







声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
前言
为什么选取豆瓣电影Top 250来进行爬取呢?原因是它的网页结构相当规整,比较适合爬虫新手练习。下面我将详细展示爬虫的整个过程。
爬虫过程
网页链接分析
爬虫起点网页为豆瓣电影 Top 250,整个250部电影一共分10页,每页对应的链接如下:
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
https://movie.douban.com/top250?start=75&filter=
...
https://movie.douban.com/top250?start=225&filter=
上述链接的结构都一致,唯一的区别是在查询字符串start = number的位置,因此,要想爬取网站的10页,可以用一个变量page来进行迭代。
请求网页
请求网页我使用的是requests库,最开始我试探性的直接使用get函数请求网页内容,请求代码如下:
import requests
url = 'https://movie.douban.com/top250?start=0&filter='
reponse = requests.get(url)
print(reponse.status_code)
#418
结果服务器响应的代码是418,说明请求未成功,于是我又将User-Agent传递给了get函数的headers参数,结果返回200,说明请求成功,实验代码为:
import requests
url = 'https://movie.douban.com/top250?start=0&filter='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
reponse = requests.get(url,headers = headers)
print(reponse.status_code)
#200
若读者想要复现代码,需要获取浏览器的User-Agent参数,对于Chrome浏览器,可以直接在浏览器中输入about:version,会出现如下界面:
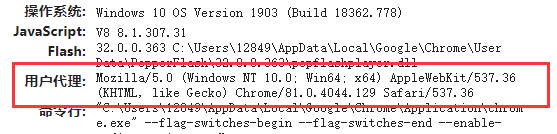
从其中就可以获取到User-Agent参数。在这些都搞定了以后,爬虫程序的请求部分就已经基本上完成了,下面是完整的请求代码:
def HTMLDownloader(page):
url = 'https://movie.douban.com/top250?start='+ str(page*25) +'&filter='
#print(url)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
try:
reponse = requests.get(url,headers = headers)
if reponse.status_code == 200:#响应成功
return reponse.text
except requests.RequestException as e:
return None
解析网页
对于网页的解析使用的是BeautifulSoup,我准备爬取的各部电影的数据有:
- 电影名
- 豆瓣评分
- 电影简介
- 电影评论
以Top 250的第一页为例,该网页部分内容如下:

右键查看其网页源码,如下图:

从网页源码中我们可以发现网页中的每部电影的信息都在一个具有属性为class = "item"的div标签中,利用这个,我们可以使用find_all()函数来获取网页中包含所有电影的div标签。
对于每部电影我们要爬取的属性可以通过如下方式获取:
- 从包含属性
class = "title"的span标签中可以获取电影名; - 从包含属性
class = "rating_num"的span标签中可以获取电影的豆瓣评分; - 从包含属性
class = ''的p标签,我们可以获取电影的简介,其中包括了导演,主演,电影年份等信息。 - 从包含属性
class = 'inq'的span标签,我们可以获取电影的评论。
通过上述分析内容,网页分析函数的雏形就基本上出来了,完整的分析程序为:
def HTMLParser(reponse):
"""
网页解析出的电影数据都保存在列表中
列表的每个元素都包含一部电影的信息
"""
outcome = []
if reponse == None:
pass
else:
soup = BeautifulSoup(reponse,'lxml') #BeautifulSoup构造方法
#寻找所有电影的div标签
items = soup.findAll('div',attrs={'class':'item'})
#从div标签中获取电影的各种信息
for item in items:
title = item.find('span',attrs = {'class':'title'}).string
rank = item.find('span',attrs = {'class':'rating_num'}).string
movinfo = item.find('p',attrs = {'class':''}).text
#有的电影没有评论
if item.find('span',attrs = {'class':'inq'}):
comment = item.find('span',attrs = {'class':'inq'}).string
else:
comment = ''
print('crawing',title,rank,movinfo,comment)
outcome.append([title,rank,movinfo.strip(),comment.strip()])
return outcome
保存提取的信息
爬取完整250部电影的信息后,我将其保存在excel中,下面是保存程序:
def MovieInfoSaver(mov):
workbook = openpyxl.Workbook() #openpyxl模块需要自己安装
sheet = workbook.active
sheet.title = 'douban_movie'
sheet.cell(1,1,'电影名')
sheet.cell(1,2,'豆瓣评分')
sheet.cell(1,3,'简介')
sheet.cell(1,4,'评论')
for idx,m in enumerate(mov):
sheet.cell(idx + 2,1,m[0])
sheet.cell(idx + 2,2,m[1])
sheet.cell(idx + 2,3,m[2])
sheet.cell(idx + 2,4,m[3])
workbook.save(u'douban_hrank_movie.xlsx') # 保存工作簿
完整爬虫程序
最后给出完整的爬虫程序
from bs4 import BeautifulSoup
import requests
import openpyxl
def HTMLDownloader(page):
url = 'https://movie.douban.com/top250?start='+ str(page*25) +'&filter='
#print(url)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
try:
reponse = requests.get(url,headers = headers)
if reponse.status_code == 200:#响应成功
return reponse.text
except requests.RequestException as e:
return None
def HTMLParser(reponse):
"""
网页解析出的电影数据都保存在列表中
列表的每个元素都包含一部电影的信息
"""
outcome = []
if reponse == None:
pass
else:
soup = BeautifulSoup(reponse,'lxml') #BeautifulSoup构造方法
#寻找所有电影的div标签
items = soup.findAll('div',attrs={'class':'item'})
#从div标签中获取电影的各种信息
for item in items:
title = item.find('span',attrs = {'class':'title'}).string
rank = item.find('span',attrs = {'class':'rating_num'}).string
movinfo = item.find('p',attrs = {'class':''}).text
#有的电影没有评论
if item.find('span',attrs = {'class':'inq'}):
comment = item.find('span',attrs = {'class':'inq'}).string
else:
comment = ''
print('clawing',title,rank,movinfo,comment)
outcome.append([title,rank,movinfo.strip(),comment.strip()])
return outcome
def MovieInfoSaver(mov):
"""
保存爬虫结果到excel中
"""
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'douban_movie'
sheet.cell(1,1,'电影名')
sheet.cell(1,2,'豆瓣评分')
sheet.cell(1,3,'简介')
sheet.cell(1,4,'评论')
for idx,m in enumerate(mov):
sheet.cell(idx + 2,1,m[0])
sheet.cell(idx + 2,2,m[1])
sheet.cell(idx + 2,3,m[2])
sheet.cell(idx + 2,4,m[3])
workbook.save(u'douban_hrank_movie.xlsx') # 保存工作簿
if __name__ == "__main__":
movinfo = []
#通过page变量请求10个页面
for page in range(10):
reponse = HTMLDownloader(page)
movinfo += HTMLParser(reponse)
MovieInfoSaver(movinfo)
爬虫结果展示
















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











