







1. 【字符串首字母转换为大写】capitalize()方法
语法参考
capitalize()方法用于将字符串的首字母转换为大写,其他字母为小写。capitalize()方法的语法格式如下:
str.capitalize()
锦囊1 将字符串的首字母转换为大写
将字符串“hello word!”的首字母转换为大写,代码如下:
str1 = 'hello word!'
print (str1.capitalize())
锦囊2 字符串全是大写字母只保留首字母大写
字符串全是大写字母的情况下,只保留首字母大写,需要先将大写字母转换为小写字母,然后将首字母大写,代码如下:
cn = '没什么是你能做却办不到的事。'
en = "THERE'S NOTHING YOU CAN DO THAT CAN'T BE DONE."
print(cn)
print('原字符串:',en)
#字符串转换为小写后首字母大写
print('转换后:',en.lower().capitalize())
锦囊3 对指定位置字符串的首字母大写
下面实现对指定位置字符串的首字母大写,先对字符串截取,然后使用capitalize()方法将该字符串首字母转换为大写,之后再进行字符串拼接,代码如下:
cn = '没什么是你能做却办不到的事。'
en = "There's nothing you can do that can't be done."
print(cn)
print('原字符串:',en)
#对指定位置字符串转换为首字母大写
print(en[0:16]+en[16:].capitalize())
2. 【所有大写字符转换为小写】casefold()方法
语法参考
casefold()方法是Python3.3版本之后引入的,其效果和lower()方法非常相似,都可以转换字符串中所有大写字符为小写。
两者的区别是:lower()方法只对ASCII编码,也就是‘A-Z’有效,而casefold()方法对所有大写(包括非中英文的其他语言)都可以转换为小写。casefold()方法的语法格式如下:
str.casefold()
锦囊1 将字符串中的大写字母转换为小写
下面使用casefold()方法对输入的大写字母进行转换,代码如下:
while 1: # 循环输入
str1=input('请输入英文:')
print(str1.casefold())
锦囊2 对非中英文的其他语言字符串中的大写转换为小写
例如,德语中的“ß”分别使用lower()方法和casefold()方法转换为小写,代码如下:
a = 'ß Fußball' #德语
print(a.lower())
print(a.casefold())
运行程序,输出结果为:
ß fußball
ss fussball
从以上结果看:lower()方法没有进行转换,而casefold()方法将“ß”转换为小写字母“ss”。因此,在对非中英文的其他语言字符串中的大写转换为小写时,应使用casefold()方法。
锦囊3 判断小写字母在所在字符串中出现的次数
首先将字符串中的英文字母转换为小写,然后进行统计,代码如下:
import string
# 26个小写英文字母
chars = string. ascii_lowercase
print('26个小写英文字母:',chars)
str = 'WWW.888.COM 888.Com mrbccd.Com'
print('原字符串:',str)
str = str.casefold()
c = {}.fromkeys(chars,0)
# 统计小写字母出现的次数
for char in str:
if char in c:
c[char] += 1
print(c)
3. 【字符串居中填充】center()方法
语法参考
字符串对象的center()方法用于将字符串填充至指定长度,并将原字符串居中输出。center()方法的语法格式如下:
str.center(width[,fillchar])
-
width参数表示要扩充的长度,即新字符串的总长度。
-
fillchar参数表示要填充的字符,如果不指定该参数,则使用空格字符来填充。
锦囊1 填充指定的字符串
以各种方式填充“涛哥很帅”,代码如下:
print('涛哥很帅'.center(10)) # 长度为10,不指定填充字符,前后各填充3个空格
print('涛哥很帅'.center(6,'-')) # 长度为6,指定填充字符,前后各填充一个'-'字符
print('涛哥很帅'.center(5,'-')) # 长度为5,只在字符串前填充一个'-'字符
print('涛哥很帅'.center(12,'-')) # 长度为12,字符串前后各填充4个'-'字符
print('涛哥很帅'.center(3,'-')) # 长度为3,不足原字符串长度,输出原字符串
锦囊2 文本按照顺序显示并且居中对齐
下面输出《中国诗词大会》中的经典诗词《锦瑟》,代码如下。
str1 = ['锦瑟',
'李商隐',
'锦瑟无端五十弦',
'一弦一柱思华年',
'庄生晓梦迷蝴蝶',
'望帝春心托杜鹃',
'沧海月明珠有泪',
'蓝田日暖玉生烟',
'此情可待成追忆',
'只是当时已惘然']
for str1_s in str1:
print('||%s||' % str1_s.center(11,' '))
4. 【统计字符串出现次数】count()方法
语法参考
count()方法用于统计字符串中某个字符出现的次数,如起始位置从11到结束位置17之间字符出现的次数。(这里要注意一点,结束位置为17,但是统计字符个数时不包含17这个位置上的字符)

count()方法的语法格式如下:
str.count(sub,start,end)
参数说明:
-
str:表示原字符串。
-
sub:表示要检索的子字符串。
-
start:可选参数,表示检索范围的起始位置的索引,默认为第一个字符,索引值为0,可单独指定。
-
end:可选参数,表示检索范围的结束位置的索引,默认为字符串的最后一个位置,不可以单独指定。
锦囊1 获取关键词“运动”在字符串中出现的次数
下面来看下一段讲话中提到多少次“运动”,代码如下:
str1='运动 123456789oplkjhgfdc'
print('这句话中"运动"共出现:',str1.count('运动'),'次')
锦囊2 统计关键词在字符串中不同位置处出现的次数
下面使用count()方法统计字母“o”在字符串不同位置处出现的次数,代码如下:
cn = '没什么是你能做却办不到的事。'
en = "There's nothing you can do that can't be done."
print(cn)
print('原字符串:',en)
# 字母“o”在不同位置处出现的次数
print(en.count('o', 0, 17))
print(en.count('o', 0, 27))
print(en.count('o', 0, 47))
锦囊3 统计任意输入内容中每个字符出现的次数
下面实现对用户输入的任意内容进行统计,统计其中每个字符出现的次数,代码如下:
chars=input('请输入字符串:')
#将输入的字符串创建一个新字典
c = {}.fromkeys(chars,0)
for keys,values in c.items():
count=chars.count(keys)
print('字符:',keys,'出现:',count,'次')
锦囊4 统计字符串中的标点符号
首先通过string模块的punctuation常量获取所有标点符号,然后判断字典中每个字符是否为标点符号,如果是标点符号则使用count()方法进行统计,最后汇总,代码如下:
import string
count=0
chars=input('请输入字符串:')
# 将输入的字符串创建一个新字典
c = {}.fromkeys(chars,0)
for keys,values in c.items():
if keys in string.punctuation: # 统计标点符号
count=chars.count(keys)+count
print('字符串中包含:',count,'个标点符号')
锦囊5 统计文本中数字出现的个数
首先通过string模块的digits常量获取所有数字,然后判断字典中每个字符是否为数字,如果是数字则使用count()方法进行统计,最后汇总,代码如下:
import string
f = open('./tmp/digits.txt', 'r')
chars=f.read()
count=0
# 将输入的字符串创建一个新字典
c = {}.fromkeys(chars,0)
for keys,values in c.items():
if keys in string.digits: # 统计数字
count=chars.count(keys)+count
print('文本中包含:',count,'个数字')
5. 【解码字符串】decode()方法
语法参考
解码是将字节流转换成字符串(文本),其他编码格式转成unicode。在Python中提供了decode()方法,该方法的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码。decode()方法的语法格式如下:
bytes.decode([encoding="utf-8"][,errors="strict"])
参数说明:
-
bytes:表示要进行转换的字节数据,通常是encode()方法转换的结果。
-
encoding=“utf-8”:可选参数,用于指定进行解码时采用的字符编码,默认为utf-8,如果想使用简体中文可以设置为gbk或gb2312(与网站使用的编码方式有关)。当只有一个参数时,可省略前面的“encoding=”,直接写编码。
注意:在设置解码采用的字符编码时,需要与编码时采用的字符编码一致,如果不一致程序会出现错误提示,此时可以更换编码方式。
- errors=“strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或xmlcharrefreplace(使用XML的字符引用)等,默认值为strict。
锦囊1 对指定的字符串进行解码
对指定的字符串进行解码,代码如下:
# 定义字节编码
Bytes1=bytes(b'\xe6\x88\x91\xe7\x88\xb1Python')
# 定义字节编码
Bytes2=bytes(b'\xce\xd2\xb0\xaePython')
str1=Bytes1.decode("utf-8") # 进行utf-8解码
str2=Bytes2.decode("gbk") # 进行gbk解码
print(str1) # 输出utf-8解码后的内容
print(str2) # 输出gbk解码后的内容
锦囊2 操作不同编码格式的文件
建立一个文件test5.txt,文件格式为ANSI,内容如下:
机器码:NH57Q35XD5MZVI7ZWL7H2UX0I
用户名称:MZRCE44HHKBQ
用Python来读取,代码如下:
# coding=gbk
# 用python来读取
print(open('./tmp/test5.txt').read())
运行程序,输出结果为:
机器码:NH57Q35XD5MZVI7ZWL7H2UX0I
用户名称:MZRCE44HHKBQ
将test5.txt另存为test51.txt,并将编码格式改为utf-8,再使用Python读取test51.txt,代码如下:
# 用python读取uft-8编码格式的文本文件
f=open('./tmp/test51.txt','rb')
s=f.read()
f.close()
print(s)
运行程序,输出结果为:
b'\xef\xbb\xbf\xe6\x9c\xba\xe5\x99\xa8\xe7\xa0\x81\xef\xbc\x9aNH57Q35XD5MZVI7ZWL7H2UX0I\r\n\xe7\x94\xa8\xe6\x88\xb7\xe5\x90\x8d\xe7\xa7\xb0:MZRCE44HHKBQ \r\n'
此时出现了乱码,这是由于字符经过不同编码解码再编码的过程中使用的编码格式不一致导致的。那么,接下来我们使用decode()方法进行解码,代码如下:
