







本次爬虫目标网址为网易云歌单页面
代码实现以下功能
1.按输入的歌单类型获取该类型歌单封面,并输出歌单名
2.可通过在headers中加上账户cookie获取系统为该账户推荐的歌单封面(每个账户系统推荐的歌单均不同)
设计思路简略为输入歌单类型后,循环获取该类型歌单每一页的地址,再根据该地址循环获取该页下每个歌单的图片地址,并将图片分辨率恢复正常大小后下载保存到本地
代码难点如下
1.页面嵌套,需要先获取输入类型的歌单网址,再逐个获取该页面每一页中的每一张封面图片,代码中使用两个大for循环获取每个歌单网址,使用两个小for循环分别获取最终歌单封面地址和歌单标题
2.需要将输入的歌单类型保存至变量后拼接至目标访问网址,输入的如果是中文字符还要进行编码后才能进行拼接,在代码中需要使用urllib.parse.quote函数进行编码
3.获取完一页的歌单封面后需要进行翻页获取下一页的歌单封面,那就必须了解歌单页码变化规律,我们观察前三页URL变化
![]()
![]()
![]()
可以看到只有offset每次加35,非常简单,代码中使用一个自增变量每次加35然后拼接至URL即可
4.要获取的是某个网易云音乐帐号下系统推荐的歌单封面,而不是未登录状态下一样口味的歌单,其实非常简单,只需要在headers中加入cookie即可,获取cookie信息需要先登录帐号,然后F12,点击network(网络),name选择第一个,如下图,
蓝色的就是cookie了,复制到代码的headers中即可

还有一些坑也提一下
1.比如网易云歌单网址如下图
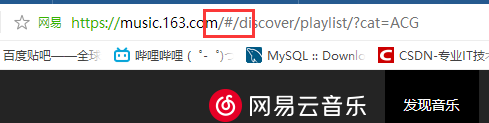
可以看到网址中有 /# 字符,亲测如果不删掉该字符是爬取不到网易云的数据的,.com后面直接接上/discover就可以了
2.最终我们获取到的歌单封面网址是这样的
http://p2.music.126.net/A514bNqtuivvuppEiXkibQ==/1407374889022377.jpg?param=140y140
访问该网址后可以看到图片分辨率非常低,只有140*140,看到网址后面的 ?param=140y140 没有,只要去除它就可以得到原始分辨率的图片了
3.最终获取的标题中会有很多空格,使用 replace(' ','') 函数即可将第一个单引号中的字符替换为第二个单引号中的字符
下面贴出更新后代码
#-*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import urllib
def getimg(str_1):
str_2 = urllib.parse.quote(str_1) # URL只允许一部分ASCII字符,其他字符(如汉字)是不符合标准的,此时就要使用进行urllib.parse.quote函数进行编码
print('字符<%s>转换后为<%s>'%(str_1,str_2),'\n','开始下载...')
url='https://music.163.com/discover/playlist/?cat='+str(str_1)+'&limit=35&offset=' # URL拼接上输入且转换后的字符
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2864.400',
'Cookie':'_ntes_nnid=3e47e957c94d56ea3714f5bbf38597bf,1532695901743; _ntes_nuid=3e47e957c94d56ea3714f5bbf38597bf; usertrack=ezq0o1u8xfxwfillERRvAg==; _ga=GA1.2.1172819859.1539098110; __oc_uuid=ed599b70-d8d0-11e8-9a49-4d470420dcfb; __utma=187553192.1172819859.1539098110.1540525248.1540525248.1; __utmz=187553192.1540525248.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _iuqxldmzr_=32; WM_TID=h3Hc9Pi6g75NPzMgDUVPDJ1qsRwbLDGK; __utma=94650624.356059233.1532951546.1536057789.1540790360.6; __utmz=94650624.1535085812.4.4.utmcsr=liuli.eu|utmccn=(referral)|utmcmd=referral|utmcct=/wp/tag/cosplay/page/2; vinfo_n_f_l_n3=954c8f473076175e.1.0.1545043421942.0.1545043443642; KAOLA_ACC=476ab7cd25c6f5d0f8007a58c2deaedc@tencent.163.com; mail_psc_fingerprint=9b38f4d5ca4a4df17bd64ac8b1e7826d; nts_mail_user=15770570072@163.com:-1:1; WM_NI=LL%2BmyxKQSMrwVt%2BCZj5KpBZM7R3cAW6hH%2F1jc9FP0bbUUukFkDKTtXlcDrV5rcINIyT%2BQJw3fDklKb0nm0E6QnS8QIM%2FuxRlstMbP3Wc3IoRI7Tii2EG5NMwWS9GAryLOGU%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee98f46a88e9f9a3b54eb1bc8fa