







收获:
使用vector创建二维数组的思路其实是创建一维数组,然后用另一个一维数组去初始化第一个一维数组,所以二维数组的初始化,也就变成了对内嵌一维数组的初始化操作:
vector<vector<int>> cost_map(grid.size(),vector<int>(grid[0].size(),INT_MAX));
//其中 , vector<int>(grid[0].size(),INT_MAX) 是对内嵌一维数组的初始化
//初始化一维数组完成之后,用此一维数组去初始化二维数组
题目:
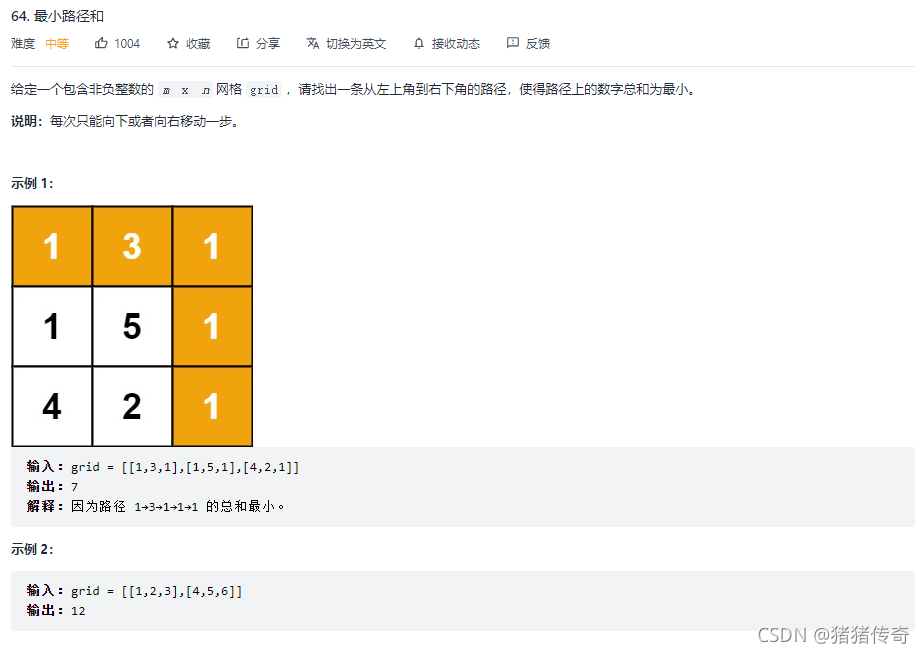
思路:
思路很简单,只要涉及到状态的,无非就那么几种方法:深搜,广搜,动态规划。
这里求最小值,用动态规划最好,时间最低
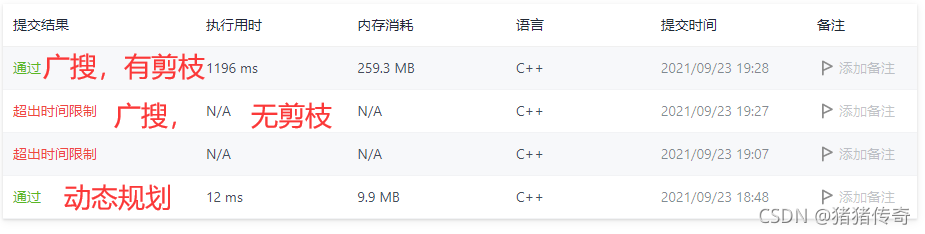
如果用深搜广搜则会超时,在这道题目中深搜广搜的复杂度都是一样的。也就是会枚举所有到达终点的状态,如果需要剪枝操作,也是维护一个当前最小cost的数组,当大于这个cost的时候,就丢弃当前状态。如果不使用剪枝,是超时的,使用了剪枝才将将AC。
运行结果:
代码:
动态规划,还是状态转移问题,动态规划最好的一点是,状态数组里面保存的始终是最优的,这样下次转移的时候也是最优的。一直是最优的。
class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
vector<vector<int>> dp(grid);
for(int i=1;i<grid.size();i++){
dp[i][0] = grid[i][0] + dp[i-1][0];
}
for(int i=1;i<grid[0].size();i++){
dp[0][i] = grid[0][i] + dp[0][i-1];
}
for(int i=1;i<grid.size();i++){
for(int j=1;j<grid[0].size();j++){
dp[i][j] = min(dp[i-1][j],dp[i][j-1]) + grid[i][j];
}
}
return dp[grid.size()-1][grid[0].size()-1];
}
};
差一点超时做法:广度优先搜索
这里的广搜必须剪枝,不剪就超时,维护一个cost数组,当当前状态大于cost数组中的值,则丢弃当前状态
class Solution {
public:
struct item{
int i;
int j;
int cost;
};
int next[2][2] = {{1,0},{0,1}};
int minPathSum(vector<vector<int>>& grid) {
int v = grid.size() - 1;
int l = grid[0].size() - 1;
if(v == 0 && l == 0) return grid[0][0];
item tmp;
vector<vector<int>> cost_map(grid.size(),vector<int>(grid[0].size(),INT_MAX));
int cost_sum = INT_MAX;
queue<item> q;
tmp.i = 0;
tmp.j = 0;
tmp.cost = grid[tmp.i][tmp.j];
q.push(tmp);
while(!q.empty()){
item t = q.front();
q.pop();
for(int k = 0;k<2;k++){
int next_i = t.i + next[k][0];
int next_j = t.j + next[k][1];
if(next_i<0 || next_i > v || next_j <0 || next_j>l || t.cost + grid[next_i][next_j] >= cost_map[next_i][next_j])continue;
item t1;
t1.i = next_i;
t1.j = next_j;
t1.cost = t.cost + grid[next_i][next_j];
cost_map[t1.i][t1.j] = t1.cost;
if(t1.i == v && t1.j == l){
cost_sum = min(cost_sum,t1.cost);
}
q.push(t1);
}
}
return cost_sum;
}
};














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