print(s.decode('utf-8')) # 使用decode()方法解码并输出
运行程序,输出结果为:
机器码:NH57Q35XD5MZVI7ZWL7H2UX0I
用户名称: MZRCE44HHKBQ
锦囊3 解码爬虫获取的字节形式代码
在使用python爬取指定的网页时,获取的内容中,如果汉字都是字节码的情况下,可以通过decode()方法实现html代码的解码工作。代码如下:
import requests # 网络请求模块
# 对爬取目标发送网络请求
response = requests.get('https://www.baidu.com/')
html_bytes = response.content # 获取爬取的内容,该内容为字节形式
print(html_bytes) # 打印字节形式的html代码
print(html_bytes.decode('utf-8')) # 打印解码后的html代码
运行程序,输出结果中字节形式
<title>\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b\xef\xbc\x8c\xe4\xbd\xa0\xe5\xb0\xb1\xe7\x9f\xa5\xe9\x81\x93</title>
输出结果中解码后
<title>百度一下,你就知道</title>
6.【编码字符串】encode()方法
语法参考
编码是将文本(字符串)转换成字节流,Unicode格式转换成其他编码格式。在Python中提供了encode()方法,该方法的作用是将Unicode编码转换成其他编码的字符串。
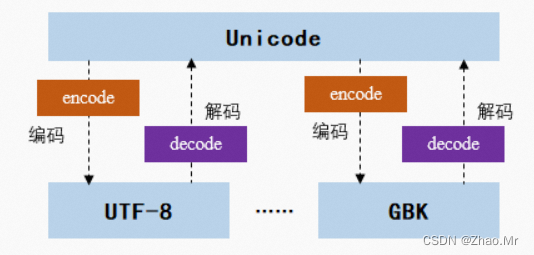
encode()方法的语法格式如下:
str.encode([encoding="utf-8"][,errors="strict"])
参数说明:
-
str:表示要进行转换的字符串。
-
encoding=“utf-8”:可选参数,用于指定进行转码时采用的编码,默认为utf-8,如果是简体中文,可以设置为gb2312或gbk(与网站使用的编码方式有关)。当只有一个参数时,可以省略前面的“encoding=”,直接写编码。
-
errors=“strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或xmlcharrefreplace(使用XML的字符引用)等,默认值为strict。
说明:在使用encode()方法时,不会修改原字符串,如果需要修改原字符串,需要对其进行重新赋值。
锦囊1 将指定字符串转为不同的编码格式
str='我爱Python' # 定义字符串
utf8Str=str.encode(encoding='utf-8') # 采用utf-8编码
gbkStr=str.encode(encoding='gbk') # 采用GBK编码
print(utf8Str) # 输出utf-8编码内容
print(gbkStr) # 输出GBK编码内容
锦囊2 Python中URL链接的编码处理
最近在豆瓣电影搜索《千与千寻》的时候发现搜素链接是这样的:
https://movie.douban.com/subject_search?search_text=%E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB&cat=1002
很明显“千与千寻”被编码成了%E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB,那么在Python中如何处理这种链接呢?
测试下上述链接中URL编码是否为“千与千寻”,首先使用encode()方法将“千与千寻”的编码格式设置为utf-8,然后使用urllib模块的quote函数将转码后的字符串设置为URL编码,代码如下:
from urllib.parse import quote
from urllib.parse import unquote
# 编码测试
mystr1 = '千与千寻'.encode('utf-8')
# 使用urllib模块quote函数进行编码
mystr2 = quote(mystr1)
print(mystr2)
# 使用urllib模块unquote函数进行解码
print(unquote(mystr2))
锦囊3 将字节类型的HTML代码写入文件
如果需要将字节类型的HTML代码写入文件时,首先需要设置open()函数中的“w”写入模式,然后再通过decode()方法对字节类型的字符串进行解码,最后再写入文件中。代码如下:
# 字节类型的html代码
html_bytes =bytes(b'<html>'
b'<head>'
b'<title>Python\xe7\xbc\x96\xe7\xa8\x8b\xe8\xaf\xad\xe8\xa8\x80</title>'
b'</head>'
b'<body>'
b'<p>\xe4\xba\xba\xe7\x94\x9f\xe8\x8b\xa6\xe7\x9f\xad\xef\xbc\x8c\xe6\x88\x91\xe7\x94\xa8Python</p>'
b'</body>'
b'</html>')
# 以“w”模式进行写入
with open('html_bytes' + ".html", "w") as f:
# 将字节类型的html代码解码后写入文件中
f.write(html_bytes.decode('utf-8'))
7. 【是否以指定子字符串结尾】endswith()方法
语法参考
endswith()方法用于检索字符串是否以指定子字符串结尾。如果是则返回True,否则返回False。endswith()方法的语法格式如下:
str.endswith(suffix[, start[, end]])
参数说明:
-
str:表示原字符串。
-
suffix:表示要检索的子字符串。
-
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
-
end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
锦囊1 检索网址是否以“.com”结尾
定义一个字符串,然后使用endswith()方法检索该字符串是否以“.com”结尾,代码如下:
str1 = 'http://www.mingrisoft.com'
print(str1.endswith('.com'))
锦囊2 筛选目录下所有以.txt结尾的文件
在开发项目过程中,经常会用到python判断一个字符串是否以某个字符串结尾,例如,筛选目录下所有以.txt结尾的文件,代码如下:
import os
file_list = os.listdir('./tmp')
for item in file_list:
if item.endswith('.txt'):
print(item)
8. 【tab符号转为空格】expandtabs()方法
语法参考
expandtabs()方法把字符串中的tab(‘\t’)符号转为空格,tab(‘\t’)符号默认的空格数是8。该方法返回字符串中的tab符号(‘\t’)转为空格后生成的新字符串。expandtabs()方法的语法格式如下:
str.expandtabs(tabsize=8)
tabsize:指定转换字符串中的tab符号(‘\t’)转为空格的字符数。
锦囊1 将Excel中复制文本中附带的tab符号替换为空格
我们知道从Excel表格中复制出来的内容一般都会带tab(‘\t’)符号,如图1所示的样式。下面使用expandtabs()方法将文本中的tab(‘\t’)符号替换为空格。
file1 = open('./tmp/book1.txt', 'r')
for str1 in file1.readlines():
print(str1.expandtabs(5), end='')
file1.close()
锦囊2 为文本定义不同大小的间距
下面使用expandtabs()方法为字符串定义不同的间距,代码如下:
str = "吉林省\t长春市\t二道区"
# 使用默认间距修改字符串
print(str.expandtabs())
print("\r")
# 定义间距,插入空格
print(str.expandtabs(2))
print("\r")
print(str.expandtabs(12))
print("\r")
运行程序,输出结果为:
吉林省 长春市 二道区
吉林省 长春市 二道区
吉林省 长春市 二道区
9. 【字符串首次出现的索引位置】find()方法
语法参考
find()方法实现查询一个字符串在其本身字符串对象中首次出现的索引位置,如起始位置从11到结束位置17之间子字符串出现的位置。如果没有检索到该字符串,则返回 -1。

find()方法的语法格式如下:
str.find(sub,start,end)
参数说明:
- str:表示原字符串。
- sub:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
- end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
锦囊1 检索邮箱地址中“@”首次出现中的位置
定义一个字符串,然后应用find()方法检索邮箱地址中首次出现“@”符号的位置索引,代码如下:
str1 = '790129881@qq.com'
print('@首次出现的位置为:',str1.find('@'))
说明:Python的字符串对象还提供了rfind()方法,其作用与find()方法类似,只是从字符串右边开始查找。
锦囊2 提取括号内数据
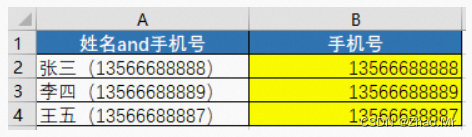
str1 = '张三(13566688888)'
l1=str1.find('(')
l2=str1.find(')')
print(str1[l1+1:l2])
锦囊3 从邮箱地址提取ID并将首字母大写
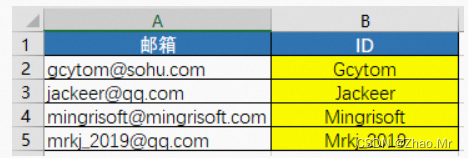
file1 = open('./tmp/email.txt', 'r')
for value1 in file1.readlines():
l=value1.find('@')
print(value1[0:l].capitalize())
file1.close()
10. 【格式化字符串】format()方法
语法介绍
https://blog.csdn.net/qq_42226855/article/details/130059915
锦囊1 格式化字符
格式化字符主要包括截取字符串,字符串对齐方式显示,填充字符串等几个方面,下面举例如下:
print(format('PYTHON','M^20.3')) # 截取3个字符,宽度为20居中,不足用‘M’填充
print(format("PYTHON",'10')) # 默认居左显示,不足部分用‘ ’填充
print(format('mingrisoft.com','.3')) # 截取3个字符,默认居左显示
print(format("PYTHON",'>10')) # 居右显示,不足部分用‘ ’填充
s='mingrisoft.com'
print(format(s,'0>20')) # 右对齐,不足指定宽度部分用0号填充
print(format(s,'>4')) # 右对齐,因字符实际宽度大于指定宽度4,不用填充
print(format(s,'*>20')) # 右对齐,不足指定宽度部分用*号填充
print(format(s,'>020')) # 右对齐,指定0标志位填充
print(format(s,'>20')) # 右对齐,没指定填充值,用默认值空格填充
print(format(s,'+^30')) # 居中对齐,用+号填充不足部分
11. 【格式化字符串】f-string
语法参考
f-string是格式化字符串的常量,它是Python3.6新引入的一种字符串格式化方法,主要目的是使格式化字符串的操作更加简便。f-string在形式上是以f或F字母开头的字符串,然后通过一对单引号将要拼接的变量按顺序排列在一起,每个变量名称都需要使用一对花括号括起来。
