







目录
摘要
1、介绍
2、威胁模型
3、要求
摘要
由于语音助手输入通道的开放性,对手可以轻松记录人们使用的语音命令,然后将其重放以欺骗语音助手。为了减轻这种欺骗攻击,我们提供了一种称为“Void”的高效语音活动检测解决方案。Void利用真人语音与通过扬声器重播的语音之间频谱功率的差异来检测语音欺骗攻击。 与使用多个深度学习模型和数千个功能的现有方法相比,Void使用仅具有97个功能的单个分类模型。
我们使用了两个数据集来评估其性能:(1)255 173个语音样本由120个参与者生成,其中15个播放设备和12个记录设备,以及(2)由42个参与者,26个播放设备和25个记录设备生成的18,030个公共语音样本。 在检测每个数据集的语音重放攻击时,Void分别达到0.3%和11.6%的相等错误率。与最新的基于深度学习的解决方案相比,该解决方案在该公共数据集中的错误率达到7.4%,与之相比,Void使用的内存减少了153倍,检测速度提高了约8倍。当与高斯混合模型结合使用梅尔频率倒谱系数(MFCC)作为分类特征时(MFCC已经被提取并用作语音识别服务的主要特征),Void在公共数据集上的错误率达到8.7%。此外,Void可以抵抗隐藏的语音命令,听不见的语音命令,语音合成,均衡操纵攻击,并将重播攻击与真人语音相结合,可实现约99.7%,100%,90.2%,86.3%和98.2%的检测率 这些攻击分别。
1、介绍
流行的语音助手如Siri (Apple)、Alexa (Amazon) 和 Now (Google) 等允许人们使用语音命令快速在线购物、拨打电话、发送消息、控制智能家电、访问银行服务等。然而,这种对隐私和安全至关重要的命令使语音助手成为攻击者可以利用的有利可图的目标。最近的研究 [11, 12, 23] 表明语音助手容易受到各种形式的语音呈现攻击,包括“语音重放攻击”(攻击者只是记录受害者对语音助手的使用并重放它们)和“语音合成攻击”(攻击者训练受害者的语音生物识别模型并创建新命令)。
为了区分真人语音和重放语音,几种语音活体检测技术已经被提出。冯等人 [11] 建议使用可穿戴设备,例如眼镜或耳塞来检测语音活跃度。他们实现了大约 97% 的检测率,但依赖于用户必须购买、携带和使用的额外硬件。基于深度学习的方法也被提出 [7, 30] ,最著名的解决方法来自一个名为“2017 ASVspoof Challenge”[7] 的在线重播攻击检测竞赛中,又非常高的准确率,实现了约 6.7% 的等错误率 (EER)——但它的计算成本高昂且复杂:两个深度学习模型(LCNN 和含有 RNN 的 CNN)和一个基于 SVM 的分类模型一起使用以实现高精度。第二个最佳解决方案使用 5 个不同分类模型和多个分类特征的集合实现了 12.3% 的 EER:均使用了恒定 Q 倒谱系数 (CQCC)、感知线性预测 (PLP) 和梅尔频率倒谱系数 (MFCC) 特征。仅 CQCC 就很大,包含大约 14,000 个特征。
为了减少计算负担并保持较高的检测精度,我们提出了“Void”(语音活体检测),这是一种高效的语音活性检测系统,它依赖于频谱图中累积功率模式的分析来检测重放的语音。 Void 使用只有 97 个频谱图特征的单一分类模型。特别是,Void 在功率模式中利用了以下两个显着特征:(1) 大多数扬声器在重放原始声音时会固有地添加失真,因此,在可听频率范围内的整体功率分布通常表现出一定的均匀性和线性。(2) 对于人声,在较低频率上观察到的功率总和相对高于在较高频率上观察到的总和[15,29]。因此,现场人声和通过扬声器重放的声音之间的累积功率分布存在显着差异。 Void 系统将这些差异提取为分类特征,以准确检测重放攻击。
