 3、替换模式 1) 全局替换:一次性替换文件中的 所有出现的旧文本 命令::%s/旧文本/新文本/g 2) 可视区域替换:先选中要替换文字的范围 命令::s/旧文本/新文本/g 3) 确认替换: 命令:%s/旧文本/新文本/gc 如果把末尾的g改成gc在替换的时候,会有提示!推荐使用! 提示信息: y - yes 替换 n - no 不替换 a - all 替换所有 q - quit 退出替换 l - last 最后一个,并把光标移动到行首 ^E 向下滚屏 ^Y 向上滚屏 4、底线命令模式 : - 进入底线命令模式 w - 保存 :q - 退出 :q! - 强制退出 /要查找的词: n查找下一行,N往上查找 ?要查找的词: n查找上一行,shift+n是往下查找 :set nu - 显示行号 :set nonu - 关闭行号 -
下载命令:wget + 空格 + 要下载文件的url路径
下载文件保存到当前目录,文件名默认是url最后一个/后面的内容,通过-O参数,可以指定文件名。 wget -O myfile http://www.minjieren.com/wordpress-3.1-zh_CN.zip wget www.baidu.com 会在当前目录生成一个index.html文件 -
curl [option] [url] :它支持文件的上传和下载,是综合传输工具,但按传统,习惯称url为下载工具。
常见参数: -A/--user-agent <string> 设置用户代理发送给服务器 -b/--cookie <name=string/file> cookie字符串或文件读取位置 -c/--cookie-jar <file> 操作结束后把cookie写入到这个文件中 -C/--continue-at <offset> 断点续转 -D/--dump-header <file> 把header信息写入到该文件中 -e/--referer 来源网址 -f/--fail 连接失败时不显示http错误 -o/--output 把输出写到该文件中 -O/--remote-name 把输出写到该文件中,保留远程文件的文件名 -r/--range <range> 检索来自HTTP/1.1或FTP服务器字节范围 -s/--silent 静音模式。不输出任何东西 -T/--upload-file <file> 上传文件 -u/--user <user[:password]> 设置服务器的用户和密码 -w/--write-out [format] 什么输出完成后 -x/--proxy <host[:port]> 在给定的端口上使用HTTP代理 -#/--progress-bar 进度条显示当前的传送状态 与wget的区别有如下几点: 1.curl是libcurl这个库支持的,wget是一个纯粹的命令行命令。 2.curl支持更多的协议。curl supports FTP, FTPS, HTTP, HTTPS, SCP, SFTP, TFTP, TELNET, DICT, LDAP, LDAPS, FILE, POP3, IMAP, SMTP and RTSP at the time of this writing. Wget supports HTTP, HTTPS and FTP. 3.curl 默认支持HTTP1.1(也支持1.0),而wget仅仅支持HTTP1.0规范。引用wget的man page中的一段话吧, 4.curl在指定要下载的链接时能够支持URL的序列或集合,而wget则不能这样; 5.wget支持递归下载,而curl则没有这个功能。(这是wget的一个主要好处,wget也是有优势的) -
防火墙
systemctl status firewalld.service查看防火墙状态 systemctl stop firewalld.servic关闭防火墙 systemctl disable firewalld.service永久关闭防火墙 1.查看防火墙状态sudo ufw status,也可以看到开放的端口 2.关闭防火墙sudo ufw disable,打开防火墙sudo ufw enable, 3.开放端口sudo ufw allow 端口号 4.关闭端口sudo ufw deny 端口号 5.重启防火墙sudo ufw reload -
常见文件的颜色:
linux文件: 设备文件: 黑色背景黄色字 目录文件: 深蓝色 可执行文件: 绿色 链接文件: 浅蓝色 普通文件: 黑色字体 压缩文件: 红色字体 -
系统基本信息
当前内核的信息 uname -a -a 表示查看所有内核信息 -n 表示查看当前主机名 -r 表示查看当前内核的版本号 -m 表示查看当前内核的架构版本号 -
查看磁盘容量
查看当前的磁盘容量 df -m 表示以人类正常识别的方式来查看当前系统的磁盘效果,打印尺寸(1024次方),不显示单位 -h 打印尺寸(1024次方),显示单位 查看当前内存的容量 free -m 表示以人类正常识别的方式来查看当前系统的磁盘效果,打印尺寸(1024次方),不显示单位 -h 打印尺寸(1024次方),显示单位 查看指定的目录容量大小 du -m 表示以人类正常识别的方式来查看当前系统的磁盘效果,打印尺寸(1024次方),不显示单位 -h 打印尺寸(1024次方),显示单位 -
Centos 7 安装之后默认是命令行界面,切换到图形界面
默认是命令行界面,基本是没有安装图形界面的包 解决办法: 1、插入网线,联网。 怎么联网如下 \#进入系统网卡配置文件 cd /etc/sysconfig/network-scripts/ \#找到ifcfg-ens33文件,进行编辑 vi ifcfg-ens33 \#修改启动设备参数为yes ONBOOT=yes 2、安装图形包 #通过yum命令获取资源并安装图形化界面GNOME的程序包,直到complete! yum groupinstall "GNOME Desktop" "Graphical Administration Tools" 3、设置默认启动方式 可设置的centOS 7系统默认启动模式 #设置为图形化界面模式 systemctl set-default graphical.target #设置为命令行模式 systemctl set-default multi-user.target 设置centOS 7默认为图形化界面启动 4、重启 -
&、&&、|、||符号的含义
& 表示任务在后台执行,如要在后台运行redis-server,则有 redis-server & && 表示前一条命令执行成功时,才执行后一条命令 ,如 echo '1‘ && echo '2' | 表示管道,上一条命令的输出,作为下一条命令参数,如 echo 'yes' | wc -l,再如ps aux | grep nginx || 表示上一条命令执行失败后,才执行下一条命令,如 cat nofile || echo "fail" -
telnet ip port : 查看某一个机器上的某一个端口是否可以访问
-
-
MySQL
-
视图:
create view 视图名称 as select查询语句; drop view 试图名称; -
外键约束:alter table 从表名 add foreign key (从表字段) reference 主表名(主表字段);
-
索引:
create index 索引名称 on 表名(字段名); drop index 索引名称 on 表名; -
set profiling=1;开启时间就监测
show profiles;查看运行时间
-
Linux终端运行mysql:mysql -u用户名 -p密码
-
存储过程:
delimiter // 取消末尾分号的作用 create procedure 存储过程名称(参数列表); begin sql语句 end // delimiter ;还原语句末尾分号的作用 调用存储过程:call 存储过程名称(); -
事务:
begin 开启事务 commit 提交事务 rollback 回滚事务 -
Linux中修改数据库配置文件,使之登录不需要密码
su - #切换到root用户 locate my.cnf #定位配置文件位置 vi 配置文件路径 #使用vi工具打开配置文件 skip-grant-tables #在文件内容[mysqld]下方添加此内容 systemctl restart mysqld #重启MySQL服务 systemctl status mysqld #查看mysql服务状况 -
修改账号密码
use mysql; update user set password=password(’新密码’)where user =‘用户名’; flush privileges -
Ubuntu安装MySQL
1、安装命令 sudo apt-get install mysql-server //服务端 sudo apt-get install mysql-client //客户端 2、登录 sudo cat /etc/mysql/debian.cnf 第一次登录里面有初始的用户和密码 mysql -u user -p password 3、修改密码 update user set authentication_string = '修改的密码' where user = 'root'; 4、修改账号权限 grant all privileges on *.* to root@'%' with grant option; 5、navicat连接报错提示用户不存在 create user 'mysql.infoschema'@'localhost' identified by '123456'; grant all privileges on *.* to 'mysql.infoschema'@'localhost' with grant option; 6、设置允许远程访问 vim /etc/mysql/mysql.conf.d/mysqld.cnf 注释掉 bind-address= 127.0.0.1 删除 port=3306的注释 7、设置root账号不限IP地址登录 update user set hostname='%' where user = 'root'; 8、创建用户 CREATE USER ‘username’@’host’ IDENTIFIED BY ‘password’; 9、查看端口 show global variables like 'port';
Python
-
面向对象