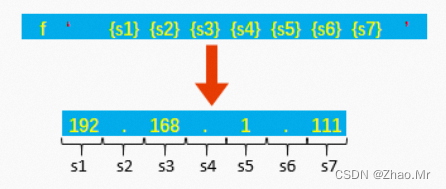
sval=f '{s1}{s2}{s3}……'
f-string功能非常强大,而且使用起来也简单方便,因此Python3.6以上版本推荐使用f-string进行字符串格式化。
锦囊1 连接指定字符串
连接指定的字符串,代码如下:
s1 = '爵士'
s2 = ' vs '
s3 = '马刺'
newstring = f'{s1}{s2}{s3}'
print(newstring)
锦囊2 替换指定内容
f-string用花括号{}表示被替换字段,其中直接填入替换内容即可,代码如下:
name = '零基础学Python'
print(f'您购买的商品是:{name}')
number = 201906140008
print(f'您的会员ID是:{number}')
price = 79.8
print(f'您消费的金额是:{price}')
锦囊3 表达式求值与函数调用
f-string的大括号{}内还可以填入表达式或调用函数,Python会求出其结果并填入返回的字符串内,例如下面的代码。
print(f'结果为: {1024 * 7688 + 8}')
name = 'MRSOFT'
print(f'转换为小写:{name.lower()}')
print(f'结果为: {(2 + 5j) / (2 - 2j)}')
锦囊4 将数字格式化为二进制、八进制、十进制和十六进制
使用f-string可以实现将数字格式化为不同的进制数,省去了进制转换的麻烦,具体介绍如下:
- b:二进制整数格式
- d:十进制整数格式
- o:八进制整数格式
- x:十六进制整数格式(小写字母)
- X:十六进制整数格式(大写字母)
例如,将12345分别格式化为二进制、十进制、八进制和十六进制,代码如下:
a = 12345
print(f'二进制:{a:^#10b}') # 居中,宽度10位,二进制整数,显示前缀0b
print(f'十进制:{a:^#10d}') # 十进制整数
print(f'八进制:{a:^#10o}') # 八进制整数,显示前缀0o
print(f'十六进制:{a:^#10X}') # 十六进制整数(大写字母),显示前缀0X
锦囊5 字符串左对齐、右对齐和居中
f-string支持三种对齐方式:
-
<:左对齐(字符串默认对齐方式);
-
>:右对齐(数值默认对齐方式);
-
^:居中。
下面以以左对齐、右对齐和居中输出“吉林省明日科技有限公司”,固定宽度18位,代码如下:
a = '吉林省666科技有限公司'
print(f'左对齐:{a:<18}')#左对齐
print(f'右对齐:{a:>18}')#右对齐
print(f'居中对齐:{a:^18}')#居中对齐
锦囊6 为数字添加千位分隔符
val1=123456.78
print(f'{val1:,}') # 浮点数使用,作为千位分隔符
val2= 12345678
print(f'{val2:015,d}') # 高位补零,宽度15位,十进制整数,使用,作为千位分隔符
val3 = 0.5 + 2.5j
print(f'{val3:30.3e}') # 宽度30位,科学计数法,3位小数
val4= 12345678988
print(f'{val4:_o}') # 八进制整数,使用_作为千位分隔符
锦囊7 在f-string大括号内填入lambda表达式
f-string大括号内也可填入lambda表达式,但lambda表达式的冒号(:)会被f-string误认为是表达式与格式描述符之间的分隔符,为避免歧义,需要将lambda表达式置于括号()内,例如下面的代码:
print(f'结果为:{(lambda x: x ** 8 + 1)(8)}')
print(f'结果为:{(lambda x: x ** 8 + 1) (2):<+8.1f}')
锦囊8 将系统日期格式化为短日期
f-string可以对日期进行格式化,如格式化成类似系统中的短日期、长日期等,其适用于date、datetime和time对象,相关介绍如下:
-
%d:表示日,是数字,以0补足两位;
-
%b:表示月(缩写);
-
%B:表示月(全名);
-
%m:表示月(数字,以0补足两位)
-
%y:年(后两位数字,以0补足两位)
-
%Y:年(完整数字,不补零)
下面输出当前系统日期并将其格式化为短日期格式,代码如下:
import datetime
e = datetime.datetime.today() # 获取当期系统日期
print('当前系统日期:',e)
print(f'短日期格式:{e:%Y/%m/%d}') # 短日期格式
print(f'短日期格式:{e:%Y-%m-%d}')
print(f'短日期格式:{e:%y-%b-%d}')
print(f'短日期格式:{e:%y-%B-%d}')
锦囊9 将系统日期格式化为长日期
下面使用f-string将当前系统日期格式化为长日期格式,代码如下:
import datetime
e = datetime.datetime.today()
print('当前系统日期:',e) # 当期系统日期
print(f'长日期格式:{e:%Y年%m月%d日}') # 长日期格式
锦囊10 根据系统日期返回星期几
f-string可以根据系统日期返回星期(数字),相关介绍如下:
- %a:星期几(缩写),如’Sun’;
- %A:星期几(全名),如’Sunday’;
- %w:星期几(数字,0是星期日、6是星期六),如’0’
- %u:星期几(数字,1是星期一、7是星期日),如’7’
下面使用f-string中的%w返回当前系统日期的星期。由于返回的星期是数字,还需要通过自定义函数进行转换,0表示星期日,依次排列直到星期六,代码如下:
import datetime
e=datetime.datetime.today() # 获取当前系统日期
# 定义数字星期返回星期几的函数
def get_week(date):
week_dict = {
0 : '星期日',
1 : '星期一',
2 : '星期二',
3 : '星期三',
4 : '星期四',
5 : '星期五',
6 : '星期六',
}
day = int(f'{e:%w}') # 根据系统日期返回数字星期并转换为整型
return week_dict[day]
print(f'今天是:{e:%Y年%m月%d日}')#长日期格式
print(get_week(datetime.datetime.today())) # 调用函数返回星期几
锦囊11 判断当前系统日期是今年的第几天第几周
f-string可以根据当前系统日期返回一年中的第几天和第几周,相关介绍如下:
-
%j:一年中的第几天(以0补足三位),如2019年1月1日返回’001’;
-
%U:一年中的第几周(以全年首个周日后的星期为第0周,以0补足两位,如’00’),如’30’;
-
%W:一年中的第几周(以全年首个周一后的星期为第0周,以0补足两位,如’00’),如’30’;
-
%V:一年中的第几周(以全年首个星期为第1周,以0补足两位,如’01’),如’31’。
下面分别使用f-string中的%j返回当前系统日期是一年中的第几天、使用%U、%W和%V返回当前系统日期是一年中的第几周,代码如下:
import datetime
e = datetime.datetime.today() # 获取当前系统日期
print(f'今天是:2019年的第{e:%j}天') # 返回一年中的第几天
print(f'今天是:2019年的第{e:%U}周') # 返回一年中的第几周
print(f'今天是:2019年的第{e:%W}周')
print(f'今天是:2019年的第{e:%V}周')
锦囊12 根据当前系统日期返回时间
f-string可以根据当前系统日期返回时间,相关介绍如下:
-
%H:小时(24小时制,以0补足两位),如’14’
-
%I:小时(12小时制,以0补足两位),如’02’
-
%p:上午/下午,如上午为’AM’,下午为’PM’
-
%M:分钟(以0补足两位),如’48’
-
%S:秒(以0补足两位),如’48’
-
%f:微秒(以0补足六位),如’734095’
下面根据当前系统日期返回时间,代码如下:
import datetime
e = datetime.datetime.today()
print(f'今天是:{e:%Y年%m月%d日}') # 长日期格式
print(f'时间是:{e:%H:%M:%S}') # 返回当前时间
print(f'时间是:{e:%H时%M分%S秒 %f微秒}') # 返回当前时间到微秒(24小时制)
print(f'时间是:{e:%p%I时%M分%S秒 %f微秒}') # 返回当前时间到微秒(12小时制)
12. 【字符串首次出现的索引位置】index()方法
语法参考
index()方法用于查询一个字符串在其本身字符串对象中首次出现的索引位置。它与find()方法功能相同,区别在于当find()方法没有检索到字符串时会返回-1,而index()方法会抛出ValueError异常。index()方法的语法格式如下:
str.index(sub,start,end)
参数说明:
- str:表示原字符串。
- sub:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
- end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
锦囊1 使用index()方法检索指定字符串出现的位置
定义一个字符串,然后使用index()方法检索该字符串中首次出现“@”符号的位置索引,代码如下:
str1 = '790129881@qq.com'
print('@符号首次出现的位置为:',str1.index('@'))
锦囊2 查询字符串中指定字符的全部索引
Python中字符串只提供了index()方法来获取指定字符的索引,但是该方法只能获取字符串中第一次出现的字符索引,所以要想获取字符串中指定字符的全部索引时需要通过自定义函数的方式来实现。代码如下:
str_indx_list=[] # 保存指定字符的索引
def get_multiple_indexes(string,str):
str2 = string # 用于获取字符串总长度
while True: # 循环
if str in string: # 判断是否存在需要查找的字符
first_index = string.index(str) # 获取字符串中第一次出现的字符对应的索引
string =string[first_index+1:] # 将每次找打的字符从字符串中截取掉
sum=len(str2)-len(string) # 计算截取部分的长度
str_indx_list.append(sum-1) # 长度减1就是字符所在的当前索引,将索引添加列表中
else:
break # 如果字符串中没有需要查找的字符就跳出循环
print(str_indx_list) # 打印指定字符出现在字符串中的全部索引
s = "aaabbdddabb" # 测试用的字符串
get_multiple_indexes(s,'a') # 调用自定义方法,获取字符串中指定字符的全部索引
13. 【判断字符串是否由字母和数字组成】isalnum()方法
语法参考
isalnum()方法用于判断字符串是否由字母和数字组成。isalnum()方法的语法格式如下:
str.isalnum()
如果字符串中至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False。
锦囊1 判断用户输入的昵称是否正确
通过isalnum()方法判断用户输入的昵称中是否包含了除字母或数字之外的特殊字符,如果包含特殊字符则提示用户重新输入,代码如下:
while True:
str1=input('请输入用户昵称:')
# 检测字符串是否由字母和数字组成
myval=str1.isalnum()
if myval==True: # 如果返回值为True
print('输入正确!')