我们的主要成果总结如下:
设计了一种快速、轻便的语音重放攻击检测系统,该系统采用单一的分类模型,且仅需97个与信号频率和累积功率分布特性相关的分类特征。与现有的依赖于多个深度学习模型的方法不同,它们无法深入解释正在提取的复杂频谱特征[7,30],而我们解释了关键频谱功率特征的特点,以及为什么这些特征在检测语音欺骗攻击时是有效的。
使用两个大数据集评估语音重放攻击检测的准确性,两个大数据集包括从120 名参与者、15 个重放设备和 12 个录音设备收集的 255173 个语音样本,以及分别从 42 名参与者、26 个重放扬声器和 25 个录音设备收集的18030 个 ASVspoof 竞赛语音样本,分别为 0.3% 和11.6% 的等错误率 (EER)。基于后一个 EER,Void 将被列为 2017 年 ASVspoof 竞赛的第二个最佳解决方案。与那次竞争中表现最好的解决方案相比,Void 的速度快了 8 倍,在检测中使用的内存少了 153 倍。当与基于 MFCC 的模型相结合时,Void 在 ASVspoof 数据集上实现了8.7% 的 EER, MFCC 已经通过语音识别服务提供,并且不需要额外的计算。
Void 对隐藏命令、听不到语音命令、语音合成、均衡(EQ)操作攻击和将重播攻击与真人语音结合攻击的性能评价,分别显示 99.7%、100%、90.2%、86.3% 和 98.2%的检测率。
2 威胁模型
2.1 语音重放攻击
我们将现场人类音频样本定义为由人类用户发起的直接通过麦克风录制的语音(通常由语音助手处理)。 在语音重放攻击中,攻击者在受害者附近使用录音设备(例如,智能手机),并首先记录受害者对用于与语音助手交互的语音命令的话语(口语)[3, 11, 12]。 然后攻击者使用内置扬声器(例如,在她的手机上可用)或独立扬声器重放录制的样本以完成攻击(见图 1)。
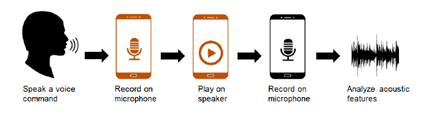
语音重放攻击可能是最容易操作的攻击,但它是最难检测的,因为与受害者的现场语音相比,录制的语音具有相似的特征。 事实上,大多数现有的基于语音生物识别的身份验证(说话人验证)系统(例如 [31, 32])都容易受到这种重放攻击。
2.2 对抗性攻击
我们还考虑了更复杂的攻击,例如最近文献中讨论过的“隐藏语音命令”[24, 25]、“听不见的语音命令”[18-20]和“语音合成”[6, 12]攻击。 此外,EQ 操纵攻击专门设计用于通过调整攻击语音信号的特定频带来挑战 Void 使用的分类特征。
3 要求
3.1 延迟和模型大小要求
我们与一家大型 IT 公司(运行自己的语音助手服务,拥有数百万订阅用户)的几位语音识别工程师的对话表明,在部署任何类型的基于机器学习的服务时,必须考虑严格的延迟和计算能力使用要求。这是因为通过持续调用机器学习算法额外使用计算能力和内存可能会导致 (1) 企业无法接受的成本,以及 (2) 处理语音命令的不可接受的延迟(延迟)。收到语音命令后,语音助手需要立即响应,不得有任何明显延迟。因此,处理延迟应接近 0 秒——通常,工程师不会将增加 100 毫秒或更多毫秒延迟的解决方案视为便携式解决方案。预计单个 GPU 可以同时处理 100 个或更多语音会话(流命令),这表明机器学习算法必须轻量级、简单且快速。
此外,作为未来解决方案的一部分,企业正在考虑在设备上实现语音助手(不会与远程服务器通信)以改善响应延迟,节省服务器成本,并最大限度地减少与与远程服务器共享用户私人语音数据相关的隐私问题。对于此类可用计算资源有限的设备上解决方案,模型和功能的复杂性以及大小(CPU 和内存使用)要求将更加受限。