1.全局变量与局部变量;global调用全局变量 2.__del__ 只要在程序没有退出的时候,就执行了 del 3.__str__ 打印对象显示__str__返回的方法,默认显示内存地址 4.私有属性,也叫封装,外部调用需要在名称前面加上_类名( _类名名称)继承class A(B)A类继承了B类的属性, 5.派生类就是子 类,基类就是父类 6.方法重写,super在子类调用父类的方法 7.多态 8.区分类属性、类方法(@classmethod)与对象属性、对象方法 9.静态方法(@staticmethod)独立存在的方法 10.@property装饰器 让开发者可以使用“对象.属性”的方式操作操作对象方法,调用时不需要括号 class Rect: def __init__(self,area): self.__area = area @property def area(self): return self.__area @area.setter # 该属性就变成了具有读写功能的属性 def area(self, value): self.__area = value @area.deleter # 获得删除属性的能力 def area(self): self.__area = 0 rect = Rect(30) #直接通过方法名来访问 area 方法 print("矩形的面积是:",rect.area) # 30 del rect.area print("删除后的area值为:",rect.area) # 0 11.__new__新建对象时执行的,一般用在单例模式中 -
上下文管理器
一个类在 Python 中,只要实现以下方法,就实现了「上下文管理器协议」: __enter__:在进入 with 语法块之前调用,返回值会赋值给 with 的 target __exit__:在退出 with 语法块时调用,一般用作异常处理 我们来看实现了这 2 个方法的例子: class TestContext: def __enter__(self): print('__enter__') return 1 def __exit__(self, exc_type, exc_value, exc_tb): print('exc_type: %s' % exc_type) print('exc_value: %s' % exc_value) print('exc_tb: %s' % exc_tb) with TestContext() as t: print('t: %s' % t) # Output: # __enter__ # t: 1 # exc_type: None # exc_value: None # exc_tb: None 在这个例子中,我们定义了 TestContext 类,它分别实现了 __enter__ 和 __exit__ 方法。 这样依赖,我们就可以把 TestContext当做一个「上下文管理器」来使用,也就是通过 with TestContext() as t 方式来执行。 从输出结果我们可以看到,具体的执行流程如下: __enter__ 在进入 with 语句块之前被调用,这个方法的返回值赋给了 with 后的 t 变量 __exit__ 在执行完 with 语句块之后被调用如果在 with 语句块内发生了异常,那么 __exit__ 方法可以拿到关于异常的详细信息: exc_type:异常类型 exc_value:异常对象 exc_tb:异常堆栈信息 我们来看一个发生异常的例子,观察 __exit__ 方法拿到的异常信息是怎样的: with TestContext() as t: # 这里会发生异常 a = 1 / 0 print('t: %s' % t) # Output: # __enter__ # exc_type: <type 'exceptions.ZeroDivisionError'> # exc_value: integer division or modulo by zero # exc_tb: <traceback object at 0x10d66dd88> # Traceback (most recent call last): # File "base.py", line 16, in <module> # a = 1 / 0 # ZeroDivisionError: integer division or modulo by zero 从输出结果我们可以看到,当 with 语法块内发生异常后,__exit__ 输出了这个异常的详细信息,其中包括异常类型、异常对象、异常堆栈。如果我们需要对异常做特殊处理,就可以在这个方法中实现自定义逻辑。 回到最开始我们讲的,使用 with 读取文件的例子。之所以 with 能够自动关闭文件资源,就是因为内置的文件对象实现了「上下文管理器协议」,这个文件对象的 __enter__ 方法返回了文件句柄,并且在 __exit__ 中实现了文件资源的关闭,另外,当 with 语法块内有异常发生时,会抛出异常给调用者。 class File: def __enter__(self): return file_obj def __exit__(self, exc_type, exc_value, exc_tb): # with 退出时释放文件资源 file_obj.close() # 如果 with 内有异常发生 抛出异常 if exc_type is not None: raise exception 打开文件open(路径,r/w/a) Readline读取一行, readlines读取全部行并以列表的形式返回 -
Python 迭代器
迭代器是一种对象,该对象包含值的可计数数字。迭代器是可迭代的对象,这意味着您可以遍历所有值。
从技术上讲,在 Python 中,迭代器是实现迭代器协议的对象,它包含方法
__iter__()和__next__() -
pow(3,2,8) 3的2次方除以8
-
@parameterized.parameterized.expand() unittist中的参数化
-
try except else finally
-
raise exception(””)
-
x, y = y, x #这样就可以直接互换两个变量的值了
-
logging
import datetime import os import logging import time from logging import handlers # 1、创建日志器 logger = logging.getLogger('admin') # 2、设置日志器级别 # DEBUG、INFO、WARNING、ERROR、CRITICAL从低到高五种级别 logger.setLevel(logging.DEBUG) # 3、创建两个处理器(输出到控制台以及输出到文件) # 3.1 创建输出到控制台的处理器 sf = logging.StreamHandler() # 3.2 创建输出到文件的处理器 # hf = logging.FileHandler('%s/%s.log' % (os.getcwd(), datetime.datetime.now().strftime('%Y-%m-%d_%H.%M.%S.%f'))) # hf = logging.FileHandler('{}/{}.log'.format(os.getcwd(),datetime.datetime.now().strftime('%Y-%m-%d_%H.%M.%S.%f'))) # 文件命名不能有< > / \ | : " * ? 特别注意冒号 """ %y 不带世纪的十进制年份(值从0到99) %Y 带世纪部分的十制年份 %m 十进制表示的月份 %b 月份的简写; 如4月份为Apr %B 月份的全称; 如4月份为April %a 星期几的简写;如 星期三为Web %A 星期几的全称;如 星期三为Wednesday %d 十进制表示的每月的第几天 %D 月/天/年 %H 24小时制的小时 %I 12小时制的小时 %M 十时制表示的分钟数 %S 十进制的秒数 %T 显示时分秒:hh:mm:ss %f 显示毫秒 """ # 3.3 创建输出到文件的处理器并根据时间切分文件 hf = logging.handlers.TimedRotatingFileHandler('{}/log.log'.format(os.getcwd()), when='S', interval=5, backupCount=3) # when 时间间隔的单位'S'秒、'M'分、'H'时、'D'天、'W0'-'W6'周一至周日、'midnight'每天的凌晨 # interval 时间的数量 ,backupCount决定了能留几个日志文件,超过数量就会丢弃掉老的日志文件。 # 4、设置级别 sf.setLevel(logging.INFO) hf.setLevel(logging.INFO) # 5、创建格式器 fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s' formatter = logging.Formatter(fmt=fmt) # 6、添加格式器到处理器当中 sf.setFormatter(formatter) hf.setFormatter(formatter) # 7、将处理器添加到日志器 logger.addHandler(sf) logger.addHandler(hf) # 8、输出日志信息 # logger.info("这是一条信息级别的日志") # logger.warning("这是一条警告级别的日志") -
Adb
-
adb devices 常看手机的设备ID名称以及状态
emulator-5554 device emulator-5554表示的是手机设备的ID名称, device表示设备处于在线状态,如果不在线显示的是offline adb start-server 启动adb服务 adb kill-server 关闭adb 服务 -
获取包名和界面名令格式
windows命令一:adb shell dumpsys window windows | findstr mFocusedApp windows命令二: adb shell dumpsys window |findstr "usedApp" LINUX/MacOS命令一: adb shell dumpsys window windows | grep mFocusedApp LINUX/MacOS命令二: adb shell dumpsys window | grep "usedApp 包名为:.com.android.settings 界面名为: .Settings -
通过aapt获取app的包名和界面名
aapt dump badging D:\BaiduNetdiskDownload\apptools\apk\xuechebu.apk 后面表示的是app安装包的路径及名称 包名:package: name='com.bjcsxq.chat.carfriend' package:name 后面的字符串表示的是app的包名 界面名:launchable-activity: name='com.bjcsxq.chat.carfriend.module_main.activity.SplashActivity' launchable-activity: name后面的字符串是界面名 -
安装卸载app
app安装 adb install 路径/app安装包名称 app卸载 adb uninstall 包名 -
上传下载文件
将电脑上的文件上传到手机 adb push 电脑上的文件路径 手机的路径 例子:adb push ./monkey.txt /sdcard 从手机上下载文件到本地 adb pull 手机的文件路径 电脑的文件夹路径 例子:adb pull /sdcard/monkey.txt D:\opt -