break
else: # 如果返回值为False
print('“用户昵称”由字母和数字组成,请重新输入!')
锦囊2 滤除空格后判断字符串是否由字母和数字组成
当字符串由字母、数字和空格组成时,isalnum()方法会判断它不是由字母和数字组成,而此时如果我们允许程序存在空格,那么要先将空格滤除,然后再使用isalnum()方法判断,滤除空格主要使用replace()方法,代码如下:
str1='mrsoft 123'
str2=str1.replace(' ','') # 滤除空格
myval1=str1.isalnum()
myval2=str2.isalnum()
print('原字符串:',str1)
print('滤除空格后:',str2)
print(myval1)
print(myval2)
14. 【判断字符串是否只由字母组成】isalpha()方法
语法参考
isalpha()方法用于判断字符串是否只由字母组成。isalpha()方法的格式如下:
str.isalpha()
如果字符串中至少有一个字符并且所有字符都是字母则返回True,否则返回False。
锦囊1 判断输入的用户名是否为全英文
当用户输入用户名时,系统要求输入全英文,因此程序中使用isalpha()方法进行判断,但是当输入中文的汉字时,isalpha()方法也会判断为True,此时应首先使用encode()方法进行编码,然后再使用isalpha()方法判断,代码如下:
while True:
str1=input('请输入用户名:')
myval=str1.encode('UTF-8').isalpha() # 判断输入的用户名
if myval==True:
print('输入正确!')
break
else:
print('用户名为全英文,请重新输入!')
15. 【判断字符串是否只包含十进制字符】isdecimal()方法
语法参考
isdecimal()方法用于检查字符串是否只包含十进制字符。这种方法只适用于unicode对象。
注意:定义一个十进制字符串,只要在字符串前添加’u’前缀即可。
isdecimal()方法的语法格式如下:
str.isdecimal()
如果字符串只包含数字则返回True,否则返回False。
锦囊1 判断字符串是否为十进制
使用isdecimal()方法判断下面的字符串是否为十进制,代码如下:
str = u'mr12468'
print(str.isdecimal())
str = u'12468'
print(str.isdecimal())
16. 【判断字符串是否只由数字组成】isdigit()方法
语法参考
isdigit()方法用于判断字符串是否只由数字组成。isdigit()方法的语法格式如下:
str.isdigit()
如果字符串只包含数字则返回True,否则返回False。
锦囊1 判断输入的邮编是否为全数字
使用isdigit()方法判断用户输入的邮编是否为全数字,代码如下:
while True:
str1=input('请输入邮编:')
# 使用isdigit()方法判断是否为全数字
myval=str1.isdigit()
if myval==True:
print('输入正确!')
break
else:
print('邮编为全数字,请重新输入!')
锦囊2 数字转换为整型前进行判断
将数字转换为整型时,如果用户输入的不是数字那么使用int()函数进行转换时将出现错误提示,此时可以通过isdigit()方法先判断用户输入的是否为数字,如果是数字则转换为整型,否则提示用户重新输入,代码如下:
while True:
str1=input('请输入数字:')
# 使用isdigit()方法判断是否为全数字
myval=str1.isdigit()
if myval==True:
strint=(int(str1)) # 将数字转换为整型
print(strint) # 输出
print(type(strint)) # 判断类型
break
else:
print('不是数字,请重新输入!')
17. 【判断字符串是否为合法的Python标识符或变量名】isidentifier()方法
语法参考
isidentifier()方法用于判断字符串是否是有效的Python标识符,还可以用来判断变量名是否合法。isidentifier()方法的语法格式如下:
str.isidentifier()
如果字符串是有效的Python标识符返回True,否则返回False。
锦囊1 判断字符串是否为Python标识符或者变量名是否合法
下面使用isidentifier()方法判断以下内容是否为Python标识符或者变量名是否合法,代码如下:
print( 'if'.isidentifier() )
print( 'break'.isidentifier() )
print( 'while'.isidentifier() )
print( '_b'.isidentifier() )
print( '666科技888m'.isidentifier() )
print( '886'.isidentifier() )
print( '8a'.isidentifier() )
print( ''.isidentifier() )
18. 【判断字符串是否全由小写字母组成】islower()方法
语法参考
islower()方法用于判断字符串是否由小写字母组成。islower()方法的语法格式如下:
str.islower()
如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是小写,则返回True,否则返回False。
锦囊1 判断字符串完全由小写字母组成
有时候我们需要判断一个字符串,例如判断字符串完全由小写字母组成,代码如下:
str = 'www.mingrisoft.com'
print(str.islower())
str = 'WWW.mingrisoft.COM'
print(str.islower())
19. 【判断字符串是否只由数字(支持罗马、汉字数字等)组成】isnumeric()方法
语法参考
isnumeric()方法用于判断字符串是否只由数字组成。这种方法是只针对unicode对象。
注意:定义一个字符串为Unicode,只要在字符串前添加’u’前缀即可。
isnumeric()方法的语法格式如下:
str.isnumeric()
如果字符串只由数字组成,则返回True,否则返回False。
锦囊1 判断字符串只由数字组成
判断字符串只由数字组成,代码如下:
str = u'mr12468'
print(str.isnumeric())
str = u'12468'
print(str.isnumeric())
str = u'ⅠⅡⅣⅦⅨ'
print(str.isnumeric())
str = u'㈠㈡㈣㈥㈧'
print(str.isnumeric())
str = u'①②④⑥⑧'
print(str.isnumeric())
str = u'⑴⑵⑷⑹⑻'
print(str.isnumeric())
str = u'⒈⒉⒋⒍⒏'
print(str.isnumeric())
str = u'壹贰肆陆捌uuu'
print(str.isnumeric())
锦囊2 简易滤除字符串列表中的数字
如果想从一个含有数字、汉字和字母的列表中滤除仅含有数字的字符,那么可以使用正则表达式来完成,但是如果觉得麻烦,还可以使用isnumeric()方法,代码如下:
str1 = [ 'mrsoft', '2019', 'mrbook88', '12',u'小柒']
for s in str1:
if not s.isnumeric(): # 滤除数字
print(s)
20.【判断字符是否为可打印字符】isprintable()方法
语法参考
isprintable()方法用于判断字符串中所有字符是否都是可打印字符或字符串为空。Unicode字符集中“Other”、“Separator”类别的字符是不可打印的字符(但不包括ASCII码中的空格(0x20))。isprintable()方法可用于判断转义字符。
说明:ASCII码中第0~32号及第127号是控制字符;第33~126号是可打印字符,其中第48~57号为0~9十个阿拉伯数字;65~90号为26个大写英文字母,97~122号为26个小写英文字母。
isprintable()方法的语法格式如下:
str.isprintable()
如果字符串中的所有字符都是可打印的字符或字符串为空则返回True,否则返回False。
锦囊1 判断字符串中的所有字符是否都是可打印的
判断以下字符串是否都是可打印的,代码如下:
str = '\n\t'
print(str.isprintable())
str = 'mr_soft'
print(str.isprintable())
str = '12345'
print(str.isprintable())
str = '蜘蛛侠'
print(str.isprintable())
21.【判断字符串是否只由空格组成】isspace()方法
语法参考
isspace()方法用于判断字符串是否只由空格组成。isspace()方法的语法格式如下:
str.isspace()
如果字符串中只包含空格,则返回True,否则返回False。
锦囊1 判断字符串是否由空格组成
下面使用isspace()方法判断字符串是否只由空格组成,代码如下:
str = ' '
print(str.isspace())
str = 'mr soft 2205'
print(str.isspace())
22. 【判断首字母是否大写其他字母小写】istitle()方法
语法参考
istitle()方法用于判断字符串中所有的单词首字母是否为大写而其他字母为小写。istitle()方法的语法格式如下:
str.istitle()
如果字符串中所有的单词首字母为大写而其他字母为小写则返回True,否则返回False。
锦囊1 判断字符串中所有的单词首字母是否为大写
