




 本文介绍了用于目标检测的创新模型MIAOD,它在Pascal VOC和MS COCO数据集上实现了高效目标检测,仅需少量标注就能达到接近全量数据的效果。文章重点讨论了模型如何通过实例不确定性学习和重新加权策略过滤背景噪声,显著提升检测性能。
本文介绍了用于目标检测的创新模型MIAOD,它在Pascal VOC和MS COCO数据集上实现了高效目标检测,仅需少量标注就能达到接近全量数据的效果。文章重点讨论了模型如何通过实例不确定性学习和重新加权策略过滤背景噪声,显著提升检测性能。
Multiple Instance Active Learning for Object Detection用于目标检测的多实例主动学习
原文链接:[2104.02324] Multiple instance active learning for object detection (arxiv.org)
代码:GitHub - yuantn/MI-AOD: Code for Multiple Instance Active Learning for Object Detection, CVPR 2021
最近在研究主动学习,找了一篇cvpr2021的文献来读,简单做一下阅读笔记。
介绍:为主动学习与目标检测量身打造的首创性结合模型,在Pascal voc数据集上以20%数据的标注达到了100%数据集标注的93.5%效果,在mscoco数据集上达到最优效果。并且可以推广到任意模型上去。
一、背景介绍
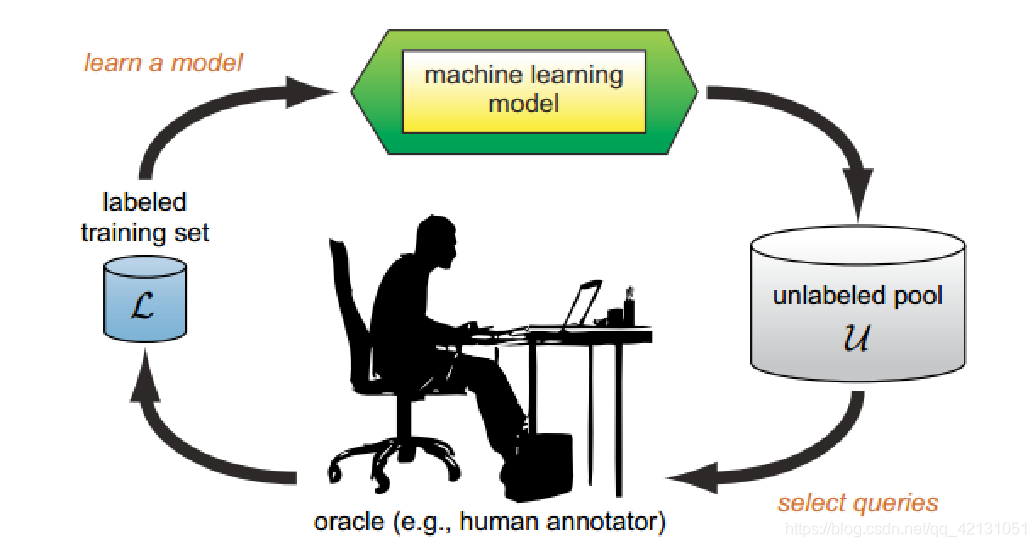
简单介绍一下主动学习,通过以周期性、学习性的方法,用少量标记获得高效特征。这个过程是由机器学习初始化的已标记数据集后,在未标记数据集中选择信息量大或者差异性大的数据进行人工标记后,将人工标记后的数据加入到数据集中再次训练,迭代进行数据的筛选与训练完成的,可以减少训练成本,适用于标记较难获得,但未标记数据容易获得的实验。
拿之前存的一个图,大概是这么个过程
作者提出了三种挑选样本的方法:
基于不确定度:为图像分类而设计的,并且由于拥挤和噪声情况的挑战性而不适用于对象检测。
基于分布(这些方法通过估计未标记样本的分布来选择
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