3.2 检测精度要求
我们的主要目标是实现具有竞争力的高精度,同时将延迟和资源使用要求保持在可接受的水平(见上文)。同样,我们与语音识别工程师的对话表明,企业需要大约 10% 或以下的 EER 才能被视为可用的解决方案。作为参考,来自 ASVspoof 2017 竞赛的最佳解决方案实现了 6.7% 的 EER [30],第二个最佳解决方案实现了 12.3% [7]。
4、主要分类特征值
Void利用了人类声音与通过扬声器重播的声音之间的频率相关频谱功率特性差异。 通过大量的试验和实验,我们观察到了与语音信号功率谱有关的三个不同特征,这些特征可以区分人类声音和通过扬声器重播的声音。 本节将详细探讨这些功能。
图1显示了重放录制的语音信号所涉及的步骤。 攻击者首先会使用自己的录音设备录制受害者的语音命令。 然后,攻击者将使用同一设备(内置扬声器)重放针对受害者设备的录制的语音命令。 然后,由受害者设备上运行的语音助手服务处理此攻击命令。 在执行此重播攻击时,由于硬件缺陷,在用攻击者的设备上的麦克风录制时,以及在通过内置扬声器重播时,可能会向受害者的原始声音添加一些失真。 以下各节探讨了重播语音的频谱功率特性,并分析了用于对语音重播攻击进行分类的关键分类功能。
4.1、频谱功率衰减特征
通常,低质量的扬声器旨在实现高灵敏度和高音量,但要以牺牲音频保真度和增加不必要的失真为代价[35]。 结果,导致非线性的失真在低质量的扬声器中可能更为普遍,而在高质量的扬声器中则不那么明显[36、37]。
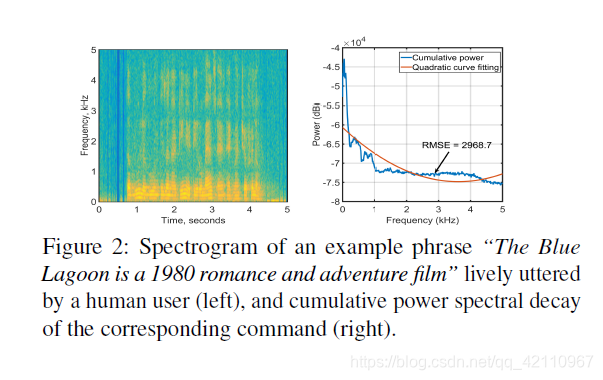
图2(左)显示了“蓝色泻湖是1980年的浪漫和冒险电影”这句话的声谱图,并通过笔记本电脑中的音频芯片组进行处理。 在此,音频采样率为44.1kHz,发声时间为5秒。 在此语音样本中,大多数频谱功率位于20Hz至1kHz之间的频率范围内。 图2(右)还显示了针对每个频率测得的累积频谱功率。 在1kHz左右的频率下,人声会呈指数衰减。
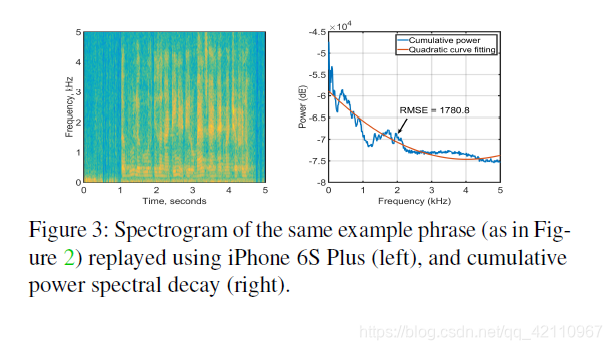
另一方面,通过iPhone 6s Plus内置扬声器重播的短语的频谱图(请参见图3)显示出一定的一致性-频谱扩展以1至5kHz之间的功率分布显示。 与图2所示的人类语音趋势不同,累积频谱功率不会呈指数下降。 而是在1至5kHz之间存在相对较大的线性衰减。 为了定量显示图2和图3之间的差异,我们在它们上添加了二次拟合曲线,并分别计算了均方根误差(RMSE)。
我们对11种内置智能手机扬声器进行的实验表明,它们的频谱功率分布具有相似的行为。 即,功率在整个频率上逐渐降低,并且没有呈指数衰减。 频谱功率密度的累积分布示例如图4所示。在人类语音示例中,总功率的大约70%位于1kHz以下的频率范围内。 但是,在扬声器的情况下,累积分布几乎呈线性增加,并且总功率的70%位于约4kHz的频率范围内。
这种扩展特性的一种可能解释是在某些频率范围内的低质量硬件提升功率。 因此,可以训练频谱功率(在可听频率范围内)的这种线性衰减模式,并将其用于对通过低质量扬声器播放的声音进行分类。 附录A演示了将使用三种信号功率功能对真人语音和通过11个内置智能手机扬声器重放的语音进行分类。
4.2、频谱功率的峰值特征
因为高质量的独立扬声器可以在很宽的频率范围内提高功率,以减少非线性失真,所以上述线性衰减模式可能不足以应对此类扬声器。
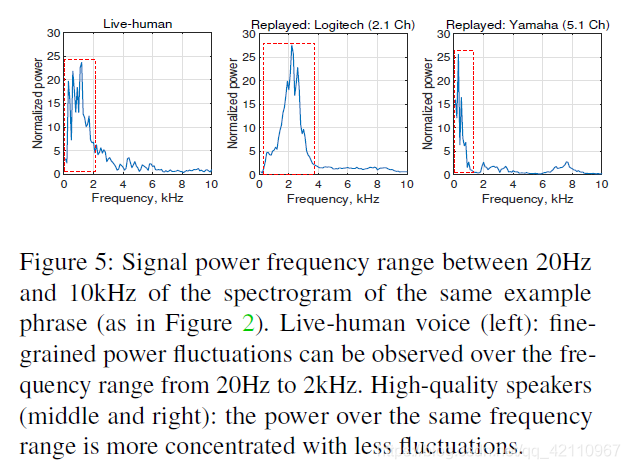