下面使用istitle()方法判断字符串中所有的单词首字母是否为大写,还记得title()方法吗?该方法可以将单词首字母转换为大写,其他字母小写。如果istitle()方法判断字符串中所有的单词首字母并不都是大写,那么此时可以使用title()方法进行自动转换,代码如下:
str1=input('请输入英文短语:')
myval=str1.istitle()
print(str1.istitle())
if myval==False:
print(str1.title())
23. 【判断字符串是否全由大写字母组成】isupper()方法
语法参考
isupper()方法用于判断字符串中所有的字母是否都是大写。isupper()方法的语法格式如下:
str.isupper()
如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是大写,则返回True,否则返回False。
锦囊1 判断字符串完全由大写字母组成
判断字符串完全由大写字母组成,代码如下:
str = 'www.mingrisoft.com'
print(str.isupper())
str = 'WWW.mingrisoft.COM'
print(str.isupper())
str = 'WWW.MINGRISOFT.COM'
print(str.isupper())
24. 【连接字符串、元组、列表和字典】join()方法
语法参考
join()方法用于连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串。
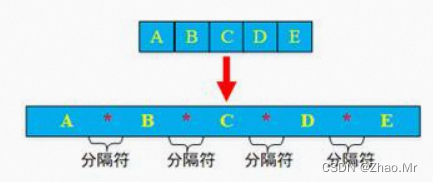
str.join(sequence)
参数说明:
-
str:分隔符,即用什么连接字符串,可以是逗号“,”、冒号“:”、分号“;”和斜杠“/”等等,也可以为空。
-
sequence:可以是字符串、字符串数组、列表、元组或字典等。
下面通过一个简单的举例来了解一下join()方法的用法。例如连接字符串数组“11”、“22”、“33”、“44”,代码如下。
s = ['11', '22', '33', '44']
print(''.join(s))
print('-'.join(s))
print('/'.join(s))
锦囊1 将NBA元组数据输出NBA对阵数据(元组转文本)
有这样一组元组数据“(‘凯尔特人’,‘雄鹿’),(‘猛龙’,‘雄鹿’),(‘雄鹿’,‘篮网’),(‘老鹰’,‘雄鹿’),(‘雷霆’,‘雄鹿’),(‘热火’,‘雄鹿’)”,将每组对阵用vs连接,代码如下:
# 定义元组
mystr=(('凯尔特人','雄鹿'),('猛龙','雄鹿'),('雄鹿','篮网'),('老鹰','雄鹿'),('雷霆','雄鹿'),('热火','雄鹿'))
# 遍历元组
number = [tuple(x) for x in mystr]
for i in number:
newStr=' vs '.join(tuple(i)) # 用vs连接元组
print(newStr)
锦囊2 以不同方式连接音乐列表(列表转文本)
首先创建一个音乐列表,代码如下:
music = ['小星星','沙漠骆驼','奶茶加糖','心如止水','给你比颗小心心']
print(music)
print(' '.join(music))
print('\n'.join(music))
print('\t'.join(music))
锦囊3 连接字典(字典转文本)
使用join()方法操作字典,例如下面的代码:
# 定义字典
mystr = {'明':1,'日':2,'科':3,'技':4}
print(':'.join(mystr))
锦囊4 创建由小写字母和数字组合的18位随机码
下面使用random模块创建一个随机的18位字符串,其中包括小写字母和数字通过join()方法进行组合,代码如下:
import random
import string
print(''.join(random.sample(string.ascii_lowercase + string.digits, 18)))
25.【计算字符串长度或元素个数】len()函数
语法参考
len()函数的主要功能是获取一个(字符、列表、元组等)可迭代对象的长度或项目个数。
其语法格式如下:
len(s)
参数说明:
-
参数s:要获取其长度或者项目个数的对象。如字符串、元组、列表、字典等;
-
返回值:对象长度或项目个数。
锦囊1 获取字符串长度
通过len()函数获取可迭代对象的长度,也就是获取可迭代对象中有多少个元素。通过len()函数获取字符串长度的常见用法如下:
# 字符串中每个符号仅占用一个位置,所以该字符串长度为34
str1 = '今天会很残酷,明天会更残酷,后天会很美好,但大部分人会死在明天晚上。'
# 在获取字符串长度时,空格也需要占用一个位置,所以该字符串长度为10
str2 = 'hello word'
print('str1字符串的长度为:',len(str1)) # 打印str1字符串长度
print('str2字符串的长度为',len(str2)) # 打印str2字符串长度
# 打印str2字符串去除空格后的长度
print('str2字符串去除空格后的长度为:',len(str2.replace(' ','')))
# 字符串中每个元素都是相同的,len函数也会根据实际数量进行长度的获取
str3 = '000000000000'
print('str3字符串长度为:',len(str3)) # 打印str3字符串长度
# 打印机str3字符串指定元素范围的长度,仅获取下标为3及以后的所有元素长度
print('获取str3字符串指定元素范围的长度为:',len(str3[3:]))
str4 = '床前明月光,疑是地上霜。举头望明月,低头思故乡。'
# 从字符第一个开始,以步进值为3获取字符串元素,然后获取提取后字符串的长度
print('根据要求提取后字符串长度为:',len(str4[0:20:3]))
# 获取str4字符串中“床”汉字对应的ASCII码值,然后获取该ASCII码值的长度
print('床ASCII码值的长度为:',len(str(ord(str4[0]))))
锦囊2 读取txt文件并计算每行的长度
按行读取文本文件中的内容,并计算每行的长度,代码如下:
file1 = open("len.txt", "r") # 以读取的方式打开txt文件
for value1 in file1.readlines(): # 循环遍历每行文字
word1 = value1.replace('\n','') # 去除换行符
print(word1) # 打印每行文字
len1 = len(word1) # 获取每行文字长度
print(len1) # 打印长度
file1.close() # 关闭文件
锦囊3 计算一个字符串中包含“aeiou”这5个字符的数量
输出一个字符串中包含“aeiou”这5个字符的数量。代码如下:
import re
def count_vowels(str):
# 使用正则表达式匹配所有包括aeiou的字符,然后计算长度
return len(re.findall(r'[aeiou]', str, re.IGNORECASE))
print(count_vowels('foobar'))
print(count_vowels('gym'))
锦囊4 计算字符串的字节长度
计算字符串在utf-8编码下所占的字节长度。代码如下:
def byte_size(string):
return (len(string.encode('utf-8'))) # 使用encode()函数设置编码格式
print(byte_size('Hello World'))
print(byte_size('人生苦短,我用Python'))
说明:在utf-8编码格式下,一个中文占3个字节。
26. 【字符串左对齐填充】ljust()方法
语法参考
字符串对象的ljust方法是用于将字符串进行左对齐右侧填充。ljust()方法的语法格式如下:
str.ljust(width[,fillchar])
-
width参数表示要扩充的长度,即新字符串的总长度。
-
fillchar参数表示要填充的字符,如果不指定该参数,则使用空格字符来填充。
锦囊1 左对齐填充指定的字符串
以各种方式填充字符串“明日科技”并且左对齐,代码如下:
print("888科技".ljust(8)) # 长度为8,不指定填充字符,字符串后由4个空格字符来填充
print("888科技".ljust(5,"-")) # 长度为5,指定填充字符,字符串后填充一个"-"字符
print("888科技".ljust(3,"-")) # 长度为3,不足原字符串长度,输出原字符串
锦囊2 中英文混排对齐
ljust()方法通过统计字符长度后填充空格的方式使输出的字符串对齐,但ljust()方法在填充包含中英文字符串的时候,填充后的长度总是不对,导致输出无法真正对齐(如图**所示),其根本原因在于ljust()方法统计字符长度时,英文占1个字符位,中文占2个字符位,而由于Python3的utf-8编码方式,中英文都占1字符位,而gbk编码方式是英文1字符位,中文2字符位。因此,解决该问题应首先更改编码方式,然后再使用ljust()方法对齐。
ulist=[]
ulist.append([1,'北京大学','Peking University','685' ])
ulist.append([2,'中国人民大学','Renmin University of China','685' ])
ulist.append([3,'浙江大学','Zhejiang University','676'])
ulist.append([4,'武汉大学','Wuhan University','632'])
ulist.append([5,'mrsoft','mrsoft','123'])
ulist.append([6,'mr学院','mr College','123'])
for ul in ulist:
len1= len(ul[1].encode('gbk')) - len(ul[1]) # 更改编码方式后计算字符串长度