6c54f869a8eaab73cb8b2bfbbbb5393bfab91f12af0fea7c3b92a9094e58efc74898f9daef17d96ace5a4d962f795c0a3d947f58efd84c45df6b888d0b462a1e78ab1b36aa28b9b96ea4ea99c85b5f754b0bd8c93d53fb2bd87afcc7398f59fabf639a69ca58dca6af4b2a3d1c83e93b29dd9d4438ff1bb99d168b1ac8383d33995bdfdaaee5a8be99c8aec3a8799fbafd07d958df7a8c47abb9481a8d837e2a3; playerid=81146496; starttime=; NNSSPID=a776c92a33154c50b675beb7fe13044f; NTES_PASSPORT=1tAjSLmRjoF2OepbYQlVX5N_4tze4tCwri6.maC4yHO8zSAkzfcxNLMHisp95DIK.vrSb_TmzrrrCwncIb20PwdWiBY8TdcSPsHjXfAv87YfmEk.7MbJ9n2iKufg7nmnpqEELiCgX73mQBOdWx_sI4DCj4d.HkysDoF_8jPId.jr1xKvbzh.ijkHx; df=mail163_letter; playliststatus=visible; NTES_SESS=pLtesJlQwWLM2_F68fUmnLEF8d5Iv4cq_qQfCP7YFVvh_q13_H8IY.vDOfMQ2gatRiX5XcUpvCDC5p9npr7FCwYI2LBmEgb9FrtbQbQA4p1eGwFrOl.xFcmhlqQhSx5lH4dzhJtM6So72SWrCTXvPWH__g6Hn3Cj6hRVd.rFD4ScPWA.3fBB8g2..VT3Rf1.jGcy8bxHaIui8Vyp9MJZX.vk0; S_INFO=1553494481|0|1&65##|m15770570072; P_INFO=m15770570072@163.com|1553494481|0|mail163|00&99|CN&1553476190&mail163#CN&null#10#0#0|157072&1|kaola&mail163|15770570072@163.com; MUSIC_EMAIL_U=112871895ffcc9c558231ef8b14c72465053be85f4706fa68125a8c6b9f1c7089e11ed1b8eda0a668b868433afc35e6d2383765fb87ce1fef2f513a9c38b5dc7; JSESSIONID-WYYY=9G0H2Gt%5C%2BkEsnP%2BUTkJdbPA6O%5C%2F2w%2BlFnFTDDdBbzpJG13a%5CeCGdp%2F7U%2FoHCA8cE6jxegjO%5Ccc%2FZyXbS%2Bw%2Fe2FEtEwfIARUM1x7QGDnWEsSQYfZ%5CHPZAO1msgcS3TvPwqjnN1q2bsteorR3DEPNr6drhmAyqgc53bCq5i8pGz6HoPk2H%3A1553497555044; MUSIC_U=e4ace7b13afdd88161175bda1c0914451762803785e1030d4312dda6e71aff68ca2d83fe0a175eb59e0eb32aa5fb495e8bafcdfe5ad2b092; __remember_me=true; __csrf=60e2fad5dc1d688abf984595f6a277e1',}
page_num=0 # 歌单翻页变量
img_num=0 # 图片命名变量
path = 'G:/爬虫/网易云1/' # 定义存储路径
for flag in range(0,38): # 歌单最大页码为38页,故循环最多38次
link = url + str(page_num) # URL拼接上自增变量即可实现歌单翻页
page_num+=35 # 每进入下一页URL中 offset 加35
page = requests.get(link , headers = headers) # 使用requests库直接获取页面信息
soup = BeautifulSoup(page.text,'lxml') # 使用BeautifulSoup库提取page中的数据
div = soup.find('div',class_='g-bd') # 获取页面中所有div标签中class为 g-bd 的数据
div_1 = div.find_all('div',class_='u-cover u-cover-1') # 原理同上,获取歌单图片和歌单标题数据
for a in div_1:
img_num+=1
img = a.find_all('img') # 获取歌单封面所在标签
title = a.find_all('a',class_='msk') # 获取歌单标题所在标签
for b in img: # 获取最终图片链接
img_src = b.get('src') # 获取歌单图片链接
img_src = img_src[:-14] # 图片链接后14个字符是限制图片分辨率用的,去除后14个字符即可获得原始分辨率图片
for c in title: # 获取最终标题
final_title = c.get('title').replace(' ','') # 获取歌单标题,标题中有大量空格,使用replace函数去除
urllib.request.urlretrieve(img_src, path + str(img_num) + '.jpg') #开始保存至本地!