查看日志信息
adb logcat 来查看相关的日志信息 -
测试app的启动速度(性能测试)
测试app启动速度的命令: adb shell am start -W 包名/界面名 Starting: Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] cmp=com.baidu.homework/.activity.user.passport.ChoiceLoginModeActivity } Status: ok Activity: com.baidu.homework/.activity.user.passport.ChoiceLoginModeActivity ThisTime: 3345 TotalTime: 3345 WaitTime: 3378 需要大家关注的是TotalTImie的时间值,那么在实际的测试过程中,会进行多次测试,然后取平均值。 -
稳定性测试 (8小时)
monkey集成在adb工具当中,主要用来做稳定性测试用的, monkey是通过java语言编写的一种稳定性测试工具。主要用来测试app会不会出现crash(崩溃)的情况。相当于让一只猴子来随机操作app,所有的操作都有可能出现,长时间的操作来测试app会不会出现问题。 monkey常用的参数 -p 参数 对指定的app进行随机操作 adb shell monkey -p com.baidu.homework 100 (100次随机事件) -v 参数 表示的是记录信息的级别 level 0:adb shell monkey -p com.baidu.homework -v 100 默认级别 level 1: adb shell monkey -p com.baidu.homework -v -v 100 打印出来的信息会比较详细,只打印跟本程序相关的日志信息 level 2: adb shell monkey -p com.baidu.homework -v -v -v 100 打印出来的信息会更多,会显示出其他程序运行的信息 -s 用于指定伪随机数。如果两次的伪随机数相同,那么两次的操作步骤、流程、操作事件完全一样。 主要的作用,就是用来复现上次的问题 adb shell monkey -p com.baidu.homework -v -v -s 10 100 --throttle 用于指定随机事件的间隔时间, 单位是毫秒 adb shell monkey -p com.baidu.homework -v -v --throttle 3000 -s 10 100 组合使用: adb shell monkey -p com.baidu.homework --throttle 500 --pct--touch 10 --pct-motion 50 -v -v -s 100 300> log.log --pct-touch 10 触模(10表示的是整个随机同件中的百分比) --pct-motion 50 滑屏(50表示的是整个随机同件中的百分比) 日志分析 如果在日志里面出现了 ANR(application not responsing) 如果日志中出现了Exception,可能程序崩溃 -
模拟点击事件
adb shell input tap x y # x y表示的是坐标点,参数之间用空格隔开模拟滑屏事件(参数之间用空格隔开)
-
adb shell input swipe startx starty endx endy startx, starty 表示的是起始点坐标,endx,endy表示的是终点坐标 -
模拟键盘操作
adb shell input keyevent 键值(3表示的HOME键,4表示的返回键,66表示的回车键) -
模拟输入操作
adb shell input text 内容(内容表示要输入的内容,另外输入的内容不能是中文) -
如果电脑上面连接了多个模拟器或者是手机。切换模拟器,那么需要加上一个参数-s device_name
adb -s emulator-5554 shell input keyevent 4
Git
-
git全局设置
git config --global user.name "yanhuibiao" git config --global user.email "772383792@qq.com" -
git init创建项目后会在对应的目录下自动创建.git目录,.git目录主要用来存放git的相关操作信息。
-
查看状态:git status 用来查看git仓库的状态
-
添加文件到缓存区:git add 文件名 或者git add . (.号代表的是所有文件)
-
添加到仓库 git commit -m “msg”
-
查看版本信息: git branch
创建版本分支: git branch dev_branch / git branch test_branch 强制将master切换到HEAD后退4步的位置:git branch -f master HEAD~4 切换到分支: git checkout dev_branch / git checkout test_branch 切换到HEAD:git checkout 哈希 -
git恢复特定的版本
git log 查看提交的历史版本 git reflog 来查看是全部的提交版本信息 git reset hash值前6位 git reset 通过把分支记录回退几个提交记录来实现撤销改动。你可以将这想象成“改写历史”。git reset 向上移动分支,原来指向的提交记录就跟从来没有提交过一样。 为了撤销更改并分享给别人,我们需要使用 git revert c1。如下图也就是说 C2' 的状态与 C1 是相同的。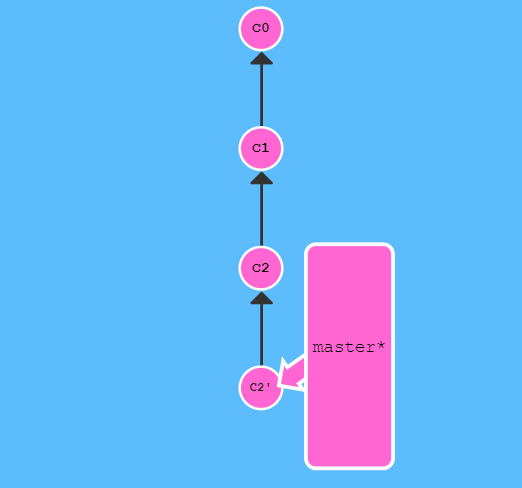
-
git cherry-pick <提交号>...如果你想将一些提交复制到当前所在的位置(
HEAD)下面的话, Cherry-pick 是最直接的方式了。 -
执行以下两条命令,可以将本地仓库上传到远端仓库
git remote add origin https://gitee.com/liaohui3389/ui_test.git git push -u origin master # 需要指定特定的分支版本, master表示的是主干分支 -
删除远程 Git 仓库,在切换git库的时候使用
git remote rm origin
-
将远端的仓库下载的本地
git clone 远端仓库地址,第一次执行时,会要求你输入远端仓库平台的用户名和密码 -
合并
$ git checkout master # 切换到master分支 $ git merge experiment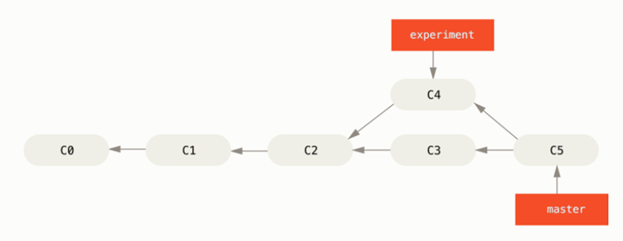
-
变基
$ git checkout experiment # 切换到experiment分支 $ git rebase master git rebase -i HEAD~4 --interactive 的 rebase 命令, 简写为 -i 如果你在命令后增加了这个选项, Git 会打开一个 UI 界面并列出将要被复制到目标分支的备选提交记录,它还会显示每个提交记录的哈希值和提交说明,提交说明有助于你理解这个提交进行了哪些更改。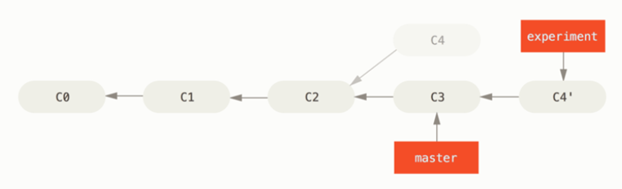
Appium
-
都是
driver = webdriver.Remote(http://127.0.0.1:4723/wd/hub, { "platformName": "android", # 表示的是android 或者ios "platformVersion": "7.1.2", # 表示的是平台系统的版本号 "deviceName": "emulator-5554", # 表示的是设备的ID名称(如果只有一个设备可以用****来代替) "appPackage": "com.vondear.onemap", # 表示app的包名 "appActivity": ".activity.ActivityLogin", # 表示的是app的界面名 "noReset": True, # 用来记住app的session,如果有登陆或做过初始化的操作,为True时,后面不需要再操作 "resetKeyboard": True, # 重置设备的输入键盘 "unicodeKeyboard": True, # 键盘编码 "automationName": "Uiautomator2"} # 获取toast消息 -
重新打开一个:appdriver.start_activity(appPackage, appActivity)
-
将应用至于后台多少秒:driver.background_app(seconds)
-
获取元素的位置 :element.location;# 返回的值是一个字典,字典中包含x和y ,x和y表示的是元素在手机屏幕左上角的点的坐标
-
获取取元素的大小 :element.size;# 返回值是一个字典,字典中会包含 width和height,width表示的宽度,height表示的高度
-
获取元素的属性值 :element.get_attribute(“attribute”); # attribute表示的是属性名
-
获取手机分辨率 :driver.get_window_size();# 返回的值是字典类型, 包含 height 和 width 高度和宽度的值
-
获取手机截图 :driver.get_screenshot_as_file(filename);# 注意事项:1、路径必须手动创建 2、文件名称必须是以PNG结尾
-
获取手机网络 :driver.network_connection

-
设置手机网络 :driver.set_network_connection(connectionType) ;# connectionType网络类型的值
-
模拟键盘操作,常用的三个键值:3 HOME键,4 返回键 , 66 回车键
driver.press_keycode(键值) -
手机通知栏操作 :driver.open_notifications()
-
swipe滑动事件