图5比较了人类真实声音和通过两个不同的高质量扬声器重放的声音的标准化信号功率。 尽管它们总体上显示出相似的指数衰减模式,但低频模式却有所不同(请参见图5中的红色虚线矩形)。 至于扬声器(中,右),与真人声音相比(左),低频处的尖峰和长峰数量较少。
因此,低频中由失真引起的功率模式(例如,可见功率峰值的数量,其相应频率以及功率峰值大小的标准偏差)可以有效地检测产生更高质量声音的独立扬声器。 我们还使用高阶多项式来准确地建模频谱功率形状,并使用这些模型来识别活人样本和重播样本之间频谱功率模式的更细粒度差异(请参见图5)。 我们还在附录B中提供了不同扬声器的功率模式。
4.3、线性预测倒谱系数(LPCC)
因为第4.1节和第4.2节中讨论的衰减和峰值模式主要着眼于特定的频率范围。 为了对更宽的频率范围进行更一般的检查,我们另外使用线性预测倒谱系数(LPCC)[4]作为补充功能。
LPCC通常用于语音相关应用程序中的听觉建模。 LPCC背后的关键思想是语音样本可以近似为先前样本的线性组合。 通过最小化语音样本和线性预测样本之间的平方差之和,可以计算出语音样本的LPCC。 LPCC的计算复杂度低于MFCC,因为LPCC不需要离散傅里叶变换的计算[5]。 我们选择LPCC作为补充的轻量级功能,以帮助Void利用覆盖语音信号更宽频率范围的频谱功能。
5、系统设计
基于第4节中描述的关键分类特征,我们设计Void以满足第3节中指定的要求。为了检测重放攻击,Void分析音频范围内的信号功率分布——计算给定信号功率的线性度,并识别低功率和高功率频率中的峰值模式。
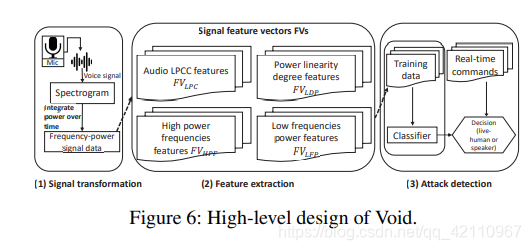
5.1、void 概述
通过Void的攻击检测包括三个阶段,如图6所示:信号转换、特征提取和实时攻击检测。整个Void算法在算法1中描述。语音命令
V
o
i
c
e
i
n
Voice_{in}
Voicein、窗口大小W和加权因子ω作为算法1的输入。
S
p
o
w
S_{pow}
Spow表示
V
o
i
c
e
i
n
Voice_{in}
Voicein的每个频率的累积频谱功率。W表示
S
p
o
w
S_{pow}
Spow单个片段的大小,用少量的段完全捕捉
S
p
o
w
S_{pow}
Spow的动态特性。使用0和1之间的加权因子ω来计算更高频率中的特征值的阈值。这些参数值是用大量训练样本通过实验确定的。最后,
p
o
w
(
i
)
pow(i)
pow(i)表示
S
p
o
w
S_{pow}
Spow的第i段中的累积功率。我们只考虑15kHz以下的语音信号,因为大多数语音样本的信号功率都低于15kHz。
 ##### 5.2、信号变换
##### 5.2、信号变换
信号变换第一步,对输入语音信号进行短时傅里叶变换(算法1的第一步)。为了计算短时傅里叶,将所给语音信号分成等长(表示为wlen = 1024)的短快,然后对每个短块进行傅里叶变换。我们使用了窗长(wlen)为1024,跳跃长度为256(这是由wlen/4计算的)的周期汉明窗。用于计算STFT的快速傅里叶变换点数(nfft)被设置为4096。获得的信号谱图包含频率和随时间变化的相应功率(见图2(左))。根据计算的STFT,计算每频率累积频谱功率(
S
p
o
w
S_{pow}
Spow)(算法1的步骤2)。术语“累积光谱功率”和“功率”在下文中互换使用。
S
p
o
w
S_{pow}
Spow是一个向量,它包含
V
o
i
c
e
i
n
Voice_{in}
Voicein整个持续时间内每个频率的总累积功率(见图2(右))。从STFT获得的