print('(第%d张)专辑:<<%s>>图片下载成功'%(img_num,final_title))
print('下载完毕!总计下载%d张图片'%(img_num))
print(' 语种','\n',
' 华语 | 欧美 | 日语 | 韩语 | 粤语 | 小语种 |','\n',
'风格','\n',
' 流行 | 摇滚 | 民谣 | 电子 | 舞曲 | 说唱| 轻音乐 | 爵士 | 乡村 | R&B/Soul | 古典 | 民族 | 英伦 | 金属 | 朋克 | 蓝调 ','\n',
' 雷鬼 | 世界音乐 | 拉丁 | 另类/独立| New Age| 古风| 后摇| Bossa Nova|','\n',
'场景','\n',
' 清晨 | 夜晚 | 学习 | 工作 | 午休 | 下午茶 | 地铁 | 驾车 | 运动 | 旅行 | 散步 | 酒吧 |','\n',
'情感','\n',
' 怀旧 | 清新 | 浪漫 | 性感 | 伤感 | 治愈 | 放松 | 孤独 | 感动 | 兴奋 | 快乐 | 安静 | 思念 |','\n',
'主题','\n',
' 影视原声 | ACG | 儿童 | 校园 | 游戏 | 70后 | 80后 | 90后 | 网络歌曲 | KTV | 经典 | 翻唱 | 吉他 | 钢琴 | 器乐 | 榜单 | 00后 |')
if __name__ == '__main__':
Fun=input('请输入想要下载歌单图片的类型:')
getimg(Fun)更新前代码
#-*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import urllib
def getimg(type2):
type3 = urllib.parse.quote(type2)
print('字符<%s>转换后为<%s>'%(type2,type3),'\n','开始下载...')
url='https://music.163.com/discover/playlist/?cat='+str(type3)+'&limit=35&offset='
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2864.400',
'Cookie':'_ntes_nnid=3e47e957c94d56ea3714f5bbf38597bf,1532695901743; _ntes_nuid=3e47e957c94d56ea3714f5bbf38597bf; usertrack=ezq0o1u8xfxwfillERRvAg==; _ga=GA1.2.1172819859.1539098110; __oc_uuid=ed599b70-d8d0-11e8-9a49-4d470420dcfb; __utma=187553192.1172819859.1539098110.1540525248.1540525248.1; __utmz=187553192.1540525248.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _iuqxldmzr_=32; WM_TID=h3Hc9Pi6g75NPzMgDUVPDJ1qsRwbLDGK; __utma=94650624.356059233.1532951546.1536057789.1540790360.6; __utmz=94650624.1535085812.4.4.utmcsr=liuli.eu|utmccn=(referral)|utmcmd=referral|utmcct=/wp/tag/cosplay/page/2; vinfo_n_f_l_n3=954c8f473076175e.1.0.1545043421942.0.1545043443642; KAOLA_ACC=476ab7cd25c6f5d0f8007a58c2deaedc@tencent.163.com; mail_psc_fingerprint=9b38f4d5ca4a4df17bd64ac8b1e7826d; nts_mail_user=15770570072@163.com:-1:1; WM_NI=LL%2BmyxKQSMrwVt%2BCZj5KpBZM7R3cAW6hH%2F1jc9FP0bbUUukFkDKTtXlcDrV5rcINIyT%2BQJw3fDklKb0nm0E6QnS8QIM%2FuxRlstMbP3Wc3IoRI7Tii2EG5NMwWS9GAryLOGU%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee98f46a88e9f9a3b54eb1bc8fa6c54f869a8eaab73cb8b2bfbbbb5393bfab91f12af0fea7c3b92a9094e58efc74898f9daef17d96ace5a4d962f795c0a3d947f58efd84c45df6b888d0b462a1e78ab1b36aa28b9b96ea4ea99c85b5f754b0bd8c93d53fb2bd87afcc7398f59fabf639a69ca58dca6af4b2a3d1c83e93b29dd9d4438ff1bb99d168b1ac8383d33995bdfdaaee5a8be99c8aec3a8799fbafd07d958df7a8c47abb9481a8d837e2a3; playerid=81146496; starttime=; NNSSPID=a776c92a33154c50b675beb7fe13044f; NTES_PASSPORT=1tAjSLmRjoF2OepbYQlVX5N_4tze4tCwri