driver.swipe(startx, starty, endx, endy, duration=None) 封装一个边滑动边查找的方法 def swipe_find(driver, element, element_info): ele_size = element.size # 获取元素大小 width = ele_size["width"] # 获取元素的宽度 height = ele_size["height"] # 获取元素的高度 获了element元素左上角点的坐标 ele_position = element.location x = ele_position["x"] # 获取左上角点的x坐标值 y = ele_position["y"] # 获取左上角点的y坐标值 start_x = x + width*0.9 # 获取的是起始点X的值 y = y + height*0.5 # 获取的是起始及终止点的Y的值 end_x = x + width*0.1 # 获取的是终止点X的值 while True: page = driver.page_source # 记录查找前的页面资源,通过对比页面资源来退出死循环 try: driver.find_element(*element_info).click() # 如果有找到对应的元素那么点击并返回 return True except Exception as e: print("没有找到该元素!") driver.swipe(start_x, y, end_x, y, duration=1000) # 没有找到元素,那么滑屏后再对比并重新查找 time.sleep(1) if page == driver.page_source: print("滑屏操作完成且没有找到元素信息") return False -
scroll滑动事件
driver.scroll(source_element, target_element) scroll无法设置滑动的持续时间,带有一定惯性。 主要用于IOS中,android高版本系统可以使用。 -
drag_and_drop拖拽事件
从一个元素滑动到另外一个元素的位置 driver.drag_and_drop(source_element, target_element) source_element 表示的是被拖动的元素对象 target_element 表示的是目标元素对象 -
高级手势操作
实现步骤: 1、创建TouchAction对象 2、调用手势方法 3、调用perform() 执行操作 -
轻敲操作
action = TouchAction(driver) 创建建手势对象action.tap(element=None, x=None, y=None, count=1) 调用轻敲手势方法,传入的是一个元素对象或者是一个坐标点count表示的是轻敲的次数, 默认值为1. 调用perform()执行轻敲操作action.perform() -
按下和抬起操作
按下:press(element, x, y) 抬起:release() TouchAction(driver).press(x=477, y=489).release().perform() 按下和抬起可以结合起来使用,达到点击的效果 调用perform()执行 -
webview操作(H5)
环境安装: 1、需要查看手机或者模拟器上webView的版本 (webView的版本必须要与chromedriver的版本配套) 2、查看H5页面的元素信息 在手机或者模拟器当中打开H5的页面 在PC的chrome浏览器当中,打开对应的地址:chrome://inspect/#devices 需要越狱 通过devtools来查看对应的元素信息。 -
长按操作
long_press(element, x=None, y=None, duration=1000) element表示的是元素对象x, y表示的是坐标点duration表示的是长按的时长,单位是毫秒 TouchAction(driver).long_press(x=650, y=650, duration=2000).perform() -
模拟手指在手机屏幕上移动的过程
move_to(element, x=x, y=y) ele表示的是元素对象, x和y表示的是坐标点。二选其一。 移动的操作是需要结合press和release一起使用。 TouchAction(driver).press(x=260,y=720).wait(500).move_to(x=540,y=720).wait(500).move_to(x=820,y=720).release().perform() -
toast操作
获取toast消息,在初始化配置中需要增加一个配置项。否则定位不到。 "automationName": "Uiautomator2"
Selenium
-
find_element_by_xpath(xpath) 绝对路径 表达式是以 /html开头,元素的层级之间是以 / 分
隔相同层级的元素可以使用下标,下标是从1开始.需要列出元素所经过的所有层级元素 , 工作当中, 一般不使用 绝对路径 例:/html/body/div/fieldset/form/p[1]/input 相对路径 匹配任意层级的元素, 是以 //tag_name或者//* 开头也可以使用下标,下标是从1开始。例子://p[5]/button -
XPATH扩展
//*[text() = 'value'] value表示的是要定位的元素的全部文本内容. //*[contains(@attribute,'value')] attribute表示的属性名称, value表示的是字符串要定位的元素中,attribute属性的属性值包含了value的内容。 //*[starts-with(@attribute,'value')] attribute表示的属性名称, value表示的是字符串要定位的元素,attribute属性的属性值是以value开头 -
CSS定位
id选择器:#id #表示通过元素的ID属性进行元素选择 id表示的的id属性的属性值 class选择器:表达式:.class .表示通过元素的class属性进行元素选择,class表示的class属性的其中一个属性值 层级选择器: 父子层级关系选择器表达式: element1>element2 通过element1来找element2,并且element2是element1的直接子元素 隔代层级关系选择器表达式: element1 element2 通过element1来找element2, 并且element2是element1的后代元素 input[type^='value'] input表示标签名称,type表示属性名称, value表示的文本内容查找元素type属性值是以value开头的元素 input[type$='value'] input表示标签名称,type表示属性名称, value表示的文本内容查找元素type属性值以value结尾的元素 input[type*='value'] input表示标签名称,type表示属性名称, value表示的文本内容查找元素type属性值包含value的元素 -
鼠标操作实现方式 selenium提供鼠标操作的方法及步骤
需要导入ActionChains类通过ActionChains :from selenium.webdriver import ActionChains 实例化鼠标对象 action = ActionChains(driver) # driver表示的是浏览器驱动对象 调用鼠标的事件方法: 调用右击事件方法 action.context_click(element) # element表示是元素对象 调用鼠标双击事件方法action.double_click(element) 调用鼠标拖动事件方法 action.drag_and_drop(source, target) # source表示的是源元素, 被拖动的元素,target表示是目标源,也就是要拖动到哪个元素上。 调用鼠标悬停事件方法 action.move_to_element(element) 调用鼠标单元素拖动事件方法action.drag_and_drop_by_offset(element, x, y) x, y 表示的元素 拖动时横向和纵向移动的距离,单位为像素, 调用鼠标的执行方法action.perform() -
键盘操作
调用键盘操作的快捷键的方法 element.send_keys(快捷键的键值) 需要导入Keys类, 第一个字母是大写from selenium.webdriver.common.keys import Keys 单键值:直接传入对应的键值 组合键:键值之间由逗号分隔send_keys(Keys.CONTROL, Keys.SHIFT, 'i') 常用的快捷键 1. send_keys(Keys.BACK_SPACE) 删除键(BackSpace) 2. send_keys(Keys.SPACE) 空格键(Space) 3. send_keys(Keys.TAB) 制表键(Tab) 4. send_keys(Keys.ESCAPE) 回退键(Esc) 5. send_keys(Keys.ENTER) 回车键(Enter) 6. send_keys(Keys.CONTROL,'a') 全选(Ctrl+A) 7. send_keys(Keys.CONTROL,'c') 复制(Ctrl+C) 8. send_keys(Keys.CONTROL, 'v') 粘贴 -
隐式等待:driver.implicitlty_wait(timeout) # timeout表示的是最长的等待时间,单位为S
-
显示等待:WebDriverWait(driver, timeout, poll_frequency=0.5).until(lambda x:x.find_element(By.ID, “userA”))
-
下拉选择实现步骤:
1、导入Select类 2、实例化select对象 select=Select(element) # element对象表示的是select元素对象 3、通过select的相关方法选择option选项 select.select_by_index(index) 参数index表示的option索引 select.select_by_value(value) 参数value表示的是option元属中value的属性值 select.select_by_visible_text(visible_text ) 参数visible_text表示的是option的文本内容 -
弹出框处理步骤:
driver.switch_to.alert 获取弹出框对象 处理弹出框 alert.text 获取弹出框提示信息 alert.accept() 弹出框的确定按钮 alert.dismiss() 取消弹出框 -
selenium执行JavaScript脚本的方法
1.1、滚动条实现步骤 定义js:js = "window.scrollTo(0, 2000)" # 如果想要移动到最下方,y值给最大值就可以了。 1.2、设置元素是否可见 document.getElementById('xxx').style.display = "none"; --->内容不可见 document.getElementById('xxx').style.display = ""; --->内容可见(再次显示时保持设置的格式) document.getElementById('xxx').style.display='block'; --->内容可见(再次显示时,没有以前设置的格式) 1.3、设置元素是否可用 document.getElementById('xxx').disabled = true; --->内容可用 document.getElementById('xxx').disabled = false; --->内容不可用 2、执行js:driver.execute_script(js) -