print(ul[0],ul[1].ljust(20-len1),ul[2],ul[3].rjust(30-len(ul[2]))) # 使用ljust()和rjust()方法对齐
27. 【大写字母转换为小写字母】lower()方法
语法参考
lower()方法用于将字符串中的大写字母转换为小写字母。如果字符串中没有需要被转换的字符,则将原字符串返回;否则将返回一个新的字符串,将原字符串中每个需要进行小写转换的字符都转换成等价的小写字符,且字符长度与原字符长度相同。
str.lower()
其中,str为要进行转换的字符串。
锦囊1 将字符串中的大写字母转换为小写字母
将字符串“WWW.Mingrisoft.com”中的大写字母转换为小写字母,代码如下:
str1 = 'WWW.Mingrisoft.com'
print(str1.lower()) # 全部转换为小写字母输出
锦囊2 将大驼峰值改为小驼峰值
骆驼式命名法(Camel-Case)又称驼峰式命名法,是编写程序时的一套命名规则(惯例),通常包括大驼峰命名法和小驼峰命名法。大驼峰是指使用每个单词的首字母全部大写,例如“StudentName”,“StudentCount”等;小驼峰是指第一个单词的首字母的小写,其余单词的首字母全部大写。例如,“studentName”, “studentCount”等。
使用low()函数结合切片功能,将大驼峰值修改为小驼峰值。代码如下:
def decapitalize(string):
"""
将大驼峰转化为小驼峰
:param string: 要转化的字符串
:return: 转化后的字符串
"""
# 将首字母转化为小写,然后拼接剩余字符
return string[:1].lower() + string[1:]
print(decapitalize('StudentName'))
print(decapitalize('StudentCount'))
28.【截掉字符串左边的空格或指定的字符】lstrip()方法
语法参考
lstrip()方法用于截掉字符串左边的空格或指定的字符。lstrip()方法的语法格式如下:
str.lstrip([chars])
参数说明:
-
str:原字符串。
-
chars:指定要截掉的字符串,可以是一个字符,或者多个字符,匹配时不是按照整个字符串匹配的,而是按照顺序一个个字符匹配的。
-
返回值:返回截掉字符串左边的空格或指定字符后生成的新字符串。
锦囊1 去除字符串左边无用的字符
下面使用lstrip()方法截掉字符串左边无用的字符,例如,星号“*”,代码如下:
str1 = '*****mingrisoft***'
print(str1.lstrip('*'))
print(str1.lstrip('**'))
print(str1.lstrip('****'))
print(str1.lstrip('*i')) # 一个个字符匹配,i与原字符不匹配
29. 【创建字符映射的转换表】maketrans()方法
语法参考
maketrans()方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
两个字符串的长度必须相同,为一一对应的关系。maketrans()方法的语法格式如下:
str.maketrans(intab, outtab)
-
intab:字符串中要转换的字符组成的字符串。
-
outtab:目标字符组成的字符串。
-
返回值:此方法返回转换表(字典类型),一般配合translate()方法使用。
锦囊1 将指定的字符替换为数字
下面使用maketrans()方法,将字符串中出现的“ming”分别对应转换为“1234”,然后使用translate()方法生成新的字符串,代码如下:
intab = 'ming' # 原字符组成的字符串
outtab = '1234' # 转换后的字符组成的字符串
str1 = 'www.mingrisoft.com'
mystr = str1.maketrans(intab, outtab)
print(str1.translate(mystr)) # 输出转换后的新字符串
锦囊2 同时删除多种不同字符
下面使用maketrans()方法和translate()方法,将文本中存在的不同字符同时删除,代码如下:
s = 'ab110mr'
# 字符映射加密
print(str.maketrans('abmr', 'mrab'))
# translate把其转换成字符串
print(s.translate(str.maketrans('abmr', 'mrab')))
锦囊3 删除垃圾邮件中的“*_/@.”等特殊符号
日常生活中经常会收到一些垃圾邮件,其中包含一些特殊符号,如“*_/@.”等。下面使用maketrans()方法和translate()方法将这些符号删除,代码如下:
import string
temp = '想做/ 兼_职/程序员_/ 的 、加,我Q: 400*765@1066.!!??有,惊,喜,哦'
print(temp.translate(str.maketrans('', '', string.punctuation)))
锦囊4 删除垃圾信息中的“》【】”等特殊符号
短息、邮箱、微信、QQ等时常会收到一些垃圾信息,这些信息中夹杂着各种符号。下面将使用maketrans()方法和translate()方法删除垃圾信息中的“》【】”等特殊符号,代码如下:
import string
temp1='【学】【编程】【*】【*】,有需要请加 Q Q :400-675-1066.谢谢!'
str1 = string.punctuation + '》【】' # 引入英文符号常量,并附加自定义字符
print(temp1.translate(str.maketrans('', '', str1)))
30. 【分割字符串为元组】partition()方法
语法参考
partition()方法根据指定的分隔符将字符串进行分割。如果字符串中包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子字符串,第二个为分隔符本身,第三个为分隔符右边的子字符串。
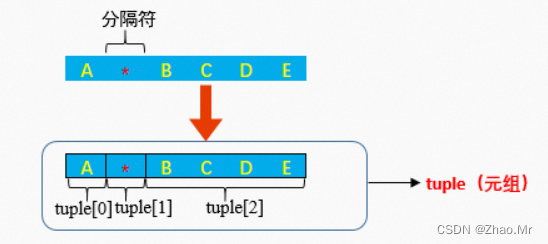
str.partition(str)
锦囊1 以“.”为分隔符将网址分割为元组
以“.”为分隔符分割字符串,例如分解网址“www.mingrisoft.com”,代码如下:
pythonUrl='www.mingrisoft.com' #定义字符串
t1=pythonUrl.partition('.')#以"."分割
print(t1)
31. 【替换字符串】replace()方法
语法参考
replace()方法用于将某一字符串中一部分字符替换为指定的新字符,如果不指定新字符,那么原字符将被直接去除。

str.replace(old [, new [, count]])
-
old:将被替换的子字符串。
-
new:字符串,用于替换old子字符串。
-
count:可选参数,表示要替换的次数,如果不指定该参数则替换所有匹配字符,而指定替换次数时的替换顺序是从左向右依次替换。
锦囊1 替换字符串中指定的字符
使用replace()函数将字符串“www.mingrisoft.com”中的“soft”替换为“book”,代码如下:
str1 = 'www.mingrisoft.com'
print (str1.replace('soft', 'book'))
锦囊2 去除大段文本中的标点字符
经常在网上查阅资料,有时复制的网页内容中会夹杂一些乱七八糟的标点字符,如#、$、%、&、'、(、)、*、+、,等,那么此时可以使用replace()方法将这些标点字符去除,实际上就是将它们替换为空,代码如下:
import string
f = open('./tmp/test3.txt', 'r')
s=f.read()
for c in string.punctuation:
s=s.replace(c,'')
print(s)
锦囊3 去除大段文本中的数字
当文本中存在一些无用的数字时,也可以使用replace()方法并结合string模块digits属性将这些数字去除,代码如下:
import string
f = open('./tmp/test4.txt', 'r')
s=f.read()
for c in string.digits:
s=s.replace(c,'')
print(s)
锦囊4 身份证号中的重要数字用星号代替
str1 = '333333201501012222'
s1=str1[6:14]
print (str1.replace(s1, '********'))
锦囊5 仅显示字符串中的字母与数字
在一些应用软件中,经常会遇到要求用户仅输入字母和数字的情况。下面使用replace()方法对输入的内容自动过滤仅显示字符串中的字母和数字。例如,输入车号“888-吉A-UA561”将自动过滤汉字和特殊符号,仅显示“888AUA561”,代码如下:
str1=input('请输入车号:')
str2 = str1.lower(); #将大写字母转换为小写字母
temp= 'abcdefghijklmnopqrstuvwxyz0123456789'
for c in str2:
if not c in temp:
str1 = str1.replace(c,'');
print(str1)
锦囊6 删除任意位置的相同的字符
删除任意位置的相同的字符。例如,字符串中有多处包含了“\t”,下面使用replace()方法将所有“\t”删除,代码如下:
# 去除字符串中相同的字符
s = '\tmrsoft\t888\tbook'
print(s.replace('\t',''))
锦囊7 通过多次使用replace()方法删除多种特殊符号
通过多次使用replace()方法,将文本中的特殊字符,如“/”、“_”和“*”等删除,代码如下:
temp ='想做/ 兼_职/程序员_/ 的加我Q: 400*765@1066有,惊,喜,哦!!'
