





移动设备的自然语言接口
Boris Katz, Gary Borchardt,Sue Felshin, and Federico Mora
介绍
人类几乎毫不费力地用自然语言表达他们的需求,因此,构造能够可靠地响应自然语言请求的机器一直是智能系统设计的长期目标和重要目标。早期成功—例如,Woods、Kaplan和Nash-Webber(1972)的月球系统,Hendrix、Sacerdoti、Sagalowicz和Slocum的梯子系统(1978年),以及Waltz的平面系统(1978)——依赖于应用特定的语法来编码特定领域或数据集的各种约束。虽然这种方法使这些系统能够响应其目标域中的一系列请求,但是系统不能很容易地移植到相关的或扩展的域中,而且它们在表达请求时使用的词汇和句法结构的覆盖面有限。最近开发的系统,如Harabagiu、Maiorano和和Pasca(2003年);Katz(1997年);Nyberg、Burger、Mardis和Ferrucci(2004年),以及Weischedel、Xu和Lichuana(2004年)—处理多个域,并使用通用语法或统计语言解释来处理用户可能提交的各种请求和短语。随着越来越多的信息源在网络中可用,加上移动设备作为请求的源和目标,最近的系统采用了更加分布式的体系结构。
在本章中,我们首先讨论与设计和构建自然语言接口,尤其是与移动设备的接口设备。然后,我们描述了这个空间中的两个系统:起始信息访问系统和启动移动的自然语言接口到移动设备。最后,我们讨论最近部署的商业系统和未来方向。
自然语言接口的目标
自然语言接口的主要目标当然是对用户请求产生适当的响应。请求可以请求接口提供信息,或者请求执行操作。接口可以对单个请求发出任意数量的响应:例如,它可以返回多个信息段,或者执行多个操作。
一般来说,接口响应的适当性可以使用信息检索领域中召回度和精确度指标的变体来评估。在此上下文中,可以计算收回率,即在许多请求中,通过将接口返回的适当响应的数量除以可能的适当响应的总数所形成的分数的平均值。精度可以计算为,在许多请求中,通过将接口返回的适当响应数除以接口返回的响应总数所形成的分数的平均值。回忆通常很难计算,因为可能没有方法枚举对请求的所有可能的、适当的响应——例如,可能返回的全部信息段,或者响应请求时可能执行的所有适当操作。回忆可能很重要,但在许多情况下,它的重要性要小一些,因为在那些用户只需要一个或几个令人满意的响应的上下文中。另一方面,精确度几乎总是很重要。返回许多不恰当响应的信息请求会分散用户的注意力,浪费显示空间,甚至可能误导用户。不适当的行动可能产生严重后果,必须不惜一切代价加以避免。
自然语言接口的另一个目标是领域覆盖。有限域系统在某些情况下是有用的,例如与单个特定数据库的接口。然而,总体来说,最近的趋势是构建接口,提供与大量数据集、域和可能的操作相关的单点交互。
易用性是自然语言接口的另一个重要方面。接口应尽可能接受不受限制的自然语言输入,它应表现出对请求和其他目的的解释的交互性,它应以多媒体信息作出回应,它应在需要时提供对其行为的解释,它应为回顾过去的响应提供一个历史机制等等。
自然语言接口的一个非常重要的方面是它们的处理复杂请求的能力。最简单的信息请求请求获取所有关于特定主题的可用信息:例如“告诉我关于德国”或某些特定属性,例如,“告诉我关于德国人口分布的情况。”更复杂的请求包括检索有关实体之间关系的信息,或执行涉及多个实体的命令。更复杂的是要求系统执行新的分析或操作。最后,一些请求可能涉及将要组合处理的子请求的嵌套。
移动设备的自然语言接口必须具有附加特性。这些接口必须能够根据不仅在移动设备本身而且在通过网络连接连接到设备的系统上可用的信息或操作作出响应。特别是在要执行操作的地方,此类系统必须具有极高的精度,因为撤销这些操作的方法通常是有限的。与此同时,移动设备通常用于用户注意力分散和不需要过多系统交互的环境;因此,在某些情况下,界面必须以极高的精度预先推断用户的意图。要实现这一点,系统可能需要依赖于从以前与该个体的交互中收集的信息、前面对话框的元素,或者其他可用的模式,如摄像机输入。移动设备的接口也必须特别响应用户的时间和位置,这些接口必须充分利用有限的显示空间。
START
我们首先讨论通用START信息访问系统,该系统自20世纪70年代初开始在麻省理工学院开发(Katz,1980、1990、1997;Katz, Borchardt和Felshin,2006年)。在其通用的问答应用程序中,START作为公共服务器可以访问http://start.mit.edu/。此版本的START回答一系列领域的问题,包括地理、艺术和娱乐,历史、科学以及维基百科中涉及的大量主题和领域。 除了通用‐用途的公共启动服务器外,还为特定的主题区域创建了几个专用‐用途服务器,其中一些涉及响应用户请求的操作的执行,另一些使用API来启动语言解析和生成功能。此外,START系统开创的几种策略被纳入了IBM的沃森系统。2011年在智力竞赛节目“危险”中击败了所有的人类冠军!(Hardesty
