







 本文讲述了如何利用Python编写脚本,通过Selenium获取网页内容,结合FFmpeg解析M3U8链接,实现动漫视频的自动化搜索和下载。
本文讲述了如何利用Python编写脚本,通过Selenium获取网页内容,结合FFmpeg解析M3U8链接,实现动漫视频的自动化搜索和下载。
python做一个樱花动漫视频的蜘蛛(配合ffmpeg和selenium)
代码思路:
- 获取m3u8链接(通过xpath去定位)然后放入ffmpeg去测试能否拿得到,若能拿到就先去寻找该链接在哪,然后定位到那个链接然后进行分析
- 找得到m3u8链接之后,就从动漫搜索框所在的页面,寻找如何跳过去
- 跳过去之后查找集数然后找到跳转到m3u8的链接进行储存
代码环境以及代码位置
gitee地址:https://gitee.com/dobest-li/YHanime-video
pip install lxml
pip install selenium
pip install ffmpy3
pip install socket
开始实现
- 找到动漫搜索框
-
搜索之后找到变化点在哪
-
 -
- 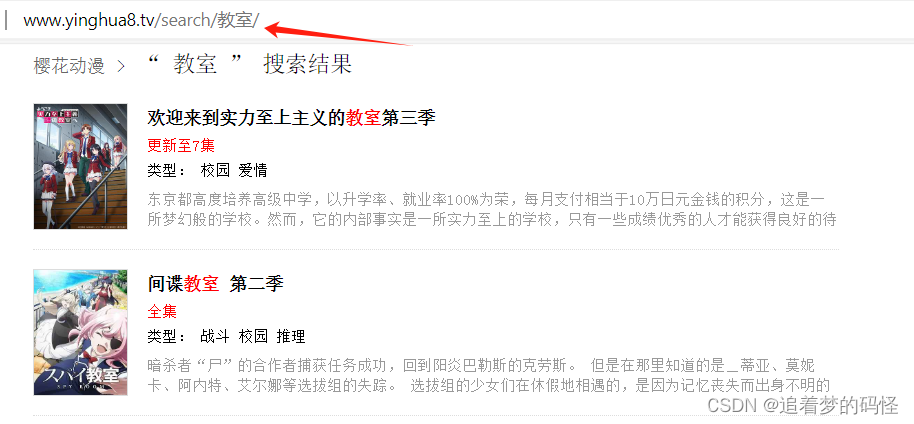
搜索之后可以发现链接是变化的,是用RESTful风格,以下是主要代码
-
word = input("请输入关键字进行搜索")
allurl = []
# 获取樱漫的Url Text
url_YH = "http://www.yinghua8.tv/search/"+word+"?page=1"
-
获取搜索之后页面列表
# 获取搜索到的列表进行返回 def getYHSearchList(self): topic_list = [] link_list = [] flag = 0 li_len = self.driver.find_elements(By.XPATH, '/html/body/div[4]/div[2]/div/ul/li') for j in range(1,999,1): if(flag == 1): break for i in range (0,len(li_len),1): print(i) try: topic = self.driver.find_elements(By.XPATH, '/html/body/div[4]/div[2]/div/ul/li')[i].text topic = topic.split("\n")[0] link = self.driver.find_elements(By.XPATH,'/html/body/div[4]/div[2]/div/ul/li/a')[i].get_attribute("href") topic_list.append(topic) link_list.append(link) except: flag=1 break if(len(li_len)<20): break print(topic_list) print(link_list) return topic_list,link_list -
获取集数
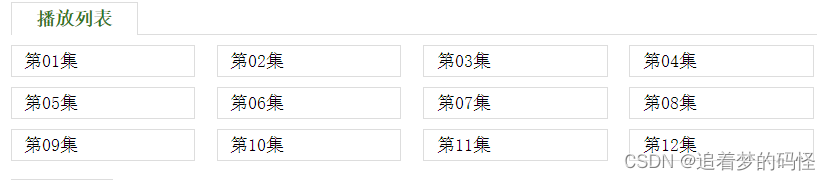
# 选择集数
def chooseEpisode(self):
print("------------------选集模块-------------------------")
episode_list = []
episode = self.driver.find_elements(By.XPATH,'//*[@id="main0"]/div/ul/li/a')
for i in episode:
episode_list.append(i.get_attribute("href"))
for i in range(0,len(episode_list),1):
print("第"+str(i+1)+"集-->"+episode_list[i])
modeNum = input("请选择模式,0是选单集(用英文逗号分割)---->")
chooseEpisodeNum = ""
if(modeNum == "0"):
chooseEpisodeNum = input("请选择您的集数")
self.downloadFilmOne(episode_list, int(chooseEpisodeNum)-1)
print("您选的集数链接是---->"+episode_list[int(chooseEpisodeNum)-1])
- 开始下载
# 下载单集
def downloadFilmOne(self,episode_list,chooseEpisodeNum):
self.driver.get(episode_list[chooseEpisodeNum])
print("-----------开始下载--------------")
findFlag = 0
try:
self.driver.find_element(By.XPATH,'//*[@id="playbox"]').get_attribute("data-vid")
except:
findFlag = 1
print("没找到m3u8资源")
if(findFlag == 0):
m3u8_str = self.driver.find_element(By.XPATH, '//*[@id="playbox"]').get_attribute("data-vid")
m3u8_url = m3u8_str.split("$")[0]
ffmpy3.FFmpeg(inputs={m3u8_url: None},
outputs={"第{}集.mp4".format(int(chooseEpisodeNum)+1): '-b:v 2000k -s 1920*1080 -crf 18'}).run()
以下是全部代码:
# -*- coding:utf-8 -*-
from lxml import etree
import ffmpy3
import socket
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#Film类
class Film:
# 初始化驱动
def initEdgeDriver(self):
option = webdriver.EdgeOptions()
# 阻塞住 防止它自动退出
option.add_experimental_option('detach', True)
option.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
return webdriver.Edge(options=option,executable_path="./msedgedriver.exe")
# 初始化数据
def __init__(self):
print("初始化中.....")
self.driver = self.initEdgeDriver()
# 定义prepareWork函数,做准备上班
def prepareWork(self, url):
self.driver.get(url)
time.sleep(1)
# 获取html
def getHtml(self,url):
# 防止远程断开
timeout = 20
socket.setdefaulttimeout(timeout)
self.driver.get(url)
html = self.driver.page_source
return html
# 获取xml
def getXml(self,html):
elemt = etree.HTML(html)
return elemt
# 获取搜索到的列表进行返回
def getYHSearchList(self):
topic_list = []
link_list = []
flag = 0
li_len = self.driver.find_elements(By.XPATH, '/html/body/div[4]/div[2]/div/ul/li')
for j in range(1,999,1):
if(flag == 1):
break
for i in range (0,len(li_len),1):
print(i)
try:
topic = self.driver.find_elements(By.XPATH, '/html/body/div[4]/div[2]/div/ul/li')[i].text
topic = topic.split("\n")[0]
link = self.driver.find_elements(By.XPATH,'/html/body/div[4]/div[2]/div/ul/li/a')[i].get_attribute("href")
topic_list.append(topic)
link_list.append(link)
except:
flag=1
break
if(len(li_len)<20):
break
print(topic_list)
print(link_list)
return topic_list,link_list
# 选择影片
def chooseFilm(self,topic_list,herf_list):
for i in range(0,len(topic_list),1):
print("------"+str(i)+"----->"+topic_list[i])
filmNameNum = input("请输入您想爬取的电影(输入编号):")
self.driver.get(herf_list[int(filmNameNum)])
# 选择集数
def chooseEpisode(self):
print("------------------选集模块-------------------------")
