







Hive已经成为数据仓库生态系统中的核心。它不仅仅是一个用于大数据分析和ETL场景的SQL引擎,同样也是一个数据管理平台,一些被大家广泛使用大数据处理引擎都声称对Hive有着很好的兼容性。而Flink从1.9开始支持Hive,只不过是beta版,不推荐在生产环境中使用。在Flink1.10版本中,标志着对Blink的整合宣告完成,对Hive的集成也达到了生产级别的要求。本文以目前最新的Flink1.12.1为例,阐述Flink集成Hive的简单过程。
HiveCatalog
多年来,Hive Metastore在Hadoop生态系统中已发展成为元数据中心。许多公司在其生产中只有一个Hive Metastore服务实例,用来管理其所有元数据,因此Flink也顺理成章的将元数据保存在Metastore中,这样做的好处是我们使用Flink SQL创建的表,用户必须在每个会话中重复创建像Kafka表这样的元对象,浪费大量时间。HiveCatalog可以让用户仅一次创建表和其他元对象,并在以后的跨会话中方便地引用和管理它们。
设置HiveCatalog
支持的Hive版本
| 大版本 | V1 | V2 | V3 | V4 | V5 | V6 | V7 |
|---|---|---|---|---|---|---|---|
| 1.0 | 1.0.0 | 1.0.1 | |||||
| 1.1 | 1.1.0 | 1.1.1 | |||||
| 1.2 | 1.2.0 | 1.2.1 | 1.2.2 | ||||
| 2.0 | 2.0.0 | 2.0.1 | |||||
| 2.1 | 2.1.0 | 2.1.1 | |||||
| 2.2 | 2.2.0 | ||||||
| 2.3 | 2.3.0 | 2.3.1 | 2.3.2 | 2.3.3 | 2.3.4 | 2.3.5 | 2.3.6 |
| 3.1 | 3.1.0 | 3.1.1 | 3.1.2 |
不同的Hive版本功能上会有差异,因此当你发现某些功能无法使用时,这可能就是Hive版本不一致造成
本文列出部分差异:
- Hive内置函数在Hive-1.2.0及更高版本时支持
- 列约束PRIMARY KEY和NOT NULL,在使用Hive-3.1.0及更高版本时支持
- 更改表的统计信息,在Hive-1.2.0及更高版本支持
- DATE列统计信息,在Hive-1.2.0及更高版本支持
- 使用Hive-2.0.x版本时不支持写入ORC表
依赖包
本文以Flink1.12为例,集成的Hive版本为1.2.1。由于Flink事先也不知道用户会集成什么版本的Hive,因此在与Hive集成时,我们需要手动添加一些依赖包到环境当中。
首先是添加对应版本的连接器,Flink在官网提供了各个Hive版本的连接器

点我跳转
本文选择的是第一个。如果您使用的Hive版本没有列出,那么需要分别添加每个所需的jar包。
然后添加hadoop类路径,在/etc/profile中添加以下内容
export HADOOP_CLASSPATH=`hadoop classpath`
export PATH=$PATH:$HADOOP_CLASSPATH
最后还需要两个jar包flink-connector-hive_2.11-1.12.1.jar和hive-exec-1.2.2.jar,其中hive-exec-1.2.2.jar包存在于Hive安装路径的lib文件夹。flink-connector-hive_2.11-1.12.1.jar的下载地址为https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.11/1.12.0/
配置sql-client-defaults.yaml
Flink SQL Cli启动时会读取sql-client-defaults.yaml配置文件,该文件存在于$FLINK_HOME/conf下,具体配置详情如下:

| 参数 | 必选 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| type | 是 | (无) | String | Catalog 的类型。 创建 HiveCatalog 时,该参数必须设置为’hive’。 |
| name | 是 | (无) | String | Catalog 的名字。仅在使用 YAML file 时需要指定。 |
| hive-conf-dir | 否 | (无) | String | 指向包含 hive-site.xml 目录的 URI。 该 URI 必须是 Hadoop 文件系统所支持的类型。 如果指定一个相对 URI,即不包含 scheme,则默认为本地文件系统。如果该参数没有指定,我们会在 class path 下查找hive-site.xml。 |
| default-database | 否 | default | String | 当一个catalog被设为当前catalog时,所使用的默认当前database。 |
| hive-version | 否 | (无) | String | HiveCatalog 能够自动检测使用的 Hive 版本。我们建议不要手动设置 Hive 版本,除非自动检测机制失败。 |
| hadoop-conf-dir | 否 | (无) | String | Hadoop 配置文件目录的路径。目前仅支持本地文件系统路径。我们推荐使用 HADOOP_CONF_DIR 环境变量来指定 Hadoop 配置。因此仅在环境变量不满足您的需求时再考虑使用该参数,例如当您希望为每个 HiveCatalog 单独设置 Hadoop 配置时。 |
启动相关组件
- 由于要用到Hive的元数据管理,因此确保Hive Metastore正在运行
启动metastore:
bin/hive --service metastore
后台启动:
bin/hive --service metastore 2>&1 >> /var/log.log &
后台启动,关闭shell连接依然存在:
nohup bin/hive --service metastore 2>&1 >> /var/log.log &
- 启动Flink的standalone集群(Flink SQLClient执行时需要)
$FLINK_HOME/bin/start-cluster.sh
操作Hive表
下面我们就可以像Hive Cli一样操作Hive表啦。首先启动FlinkSQL Cli
./bin/sql-client.sh embedded
看到一只大松鼠说明启动成功

查看注册的catalog
Flink SQL> show catalogs;
default_catalog
myhive
选择catalog
Flink SQL> use catalog myhive;
查看表
Flink SQL> show tables;
kafkatable
kylin_account
kylin_cal_dt
kylin_category_groupings
kylin_country
kylin_sales
tb_test_sqlclient
test
testkafka
使用Flink SQL查询Hive表
Flink SQL> select * from tb_test_sqlclient;

插入一条数据,从Hive客户端查看是否存在
Flink SQL> insert into tb_test_sqlclient select 2,'kris';
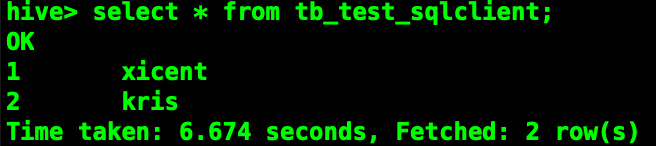
可见从Flink SQLClient插入一条数据,在Hive客户端同样可以查询到。
此时打开Flink Standalone WebUI我们可以看到刚刚SQL执行的任务

OK,Flink SQL Client集成Hive是不是特别简单,这只是SQL Client一个很小的功能而已喔,我们还可以使用它执行流处理任务并实时查看输出的结果等等,下一篇将带大家看看如何使用Flink SQL Client消费Kafka数据提交流式任务。
微信公众号:喜讯Xicent
















 9864
9864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