, 2011年;默多克,2012年)。START在其传统的问答角色中,接受英语问题,并利用包括结构化、半结构化和非结构化材料。其中一些材料在本地维护,另一些通过Internet远程访问。在某些情况下,响应由系统或其相关资源动态计算。START的一个特别重点是提供高精度的信息访问,这样用户可以保持高度的信心,如果系统返回的响应与提交的问题相匹配。图23.1给出了一个请求—响应交互实例。
START设计的一个特别重要的方面是使用三元表达式作为自然语言表达式的内部表示。三元表达式将语言表示为一组嵌套的主语-关系-宾语三元组,其中主语和宾语本身可以是三元表达式(Katz, 1988;Katz,1990)。三元表达式表示是一种通用的语法驱动的语言表示,它突出了重要的语义关系,并允许对语法和词汇特征进行详细编码。事实证明,由于它的速度快、紧凑性和用于存储、匹配和检索信息的准确性,它对START的解析和问题回答能力非常有益。
由于START最初是在开发的初始阶段配置的,所以它的作用是根据以前提交给系统的英语语句来回答英语问题,而这一操作也是START当前功能的基础。当START显示一个用于处理的英语语句时,它解析该语句并以一组嵌套三元表达式的形式对其进行编码。可以将START知识库中的结果条目看作是英语句子句法结构的“摘要”。然后以相同的方式分析用户提交的问题,并与知识库中存储的断言进行匹配。然后检索匹配的断言并将其表示为英语响应。(下面描述的使用自然语言注释的技术扩展了这种方法,使START能够提供额外的材料并执行计算来响应匹配。)因为匹配发生在句法结构的层次上,所以语言学上复杂的机制,如同义词、下义、本体和结构转换规则,都可以在匹配过程中发挥作用,从而实现远远超出简单关键字匹配的功能。

图23.1 START 执行货币转换.
特别是,结构转换规则使系统能够找到匹配,尽管由于动词和其他成分的参数的替代实现而导致表达上的显著差异(Katz & Levin,
1988)。例如,假设START有一个语句“Greece surprised the European Union with its actions.(希腊的行动使欧盟感到惊讶)”。这一声明也可以解释为“Greece’s actions surprised the European Union.(希腊的行动令欧洲感到意外)” 为了匹配与该语句的这个替代版本相关的问题,START必须使用结构转换规则,该规则可以表示为:
If < < subject verb object1 > with object2>
Then < object2 verb object1 > AND
<object2 related‐to subject>
Where verb belongs to the emotional‐reaction class
有了这个规则,START不仅可以回答
Did Greece surprise the European Union with its actions?
Did Greece surprise the European Union?
希腊的行动是否让欧盟感到意外?
希腊让欧盟感到意外吗?
而且,它还可以回答如下问题
Did Greece surprise the European Union with its actions?
Did Greece surprise the European Union?
希腊的行动令欧盟吃惊吗?
哪个国家的行动令欧盟感到惊讶?
注意,在START中,结构转换规则通常与动词类关联,而不是与单个动词关联。以上规则适用于所有情感反应类动词,包括“惊喜”、“愤怒”、“尴尬”等。在Levin(1993)中可以找到一系列其他适合用于结构转换规则的动词类。START设计的第二个重要方面是使用自然语言注释(Katz, 1997)。自然语言注释是与信息片段相关联的自然语言短语和句子,描述其内容。当START将用户请求与自然语言注释匹配时,它可以访问相关的信息片段作为对用户的响应。
例如,一个包含火星云信息的HTML片段可以用以下英语句子和短语进行注释:
火星上的云
火星云由水和二氧化碳组成。
…
START解析这些注释,并使用返回原始信息段的指针存储解析后的结构(嵌套三元表达式)。要回答一个问题,将用户查询与知识库中存储的注释进行比较。如果在从注释派生的三元表达式和从查询派生的三元表达式之间找到匹配,则将相应的带注释的段作为答案返回给用户。例如,上面的注释允许开始回答以下问题:
火星上有云吗?
火星上有云吗?
火星云的组成是什么?
你知道火星上的云是由什么构成的吗?