S
p
o
w
S_{pow}
Spow是大小为1500的向量(算法1的步骤2)。我们使用符号大小(
S
p
o
w
S_{pow}
Spow)来表示存储在
S
p
o
w
S_{pow}
Spow中的值的数量。
5.3、特征提取
从第一阶段计算出的向量
S
p
o
w
S_{pow}
Spow用作第二阶段的输入,以提取分类特征。Void 顺序计算以下四种类型的特征:
(1)低频能量功能(FVLFP),
(2)信号功率线性度特征(FVLDF),
(3)高功率频率功能(FVHPF),
(4)音频信号的LPCC功能(FVLPC)。
FV代表特征向量。
前三个要素类是从
S
p
o
w
S_{pow}
Spow计算出来的,而FVLPC是直接从原始语音信号
V
o
i
c
e
i
n
Voice_{in}
Voicein计算出来的。
5.3.1、低频能量特征
在算法1的第二阶段中,我们首先根据给定的窗口大小W将信号Spow分为相等长度的k个短段(请参见步骤3)。我们经验地设置W=10。如果Spow的大小不能整除W,我们将省略最后一段。
接下来,我们计算每段
S
e
g
i
Seg_i
Segi的功率之和,对于i=1到k(参见步骤4和5)。
然后将功率密度值的前k段矢量化为(=pow(1),…,pow(k))(参见步骤6)。
向量直接在FVLFP中使用(请参见步骤7)。
执行完此步骤后,我们将具有累积频谱功率所有k段的密度值。每个段的功率密度值按频率排序,从给定语音样本的最低频率开始。我们只对将功率密度值保持在5kHz的频率范围内感兴趣,因为我们的实验表明,在5kHz以下的较低频率下,人声和重放的声音之间存在明显的差异(请参见图5)。因此,我们仅保留向量的前48个值,并将它们分配给FVLFP(请参见步骤7)。
5.3.2、信号能量线性度特性
给定k个分段的向量,我们将计算信号的特征向量(FVLDF)以测量线性度(如第4.1节所述)。

算法2描述了计算的线性度的过程。
最初,通过将中的每个值除以总信号功率(sum())来对进行归一化(请参阅算法2中的步骤1)。 然后,将归一化的功率信号矢量
<
p
o
w
>
n
o
r
m
a
l
<pow> _{normal}
<pow>normal用于计算频谱功率的累积分布,用
p
o
w
c
d
f
pow_{cdf}
powcdf表示(请参见步骤2)。 在此步骤中,
<
p
o
w
>
n
o
r
m
a
l
<pow> _{normal}
<pow>normal以逐步方式累积。
对于
p
o
w
c
d
f
pow_{cdf}
powcdf的线性度,我们计算出以下两个特征(请参见步骤3和4):
p
o
w
c
d
f
pow_{cdf}
powcdf的相关系数ρ和二次曲线拟合系数q(请参见附录C)。
5.3.3、高能量频率特征
给定向量
<
p
o
w
>
<pow>
<pow>和峰选择阈值
w
w
w,我们计算特征向量(FVHPF)来捕获频谱功率的动态特性(请参阅附录D)。

算法3描述了计算高能量频率特征(FVHPF)的过程。在
<
p
o
w
>
<pow>
<pow>中,我们首先确定峰及其位置(请参阅步骤1)。
5.3.4、LPCC 特征
我们使用自相关方法和Levinson-Durbin算法[26]来计算给定语音信号的LPCC,生成12个系数,这12个LPCC系数存储在特征向量FVLPC中。
















 2640
2640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











