







决策模型在学习中有一个重要的因素损失函数(并不是每一个公式都可以拿最小二乘法解)
线性回归除了做预测还可以做分类,比如鸢尾花数据

这个算法是用了sklearn

定义一个线性回归的对象,然后把数据放进去开始训练,得到斜率和结局

这是预测

所以线性回归还可以做分类

现在采用统一分布(uniform)的方式取随机值(random)low最小值10000,最高值100000,size取多少个数据

线性回归可以做分类,但是先天不足,因为先天的假设就是数据就是尽可能靠拢
现在想得到一个分类,都是1,形状是50长的数组,int32的数组,这类数据就是1万到10万之间的

现在产生第二类数据,数据全是0,值从0到3万

这两类样本想要合并成一类样本,hstack(水平stack),把两个数据横列在一起,y也一样


把坐标轴放大点

这样分类的正确率也能达到60,70%

这样就能看到其中的问题
1:传统的线性回归输出不适合分类判定;
围绕分类,对线性回归改造它的输出值,其实概率大于50%,就有理由认为是100%
2:分类上逻辑存在缺陷
假设1:线性假设,因为先天的假设就是数据就是尽可能靠拢
假设2:真实值存在误差,误差是独立,epsilon是动态分布的,整个假设建立在误差上,误差是独立的。
假设3:误差服从正态分布

这里的假设是有缺陷的,所以对分类逻辑要重新设计:(任何分类都需要正面因素(就是概率)+负面因素)
从概率方面重新设计,还需要改造线性回归的输出怎么样不是一个完全的线性,把线性回归的输出值统一做一个规则化,规则成概率,然后概率的方式看输出值。变成一个正因素和负因素的逻辑推理,以整个推理的方式来照道函数的概率,再找到损失函数,再找到最小求解,这个值就是可靠的
线性回归只考虑单一输出值,不足以作为分类的标准。逻辑回归是在线性回归的基础上改造

重做模型就是为了分类而重做。
逻辑回归改造线性回归,是把线性回归只限制在0和1,分类模型一定是概率模型

模型重构的过程:
存在一个函数把任意值映射到0-1之间,就是S曲线函数:

dfrac分数分母1,分子1+e^(-1指数)

这个模型就是s曲线函数,x等于0,或是x无穷大,它的值都在0和1之间

可以写程序,把这个画出来
x的坐标等于,np,产生一个连续的数linespace(-10到10之间,产生个数100个,数据是浮点数,float32位)
y的坐标就是上面的


数据再狠一点

这条曲线有良好的性质,在0的时候就是x的直线,导数可以自增的表示

任何的样本,再之后的任何决策模型,都可以加上一句话,s(x权重),包含结局。就把之前下线性回归之上做了修正,这样y和x之间就不是一个线性,但是把这个模型称为广义的线性回归模型中的分支

s不管怎么算都改变不了后面的线性结局

但是,是不是这个概率,就要正反两个因素重构回归模型来决定,如何从正因素还是负因素来做推理
现在认为x的数据受某种因素影响是为A类的,判断其他因素可能是B类,这两种运算就得到两个值

这是从似然函数到损失函数怎么来的
y值等于0或1

想要变成行的概念,使用双斜杠\

上面A可以是正因素,下面的B是负因素

写成一个比较严格的表达方式,eqslant相等

现在从正反两个因素来推导结果

这样就从正反因素变成了决策模型,就是0和1

还可以变成这样


重新回到线性回归来分析,从概率误差角度来分析,模型建立好后,就要分析误差,快速做两个推导,最终是要把W求出来,这样算出的Y值就是概率模型
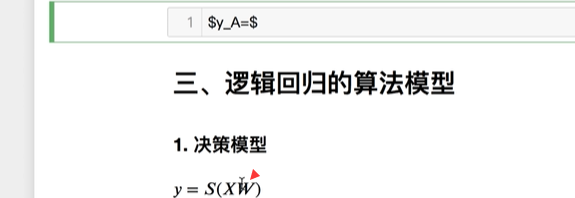
A类 和B类各有误差,两套标准

**推导出影响xw的因素,正反因素,s的值不起绝对作用,主要是w。epsilon是误差值,从误差角度来看
**

转换成下面的概念,弥补线性回归分类不足的模型,主要是分类,概率可能性的分类模型,既然是概率分类就不是单纯一个值,而是大于等于,小于多少,建立一个正反两方面的概率模型