episode_list = []
episode = self.driver.find_elements(By.XPATH,'//*[@id="main0"]/div/ul/li/a')
for i in episode:
episode_list.append(i.get_attribute("href"))
for i in range(0,len(episode_list),1):
print("第"+str(i+1)+"集-->"+episode_list[i])
modeNum = input("请选择模式,0是选单集,1是选全部,2是选区间(输入起始与结束区间),3是选某几集(用英文逗号分割)---->")
chooseEpisodeNum = ""
if(modeNum == "0"):
chooseEpisodeNum = input("请选择您的集数")
self.downloadFilmOne(episode_list, int(chooseEpisodeNum)-1)
print("您选的集数链接是---->"+episode_list[int(chooseEpisodeNum)-1])
# 下载单集
def downloadFilmOne(self,episode_list,chooseEpisodeNum):
self.driver.get(episode_list[chooseEpisodeNum])
print("-----------开始下载--------------")
findFlag = 0
try:
self.driver.find_element(By.XPATH,'//*[@id="playbox"]').get_attribute("data-vid")
except:
findFlag = 1
print("没找到m3u8资源")
if(findFlag == 0):
m3u8_str = self.driver.find_element(By.XPATH, '//*[@id="playbox"]').get_attribute("data-vid")
m3u8_url = m3u8_str.split("$")[0]
ffmpy3.FFmpeg(inputs={m3u8_url: None},
outputs={"第{}集.mp4".format(int(chooseEpisodeNum)+1): '-b:v 2000k -s 1920*1080 -crf 18'}).run()
if __name__ == '__main__':
try:
print("不要输入超过提示的范围,否则将会报错退出")
word = input("请输入关键字进行搜索(搜索较慢请耐心等待,网络会影响搜索速度,软件会捕捉所有可能下载的剧名并显示,2分钟没出来请关闭重试)")
allurl = []
# 获取樱漫的Url Text
url_YH = "http://www.yinghua8.tv/search/"+word+"?page=1"
film = Film()
html = film.getHtml(url_YH)
topic_list,link_list = film.getYHSearchList()
film.chooseFilm(topic_list,link_list)
film.chooseEpisode()
except Exception:
print("报错了"+Exception)
运行效果
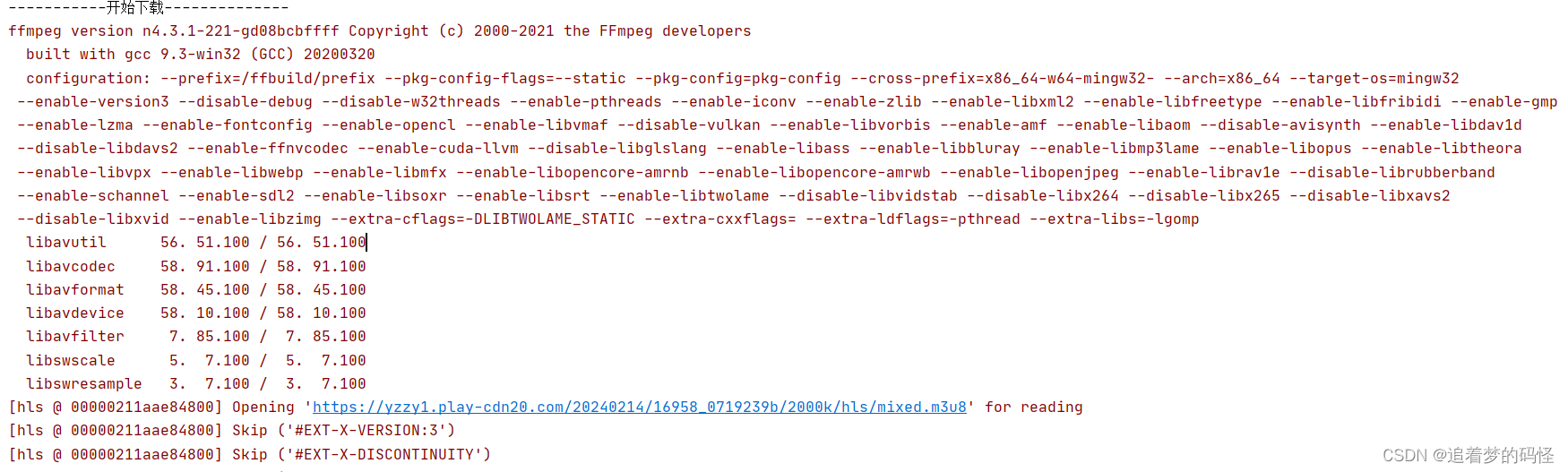


注意事项:
- 仅供学习研究使用
- 该代码需要有ffmpeg和selenium-4.8.3.dist-info配合使用,因为4.8.3可以指定webdriver的位置
- webdriver一定要配合对应的浏览器进行驱动
- ffmpeg和webdriver建议和源码放在一个目录下
- 如果发现代码找不到资源如空列表[],[],空链接时候,可能是页面加载慢但代码先行,可以加个time.sleep()这个函数等待页面加载出来(放到 self.driver.get(xxx)之后)。
- 直接运行,记得要让FFmpeg和webdriver与代码在同一目录下
- selenium这个版本要用selenium-4.8.3.dist-info与selenium文件夹,在site-packages中有(因为这个版本可以指定webdriver的位置)。
- pyinstaller打包的时候,若ffmpy3打不上去,参考博客:https://blog.csdn.net/qq_42145991/article/details/136199973
- webdriver一定要和浏览器匹配(edge有自己的驱动,谷歌有谷歌的驱动),该代码中的driver是匹配edge 121.0.2277.128版本


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









