






Logistic Regression是解决分类问题,这里面将训练两个模型,一个是判别模型,一个是生成模型,首先,实现的是判别模型。再一次读取数据时,我们实现的判别模型。
目标:根据人们的个人资料,判断其年收入是否高于 50,000 美元
1.读取数据

X.shape[0]:x的垂直尺寸(高度)
X.shape[1]:x的水平尺寸(宽度)
X.shape[2]:X的维度
我们看一下X_train,Y_train,X_test得shape,从输出我们可以相称X_train是一个54256×510得大矩阵,Y_train是一个54256×1得列向量,这里也就是我们的targe!而X_test是我们的测试集是一个27622×510的矩阵,我们需要用train的数据来训练好我们的分类器,然后去预测test里面的targe!
Y_train里面都是1,0,0,1…这样的数据,1是高于 50,000 美元,0是不高于 50,000 美元

2.正则化
reshape()函数的常见的用法

np.mean(data, axis=0)
axis=0,那么输出矩阵是1行,求每一列的平均(按照每一行去求平均);axis=1,输出矩阵是1列,求每一行的平均(按照每一列去求平均)。还可以这么理解,axis是几,那就表明哪一维度被压缩成1。

此函数用于规范特定列X
在处理测试数据时,训练数据的均值和标准方差将被重用
参数:
X:待处理数据
train:处理训练数据时为“True”,测试数据为“False”
特定列:将规范化的列的索引。如果“无”,则所有列将被规范化。
X_mean:训练数据的平均值,当train='False’时使用
X_std:训练数据的标准偏差,当train='False’时使用
输出:
X:标准化数据
X_mean:训练数据的计算平均值
X_std:训练数据的计算标准差
3.把数据分成训练集和测试集

调用以上两个函数,首先先将数据正则化((x-均值)/标准差+1e-8)),为了防止标准差为0,加一个1e-8代表110^(-8),然后将正则化后的数据分割:
X_train=X_train0.9
Y_train=Y_train0.9
X_dev=X_train0.1
Y_dev=Y_train*0.1

4.返回随机序列,功能类似洗牌
5.sigmod函数
np.clip()函数:限制一个array的上下界
给定一个范围[min, max],数组中值不在这个范围内的,会被限定为这个范围的边界。如给定范围[0, 1],数组中元素值小于0的,值会变为0,数组中元素值大于1的,要被更改为1.
参数
numpy.clip(a, a_min, a_max, out=None)
a : array
a_min : 要限定范围的最小值
a_max : 要限定范围的最大值
out : 要输出的array,默认值为None,也可以是原array

6.逻辑回归函数,参数是w和b
参数:
X: input data, shape = [batch_size, data_dimension]
w: weight vector, shape = [data_dimension, ]
b: bias, scalar
输出:
predicted probability of each row of X being positively labeled,
shape = [batch_size, ]

扩充:numpy.matmul
原型: numpy.matmul(a, b, out=None)
两个numpy数组的矩阵相乘
(1). 如果两个参数a , b a,ba,b都是2 22维的,做普通的矩阵相乘。

(2). 如果某一个参数是N ( N > 2 )维的,该参数被理解为一些矩阵(参数的最后两个维数为矩阵维数)的stack,而且计算时会相应的广播

首先,对于a,它会被理解成两个2 × 4 的矩阵的stack

同样对于b,它会被理解成两个4 × 2的矩阵的stack

那么np.matmul(a,b)则会将a 的第一个矩阵和b的第一个矩阵相乘,将a 的第二个矩阵b的第二个矩阵相乘,最终得到一个2 × 2 × 2 的结果。
同理,同样对于c,它会被理解成一个4 × 2 的矩阵的stack,对于np.matmul(a,c),则会广播c的一个矩阵,将a的第一个矩阵和第二个矩阵分别与c的一个矩阵相乘最终得到一个2 × 2 × 2 的结果。
7.预测函数
此函数返回X的每一行的真值预测,并对logistic回归函数的结果进行四舍五入。
np.round() 四舍五入
astype:转换数组的数据类型

8.精度函数
此函数用于计算预测精度

9.交叉熵-损失函数


10.梯度函数
该函数计算交叉熵损失相对于权重w和偏差b的梯度。

11.名词小结
epoch(时期):
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次>epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )
再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。
然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。
Batch(批 / 一批样本):将整个训练样本分成若干个Batch。
Batch_Size(批大小):每批样本的大小。
Iteration(一次迭代):训练一个Batch就是一次Iteration(这个概念跟程序语言中的迭代器相似)。
12.训练
我们使用小批次梯度下降法来训练。训练资料被分为许多小批次,针对每一个小批次,我们分别计算其梯度以及损失,并根据该批次来更新模型的参数。当一次迴圈完成,也就是整个训练集的所有小批次都被使用过一次以后,我们将所有训练资料打散并且重新分成新的小批次,进行下一个for,直到事先设定的for数量到此为止。
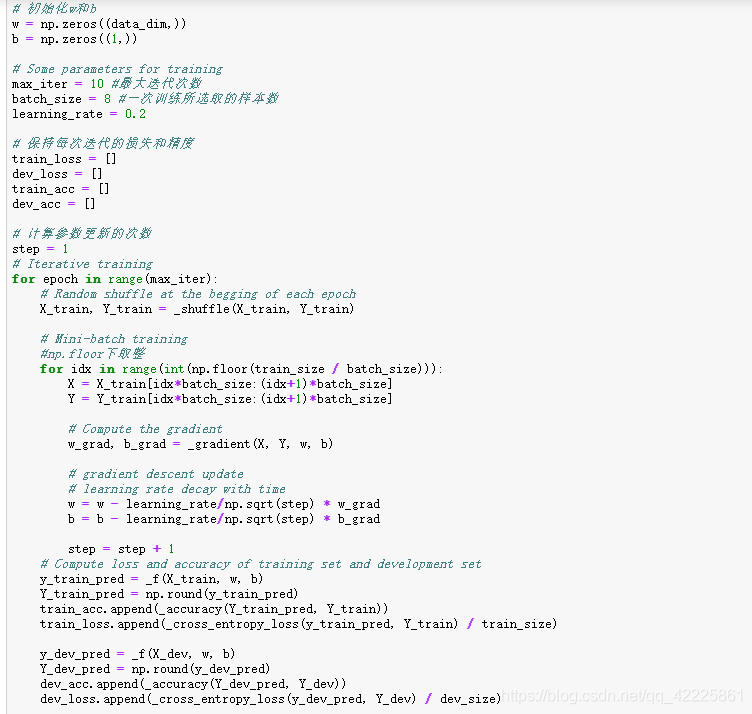
13.画图



14.预测测试集的target并且保存在 output_logistic.csv 中

12.sum(axis)相关用法
https://www.cnblogs.com/SupremeBoy/p/12955652.html
13.format 格式化函数
format 函数可以接受不限个参数,位置可以不按顺序
设置参数

也可以向 str.format() 传入对象:

数字格式化

14.enumerate() 函数
enumerate(sequence, [start=0])
sequence – 一个序列、迭代器或其他支持迭代对象。
start – 下标起始位置。


15.生成模型,首先也是要读取数据

16.接下来,我们主要是将训练的数据,按着类别进行划分,lable是1的为一类,lable是0的为一类,然后,我们分别求每一类的均值,和方差。

17.我们对cov做一个SVD,计算inv,目的是为了计算w和b,公式在下边。


18.预测testing labels并且保存在 output_generative.csv 中。















 2479
2479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









