






前言
在验证安全产品检测有效性的情况下,需要获取pcap流量进行回放攻击,这时需要对攻击请求进行构造,通常可以直接打攻击到靶机上进行抓取流量保存下来。也可以通过Re2PCAP来构造,但是Re2PCAP其实还是需要本地网卡发送数据包,会容易有各种奇怪的bug。需要对多个攻击payload验证构造时,需要手动频繁操作。所以最快的方法是直接构造pcap,所以我们可以通过python 的scapy库来快速构造数据包。
TCP三次握手
构造http请求数据包前,需要完成tcp三次握手的数据包构造,网上关于tcp三次握手的基础文章很多,可以直接参考。下面就直接以三次握手原理通过scapy来构造
需要注意seq和ack的值的对应关系,代码如下:
#链路层和网络层构造 ipsrc= Ether(src=src_mac,dst=dst_mac)/IP(src=src_ip,dst=dst_ip) ipdst = Ether(src=dst_mac,dst=src_mac)/IP(src=dst_ip,dst=src_ip) # 构造SYN数据包 syn_packet = ipsrc/TCP(sport=src_port,dport=dst_port, seq=seq,flags="S") # 构造SYN/ACK数据包 syn_ack_packet = ipdst/TCP(sport=dst_port,dport=src_port, flags="SA", seq=seq2, ack=syn_packet[TCP].seq + 1) # 构造ACK数据包 ack_packet = ipsrc/TCP(sport=src_port,dport=dst_port, flags="A", seq=syn_ack_packet[TCP].ack, ack=syn_ack_packet[TCP].seq + 1)
HTTP请求和响应
http请求和响应构造时需要注意seq 的计算加上请求数据大小,代码如下:
# 构造HTTP请求报文 #http_request = "GET / HTTP/1.1\r\nHost: www.example.com\r\nConnection: close\r\n\r\n" http_request_packet = ipsrc/TCP(sport=src_port,dport=dst_port, flags=24, seq=ack_packet[TCP].seq, ack=syn_ack_packet[TCP].seq + 1)/http_request.encode() httpack = ipdst/ TCP(sport=dst_port,dport=src_port, seq=http_request_packet[TCP].ack,ack=http_request_packet[TCP].seq + len(http_request), flags='A') # 构造HTTP响应报文 #http_response = "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\nContent-Length: 0\r\nConnection: close\r\n\r\n" http_response_packet = ipdst/TCP(sport=dst_port,dport=src_port, flags=24, seq=httpack[TCP].seq, ack=httpack[TCP].ack )/http_response.encode()
TCP四次挥手
最后TCP四次挥手结束整个请求