frame切换实现方法:
driver.switch_to.frame(frame_reference) --> 切换到指定frame的方法frame_reference:可以为frame框架的name、id或者定位到的frame元素 driver.switch_to.default_content() --> 恢复默认页面方法 -
窗口操作的三种方法
获取当前窗口句柄:driver.current_window_handle 获取所有窗口句柄: driver.window_handles 返回的是一个列表 切换窗口句柄: driver.switch_to.window(window_handle),window_handle表示的是要切换到哪个窗口句柄,窗口句柄:由操作系统生成的一串唯一识别码,是一串字符 -
载图方法: driver.get_screenshot_as_file(filename),截图的文件名必须是以PNG结尾,filename中的文件目录必须手动创建
-
selenium操作cookie
driver.get_cookie(name) 获取指名称的cookie信息,返回的是一个字典 driver.get_cookies() 获取的是所有cookie的信息,返回的是一个列表 driver.add_cookie(dict_cookie) 往浏览器驱动增加cookie, dict_cookie是一字典 注意事项:如何确认哪个cookie是用来控制用户权限的,针对登陆的前后的cookie进行对比,比登陆之前多的cookie都可以用来使用控制用户权限。手动登陆之后不能退出,退出之后就相当于cookie无效了 -
无法定位元素的几种解决方案
(1)WebDriver只能在一个页面上对元素识别与定位,对于frame/iframe表单内嵌的页面元素无法直接定位。
解决方法:driver.switch_to.frame(id/name/obj) switch_to.frame()默认可以直接取表单的id或name属性。如果没有可用的id和name属性,可以先定位到frame/iframe,再将定位对象传给switch_to.frame(对象)方法。xf = driver.find_element_by_xpath('//*[@class="if"]') driver.switch_to.frame(xf) driver.switch_to.parent_frame() 切到父frame。影响性能,可以提给开发,让其改进。 driver.switch_to.default_content() 跳回最外层的页面(2)页面跳转到新标签页,或弹出警告框等
在页面操作过程中有时候点击某个链接会弹出新窗口,这时就需要切换焦点到新窗口上进行操作。 解决方法1 driver.switch_to.window(window_handle)切换到新窗口。 首先获取当前窗口的句柄driver.current_window_handle,接着打开弹出新窗口,获得当前打开的所有窗口的句柄driver.window_handles。通过for循环遍历handle,如果不等于第一次打开窗口的句柄,那么一定是新窗口的句柄,因为执行过程只打开了两个窗口;改变条件,如果等于第一次打开窗口的句柄,那么可以切换回第一次打开的窗口。 解决方法2 对于JavaScript生成的alert、confirm以及prompt,无法使用前端工具对弹出窗口进行定位的,使用driver.switch_to.alert方法定位弹出框。 alert的方法有: .accept() '等同于点击“确认”或“OK”' .dismiss() '等同于点击“取消”或“Cancel”' .text '获取alert文本内容,对有信息显示的alert框' .send_keys(text) '发送文本,对有提交需求的prompt框' .authenticate(username,password) '验证,针对需要身份验证的alert'(3)页面元素失去焦点导致脚本运行不稳定
解决方法: `driver.switch_to.active_element` 遇到脚本不稳定,有时会失去焦点导致测试失败的情况下,可以先切到焦点元素再进行操作。注意.active_element后面不带括号()。 下面是一个参考案例: '最初的 “右击鼠标 → 新建文件夹 → 输入文件夹名称” 的代码' l = driver.find_element_by_id('pm_treeRoom_1_span') ActionChains(driver).context_click(l).perform() driver.find_element_by_class_name('fnew').click() time.sleep(2) driver.find_element_by_xpath('//*[@id="pm_treeRoom_1_ul"]/li[...]').send_keys('filename') time.sleep(2) 结果这种操作总会导致输入框失去焦点,直接消失,更不能send_keys进去了,直接报错。'修改后的代码如下' driver.find_element_by_class_name('fnew').click() time.sleep(2) driver.switch_to.active_element.send_keys('filename') time.sleep(2)(4)使用Xpath或CSS定位
find_element_by_xpath("//标签[属性='值']") 使用Xpath/CSS方法,非常适合定位属性值动态生成、不容易定位的元素。如果不想指定标签,则可以使用“*”代替,使用xpath不局限于id、name和class这三个属性,元素的任意属性值都可以使用,只要它能唯一的标识一个元素。 解决方法1: 如果一个元素没有唯一属性,那么我们可以一级一级向上查找,直到找到可以唯一定位元素的属性,再向下查找其子元素。 find_element_by_xpath("//form[@id='form']/span[2]/input") 首先通过唯一标识属性id=form定位最外层元素,接着找到最外层元素下的第2个span标签的元素为父元素,最后向下查找定位到父元素下标签为input的子元素。 解决方法2: 如果一个属性不能唯一地区分一个元素,那么使用多个属性来唯一地定位一个元素。 `find_element_by_xpath("//input[@id='kw'and@class='su']/span/input")` 首先找到标签为input,id=kw且class=su的元素,接着找到其下标签为span的子元素,继续向下查找找到标签为input的子元素。 解决方法3:检查Xpath描述是否有误,导致无法定位到元素。(5)页面还没加载出来就对页面上的元素进行操作
因为加载元素延时造成的脚本失败,我们可以通过设置等待时间来提升自动化脚本的稳定性。
-
解决方法1:
WebDriverWait()显示等待。等待单个的元素加载,通常配合until()、until_not()方法使用。
即,WebDriverWait(driver, 超时时长, 调用频率, 忽略异常).until(可执行方法, 超时时返回的信息) WebDriverWait(driver,5,1).until(expected_conditions.presence_of_element_located(By.ID,'kw')) 最长等待时间为5s,每隔1秒检查一次id='kw'的元素是否被加载在DOM树里(并不代表该元素一定可见)。最常用的method是expected_conditions类提供的预期条件判断。 或者 WebDriverWait(driver,timeout,1).until(lambda x: x.find_element(By.XPATH, message)) is_disappeared= WebDriverWait(driver, 30, 1, (ElementNotVisibleException)).until_not(lambda x: x.find_element_by_id('someId').is_displayed()) 最长等待时间为30s,每隔1秒检查一次id='someId'的元素是否从DOM树里消失,忽略默认异常信息NoSuchElementException和指定的异常信息ElementNotVisibleException。此处匿名函数lambda的用法具体参考Python语法。- 解决方法2:
driver.implicitly_wait(秒) 隐式等待。 全局等待,对所有元素设置超时时间,等待页面的加载,因此只需要设置一次即可。这里的时间是最长等待时间(非固定等待时间)。- 解决方法3:
sleep(秒)线程等待(强制等待)。 休眠固定的时间,使用时需要先引入time模块的sleep方法from time import sleep。(6)元素被遮挡,不可用,不可见
- 解决方法1: driver.maximize_window()由于窗口大小改变引起的页面元素布局发生变化,被测元素被遮挡,可以先将窗口最大化,再进行元素定位。 - 解决方法2: .is_enabled()由于业务原因元素在某些情况下不可用(元素属性disabled,灰显),首先检查测试步骤是否符合业务逻辑,其次确认是否为业务流程上的Bug。 - 解决方法3: .is_displayed()对于属性不一定可见的元素,在定位前首先判断其属性是否可见,是否被隐藏。 - 解决方法4: 由于布局不合理导致的元素被遮盖、或是元素本身缺失引起的无法定位问题属于Bug,可以提给开发让其改进。(7)用WebDriver调用JavaScript代码代替无法实现的功能
WebDriver提供了driver.execute_script()方法来执行JavaScript代码。 解决方法: 如果页面内容过长,需要下拉,窗口最大化也无法查看到所有元素,可以通过执行JavaScript脚本实现滚动条的拖动等动作。 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") 以上语句实现了拉动页面到底部的功能,其中window.scrollTo(左边距,上边距)是JavaScript中用于设置浏览器窗口滚动条的水平和垂直位置的代码。text = "input text" driver.execute_script("var obj=document.getElementById('text'); obj.value=' " + text + " ';") 假设一个输入框可以通过id='text'将其定位,却不能通过send_keys()输入文本内容,可以借助JavaScript代码来实现。video = driver.find_element_by_xpath("body/Section[1]/div/video") url = driver.execute_script("return arguments[0].currentSrc;", video) print(url) '返回文件播放地址' print("start") driver.execute_script("return arguments[0].play()", video) '播放视屏' sleep(15) '播放15秒钟' print(stop) driver.execute_script("arguments[0].pause()", video) '暂停视屏' ... 以上实现了HTML5视屏<video>标签的部分测试,更多内容参考HTML DOM Video对象。 其中arguments是JavaScript的内置对象。因为将video对象传给了arguments,所以arguments[0]相当于JavaScript脚本的document.getElementsByTagName("video")。JavaScript不支持重载,使用arguments对象可以模拟函数重载效果。(8)WebDriver无法操作Windows控件