print(temp.replace(' ','').replace("*",'').replace('_','').replace('、','').replace('/','').replace(',',''))
锦囊8 Python爬取文本用replace()方法替换p标签
通过Python爬取了“百度知道”中全国985院校有哪些的相关内容,但是文本中存在大量的p标签,例如,“
1. 清华大学(北京)
2. 北京大学(北京)
……”。下面使用replace()方法将标签“
”,将标签“
”替换成换行符“\n”,代码如下:f = open('./tmp/text.txt', 'r') # 打开文本
s=f.read()
s=s.replace('<p>','').replace('</p>','\n') # 替换p标签
print(s,end='') # 输出去掉空行

32.【返回字符串最后一次出现的位置】rfind()方法
语法参考
rfind()方法返回子字符串在字符串中最后一次出现的位置(从右向左查询),如果没有匹配项则返回-1。rfind()方法的语法格式如下:
str.rfind(sub,start,end)
参数说明:
-
str:表示原字符串。
-
sub:表示要检索的子字符串。
-
start:开始查找的位置,默认为0。
-
end:结束查找位置,默认为字符串的长度。
锦囊1 查找指定字符串最后一次出现的位置
查找m在字符串“www.baidu.com”最后一次出现的位置和指定区间内出现的位置,代码如下:
str = 'www.baidu.com'
substr = 'm'
print(str.rfind(substr))
print(str.rfind(substr, 0, 5))
print(str.rfind(substr, 5, 0))
锦囊2 用rfind()方法截取网址中倒数第二个斜杠“/”与最后一个斜杠“/”之间的内容
首先使用rfind()方法获取倒数第二个斜杠“/”的位置,然后使用切片方法截取该内容,代码如下:
str1= 'https://baike.baidu.com/item/%E5%90%89%E6%9E%97%E7%9C%81%E6%98%8E%E6%97%A5%E7%A7%91%E6%8A%80%E6%9C%89%E9%99%90%E5%85%AC%E5%8F%B8/10331044'
end_pos = str1.rfind('/') - 1 # 倒数第一个"/"的位置再左移一位
start_pos = str1.rfind('/', 0, end_pos) # 倒数第二个"/"的位置
str2 = str1[start_pos + 1:end_pos] # 截取倒数第二个 "/" 后面的内容
print(str2)
33. 【返回字符串最后一次出现的位置】rindex()方法
语法参考
rindex()方法的作用与index()方法类似。rindex()方法用于查询子字符串在字符串中最后出现的位置,如果没有匹配的字符串会报异常。另外,还可以指定开始位置和结束位置来设置查找的区间。rindex()方法的语法格式如下:
str.rindex(sub,start,end)
参数说明:
-
str:表示原字符串。
-
sub:表示要检索的子字符串。
-
start:开始查找的位置,默认为0。
-
end:结束查找的位置,默认我字符串的长度。
锦囊1 查找子字符串最后一次出现的位置
查找m在字符串“www.baidu.com”最后一次出现的位置和指定区间内出现的位置,代码如下:
str = 'www.baidu.com'
substr = 'm'
print(str.rindex(substr))
print(str.rindex(substr, 0, 5))
print(str.rindex(substr, 5, 0))
34. 【字符串右对齐填充】rjust()方法
语法参考
字符串对象的rjust方法是用于将字符串进行右对齐左侧填充。rjust()方法的语法格式如下:
str.rjust(width[,fillchar])
-
width:表示要扩充的长度,即新字符串的总长度。
-
fillchar:表示要填充的字符,如果不指定该参数,则使用空格字符来填充。
锦囊1 填充指定的字符串右对齐
以各种方式填充字符串“888科技”并且右对齐,代码如下:
print('888科技'.rjust(8)) # 长度为8,不指定填充字符,字符串前由4个空格字符来填充
print('888科技'.rjust(5,"-")) # 长度为5,指定填充字符,字符串前填充一个"-"字符
print('888科技'.rjust(3,"-")) # 长度为3,不足原字符串长度,输出原字符串
35. 【从右边分隔字符串为元组】rpartition()方法
语法参考
rpartition()方法根据指定的分隔符将字符串进行分割。如果字符串中包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子字符串,第二个为分隔符本身,第三个为分隔符右边的子字符串。partition()方法的语法格式如下:
str.rpartition(str)
rpartition()方法与partition()方法基本一样,细微区别在于rpartition()方法是从目标字符串的末尾也就是右边开始搜索分割符。
锦囊1 rpartition()方法与partition()方法的区别
以“.”为分隔符分割字符串“www.m888888.com”,分别使用rpartition()方法和partition()方法看下输出结果有什么不同,代码如下:
str1='www.m888888.com'
print(str1.rpartition('.'))
print(str1.partition('.'))
36. 【分割字符串】split()方法
语法参考
split()方法可以把一个字符串按照指定的分隔符切分为字符串列表。该列表的元素中,不包括分隔符。
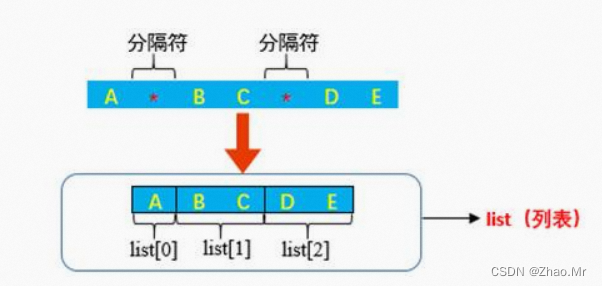
split()方法的语法格式如下:
str.split(sep, maxsplit)
参数说明:
-
str:表示要进行分割的字符串。
-
sep:用于指定分隔符,可以包含多个字符,默认为None,即所有空字符(包括空格、换行“\n”、制表符“\t”等)。
-
maxsplit:可选参数,用于指定分割的次数,如果不指定或者为-1,则分割次数没有限制,否则返回结果列表的元素个数,个数最多为maxsplit+1。
-
返回值:分隔后的字符串列表。
说明:在split()方法中,如果不指定sep参数,那么也不能指定maxsplit参数。
锦囊1 根据不同的分隔符分割字符串
定义一个字符串,然后应用split()函数根据不同的分隔符进行分割字符串,代码如下:
str1 = 'www.m888888.com'
list1 = str1.split() # 采用默认分隔符进行分割
list2 = str1.split('.') # 采用.号进行分割
list3 = str1.split(' ',1) # 采用空格进行分割,并且只分割第1个
print(list1)
print(list2[1])
print(list3)
说明:在使用split()方法时,如果不指定参数,默认采用空白符进行分割,这时无论有几个空格或者空白符都将作为一个分隔符进行分割。
锦囊2 分解网址提取有价值的信息
使用split()函数分解网址从中提取有价值的信息,代码如下:
str='https://www.m888888.com/Index/ServiceCenter/product/id/24.html'
print(str.split())
print(str.split('/'))
print(str.split('/')[-1])
print(str.split('/')[-1].split('.')[0])
锦囊3 删除字符串中连续多个空格而保留一个空格
处理文本过程中,经常会发现文本中存在过多的空格,那么如何删除多余的空格,只保留一个空格呢?下面使用split()方法进行处理,代码如下:
line='吉林省 长春市 二道区 东方广场中意之尊888'
print(' '.join(line.split()))
37. 【返回是否包含换行符的列表】splitlines()方法
语法参考
splitlines()方法用于按照换行符(\r、\r\n、\n)分隔,返回一个是否包含换行符的列表,如果参数keepends为False,则不包含换行符,如果为True,则包含换行符。splitlines()方法的语法格式如下:
str.splitlines([keepends])
-
keepends:输出结果是否包含换行符(\r、\r\n、\n),默认值为False,不包含换行符,如果为True,则保留换行符。
-
返回值:返回一个包含换行符的列表。
锦囊1 返回包含换行符并自动换行的列表
通过splitlines()方法分别得到不带换行符的列表和带换行符的列表,其中不带换行符的列表输出后字符串显示在同一行,而带换行符的列表输出后会自动换行,代码如下:
str = 'Python从入门到项目实践\r\n零基础学Python\r\nPython项目开发案例集锦'
list1=str.splitlines() # 不带换行符的列表
print(list1)
print(list1[0],list1[1],list1[2])
list2=str.splitlines(True) # 带换行符的列表
print(list2)
print(list2[0],list2[1],list2[2],sep='') # 使用sep去掉空格
38. 【是否以指定的子字符串开头】startswith()方法
语法参考
startswith()方法用于检索字符串是否以指定子字符串开头。如果是则返回True,否则返回False。startswith()方法的语法格式如下:
str.startswith(prefix[, start[, end]])
参数说明:
-
str:表示原字符串。
-
prefix:表示要检索的子字符串。
-
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
-
end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
锦囊1 判断手机号是否以“130”、“131”、“186”等联通手机号段开头
用户输入手机号,通过startswith()方法判断输入的手机号是否属于联通号段(“130” “131” “132” “155” “156”“175” “176” “185” “186” “166”),代码如下:
while 1:
# 创建元组
tuples=('130','131','132','155','156','175','176','185','186','166')
str1 = input('请输入联通手机号:')
# 判断手机号是否以指定的字符开头
myval=str1.startswith(tuples,0)
if myval==True:
print(str1.startswith(tuples,0))
break
else:
print('您输入的不是联通手机号,请重新输入!')
39. 【去除字符串头尾特殊字符】strip()方法
语法参考
strip()方法用于移除字符串左右两边的空格和特殊字符。
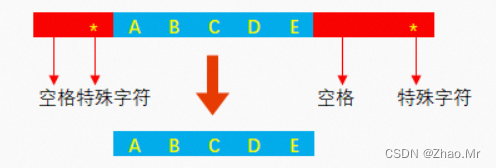
strip()方法的语法格式如下:
str.strip([chars])
参数说明:
-
str:原字符串。
-
chars:为可选参数,用于指定要去除的字符,可以指定多个。例如,设置chars为“ ”,则去除左、右两侧包括的“ ”或“”。如果不指定chars参数,默认将去除字符串左右两边的空格、制表符“\t”、回车符“\r”、换行符“\n”等。
锦囊1 同时去除空格、制表符“\t”、回车符“\r”和换行符“\n”
一般在获取网页文本时会发现复制下来的文本有时会包括一些没用的字符,如空格、制表符、回车符和换行符等。下面使用strip()方法将这些特殊字符去除,代码如下:
str1=' add_sheet会返回一个Worksheet类。创建的时候有可选参数cell_overwrite_ok,表示是否可以覆盖单元格,其实是Worksheet实例化的一个参数,默认值是False。去除字符串中的特殊字符\t\n\r'
print(str1.strip(' \t\n\r')) # 去除字符串中头尾的空格
锦囊2 删除两边的特殊符号和空格
字符串两边可能会包含一些特殊符号和空格,如“-”、“+”和空格。下面使用strip()进行去除,代码如下:
str1='-+-+-吉林省明日科技有限公司+--+- '
# 删除两边 - + 和空格
print(str1.strip().strip('-+'))
锦囊3 删除含有指定字符的所有字符
strip()方法还有一种用法是str.strip©,其中c是一个字符或者一个字符串。它删除的是str字符串从头开始或者从尾开始c中的字符,例如下面的代码:
str='八百标兵 八百标兵奔北坡,炮兵并排北边跑 炮兵怕把标兵碰,标兵怕碰炮兵炮'
print(str.strip('百八炮兵'))
40. 【大小写字母互转】swapcase()方法
语法参考
swapcase()方法用于对字符串的大小写字母进行转换并生成新的字符串,原字符串中的字母大写使用swapcase()方法后会转成小写;原字符串中的字母小写使用swapcase()方法后会转成大写。swapcase()方法的语法格式如下:
str.swapcase()
锦囊1 对输入的英文字母实现大小写互转
下面使用swapcase()方法实现英文字母大小写互转,代码如下:
while True: # 循环输入
s=input('请输入英文:')
print(s.swapcase())
41.【单词首字母转换为大写】title()方法
语法参考
title()方法与前面介绍的capitalize()有些区别,该方法用于将字符串中的每个单词的首字母转换为大写字母,其余字母均为小写。
str.title()
锦囊1 将字符串中每个单词的首字母转换为大写
将字符串“hello word!”中的各个单词中的首字母转换为大写,代码如下:
str1 = "hello word!"