6.maC4yHO8zSAkzfcxNLMHisp95DIK.vrSb_TmzrrrCwncIb20PwdWiBY8TdcSPsHjXfAv87YfmEk.7MbJ9n2iKufg7nmnpqEELiCgX73mQBOdWx_sI4DCj4d.HkysDoF_8jPId.jr1xKvbzh.ijkHx; df=mail163_letter; playliststatus=visible; NTES_SESS=pLtesJlQwWLM2_F68fUmnLEF8d5Iv4cq_qQfCP7YFVvh_q13_H8IY.vDOfMQ2gatRiX5XcUpvCDC5p9npr7FCwYI2LBmEgb9FrtbQbQA4p1eGwFrOl.xFcmhlqQhSx5lH4dzhJtM6So72SWrCTXvPWH__g6Hn3Cj6hRVd.rFD4ScPWA.3fBB8g2..VT3Rf1.jGcy8bxHaIui8Vyp9MJZX.vk0; S_INFO=1553494481|0|1&65##|m15770570072; P_INFO=m15770570072@163.com|1553494481|0|mail163|00&99|CN&1553476190&mail163#CN&null#10#0#0|157072&1|kaola&mail163|15770570072@163.com; MUSIC_EMAIL_U=112871895ffcc9c558231ef8b14c72465053be85f4706fa68125a8c6b9f1c7089e11ed1b8eda0a668b868433afc35e6d2383765fb87ce1fef2f513a9c38b5dc7; JSESSIONID-WYYY=9G0H2Gt%5C%2BkEsnP%2BUTkJdbPA6O%5C%2F2w%2BlFnFTDDdBbzpJG13a%5CeCGdp%2F7U%2FoHCA8cE6jxegjO%5Ccc%2FZyXbS%2Bw%2Fe2FEtEwfIARUM1x7QGDnWEsSQYfZ%5CHPZAO1msgcS3TvPwqjnN1q2bsteorR3DEPNr6drhmAyqgc53bCq5i8pGz6HoPk2H%3A1553497555044; MUSIC_U=e4ace7b13afdd88161175bda1c0914451762803785e1030d4312dda6e71aff68ca2d83fe0a175eb59e0eb32aa5fb495e8bafcdfe5ad2b092; __remember_me=true; __csrf=60e2fad5dc1d688abf984595f6a277e1',}
t=0
i=0
path = 'G:/爬虫/网易云1/'
for flag in range(0,38):
link = url + str(t)
t+=35
page = urllib.request.Request(link,headers = headers)
html = urllib.request.urlopen(page).read()
soup = BeautifulSoup(html,'html.parser')
div = soup.find('div',class_='g-bd')
div1 = div.find_all('div',class_='u-cover u-cover-1') #获取到歌单图片和歌单标题所在数据
for a in div1:
i+=1
img = a.find_all('img') #获取到歌单封面所在标签
title = a.find_all('a',class_='msk') #获取到歌单标题所在标签
for b in img:
img_src = b.get('src') #获取到歌单封面链接
img_src = img_src[:-14]
for c in title:
final_title = c.get('title').replace(' ','') #获取到歌单标题
urllib.request.urlretrieve(img_src, path + str(i) + '.jpg')
print('(第%d张)专辑:<<%s>>图片下载成功'%(i,final_title))
print('下载完毕!总计下载%d张图片'%(i))
print(' 语种','\n',
' 华语 | 欧美 | 日语 | 韩语 | 粤语 | 小语种 |','\n',
'风格','\n',
' 流行 | 摇滚 | 民谣 | 电子 | 舞曲 | 说唱| 轻音乐 | 爵士 | 乡村 | R&B/Soul | 古典 | 民族 | 英伦 | 金属 | 朋克 | 蓝调 ','\n',
' 雷鬼 | 世界音乐 | 拉丁 | 另类/独立| New Age| 古风| 后摇| Bossa Nova|','\n',
'场景','\n',
' 清晨 | 夜晚 | 学习 | 工作 | 午休 | 下午茶 | 地铁 | 驾车 | 运动 | 旅行 | 散步 | 酒吧 |','\n',
'情感','\n',
' 怀旧 | 清新 | 浪漫 | 性感 | 伤感 | 治愈 | 放松 | 孤独 | 感动 | 兴奋 | 快乐 | 安静 | 思念 |','\n',
'主题','\n',
' 影视原声 | ACG | 儿童 | 校园 | 游戏 | 70后 | 80后 | 90后 | 网络歌曲 | KTV | 经典 | 翻唱 | 吉他 | 钢琴 | 器乐 | 榜单 | 00后 |')
type1=input('请输入想要下载歌单图片的类型:')
getimg(type1)运行效果

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}