文件的普通上传和下载(参考How to auto save files using custom Firefox profile ?),可以通过`.send_keys('本地路径')和find_element_by_partial_link_text('下载链接名').click()`实现。 解决方法: 对于插件上传,需要操作Windows控件的,可以通过安装Autoit工具、编写脚本、保存为“.au3”文件、转换成“.exe”文件,再由自动化脚本os.system("D:\\upfile.exe")实现上传/下载。 通过autoit来获取弹出的窗口 autoit.win_wait_active("打开", 3) # 3表示的是时间,秒为 单位 # 在文件选择输入框中输入文件的地址及文件名称 autoit.control_send("打开", "Edit1", r"C:\Users\LiaoFei\Pictures\Saved Pictures\333.jpg") # 在弹出窗口中点击打开按钮 autoit.control_click("打开", "Button1") 虽然这种方法可以解决文件上传、下载的操作问题,但是并不推荐。因为通过python调用exe程序并不在python的可控范围内,执行多长时间,执行过程是否出错,都无从自动化过程得知。(9)firefox安全性强,不允许跨域调用出现报错
错误描述:

-
```
解决办法:
Firefox 要取消XMLHttpRequest的跨域限制的话,
- 第一、从 about:config 里设置 signed.applets.codebase_principal_support = true;(地址栏输入about:config 即可进行firefox设置);
- 第二、在open的代码函数前加入类似如下的代码:
try {
netscape.security.PrivilegeManager.enablePrivilege("UniversalBrowserRead");
} catch (e) {
alert("Permission UniversalBrowserRead denied.");
```
-
当alert = driver.switch_to.alert报错UnexpectedAlertPresentException,可尝试使用下面代码
try: print(driver.switch_to.alert.text) except UnexpectedAlertPresentException: print(driver.switch_to.alert.text) driver.switch_to.alert.accept()
Markdown
-
如何让# * >等符号原样显示?
1、加" \ "[转义]: 2、可以使用反引号" ` "包裹需要转义的内容,反引号位于键盘左上角Esc下面的位置 示例: \# \* \> `#` -
有序列表用代码表示
1.加上空格 2.加上空格 -
空格与换行的代码
空格  空行
Pytest+Allure
-
避免路径问题可在项目目录中添加conftest.py文件
-
[pytest] \# 添加命令行参数 addopts = -s -v --html=report/report.html \# 文件搜索路径 testpaths = ./scripts \# 文件名称 python_files = test_*.py \# 类名称 python_classes = Test* \# 方法名称 python_functions = test_* -
能够生成 pytest-html 测试报告
命令 pip3 install pytest-html 进行安装 在配置文件中的命令行参数中增加 --html=用户路径/report.html pytest.ini addopts = -s --html=report/report.html -
控制函数执行顺序
使用命令 pip3 install pytest-ordering 进行安装 1. 标记于被测试函数,@pytest.mark.run(order=序号) 2. 根据order传入的参数来解决运行顺序 3. order值全为正数或全为负数时,运行顺序:值越小,优先级越高 4. 正数和负数同时存在:正数优先级高 -
失败重试
应用场景 自动化测试脚本可能会使用到网络,如果网络不好可能最终会使脚本不通过。像这种情况可能并不是脚本本身的问题,仅仅是因为网络忽快忽慢,那么我们可以使用失败重试的插件,当失败后尝试再次运行。一般情况最终成功可以视为成功,但最好进行进行排查时候是脚本问题。 使用命令 pip3 install pytest-rerunfailures 进行安装 在配置文件中的命令行参数中增加 --reruns n pytest.ini addopts = -s --reruns 3 结果中R表示重试 注意点:重试时,如果脚本通过,那么后续不再重试 -
pytest 跳过函数
应用场景 同一个软件在不同的设备上可能会有不同的效果,比如,iOS 的 3d touch 操作是需要 6s 以上设备支持的,6 和 6s 都可以安装同一款应用,如果设备不支持,那么根本没有必要去测试这个功能。此时,我们可以让这种函数进行跳过。 方法名 @pytest.mark.skipif(condition, reason=None) 跳过测试函数 # 参数: # condition:跳过的条件,必传参数 # reason:标注原因,必传参数 使用方式 在需要跳过的测试脚本之上加上装饰器 @pytest.mark.skipif(condition, reason="xxx") 示例 import pytest class TestLogin: def test_a(self): # test开头的测试函数 print("------->test_a") assert 1 # 断言成功 @pytest.mark.skipif(condition=True, reason="xxx") def test_b(self): print("------->test_b") assert 0 # 断言失败 -
pytest 数据参数化
应用场景 登录功能都是输入用户名,输入密码,点击登录。但登录的用户名和密码如果想测试多个值是没有办法用普通的操作实现的。数据参数化可以帮我实现这样的效果。 方法名 @pytest.mark.parametrize(argnames, argvalues, indirect=False, ids=None, scope=None) # 参数: # argnames:参数名 # argvalues:参数对应值,类型必须为可迭代类型,一般使用list 一个参数使用方式 1. argnames 为字符串类型,根据需求决定何时的参数名 2. argvalues 为列表类型,根据需求决定列表元素中的内容 3. 在测试脚本中,参数,名字与 argnames 保持一致 4. 在测试脚本中正常使用 示例 import pytest class TestLogin: @pytest.mark.parametrize("name", ["xiaoming", "xiaohong"]) def test_a(self, name): print(name) assert 1 多个参数使用方式 示例 import pytest class TestLogin: @pytest.mark.parametrize(("username", "password"), [("zhangsan", "zhangsan123"), (" xiaoming", "xiaoming123")]) def test_a(self, username, password): print(username) print(password) assert 1 多个参数还可以将装饰器写成 @pytest.mark.parametrize("username,password",[("zhangsan", "zhangsan123"), ("xiaoming", "xiaoming123")]) 效果是一样的。 -
Allure生成测试结果文件
安装 pip install allure-pytest 1、使用步骤 1.1、将 pytest 配置文件中的命令行参数加上如下代码 --alluredir report 1.2、编写好测试脚本后,正常的在命令行中运行 pytest 即可 1.3、程序运行结束后,会在项目的report目录中生成一些json文件 2、将测试结果文件转成 html 2.1、安装 2.1.1、https://bintray.com/qameta/generic/allure2 下载 allure-2.6.0.zip 2.1.2、解压缩到一个目录 2.1.3、将压缩包内的 bin目录配置到path系统环境变量 2.1.4、右键我的电脑-属性-高级设置-环境变量-找到系统环境变量的path项-增加allure到bin目录 2.1.5、在命令行中敲allure命令,如果提示有这个命令,即为成功 2.2、使用步骤 在保证项目中的report目录下有 json文件的时候,执行以下步骤。 2.2.1、进入 report 上级目录执行命令 allure generate report/ -o report/html --clean 2.2.2、report 目录下会生成html文件夹,html下会有一个index.html,右键用浏览器打开即可。 3、参数和命令详解 3.1、addopts = -s --alluredir report 中的 --alluredir report 是什么意思? --alluredir后面的report为测试结果文件输出的目录名 3.2、allure generate report/ -o report/html --clean 是什么意思? allure generate 表示的是生成测试报告 report/ 表示的是测试报告的数据目录 -o report/html 表示将 index.html 报告生成到哪个文件夹 --clean 表示的是清除之前 report/html里面的报告文件 4、Allure 与 pytest 结合 4.1、添加测试步骤 一套登录流程需要至少三个步骤,输入用户名,输入密码,点击登录。