…
图23.2给出了开始回答此类问题的示例。
当然,除了少量特别重要的信息外,手工注释每个内容项是不切实际的。然而,所有类型的源——结构化、半结构化和非结构化——都可能包含大量的并行材料。参数化注释通过结合固定的语言元素和“参数”来解决这种情况,“参数”指定注释的可变部分。因此,它们可以用来描述整个类的内容,同时保留非参数化注释的索引功能。例如,参数化注释(参数以斜体显示)

图23.2 START使用基于注释的匹配回答问题。
住在城里的人数。
可以在数据方面描述包含不同城市人口数据的大型半结构化Web资源。在问题方面,该注释由结构转换规则支持,可以识别以多种形式提交的问题:
有多少人住在芝加哥?
匹兹堡人多吗?
有多少人住在西雅图?
住在波士顿的人多吗?
可以包括以其他方式描述总体数据的其他参数化注释(例如,使用术语“population”或“populous”),并且可以参数化注释的其他元素。因此,可以使用少量参数化注释回答大量不同的问题。例如,通过进一步的参数化,单个注释可以回答关于区域、海拔、人口密度和人口之外的其他属性的问题。
使用自然语言注释,特别是参数化自然语言注释,使START能够以各种方式响应用户请求。 例如,START可以从因特网上的资源检索多媒体信息或信息,执行计算,检索外语材料,并代表其用户执行特定操作。
因特网上和结构化数据集中可检索信息的一个重要子集由可视为“对象”集合的数据组成,每个对象具有一个或多个具有特定“值”的“属性”。START与一个名为Omnibase的系统协同工作,该系统管理符合这个对象属性值数据模型的信息(Katz et al., 2002)。
参数化注释充当START和Omnibase的对象-属性-值数据模型之间的接口,允许组合系统回答关于各种主题的问题,如国家的人口、地区、GDP或国旗;一个城市的人口、位置或地铁图;或名人的出生地、出生日期或配偶。对象-属性-值数据模型比表面上看起来更适用,因为可以使用不同的措辞强制转换许多对象属性问题;例句:“安格拉·默克尔的生日是几号?”可以这么说:“安格拉•默克尔(Angela Merkel)是什么时候出生的?”“阿根廷有多大?”可以写成“阿根廷有多大?”等等。然而,还有其他不属于对象-属性-值模型的可能类型的查询,例如关于两个对象的函数的信息量的问题(例如,“我如何从波士顿到纽约?”)。这些问题及其请求的信息可以通过更通用的自然语言注释进行建模。
图23.3展示了START使用Omnibase的支持回答的一个问题。
为了成功地将输入问题与参数化注释匹配,START必须知道哪些术语可以与任何给定的参数关联。Omnibase通过作为源特定终端的外部地名词典来支持这一要求,术语的变体可以从对象名称中计算、从信息源中的半结构化材料中提取或手动定义。这维护了抽象层的完整性:信息源术语与信息源处理一起保存。Omnibase对对象属性值数据模型的使用同样适用于固定的、半结构化的网站和通过特殊查询语言或基于交互表单的接口访问的“深度Web”源。当开始传递一个对象属性查询Omnibase时,Omnibase执行访问脚本相关的信息来源问题,和访问脚本可能获得单个元素的信息直接从一个静态的网页,从本地数据源中提取数据,或获取动态信息或“隐藏”信息与查询接口进行交互。
最近的工作使START和Omnibase系统能够访问信息,而不需要手动创建注释。许多信息源具有基本规则的结构,使我们能够提取属性-值对。此外,这些属性名通常以英语名词和其他短语的形式出现。在这种情况下,当询问对象-属性-值问题时,START首先分析问题以找到对象和属性名,然后运行一个过程来提取值作为对问题的响应。使用这种技术,START可以自动回答诸如“爱因斯坦的母校是哪里?”或者“意大利的电话号码是什么?”