print (str1.title())
42. 【按照转换表转换字符】translate()方法
语法参考
translate()方法根据参数table给出的表(包含256个字符)转换字符串的字符,要过滤掉的字符放到deletechars参数中。translate()方法的语法如下:
str.translate(table[, deletechars])
-
table:转换表,它是通过maketrans方法转换而来的。
-
deletechars:字符串中要过滤的字符列表。
-
返回值:返回转换后的新字符串。
锦囊1 去掉文本中拼音的音调
import sys
import unicodedata
mystr = 'Jí Lín Shěng Míng Rì Kē Jì Yǒu Xiàn Gōng Sī'
# 将unicode字符串转换为普通格式的字符
b = unicodedata.normalize('NFD',mystr)
# 列出组合型字符,并使用dict.fromkeys()方法构造一个字典
mychr = dict.fromkeys(c for c in range(sys.maxunicode) if unicodedata.combining(chr(c)))
# 去除音调
print(b.translate(mychr))
运行程序,输出结果为:
Ji Lin Sheng Ming Ri Ke Ji You Xian Gong Si
43. 【字符串小写字母转换为大写字母】upper()方法
语法参考
upper()方法用于将字符串中的小写字母转换为大写字母。如果字符串中没有需要被转换的字符,则将原字符串返回;否则返回一个新字符串,将原字符串中每个需要进行大写转换的字符都转换成等价的大写字符,且新字符长度与原字符长度相同。
str.upper()
锦囊1 将字符串中的小写字母转换为大写字母
将字符串“www.MINGRISOFT.com”中的大写字母转换为小写字母,代码如下:
str1 = 'www.ASDFIDOSDDFG.com'
print(str1.upper()) # 全部转换为大写字母输出
44. 【字符串前面填充】zfill()方法
语法参考
zfill()方法返回指定长度的字符串,原字符串右对齐,字符串前面填充0。zfill()方法语法格式如下:
str.zfill(width)
锦囊1 数字编号固定五位前面补零
在图书管理系统中,学生学号和图书号只用1-100这种显得不规范,想用00001这种格式。下面使用zfill()方法实现学生学号固定五位,不够五位用0填充。例如,学生学号886用0填充五位为00886,代码如下:
n = '886'
s = n.zfill(5)
print('学生学号为:',s)
45. 【截取字符串】切片方法
语法参考
字符串属于序列,可以采用切片方法截取字符串。切片方法截取字符串的语法格式如下:
string[start : end : step]
参数说明:
-
string:表示要截取的字符串。
-
start:表示要截取的第一个字符的索引(包括该字符),如果不指定,则默认为0。
-
end:表示要截取的最后一个字符的索引(不包括该字符),如果不指定则默认为字符串的长度。
-
step:表示切片的步长,如果省略,则默认为1,当省略该步长时,最后一个冒号也可以省略。

锦囊1 应用切片截取不同位置的字符
应用切片方法截取不同位置的字符并输出,如果字符中的最后一位是特殊字符(如空格、回车符等)可使用[:-1]去掉,具体代码如下:
str1 = '人生苦短,我用Python!&' # 定义字符串
substr1 = str1[1] # 截取第2个字符
substr2 = str1[5:] # 从第6个字符截取
substr3 = str1[:5] # 从左边开始截取5个字符
substr4 = str1[2:5] # 截取第3个到第5个字符
substr5=str1[:-1] # 去掉最后一个字符
print(substr1+'\n'+substr2+'\n'+substr3+'\n'+substr4+'\n'+substr5)
锦囊2 反转字符串
反转字符串就是将输入的字符串反转过来,例如将“888888科技有限公司”反转过来,代码如下:
sStr1 = '888888科技有限公司'
sStr1 = sStr1[::-1]
print(sStr1)
输出结果为:'公司限有技科888888'。
这是将字符串 sStr1 反转(倒序)的操作,使用 [::-1] 可以实现。
46. 【使用百分号“%”格式化字符串】
语法参考
在Python中,要实现格式化字符串,可以使用“%”操作符。语法格式如下:
'%[-][+][0][m][.n]格式化字符'%exp
参数说明:
-
- :可选参数,用于指定左对齐,正数前方无符号,负数前面加负号。
-
+ :可选参数,用于指定右对齐,正数前方加正号,负数前方加负号。
-
0 :可选参数,表示右对齐,正数前方无符号,负数前方加负号,用0填充空白处(一般与m参数一起使用)。
-
m:可选参数,表示占有宽度。
-
.n:可选参数,表示小数点后保留的位数。
-
格式化字符:用于指定类型。
-
exp :要转换的项。如果要指定的项有多个,需要通过元组的形式进行指定,但不能使用列表。
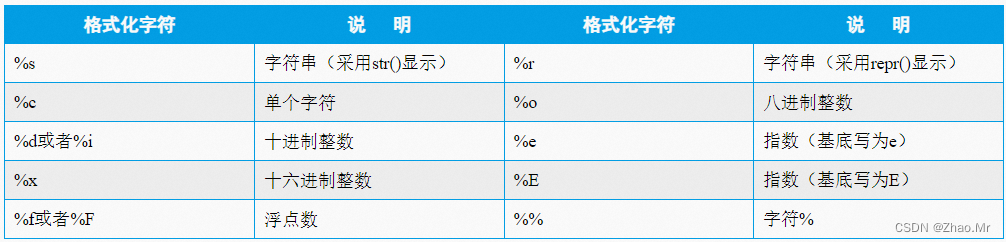
锦囊1 对齐输出字符串
下面使用通过填补空格的方法实现对齐输出字符串,代码如下:
ulist=[]
ulist.append([1,'北京大学','Peking University',685 ])
ulist.append([2,'中国人民大学','Renmin University of China',685 ])
ulist.append([3,'浙江大学','Zhejiang University',676])
ulist.append([4,'武汉大学','Wuhan University',632])
for ul in ulist:
# 当字符串长度小于6时,在字符串的左侧填补空格,使得字符串的长度为6
print(ul[0],'%+6s'%ul[1],'\t%6d'%ul[3])
锦囊2 使用%s将日期型数据转换为字符串
有时需要将日期型数据转换为字符串,此时可以使用%s进行转换。例如,将当期系统日期转换为字符串,代码如下:
import datetime
d1 = datetime.date.today() # 获取当前系统日期
print(type(d1)) # 判断日期类型
d2='%s' % d1 # 将日期转换为字符串
print(type(d2)) # 判断日期类型
print(d2) # 输出日期
47. 【直接或通过“+”和“,”等操作符操纵字符串】
语法参考
在Python中有几种非常简单的方法可以实现快速连接字符串,例如直接连接、加号“+”、逗号“,”、星号“*”以及百分号“%”等。
例如,使用加号“+”连接字符串,语法格式如下:
str1+str2+str3+……+strn
锦囊1 直接连接字符串
在Python中可以直接连接字符串,代码如下:
print('www.''qwerty''.com')
锦囊2 使用加号“+”批量增加前缀
使用加号“+”可以直接将两个字符串进行连接,下面实现批量为文章标题增加前缀“原创:”,代码如下。
file1 = open('./tmp/test6.txt')
for value1 in file1.readlines():
word1 = '原创:'+str(value1)
print(word1)
file1.close()
锦囊3 使用逗号“,”连接字符串返回元组
如果两个字符串之间用逗号“,”隔开,那么这两个字符串将被连接,但是,字符串之间会多出一个空格,代码如下:
str1='www.','qwewertyu','.com'
print(str1)
锦囊4 使用星号“*”实现字符串拷贝
用星号“*”实现字符串的拷贝,代码如下:
mystr='科技 '
print(mystr*3)
锦囊5 使用百分号“%”格式化字符串
这种方式是使用百分号“%”实现格式化字符串和一组变量,其中字符串为Python的占位符%s,占位符的数量和右边变量的数量应相同,连接后占位符会自动被用右边变量组中的变量替换。例如下面的代码:
mystr1 = '888'
mystr2 = '科技'
print('%s%s%s'%(mystr1,mystr2,'mrkj'))
说明:占位符%s表示字符串str,还可以表示整数int,浮点数float。
锦囊6 多行字符串连接
在Python中如果有未闭合的小括号,Python会自动将多行连接为一行,相比三个引号和换行符,这种方式不会把换行符、前导空格当作字符。代码如下:
mystr = ('吉林省'
'长春市'
'二道区'
'东方广场')
print(mystr)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