# 构造SYN数据包 syn_packet = ipsrc/TCP(sport=src_port,dport=dst_port, seq=seq,flags="S") # 构造SYN/ACK数据包 syn_ack_packet = ipdst/TCP(sport=dst_port,dport=src_port, flags="SA", seq=seq2, ack=syn_packet[TCP].seq + 1) # 构造ACK数据包 ack_packet = ipsrc/TCP(sport=src_port,dport=dst_port, flags="A", seq=syn_ack_packet[TCP].ack, ack=syn_ack_packet[TCP].seq + 1) # 构造HTTP请求报文 #http_request = "GET / HTTP/1.1\r\nHost: www.example.com\r\nConnection: close\r\n\r\n" http_request_packet = ipsrc/TCP(sport=src_port,dport=dst_port, flags=24, seq=ack_packet[TCP].seq, ack=syn_ack_packet[TCP].seq + 1)/http_request.encode() httpack = ipdst/ TCP(sport=dst_port,dport=src_port, seq=http_request_packet[TCP].ack,ack=http_request_packet[TCP].seq + len(http_request), flags='A') # 构造HTTP响应报文 #http_response = "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\nContent-Length: 0\r\nConnection: close\r\n\r\n" http_response_packet = ipdst/TCP(sport=dst_port,dport=src_port, flags=24, seq=httpack[TCP].seq, ack=httpack[TCP].ack )/http_response.encode()
最后利用wrpcap保存到文件,整个一起构造后的效果:
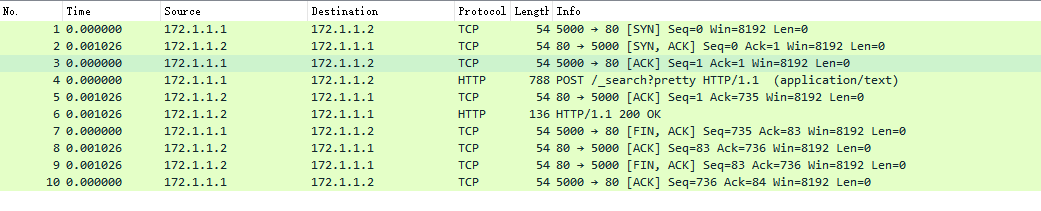
构造的坑
TCP segment of ressembled PDU问题
通过txt请求文本构造pcap时出现TCP segment of ressembled PDU,无法解析成http
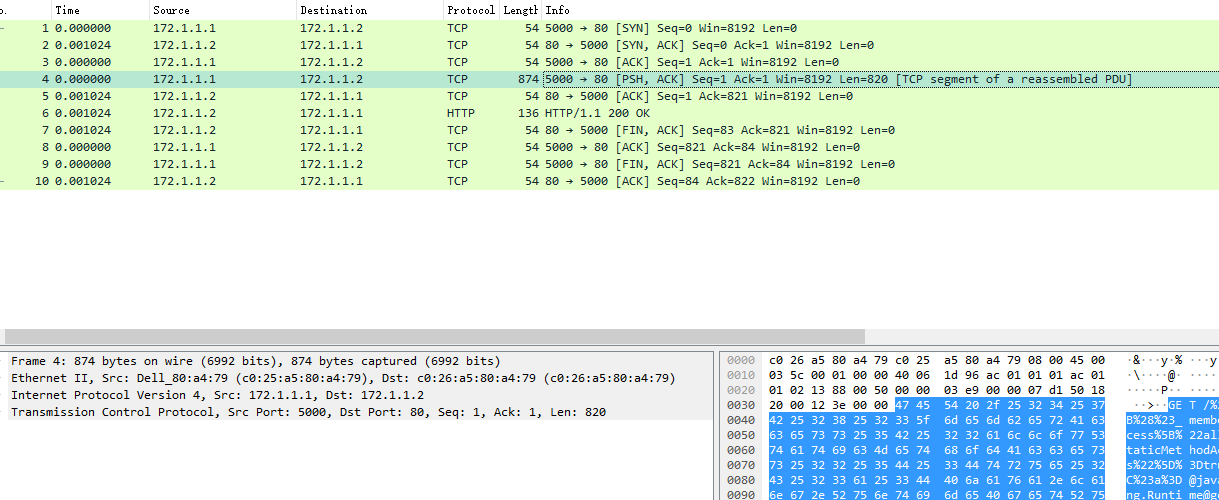
发现是txt的请求数据中Content-Length 值错误和实际对应不上导致的
所以构造前需要对txt请求文本做下简单校验和纠正,下面代码对传入文本进行Content-Length值纠正
def fix_content_length(request_body):
content_length = re.search(r'Content-Length: (\d+)', request_body)
if content_length:
if request_body[0:3] == 'GET':
request_body = re.sub(r'Content-Length: \d+', 'Content-Length: {}'.format(0), request_body)
return request_body
expected_length = int(content_length.group(1))
try:
actual_length = len(request_body.split('\r\n\r\n', 1)[1])
except:
try:
actual_length = len(request_body.split('\n\n', 1)[1])
except:
request_body+= "\r\n\r\n"
actual_length = 0