图23.3 START和Omnibase使用英文来源的材料回答问题
维基百科是一个特别有用的信息来源,它是世界上最大的众包百科全书,拥有超过500万篇文章。文章按层次结构部分组织,许多文章都有一个表,该表总结了文章中的关键信息。为了访问这类信息,我们开发了WikipediaBase (Morales, 2016),该系统将维基百科转变为一个虚拟数据库,并以对象属性-值数据模型对其进行组织。我们将信息框属性和节标题视为属性。使用WikipediaBase,
START可以在“个人生活”部分的内容中回复“告诉我关于爱因斯坦的个人生活”或者“爱因斯坦获得了什么奖项?”在阿尔伯特·爱因斯坦(Albert Einstein)的信息箱里,有一排“著名奖项”。
凭借对英语形态和语法的理解,START可以识别对象-属性-值问题的变体。
它可以正确回答诸如“谁设计奥克兰海湾大桥?”(来自信息框中的“设计师”属性)或“布鲁克林大桥穿过什么河?”(来自信息框中的“十字架:东河”)等问题。
还可以以与属性名称几乎没有表面相似性的方式询问信息。例如,“爱因斯坦上的是哪所大学?”和“爱因斯坦在哪里学习?”以及“爱因斯坦的母校是谁?”但他们几乎没有什么共同语言。为了解决这些类型的问题,我们编制了一个关于维基百科信息框的超过15,000个问题的众包语料库。 我们使用这些问题来训练机器学习模型,该模型从一组候选答案中高精度地选择正确的答案(Morales,2016; Morales,Premtoon,Avery,Felshin,&Katz,2016)。 我们在回答问题的自动技术方面的持续工作将使START系统能够快速扩展到新类型的问题和信息来源。
一些用户请求可能包含子请求。例如,START的用户可能会提交一个请求“法国的总统是什么时候出生的?”这类问题很有趣,因为回答这些问题通常涉及来自不同来源的信息,实际上,系统必须回答问题的一部分。“谁是法国的总统?”——在继续使用这个子问题的答案之前——在这个例子中,Francois hollande——在另一个待回答的子问题中。“弗朗索瓦·奥朗德是什么时候出生的?”自然语言注释可以提供帮助,因为它们可以用来描述可以独立回答的简单问题集。此外,通过同义词、下位词等参数匹配机制,以及提供简单问题答案的底层机制,可以用来弥合资源之间的术语差异,从而允许回答一系列复杂问题。
START使用了一种方法,在这种方法中,它从语言学的角度分析复杂的问题,以便分离出有效的候选子问题,并确定回答这些子问题的合适顺序。然后,START通过带注释的资源材料库检查是否可以回答特定的子问题。这种方法在(Katz,Borchardt, & Felshin, 2005)中有更详细的描述。图23.4提供了一个回答复杂问题的示例。
START还包含一个复杂的自然语言生成功能,它接受一组三元表达式作为输入,并将其转换为可读的英语。此外,在生成之前,系统可以将三元表达式连接在一起、修改和扩充,使START能够根据需要生成单独的句子、叙事文本和对话元素。

图23.4 START使用句法分解策略回答复杂问题
总之,START的表示和技术集合 - 其三元表达式,结构转换规则,自然语言注释,句法分解策略,自然语言生成能力等等 - 为解释一系列请求和发布范围提供了一个平台。 特别是自然语言注释使START能够响应请求执行任意过程,这使START不仅可以作为问答系统,还可以作为用户请求可以导致虚拟或物理操作的接口。 接下来描述的StartMobile系统就是这样一种应用程序,其中START用于代表其用户在移动设备上执行操作。
StartMobile
在一个预示着苹果Siri等系统的引入的应用程序中,我们使用START创建了一个名为StartMobile的系统,它为移动设备提供了一个自然的语言界面(Bourzac, 2006;Katz, Borchardt, Felshin,& Mora, 2007;Katz, Mora, Borchardt, & Felshin,2011)。StartMobile允许用户对其移动设备上显示的信息提出英语请求,发出在其设备上执行操作的命令,并从其设备范围之外的广泛来源请求信息。可以使用谷歌,Inc.提供的语音识别工具以书面形式或语音方式输入请求。
StartMobile使用START系统作为处理用户请求的第一阶段。START执行请求的初始解释,如果这些请求涉及从万维网或其他来源检索一般信息,则START获取信息,以便向用户显示。如果不可能完成请求的解释,然而,或者请求涉及行为必须在执行用户的移动设备,开始编码用户请求的语言称为莫比乌斯,被设计来传达自然语言解释的请求在不同阶段之间的系统和设备。最后,驻留在用户移动设备上的软件在必要时完成用户请求的解释,并执行必要的操作来满足这些请求。
StartMobile系统支持多种型号手机上的一系列活动:
•为用户的利益检索通用信息;
•检索存储在用户移动设备上的联系人和日历信息;
•检索文本消息并管理用户的文本消息收件箱;
•从用户的移动设备拨打电话;
•在用户的移动设备或其他用户的移动设备上创建提醒;
•使用移动设备的摄像头拍照;
•修改设备设置;
•访问用户移动设备上的位置信息,并显示相关地图和方向信息;
•检索用于向移动用户演示的视频教程。
图23.5展示了StartMobile系统的运行情况,使用了输入的请求条目。(为了将StartMobile放在合适的历史背景中,作为当今商业系统的前身,本文和以下截屏显示了StartMobile在2006-2007年最初开发期间捕获的手机输出。)在图23.5所示的交互中,移动用户要求系统列出该用户在特定公司的联系人。

图23.5 StartMobile在存储在移动设备上的联系人中执行搜索。
通过使用参数化注释、结构转换规则和相关技术,START使StartMobile应用程序能够接受各种不同形式的请求。在图23.5所示的例子中,这些不同的形式有:
谁在iRobot工作?
我在iRobot认识谁?
我的哪个朋友在iRobot工作?
