






一、分类指标评价
1.几个常用的术语
这里首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negtive)分别是:
1)True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
2)False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
4)True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。

2、评价指标
1)正确率(accuracy)
正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),这个很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好;
2)错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate;
3)灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力;
4)特效度(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力;
5)精度(precision)
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP);
6)召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
7) F1-score
由于Precision和Recall是一对不可调和的矛盾,很难同时提高二者,也很难综合评价。故提出F1来试图综合二者,F1是P和R的调和平均(harmonic mean):

3.ROC
在进一步了解ROC之前,首先定义两个指标:
1)真正例(True Positive Rate,TPR),表示所有正例中,预测为正例的比例:
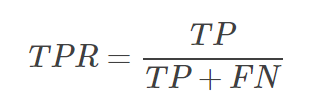
2)假正例(False Positive Rate,FPR),表示所有负例中,预测为正例的比例:

以FPR为横坐标,TPR为纵坐标,那么ROC曲线就是改变各种阈值后得到的所有坐标点 (FPR,TPR) 的连线,画出来如下。红线是随机乱猜情况下的ROC,曲线越靠左上角,分类器越佳。

4.AUC
1)AUC(Area Under Curve)就是ROC曲线下的面积。
2)AUC的计算有两种方式,梯形法和ROC AUCH法,都是以逼近法求近似值。
3)AUC的含义:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率,就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
4)用AUC判断分类器(预测模型)优劣的标准:
AUC = 1 是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
简单说:AUC值越大的分类器,正确率越高。
5.用python的sklearn:绘制ROC曲线+求AUC
sklearn.metrics.roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True)
输入:其中y_true为真实标签,y_score为预测概率,或称为置信度。pos_label为正类样本标签。
输出:fpr(假正率、1-特效性)、tpr(真正率、灵敏度)、thresholds(阈值)
假正率 = 预测为正类的负样本/所有负类样本,越小越好。
真正率 = 预测为正类的正样本/所有正类样本,越大越好。
#ROC
import numpy as np
from sklearn.metrics import roc_curve, auc
y = np.array([1, 1, 1, 1, 1,
2, 2, 2, 2, 2])
y_proba = np.array([0.1, 0.4, 0.4, 0.3, 0.5,
0.4, 0.6, 0.7, 0.8, 0.5]) # probability of prediction as positive
fpr, tpr, thresholds = roc_curve(y, y_proba, pos_label=2)
auc = auc(fpr, tpr)
print(fpr)
print(tpr)
print(auc)
## AUC
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print('AUC socre:',roc_auc_score(y_true, y_scores))
二、回归评价指标
1.均方误差(MSE):

2.均方根误差(RMSE)

3.MAE(平均绝对误差)

范围[0,+∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
4.MAPE:平均绝对百分比误差
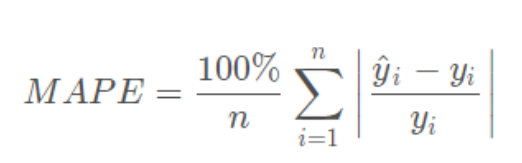
范围[0,+∞),MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。MAPE 的值越小,说明预测模型拥有更好的精确度.
5.R2(R-Square)决定系数
其中,分子部分表示真实值与预测值的平方差之和,类似于均方差 MSE;分母部分表示真实值与均值的平方差之和,类似于方差 Var。
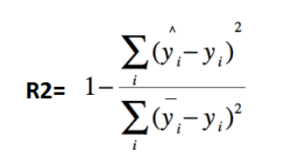
根据 R-Squared 的取值,来判断模型的好坏,其取值范围为[0,1]:
如果结果是 0,说明模型拟合效果很差;
如果结果是 1,说明模型无错误。
一般来说,R-Squared 越大,表示模型拟合效果越好。
6.Python代码实现
# coding=utf-8
import numpy as np
from sklearn import metrics
# MAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true))
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, -2.2])
# MSE
print('MSE:',metrics.mean_squared_error(y_true, y_pred))
# RMSE
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_true, y_pred)))
# MAE
print('MAE:',metrics.mean_absolute_error(y_true, y_pred))
# MAPE
print('MAPE:',mape(y_true, y_pred))
## R2-score
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print('R2-score:',r2_score(y_true, y_pred))















 802
802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









