






文章目录
1. ClassPathBeanDefinitionScanner的用途
用于扫描给定包下的类
像日常开发用到的
@ComponentScan@SpringBootApplication
这两个注解都是基于ClassPathBeanDefinitionScanner来实现的。
2. 如何基于包扫描类
首先提出一个问题:如通过给定包名来扫描包中类的信息呢?
方式一:使用Class.forName
- 首先,通过包名访问目录下的所有class文件。
- 接下来,将所有class文件的路径转换为类路径格式,例如将 “a/b/c/HelloWorld.class” 转换为 “a.b.c.HelloWorld”。
- 最后,使用
Class.forName方法加载a.b.c.HelloWorld。
方式二:基于字节码库
- 同样,首先通过包名访问目录下的所有class文件。
- 然后,通过字节码库读取这些class文件,以获取类信息。
Spring采取的是方式二
并且使用ASM作为字节码库, ( ASM是java字节码类库中性能最高的之一 )
那为什么Spring不采用Class.forName呢
使用Class.forName必定会经历查找 -> 加载 -> 初始化的过程,最终将类加载到JVM中
可是我们指定一个包去扫描,只需要扫描出包含特定注解的类,而并不需要将所有的类都加载到JVM中
3. ClassPathBeanDefinitionScanner的调用入口
从ClassPathBeanDefinitionScanner暴露的publicscan方法作为入口
3.1 scan
public int scan(String... basePackages) {
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
// 调用 { doScan }
doScan(basePackages);
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
3.2 doScan
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 遍历所有要扫描的包
for (String basePackage : basePackages) {
// 传入包名调用 findCandidateComponents
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
// 省略其他代码...
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
3.3 findCandidateComponents
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
// 用于读取META-INF/spring.components
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 跟踪else分支
return scanCandidateComponents(basePackage);
}
}
3.4 scanCandidateComponents
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
// 1. 将包名转换为路径 , 例如: "a.b.c" => "classpath:a/b/c/**/*.class"
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 2. 获取路径下的所有文件对象: ( 注: Resource类是Spring的资源工具类, 这里可以将其认为是一个File对象 )
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
for (Resource resource : resources) {
// 3. 获取MetadataReader ( 核心方法: Spring就是在这一步通过ASM读取class文件的 )
// getMetadataReaderFactory()将会返回 { CachingMetadataReaderFactory } , Spring写死的
// 接下来主要跟踪 { CachingMetadataReaderFactory#getMetadataReader } 方法
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
candidates.add(sbd);
}
}
}
return candidates;
}
3.5 CachingMetadataReaderFactory#getMetadataReader
首先请思考一个问题:
缓存是有必要的吗
举个很简单的例子
假设在项目中既使用了@ComponentScan,还使用了@DubboComponentScan和@MapperScan
那么不可避免的就会读到相同的class文件,所以缓存是很有必要的
public MetadataReader getMetadataReader(Resource resource) throws IOException {
if (this.metadataReaderCache instanceof ConcurrentMap) {
MetadataReader metadataReader = this.metadataReaderCache.get(resource);
if (metadataReader == null) {
metadataReader = super.getMetadataReader(resource);
this.metadataReaderCache.put(resource, metadataReader);
}
return metadataReader;
}
// 只会走这个分支
// { CachingMetadataReaderFactory } 在构造方法中会初始化 { metadataReaderCache } 为 { LinkedHashMap }
else if (this.metadataReaderCache != null) {
synchronized (this.metadataReaderCache) {
// 尝试读缓存
MetadataReader metadataReader = this.metadataReaderCache.get(resource);
if (metadataReader == null) {
// 读不到缓存, 那么通过ASM解析class文件
// 接下来继续跟踪 { super.getMetadataReader } ( super是:SimpleMetadataReaderFactory )
metadataReader = super.getMetadataReader(resource);