给我iRobot的同事看看
START用于StartMobile系统中的一般信息访问。START对一般问题的回答经过简化,以便在小屏幕上显示,然后转发到用户的移动设备上,以便向用户显示。图23.6展示了用于检索多媒体信息的StartMobile。StartMobile中的另一种机制允许用户向START服务器提交文本消息,然后也可以通过文本消息接收响应。
图23.5和23.6完整地描述了用户提交的语法请求。StartMobile还被配置为允许用户在含义清晰的一系列情况下输入零碎的话语。例如,对于图23.6所示的请求,用户可以输入“赫尔辛基地铁地图”或“地铁地图赫尔辛基”,从而显示相同的地图。
其他类型的请求涉及用户移动设备上维护的信息。要处理这些请求,START将它们与自然语言注释进行匹配;然而,本例中的注释材料是一个将指令转发到移动设备的过程。移动设备上的相关软件执行必要的操作并将结果交付给用户。图23.7描述了这样一个请求的处理,涉及到在用户的移动设备上通过日历进行搜索。
一些用户请求可能包含用户移动设备上的特定数据条目中出现的不寻常的名称——人员、街道、城市、企业等。为了使START能够正确地分析这些请求并采取适当的行动,StartMobile实现了一种机制,在该机制中提交的用户请求最初在用户的移动设备上被检查,以识别和分类出现在联系人数据库或日历等数据集中的名称。START使用此信息的方式与使用Omnibase系统作为地名词典的方式类似。对于图23.8所示的请求,这种机制使StartMobile能够正确处理名称“Boris”和“Federico”。

图23.6 StartMobile响应一般信息请求。

图23.7 StartMobile通过用户移动设备上的日历进行搜索
在另一组情况下,用户的输入不是对信息的请求,而是在用户的移动设备上执行操作的命令。这些请求的处理方式与用户移动设备上的信息请求类似,START将指令转发给在用户移动设备上执行操作的软件。图23.9展示了StartMobile如何处理使用用户移动设备上的相机拍照的请求。
在其他情况下,用户可以在一个移动设备上输入请求,以在另一个移动设备上执行操作。在这种情况下,START将把指令中继到第一个设备,然后第一个设备必须把适当的指令中继到附属设备。图23.10展示了StartMobile正在处理的此类请求的示例。
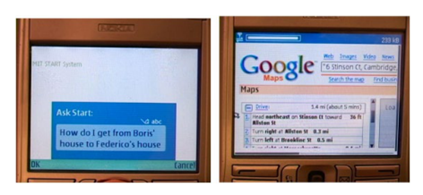
图23.8 StartMobile显示从一个位置到另一个位置的方向。

图23.9 StartMobile响应使用手机摄像头拍照的请求。
在StartMobile应用程序中,高精度非常重要。系统经常被要求执行不容易撤销的操作。另外,在某些情况下,交互性可能不如通过计算机控制台进行交互的用户所希望的那样好。最后,有限的显示空间会增加所列结果中不适当的响应带来的不便。
移动设备的自然语言接口的另一个重要问题是在这种情况下处理的分布式性质。通常情况下,自然语言请求只能在特定的、匹配的知识成分存在的情况下被完全理解。在分布式环境中,这种知识是分布式的,在某些情况下,网络设备和系统不仅需要协作以最终满足接收到的请求,还需要协作以初步理解请求,以便能够满足这些请求。

图23.10 StartMobile在附属移动设备上发布提醒。
StartMobile使用了一种基于语言的中间表示,称为Moebius(Borchardt,2014),它支持分布式解释和分布式满足自然语言请求。Moebius服务于在句法和语义解释的不同阶段对自然语言请求进行编码,以便这些请求可以在系统(例如,用户的移动设备、中央服务器和其他用户的移动设备)之间进行中继,以接收额外的解释和实现。虽然moebius专门处理不明确请求的表示和处理,但它也适用于更直接的请求,因此我们将该语言用作所有必须在系统和设备之间中继的startmobile请求的中间表示。
下面是start向用户的移动设备发出的moebius表达式的示例,描述了图23.10中所示的英语请求的基本解释版本。
alert(object:person mother(of:person “user”), with:message_string “Take your medicine at 3 pm.”, at:time “2007‐01‐29 T15:00:00”)!
moebius指定了表示元素之间的基本句法关系,并添加了语义标签,从一般到特定类别的层次结构中绘制。
Moebius的一个关键方面是它使用语言本身作为表示。在这方面,它与启动系统共享一个共同的方向。Start使用基于语言的三元表达式表示问题和自然语言注释。事实上,当start将一个问题与自然语言注释匹配时,它做了两件事:它提供了问题的答案,并承诺对该问题进行解释。Moebius可以被认为是将这一思想扩展到分布式环境中,使部分解释的请求能够由分布式环境中多个系统的集体操作来解释和实现。
作为使用moebius在不同解释阶段描述模糊请求的示例,考虑请求
Is Carl at IBM?