这样就算出来z大于0

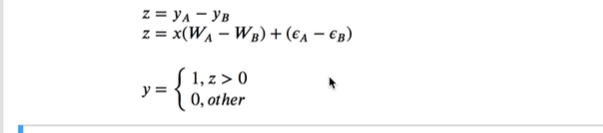
就会发现上面的公式回归的线性回归上面

这样有十足的把握,sw算出来就是概率

这个模型又回到线性代数模型,叫ze,最终xw,有理由相信它是个概率
 、
、
这里的epsilon求出来尽可能小,概率才是最大的

求w的概率模型,概率=1

按照刚才的推导,可以做一个转换


也可以认为epsilon> -xw,这是一个样本产生的值
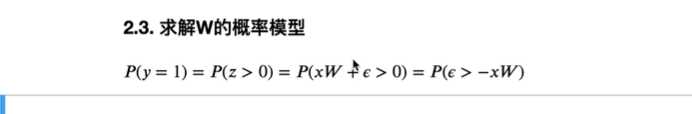
如果这个模式=0 ,那就可以把epsilon变成相反的模型
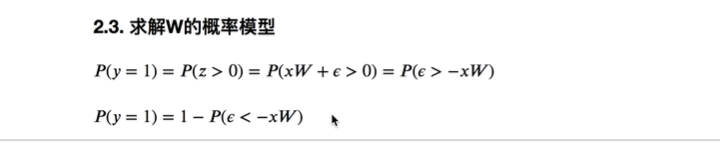
假设epsilon服从正态分布


误差越小越好

这个模型在数学里称为PROBIT

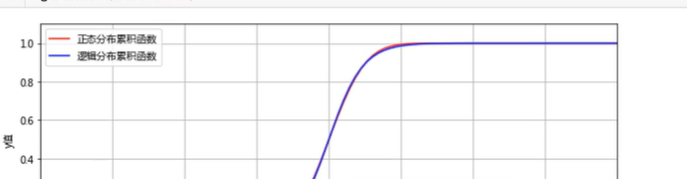
上面的是理想模型,这个模型有个问题,正态分布概率函数,没有一个数学函数可以表达他的概率累积函数,这个公式无解

为了求解,数学家找了一个非常接近的,sigmoid函数,S曲线函数





加上一个系数,

这样正态分布累积函数和逻辑分布累积函数惊人相似
因为正态分布没办法求,就只能用分子分母

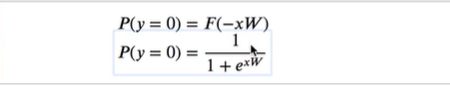
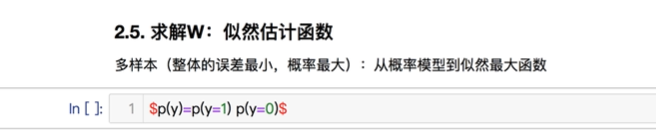
如何让误差越小,概率越大,单样本要变成多样本模型(总体误差越小,概率越高),从概率模型到似然最大函数。
y是1的几率,是0的几率
采用概率的计算使用二项分布:


由于误差,这个y可能是0.几
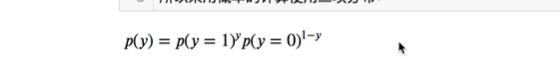
多个样本可以写成下面的

整个概率,就变成多个样本的概率模型,最大似然函数
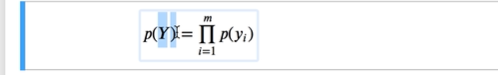
这个p(yi)单个样本,把逻辑样本概率乘起来,就属于同一结果的概率模型
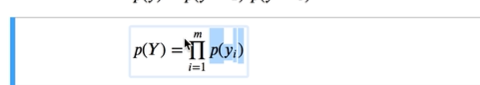
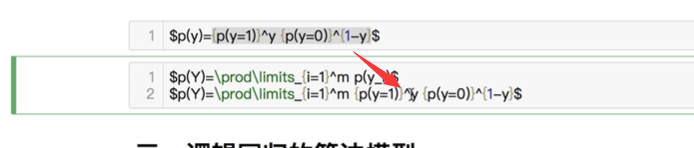
copy下来替换y的模型

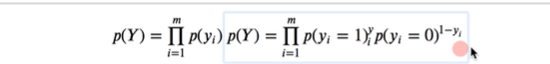
加个bar区分开


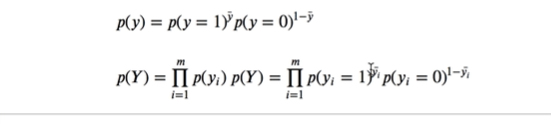


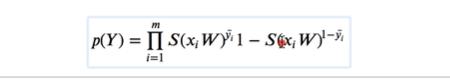
方便后面加上1

最大似然函数
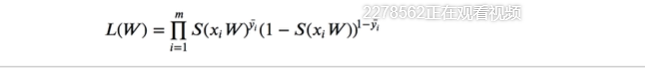
如果要求最大似然函数的结果,求对数

概率越大,误差越小,似然函数就是这么来的,w不好求,需要梯度下降
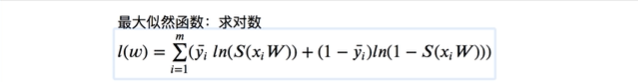
为了方便可以加上dfrac{1}{m}求平均数

也有的在前面加符号

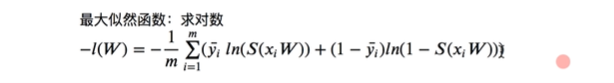
因为是负数,所以是求最小值,这就是机器学习里逻辑回归鼎鼎大名的损失函数

在机器学习里叫交叉熵函数

真实的结果

理想算出的结果

权重

线性回归是直接算出矩阵,可以求出来,逻辑回归到现在为止还不指望算结果

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