this.metadataReaderCache.put(resource, metadataReader);
}
return metadataReader;
}
}
else {
return super.getMetadataReader(resource);
}
}
3.6 SimpleMetadataReaderFactory#getMetadataReader
@Override
public MetadataReader getMetadataReader(Resource resource) throws IOException {
return new SimpleMetadataReader(resource, this.resourceLoader.getClassLoader());
}
SimpleMetadataReader构造方法
SimpleMetadataReader(Resource resource, @Nullable ClassLoader classLoader) throws IOException {
// 1. SimpleAnnotationMetadataReadingVisitor 是一个 { ClassVisitor } ( 注: ClassVisitor属于ASM部分 )
SimpleAnnotationMetadataReadingVisitor visitor = new SimpleAnnotationMetadataReadingVisitor(classLoader);
// 2. 通过 { resource } 创建 { ClassReader } , 在accept方法中会遍历class文件, 并且回调 { visitor } 的方法
getClassReader(resource).accept(visitor, PARSING_OPTIONS);
this.resource = resource;
this.annotationMetadata = visitor.getMetadata();
}
ClassVisitor方法相关实现细节就不深究了
ClassReader会遍历class文件中的所有字段/方法/注解等,并且回调ClassVisitor的相关方法
在第二步遍历完成后,SimpleMetadataReader就保存了该class文件所有的注解信息
回到 scanCandidateComponents方法继续跟踪
3.7 scanCandidateComponents
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
// 1. 将包名转换为路径 , 例如: "a.b.c" => "classpath:a/b/c/**/*.class"
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 2. 获取路径下的所有文件对象: ( 注: Resource类是Spring的资源工具类, 这里可以将其认为是一个File对象 )
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
for (Resource resource : resources) {
// 3. 获取MetadataReader ( 核心方法: Spring就是在这一步通过ASM读取class文件的 )
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 4. 根据注解过滤
// @ComponentScan 可以指定excludeFilters和includeFilters
// 默认是只包含 { @Component } 注解 ( 注: @Service / @Controller / @Repository 都属于@Component )
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 只有满足一下任一条件才会返回 true
// - 是外部类, 或者内部静态类
// - 不是接口也不是抽象类
// - 是抽象类, 但是类中方法有 { @Lookup } 注解 : 这种情况比较少见
if (isCandidateComponent(sbd)) {
// 添加到集合中
candidates.add(sbd);
}
}
}
// 返回集合
return candidates;
}
接下来继续回到doScan方法
3.8 doScan
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 遍历所有要扫描的包
for (String basePackage : basePackages) {
// 传入包名调用 findCandidateComponents
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 此时已经扫描完成了, 并且拿到了扫描后的 { BeanDefinition } 集合
for (BeanDefinition candidate : candidates) {
// 检查是否有重复的 { BeanDefinition }
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册到 { BeanDefinitionRegistry } 中
// { this.registry } 在ClassPathBeanDefinitionScanner的构造方法中传入
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
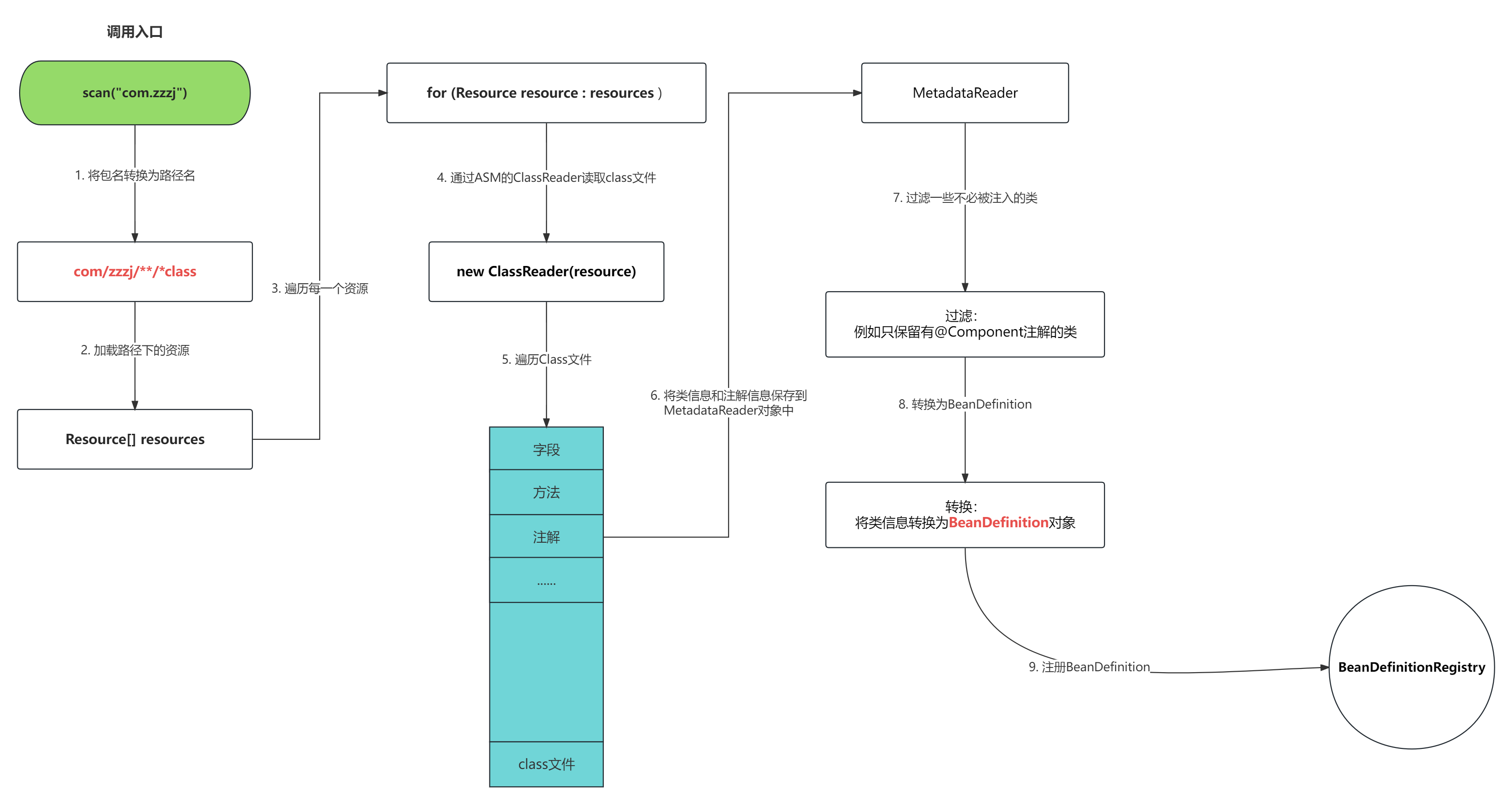
4. 总结
ClassPathBeanDefinitionScanner的扫描源码总的来说还是不复杂的,主要有以下步骤
- 遍历所有要扫描的包名
- 将包名转换为路径,例如 “com.abc.efg” 转换为 “com/abc/efg/**/*.class”
- 使用Spring的工具类获取路径下所有class文件对应的
Resource对象 - 将Resource对象传入ASM的ClassReader
- ClassReader读取class文件,遍历class文件所有的 字段/方法/注解 等,并且回调Spring的ClassVisitor
- ClassVisitor保存下所有的注解
- 根据
includeFilter和excludeFilter过滤注解,过滤掉一些用不到的类 - 将类转换为
BeanDefinition - 将
BeanDefinition注册到BeanDefinitionRegistry
5. 流程图















 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