这个问题可以用来确定Carl是否受雇于IBM,也可以用来确定Carl目前是否实际存在于IBM设施中。我们假设人类用户按照GRICE(1975)提出的会话准则构建了请求,即通过提供足够数量的信息,但不提供太多的信息,通过诚实,仅提供相关信息,以及通过清晰或清晰来构建请求。对于人类用户,请求“Carl在IBM吗?“在上下文中可能是明确的;但是,系统可能需要额外的知识来消除请求的歧义。系统可通过与美国人类协商,参考当前处理状态下的上下文信息,通过咨询预期满足请求的组件所提供的能力清单(即,这些组件是否已知能够响应一种解释或另一种解释),获得这一知识。呃,等等。
如果最初处理请求的设备“是IBM的Carl吗?“无法访问完全解释请求所需的知识,然后,使用Moebius,该设备可以以部分解释的形式对请求进行编码:
be(subject:person “Carl”, at:object “IBM”)?
这种表示法从语法上分析请求,但是它没有承诺对“carl”和“ibm”之间的关系进行语义解释,也没有承诺对“ibm”的特定语义类别进行语义解释(“object”是最通用的语义类别)。如果此请求被中继到另一个设备或系统,该设备或系统具有消除请求歧义的必要知识,则该系统可以将该请求转换为两种更完全解释的形式之一。如果确定请求与IBM设施的物理存在有关,则可以将请求重新表示为
be(subject:person “Carl”, at:facility “IBM”)?
其中“ibm”在语义上被分类为物理“设施”。另一方面,如果确定请求与就业有关,则可以将请求重新表示为
employ(subject:organization “IBM”, object:person “Carl”)?
其中“ibm”在语义上被分类为抽象的“组织”,关系被重新表示为就业关系。随后,可根据所选解释继续进行后续处理。
在StartMobile中,当移动设备接收到请求的部分解释形式“Carl在IBM吗?”“它选择将此解释为有关就业的请求。因此,它将接收到的表达式转换为更完全解释的moebius表达式,请求为Carl提供就业信息,然后处理此moebius表达式。图23.11说明了StartMobile对请求的处理“Carl在IBM吗?”“使用记录在用户移动设备联系人数据库中的就业信息。在这种情况下,显示的输出明确通知用户StartMobile已检索到就业信息,以便澄清StartMobile对用户请求的解释。
一般来说,歧义可以从许多方面产生:抽象动词;句法歧义;省略的副词短语;模糊的介词和连词;抽象语义类别;对象描述;模糊的名称、时间和地点;回指;以及抽象形容词和副词,等等。Moebius提供了几种描述和解决这些歧义的机制。抽象动词可以用更具体的动词代替。例如,对“联系人”的请求可以重新表示为“呼叫”号码或“发送”消息的请求。抽象语义类别可以替换为更具体的类别。例如,“消息”可以替换为“电子邮件”、“文本消息”、“语音消息”等等。“地址(of:设施公寓(of:person“sandra”))和“3点钟”等描述性子表达式可替换为更具体的表达式,如“298 Beacon Street,Boston,MA 02116”和“2013-07-22 T15:00:00”,此外,可通过插入副词ph来澄清不明确的命令、语句和问题。例如,用完全不同的表达式替换原始表达式。Moebius的目标是在不同的解释阶段捕获一系列这样的歧义,我们发现,简单的自然语言,结构便于计算机处理,提供了足够的表现力来模拟许多常见的歧义。
StartMobile系统将Start定位为一个中央服务器,由一个或多个移动设备访问,这些设备偶尔会直接交互。Start执行用户请求的初始处理,然后根据需要将Moebius请求传递给其他系统和设备,以便进一步解释和/或实现。但是,StartMobile系统的总体设计也允许其他配置。

图23.11 StartMobile响应不明确的请求。
另一种选择是在每个用户的移动设备上执行自然语言请求的初始处理。然后,每个移动设备可以将Moebius请求转发给其他设备和系统,以便根据这些系统所掌握的知识进行进一步解释,或者完成移动设备外部的操作。
第三种可能是这两种方法的混合。在这种配置中,每个用户的移动设备都将包含一个轻量级的功能,用于简单的语言处理,然后根据需要将部分解释的请求甚至未解释的请求传递给其他更重要的语言处理组件。
StartMobile的一个特别重点是允许用户提出导致操作的请求:例如设置提醒、拍照或设置位置触发的警报。在StartMobile的努力之后,我们继续探索自然语言界面的构建,这些界面代表用户执行操作。特别是,我们使用Start作为名为Analyst’s Assistant的系统中的一个组件,该系统支持车辆跟踪信息数据集中显示的车辆事件的协作用户-系统解释(Borchardt等人,2014)。通过这项工作和相关工作,我们认为代表用户执行操作的自然语言接口可以从执行相关操作集合的目标支持中受益匪浅。例如,在移动电话域中,用户可能希望使用该界面拍摄照片,然后将其发送给朋友,然后在图片上附加标签并将其保存到手机的内存中。能够增强界面在支持此类交互方面的有效性的特定功能是:(a)具有强大的引用功能,用户可以使用“that picture”、“my church friends”或“mouse”等简单结构引用先前提到的数量或系统以前的响应。/触摸屏选择,以及(b)在输入和输出中为多个粒度级别的请求和描述提供支持,从粗粒度操作和返回的摘要到细粒度规范和“向下钻取”结果。