我们可以通过添加测试步骤,让这些步骤在报告中进行体现 使用方式:在操作层中的方法上加上 @allure.step(title="测试步骤001") 装饰器 # page/login_page.py class LoginHandle(BaseHandle): def __init__(self): self.login_page = LoginPage() @allure.step(title="输入手机号") def input_mobile(self, mobile): self.input_text(self.login_page.find_mobile(), mobile) @allure.step(title="输入验证码") def input_code(self, code): self.input_text(self.login_page.find_code(), code) @allure.step(title="点击登录按钮") def click_login_btn(self): self.login_page.find_login_btn().click() 4.2、添加图片描述 如果我们想将某些操作过后的结果展现在报告上,可以使用添加图片描述的方法。 使用方式:在需要截图的地方添加如下代码: allure.attach(driver.get_screenshot_as_png(), "截图", allure.attachment_type.PNG) 核心代码 # script/test_login.py @pytest.mark.parametrize("mobile,code,username", build_data()) def test_login(self, mobile, code, username): # 登录 self.login_proxy.login(mobile, code) # 截图 allure.attach(self.driver.get_screenshot_as_png(), "截图", allure.attachment_type.PNG) # 断言 is_exist = utils.exist_text(DriverUtil.get_mp_driver(), username) assert is_exist 4.3、 添加严重级别 在工作中,我们会向开发人员提交很多 bug ,不同的 bug 优先级也应当不同,打开程序就崩溃,和关于软件的页面错了一个字。就这两者而言,崩溃肯定更严重,也更需要开发人员优先修复。那么,我可以将这些 bug 的优先级展示在报告当中。 使用方式:在测试脚本中,增加装饰器 @allure.severity(allure.severity_level.BLOCKER) 参数有五个,也对应不同的优先级,只需要将最后一个词替换即可。 1. BLOCKER 最严重 2. CRITICAL 严重 3. NORMAL 普通 4. MINOR 不严重 5. TRIVIAL 最不严重 示例 # script/test_login.py @allure.severity(allure.severity_level.BLOCKER) @pytest.mark.parametrize("mobile,code,username", build_data()) def test_login(self, mobile, code, username): logging.info("mobile={} code={} username={}".format(mobile, code, username)) # 登录 self.login_proxy.login(mobile, code) # 截图 allure.attach(self.driver.get_screenshot_as_png(), "截图", allure.attachment_type.PNG) # 断言 is_exist = utils.exist_text(DriverUtil.get_mp_driver(), username) assert is_exist
-
MongoDB
-
创建集合
MongoDB 中使用 createCollection() 方法来创建集合。
语法格式:db.createCollection(name, options)参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:
字段 类型 描述 capped 布尔 (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 autoIndexId 布尔 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 size 数值 (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段。 max 数值 (可选)指定固定集合中包含文档的最大数量。 -
删除集合
db.collection.drop() 示例>use mydb switched to db mydb >show collections mycol mycol2 >db.mycol2.drop() true > -
插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document) db.COLLECTION_NAME.save(document)- save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
- insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
3.2 版本之后新增了 db.collection.insertOne() 和 db.collection.insertMany()。
db.collection.insertOne() 用于向集合插入一个新文档,语法格式如下:
db.collection.insertOne(<document>,{writeConcern: <document>})db.collection.insertMany() 用于向集合插入一个多个文档,语法格式如下:
db.collection.insertMany( [ <document 1> , <document 2>, ... ], { writeConcern: <document>, ordered: <boolean> } )参数说明:
- document:要写入的文档。
- writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
- ordered:指定是否按顺序写入,默认 true,按顺序写入。
-
基本查询
db.集合名称.find({条件文档}) and和or一起使用 例5:查询年龄大于18或性别为男生,并且姓名是郭靖 db.stu.find({$or:[{age:{$gte:18}},{gender:true}],name:'gj'}) 范围运算符 使用"$in","$nin" 判断是否在某个范围内 使用//或$regex编写正则表达式 db.stu.find({name:/^黄/}) db.stu.find({name:{$regex:'^黄'}}) 自定义查询 使用$where后面写一个函数,返回满足条件的数据 查询年龄大于30的学生 db.stu.find({ $where:function() { return this.age>30; } }) -
Limit
- 方法limit():用于读取指定数量的文档
- 语法:参数NUMBER表示要获取文档的条数
db.集合名称.find().limit(NUMBER) -
SKIP
- 方法skip():用于跳过指定数量的文档
db.集合名称.find().skip(NUMBER) -
投影
db.stu.finf({},{_id:0,name:1,age:1}) -
排序
- 方法sort(),用于对结果集进行排序
db.集合名称.find().sort({字段:1,...}) -
消除重复
- 方法distinct()对数据进行去重
db.集合名称.distinct('去重字段',{条件}) -
聚合 aggregate
- 聚合(aggregate)主要用于计算数据,类似sql中的sum()、avg()
db.集合名称.aggregate({管道:{表达式}})
管道
- 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的输入
ps ajx | grep mongo
- 在mongodb中,管道具有同样的作用,文档处理完毕后,通过管道进行下一次处理
- 常用管道
- $group:将集合中的文档分组,可用于统计结果
- $match:过滤数据,只输出符合条件的文档
- $project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
- $sort:将输入文档排序后输出
- $limit:限制聚合管道返回的文档数
- $skip:跳过指定数量的文档,并返回余下的文档
- $unwind:将数组类型的字段进行拆分
表达式
- 处理输入文档并输出
- 语法
表达式:'$列名'
- 常用表达式
- s u m : 计 算 总 和 , sum:计算总和, sum:计算总和,sum:1 表示以一倍计数
- $avg:计算平均值
- $min:获取最小值
- $max:获取最大值
- $push:在结果文档中插入值到一个数组中
- $first:根据资源文档的排序获取第一个文档数据
- $last:根据资源文档的排序获取最后一个文档数据
-
建立索引
- 创建索引
- 1表示升序,-1表示降序
db.集合.ensureIndex({属性:1})- 建立唯一索引,实现唯一约束的功能
db.t1.ensureIndex({"name":1},{"unique":true})- 联合索引,对多个属性建立一个索引,按照find()出现的顺序
db.t1.ensureIndex({name:1,age:1})- 查看文档所有索引
db.t1.getIndexes()- 删除索引
db.t1.dropIndex('索引名称') -
与python交互
- 进入虚拟环境py2_db,安装包pymongo
workon py2_db pip install pymongo- 引入模块pymongo
from pymongo import *- 主要提供如下对象用于进行交互
- MongoClient对象:用于与MongoDB服务器建立连接
- DataBase对象:对应着MongoDB中的数据库
- Collection对象:对应着MongoDB中的集合
- Cursor对象:查询方法find()返回的对象,用于进行多行数据的遍历
MongoClient对象
- 使用init方法创建连接对象
client=MongoClient('主机ip',端口)Database对象
- 通过client对象获取获得数据库对象