if actual_length != expected_length:
request_body = re.sub(r'Content-Length: \d+', 'Content-Length: {}'.format(actual_length), request_body)
request_body = re.sub(r'Content-MD5: .*', '', request_body) # update the Content-MD5 header
request_body = re.sub(r'Content-Encoding: .*', '', request_body) # update the Content-Encoding header
return request_body
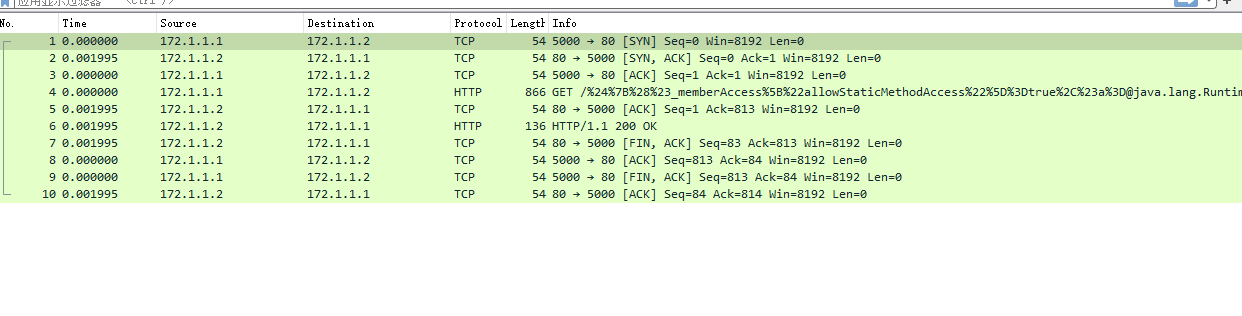
将传入请求txt文本先进行纠正后,构造的pcap正常

malformed packet MIME multipart 错误
在构造multipart类型数据时发现格式错误
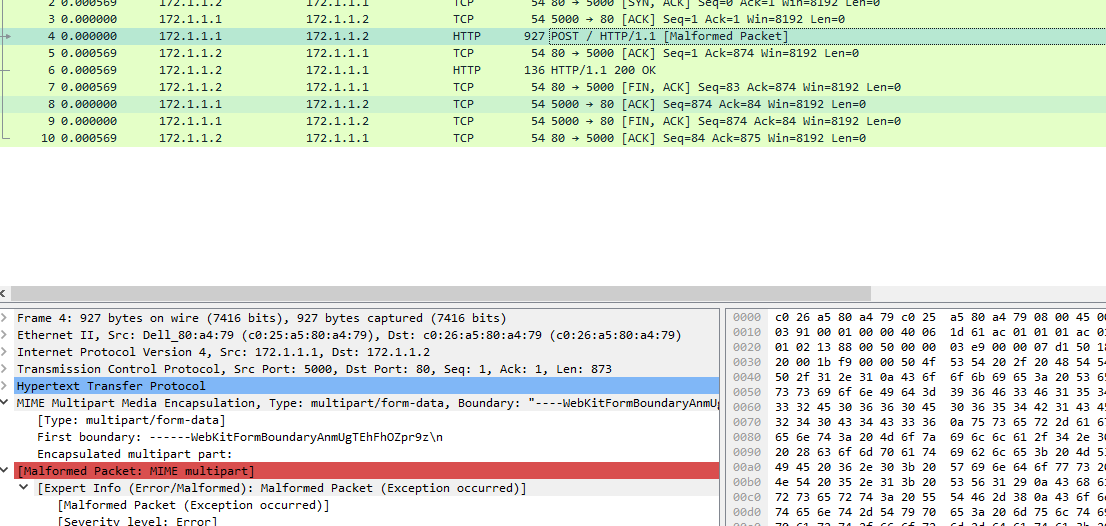
最后找到原因是 windows读取\r\n会读取成\n,但是当multipart/data类型时解析是必须是\r\n的
所以需要读取文本后replace掉所有的\n成\r\n
修复后代码
def fix_content_length(request_body):
content_length = re.search(r'Content-Length: (\d+)', request_body)
request_body = request_body.replace('\n', '\r\n')
if content_length:
if request_body[0:3] == 'GET':
request_body = re.sub(r'Content-Length: \d+', 'Content-Length: {}'.format(0), request_body)
return request_body
expected_length = int(content_length.group(1))
try:
body = request_body.split('\r\n\r\n', 1)[1]
actual_length = len(body)
except:
request_body+= "\r\n\r\n"
actual_length = 0
if actual_length != expected_length:
request_body = re.sub(r'Content-Length: \d+', 'Content-Length: {}'.format(actual_length), request_body)
request_body = re.sub(r'Content-MD5: .*', '', request_body) # update the Content-MD5 header
request_body = re.sub(r'Content-Encoding: .*', '', request_body) # update the Content-Encoding header
return request_body
最后
最后根据实际使用情况,可以加些文件夹读取和命令行参数,方便快速批量构造http的pcap
一份完整的代码github链接:
GitHub - Trepverterless/Re2HTTPpcap: 利用scapy构造通过txt请求文本构造http pcap















 7204
7204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