商业系统
Start和StartMobile在构建中基本上是基于规则的,这些规则是通过一定程度的人工参与和努力创建的。这使得系统能够响应相当复杂的请求,远远超出了实体描述和关系请求的范围,这些请求可以由简单的基于关键字或统计解释技术支持。这也使得这些系统的响应达到了非常高的精度。另一方面,随着网络上可用信息的爆炸式增长和移动设备内的维护,如果没有一定程度的自动构建功能,很难提供对可用源和请求类型的全面覆盖。目前的商业系统,如苹果的Siri、IBM的Watson、谷歌的“Google Now”、微软的Cortana和亚马逊的Alexa,都采用了Start和StartMobile中包含的技术,并结合基于大规模机器学习的统计解释和响应计算。这为这些系统提供了额外的覆盖范围,并增加了处理格式错误或特殊请求的能力,同时牺牲了响应产生过程中的一些精确性。
当前的商业系统可以接受书面请求、语音输入或两者兼而有之。接受书面和语音输入的系统通常以模块化方式设计,与StartMobile一样,在StartMobile中,语音输入是独立处理的,语音识别的结果将提交给系统的问答组件。
谷歌(Google,Inc.)提供的功能可以作为信息访问和问答系统建设中当前设计实践的例证。虽然这些功能通过使用统计机器学习技术将请求直接匹配到非结构化源中潜在的相关材料,提供了广泛的覆盖范围,但也有一种情况,即在不同源中发现的知识的先验结构在精神上与对象相似-属性Y——Start同伴系统Omnibase中知识的价值结构,导致对特定类型请求的更高精度回答(Dong等人,2014年)。
结论
移动电话和其他移动设备有潜力为用户提供许多有用的功能和功能,但这些设备越有能力,就越难在传统接口中使用它们。自然语言可以以非常紧凑的形式表达各种各样的请求,人类可以直观地使用这些请求。因此,自然语言接口有可能显著降低与移动设备交互的复杂性。我们认为自然语言接口构造的最新进展是实现这一目标的可喜步骤。
移动设备的自然语言接口的设计和构造仍面临许多挑战:
•需要在基于规则的处理技术(如在Start和StartMobile中产生高精度响应的技术)与大规模机器学习技术(如产生当前商业系统领域覆盖的技术)之间进一步集成。
•许多系统对涉及复杂句法结构、假设上下文和特殊用途词汇的请求的覆盖范围有限。
•在接受语音输入的情况下,语音识别和请求处理组件可以更紧密地集成,以便语音输入的解释在很大程度上受请求处理组件的功能和约束的影响。
•目前的系统很少能够解释确定其响应的方式。这样的解释将帮助用户评估系统的响应是否适合提交的请求的可能性。
•最后,支持请求的分布式处理需要额外的工作,其中多个设备和系统包含解释和满足请求所需的信息片段。
致谢
本章所述的工作部分由国防高级研究项目局、诺基亚公司和情报高级研究项目活动提供资金支持;部分由AFRL合同号FA8750-15-C-0010提供资金支持;部分由美国国家科学基金会(NSF)ST提供资金支持。C授予CCF‐1231216。作者还希望感谢Alvaro
Morales对本章的帮助。
参考
Borchardt,G. C. (2014). Moebius language reference,version 1.2 (Report MIT‐CSAILTR‐2014‐005). Cambridge, MA: MIT Computer Science and Artificial Intelligence Laboratory.
Borchardt,G., Katz, B., Nguyen, H.‐L., Felshin, S., Senne, K., & Wang, A. (2014). An analyst’s assistant for the interpretation of vehicle track data (Report MIT‐CSAILTR‐2014‐022).
Cambridge, MA: MIT Computer Science and Artificial Intelligence Laboratory.
Bourzac, K. (2006, April 27). Nokia phones go to natural language class. Communications News,MIT Technology Review. Retrieved from http://www.technologyreview.com/news/ 405713/nokia‐phones‐go‐to‐natural‐language‐class/
Dong, X.,Gabrilovich, E., Heitz, G., Horn, W., Lao, N., Murphy, K.,… Zhang, W. (2014).Knowledge Vault: A web‐scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp.601–610). New York, NY: ACM.
