




 本文介绍了PyTorch中搭建神经网络模块的方法,包括如何保存和提取网络及其参数。批训练的概念被讲解,强调了epochs和batch-size在训练过程中的作用,解释了批训练如何减少随机性和计算量。最后,讨论了不同的Optimizer,如SGD、Momentum、RMSprop和Adam,指出选择适合数据和网络的优化器的重要性。
本文介绍了PyTorch中搭建神经网络模块的方法,包括如何保存和提取网络及其参数。批训练的概念被讲解,强调了epochs和batch-size在训练过程中的作用,解释了批训练如何减少随机性和计算量。最后,讨论了不同的Optimizer,如SGD、Momentum、RMSprop和Adam,指出选择适合数据和网络的优化器的重要性。
1、搭建神经网络模块
# 方法一
class Net(torch.nn.Module): # 继承 torch 的 Module
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__() # 继承 __init__ 功能
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出
self.out = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出
def forward(self, x):
# 正向传播输入值, 神经网络分析出输出值
# F.relu()这是一个函数
x = F.relu(self.hidden(x)) # 激励函数(隐藏层的线性值)
x = self.out(x) # 输出值, 但是这个不是预测值, 预测值还需要再另外计算
return x
'''
Net(
(hidden): Linear(in_features=2, out_features=10, bias=True)
(out): Linear(in_features=10, out_features=2, bias=True)
)
'''
# 方法二
net2 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
# ReLU()这是一个类
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
'''
Sequential(
(0): Linear(in_features=1, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=1, bias=True)
)
'''
2、保存和提取神经网络模块
保存:保存整个网络;或只保存网络的参数
def save():
# 建网络
net1 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
optimizer = torch.optim.SGD(net1.parameters(), lr=0.2)
loss_func = torch.nn.MSELoss()
# 训练
for t in range(100):
prediction = net1(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.save(net1, 'net.pkl') # 保存整个网络
torch.save(net1.state_dict(), 'net_params.pkl') # 只保存网络中的参数 (速度快, 占内存少)
提取: 提取整个神经网络/提取整个神经网络参数复制到新建立的结构相同的神经网络上
# 这种方式将会提取整个神经网络
net2 = torch.load('net.pkl')
prediction = net2(x)
# 提取整个神经网络参数复制到新建立的结构相同的神经网络上
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
# 将保存的参数复制到 net3
net3.load_state_dict(torch.load('net_params.pkl'))
prediction = net3(x)
3、批训练
epochs指的就是训练过程中数据将被“轮”多少次。(自行理解是同样的数据训练多少次)
batch-size(用mini-batch SGD的时候每个批量的大小)
step=所有数据/ batch-size
这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
4、Optimizer 优化器
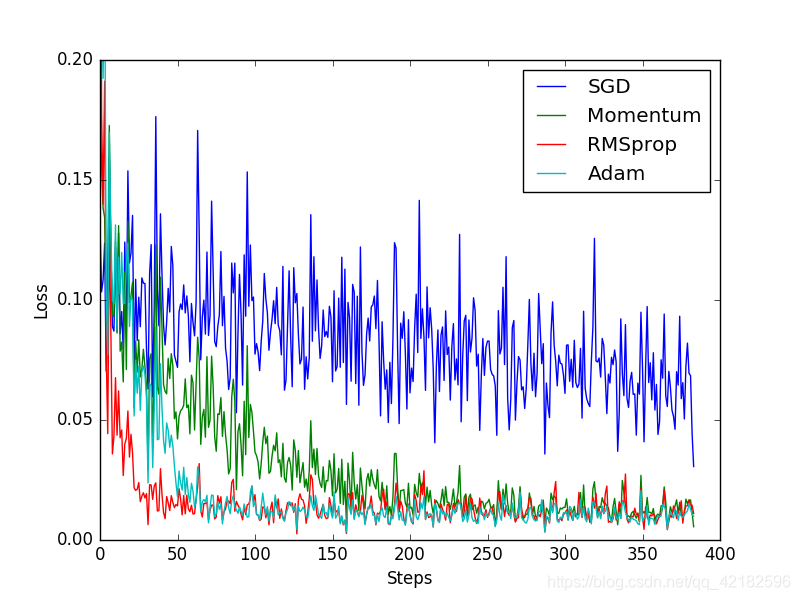
SGD 是最普通的优化器, 也可以说没有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了动量原则. 后面的 RMSprop 又是 Momentum 的升级版. 而 Adam 又是 RMSprop 的升级版. 不过从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点. 所以说并不是越先进的优化器, 结果越佳. 我们在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据/网络的优化器.

















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