db=client.数据库名称Collection对象
- 通过db对象获取集合对象
col=db.集合名称- 主要方法如下
- insert_one:加入一条文档对象
- insert_many:加入多条文档对象
- find_one:查找一条文档对象
- find:查找多条文档对象
- update_one:更新一条文档对象
- update_many:更新多条文档对象
- delete_one:删除一条文档对象
- delete_many:删除多条文档对象
Cursor对象
- 当调用集合对象的find()方法时,会返回Cursor对象
- 结合for…in…遍历cursor对象
-
创建超级用户
use admin db.createUser({user: 'admin',pwd: '123',roles:[{role:'root',db:'admin'}] })启用安全认证
- 修改配置文件
sudo vi /etc/mongod.conf- 启用身份验证
- 注意: keys 和 values 之间一定要加空格,否则会解析报错
security: authorization enabled- 重启服务
sudo service mongod restart- 使用认证某个数据方式终端连接
mongo -u admin -p 123 --authenticationDatabase admin普通用户管理
- 使用超级管理员登录,然后进入用户管理操作
- 查看当前数据库的用户
use demo show users- 创建普通 用户
db.createUser({user: 'yyy',pwd: '123',roles:[{role:'readWrite',db:'demo'}] })- 退出 root 连接 使用yyy 登录
mongo -u yyy -p 123 --authenticationDatabase python_info- 切换数据库,执行命令查看效果
- 修改 yoghurt:可以修改密码, 或者roles 属性
# 修改密码 db.updateUser('yyy',{pwd: '456'}) # 修改属性 db.updateUser('yyy',{roles:[{role: 'read',db:'demo'}]}) -
Docker
-
安装
yum install epel-release -y 安装扩展源,避免yum源没有docker yum install docker -y #检测docker是否安装成功 yum list docker rpm -qa | grep docker #启动docker引擎服务 systemctl start docker.service service docker start(Linux版本6.*) #查看docker的进程 ps -ef | grep docker #查看docker的版本信息 docker version -
在docker安装nginx
#在docker仓库中搜索nginx docker search nginx #从docker仓库中下载nginx docker pull docker.io/nginx #下载的过程中太慢,可以修改镜像源 vim /etc/docker/deamon.json修改为以下内容 { "registry-mirrors":["https://registry.docker-cn.com"] } 修改完成后重启Docker引擎服务即可:service docker restart #查看nginx镜像列表和文件路径 docker images ls docker images | grep -i nginx || /var/lib/docker/image/ #基于nginx镜像启动nginx容器 docker run -itd -p 80:80 docker.io/nginx #通过浏览器访问宿主机ip+端口 run 全新启动一台容器 -i interactive交互模式 -t tty打开终端 -d detach后台启动 -p publish发布端口,将宿主机80映射至容器的80端口 #docker ps 查看容器状态,获取id #docker inspect id | grep -i ipaddr | tail -1 查看虚拟机ip 使用 docker port 可以查看指定(ID或者名字)容器的某个确定端口映射到宿主机的端口号。 #docker port bf08b7f2cd89 创建tomcat容器 #docker run -itd -p 8080:8080 docker.io/tomcat 创建一百台nginx容器 for i in $(seq 0 99);do docker run -itd -p 80$i:80 --name=web0$i --privileged nginx:latest; done -
在宿主主机内使用 docker logs 命令,查看容器内的标准输出
-
容器的使用
停止容器的命令: $ docker stop <容器 ID> 启动容器的命令: $ docker start <容器 ID> 重启容器的命令: $ docker restart <容器 ID> 进入容器 在使用 -d 参数时,容器启动后会进入后台。此时想要进入容器,可以通过以下指令进入: docker attach docker exec:推荐大家使用 docker exec 命令,因为此命令会退出容器终端,但不会导致容器的停止 docker exec -it 243c32535da7 /bin/bash 导出容器 如果要导出本地某个容器,可以使用 docker export 命令。 $ docker export 1e560fca3906 > ubuntu.tar 导入容器快照 可以使用 docker import 从容器快照文件中再导入为镜像 $ cat docker/ubuntu.tar | docker import - test/ubuntu:v1 此外,也可以通过指定 URL 或者某个目录来导入,例如: $ docker import http://example.com/exampleimage.tgz example/imagerepo 删除容器 删除容器使用 docker rm 命令: $ docker rm -f 1e560fca3906 使用 docker inspect 来查看 Docker 的底层信息。它会返回一个 JSON 文件记录着 Docker 容器的配置和状态信息。 $ docker inspect name/id -
安装完docker后,执行docker相关命令,出现下面报错:
”Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.26/images/json: dial unix /var/run/docker.sock: connect: permission denied“
docker守护进程启动的时候,会默认赋予名字为docker的用户组读写Unix socket的权限,因此只要创建docker用户组,并将当前用户加入到docker用户组中,那么当前用户就有权限访问Unix socket了,进而也就可以执行docker相关命令 sudo groupadd docker #添加docker用户组 sudo gpasswd -a $USER docker #将登陆用户加入到docker用户组中 newgrp docker #更新用户组 -
Docker 镜像使用
当运行容器时,使用的镜像如果在本地中不存在,docker就会自动从docker镜像仓库中下载,默认是从Docker Hub公共镜像源下载。 - 1、管理和使用本地 Docker 主机镜像 可以使用 docker images ls来列出本地主机上的镜像 - 2、使用镜像来创建一个容器 docker run -t -i ubuntu:14.04 /bin/bash - 3、更改后的容器。我们可以通过命令docker commit来提交容器副本 $ docker commit -m="has update" -a="runoob" e218edb10161 runoob/ubuntu:v2 各个参数说明: -m: 提交的描述信息 -a: 指定镜像作者 e218edb10161:容器 ID runoob/ubuntu:v2: 指定要创建的目标镜像名 (配合仓库推送更新后的镜像) - 4构建镜像 我们使用命令docker build,从零开始来创建一个新的镜像。我们需要创建一个Dockerfile文件 $ cat Dockerfile 每一个指令都会在镜像上创建一个新的层,每一个指令的前缀都必须是大写的。 FROM centos:6.7 RUN /bin/echo -e "LANG=\"en_US.UTF-8\"" >/etc/default/local EXPOSE 22 EXPOSE 80 CMD /usr/sbin/sshd -D 第一条FROM,指定使用哪个镜像源 RUN 指令告诉docker 在镜像内执行命令,安装了什么。。。 然后,我们使用 Dockerfile 文件,通过 docker build 命令来构建一个镜像。 docker build -t runoob/centos:6.7 . 参数说明: -t :指定要创建的目标镜像名 . :上下文路径,默认上下文路径就是 Dockerfile 所在的位置。注意:上下文路径下不要放无用的文件,因为会一起打包发送给 docker 引擎,如果文件过多会造成过程缓慢。 (我们可以使用新的镜像来创建容器) - 4、删除镜像 镜像删除使用 docker rmi命令,比如我们删除 hello-world 镜像: $ docker rmi hello-world -
容器连接
先创建一个新的 Docker 网络。 $ docker network create -d bridge test-net 连接容器 运行一个容器并连接到新建的 test-net 网络: $ docker run -itd --name test1 --network test-net ubuntu /bin/bash -
Docker 仓库管理
1. 登录和退出 登录需要输入用户名和密码,登录成功后,我们就可以从 docker hub 上拉取自己账号下的全部镜像。 $ docker login 账户:yanhuibiao 邮箱:772383792@qq.com 2. 退出 docker hub 可以使用以下命令: $ docker logout 3.推送镜像 用户登录后,可以通过 docker push 命令将自己的镜像推送到 Docker Hub。 $ docker tag ubuntu yanhuibiao/ubuntu:18.04 会创建一个Ubuntu的仓库,里面有18.04版本的镜像 $ docker push yanhuibiao/仓库名(镜像名):tagname(版本) -
镜像监测
docker stats 具体容器名称 -















 6564
6564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