Grice, H. P.(1975). Logic and conversation. In P. Cole and J. L. Morgan (Eds.), Syntax and Semantics, Volume 3: Speech Acts.New York, NY: Academic Press.
Harabagiu,S. M., Maiorano, S. J., & Pasca, M. A. (2003). Open‐domain textual question
answering techniques. Natural Language Engineering, 9(3), 1–38.
Hardesty, L(2011, April 19). The brains behind Watson. MIT News Magazine, MIT Technology Review. Retrieved from http://www.technologyreview.com/article/423712/the‐brains‐ behind‐watson/
Hendrix, G.,Sacerdoti, E., Sagalowicz, D., & Slocum, J. (1978). Developing a natural language interface to complex data. ACM Transactions on Database Systems, 3(2),105–147.
Katz, B.(1980). A three‐step procedure for language generation (A.I. Memo 599). Cambridge, MA: MIT Artificial Intelligence Laboratory.
Katz, B. (1988). Using English for indexing and retrieving. In Proceedings of the 1st RIAO Conference on User‐Oriented Content‐Based Text and Image Handling (RIAO ‘88) (pp. 313–333). Paris: Centre de Hautes Etudes Internationales d’Informatique Documentaire (CID).
Katz, B.(1990). Using English for indexing and retrieving. In P. H. Winston & S. A. Shellard (Eds.), Artificial intelligence at MIT: Expanding frontiers (vol. 1, pp. 134–165).Cambridge, MA: MIT Press.
Katz, B. (1997). Annotating the World Wide Web using natural language. In Proceedings of the 5th RIAO Conference on Computer Assisted Information Searching on the Internet (RIAO ‘97) (pp.136–155). Paris: Centre de Hautes Etudes Internationales d’Informatique Documentaire (CID).
Katz, B.,Borchardt, G., & Felshin, S. (2005). Syntactic and semantic decomposition strategies for question answering from multiple resources. In Proceedings of the AAAI 2005 Workshop on Inference for Textual Question Answering (pp. 35–41). Menlo Park, CA: AAAI Press.
Katz, B., Borchardt, G., & Felshin, S. (2006). Natural language annotations for question answering. In Proceedings of the 19th International FLAIRS Conference (FLAIRS 2006) (pp. 303–306). Menlo
Park, CA: AAAI Press.
Katz, B.,Borchardt, G., Felshin, S., & Mora, F. (2007). Harnessing language in mobile environments. In Proceedings of the First IEEE International Conference on Semantic Computing (ICSC 2007) (pp. 421–428). Los Alamitos, CA: IEEE Computer Society Conference Publishing
Services.
Katz, B.,Felshin, S., Yuret, D., Ibrahim, A., Lin, J., Marton, G.,… Temelkuran, B.(2002). Omnibase: Uniform access to heterogeneous data for question answering.In Proceedings of the 7th International Workshop on Applications of Natural Language to Information Systems (NLDB 2002)
(pp. 230–234). Berlin: Springer.
Katz, B.,& Levin, B. (1988). Exploiting lexical regularities in designing natural language systems. In Proceedings of the 12th International Conference on Computational Linguistics (COLING ‘88)(pp. 316–323). Budapest: John von Neumann Society for Computing Sciences.
Katz, B.,Mora, F., Borchardt, G., & Felshin, S. (2011). StartMobile: Using language to connect people to mobile devices [Video File]. Retrieved from https://www.youtube.com/ watch v=BqOKqXaUWOw.
Levin, B. (1993). English verb classes and alternations: A preliminary investigation. Chicago, IL:
University of Chicago Press.
Morales. A. (2016). Learning to answer questions from semi‐structured knowledge sources Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA. Retrieved from
https://dspace.mit.edu/handle/1721.1/105973
Morales, A.,Premtoon, V., Avery, C., Felshin, S., & Katz, B. (2016). Learning to answer questions from Wikipedia infoboxes. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP 2016) (pp. 1930–1935), Stroudsburg, PA: Association for
Computational Linguistics.
Murdock, J. W. (2012). This is Watson. IBM Journal of Research and Development, 56(3–4).
Nyberg, E.,Burger, J., Mardis, S., & Ferrucci, D. (2004). Software architectures for advanced QA. In M. Maybury (Ed.), New directions in question answering. Cambridge, MA: MIT Press.
Waltz, D. L.(1978). An English language question answering system for a large relational database. Communications of the ACM, 21(7), 526–539.
Weischedel, R., Xu, J., & Licuanan, A. (2004). A hybrid approach to answering biographical questions. In M. Maybury (Ed.), New directions in question answering. Cambridge, MA: MIT Press.
Woods, W. A., Kaplan, R. M., & Nash‐Webber, B. L. (1972). The Lunar Sciences Natural Language Information System: Final report (Report No. 2378). Cambridge, MA: BBN Technologies.















 3264
3264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









