






 本文提出了一种结合时间延迟补偿、加权RLS滤波和深度神经网络的AEC算法,用于AEC-Challenge。算法在主观测试中表现出色,尤其是在残余回声抑制方面。
本文提出了一种结合时间延迟补偿、加权RLS滤波和深度神经网络的AEC算法,用于AEC-Challenge。算法在主观测试中表现出色,尤其是在残余回声抑制方面。
参考文献:WEIGHTED RECURSIVE LEAST SQUARE FILTER AND NEURAL NETWORKBASED RESIDUAL ECHO SUPPRESSION FOR THE AEC-CHALLENGE
论文题目:针对AEC挑战的加权递归最小二乘滤波器和基于神经网络的残余回声抑制
参考资料: https://www.cnblogs.com/LXP-Never/p/11071911.html#blogTitle46
摘要
本文提出了一种提交给 AEC 挑战赛的实时声学回声消除 (AEC) 算法。该算法由三个模块组成:基于时延补偿的广义互相关与PHAse变换(GCC-PHAT)、基于加权递归最小二乘(wRLS)的线性自适应滤波和基于神经网络的残余回声抑制。wRLS 滤波器源自一种新颖的半盲源分离视角。神经网络模型根据对齐参考和线性滤波器输出来预测相敏掩模(PSM)。该算法的平均主观得分为 4.00,在 AEC-Challenge 中排名第二。
索引术语——AEC-Challenge、加权 RLS、残余回声抑制、深度神经网络
1、引言
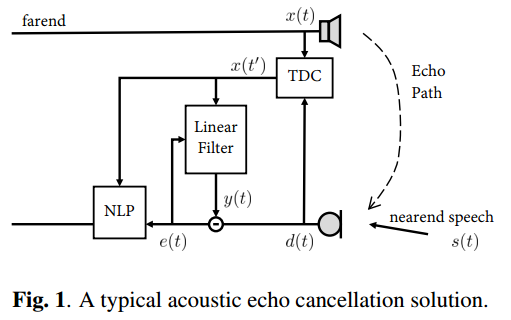
声学回声消除 (AEC) 在全双工语音通信系统中起着至关重要的作用。AEC 的目标是在有扬声器信号(远端)时不出现回声泄漏,在用户说话(近端)时不出现语音失真。自电信业早期以来,这一直是一个具有挑战性的问题 [1]。一个实用的声学回声消除解决方案,例如 WebRTC 项目 [2] 中的解决方案,通常由三个模块组成:时间延迟补偿 (TDC)、线性自适应滤波和非线性处理 (NLP)。
时间延迟补偿是必要的,特别是在麦克风信号捕获和扬声器信号渲染由不同线程处理并且采样时钟可能不同步的实际系统中。远端和近端信号之间的典型延迟范围为10 ms 到 500 ms。尽管理论上,线性自适应滤波器可以通过拥有足够数量的滤波器抽头来处理任何延迟。TDC 可以通过避免过度参数化和加速收敛来提高性能。时延估计方法包括广义互相关与PHAse变换(GCC-PHAT)算法[3]和音频指纹技术[4]。
线性自适应滤波器,例如归一化最小均方(NLMS)滤波器[5]和卡尔曼滤波器[6],可以在时域或频域设计。为了获得最佳性能,滤波器长度应该很长足以覆盖整个回声路径,这可能是时域中的数千个抽头。频域自适应滤波器(FDAF)[7]更常被选择用于节省计算量和更好的建模统计。
引入 NLP 作为线性滤波的补充,以抑制残余回声。这些方法通常改编自降噪技术,例如多帧维纳滤波器[8]。最近的许多研究还采用深度学习方法来抑制残余回声[9,10,11,12],并在合成数据集上报告合理的客观分数。一个担忧是神经网络模型在实际应用中可能会显着退化。因此,AEC-Challenge [13] 的组织目的是通过提供真实环境中 2,500 多个真实音频设备和人类说话者的录音来刺激该领域的研究。该评估基于在所有不同的单通话和双通话场景中获得的平均 P.808 平均意见得分 (MOS) [14]。
本文描述了我们向 AEC-Challenge 提交的内容,该挑战由三个级联模块组成:用于时间延迟补偿的 GCC-PHAT、用于线性滤波的加权递归最小二乘法 (wRLS) 和深度前馈顺序存储网络 (Deep-FSMN) [ 15]用于残余回声抑制。 wRLS 滤波器源自一种新颖的半盲源分离视角,并且显示出对双方通话友好。该算法在挑战赛中证明了其有效性,并将在以下部分中进行描述。
2、提出的算法
如图 1 所示,t 时刻捕获的信号表示为:
![]()
其中x(t)、s(t)和v(t)分别是远端信号、近端语音信号和信号建模误差。a(t)表示回声路径,*表示卷积。为了简单起见,下面假设 v(t) = 0。 d、x、a、s的频率表示分别记为D、X、A、S。
2.1、延时补偿
首先应用GCC-PHAT算法来对齐远端参考和近端麦克风信号。广义互相关定义为![]() ,其中 E[·] 表示期望,f 为频率指数,
,其中 E[·] 表示期望,f 为频率指数,![]() 为变量的共轭。在线实现由下式给出:
为变量的共轭。在线实现由下式给出:
![]()
其中 α 是平滑参数。相对延迟 τ 是通过执行快速傅立叶逆变换 (IFFT) 并找到最大值的索引来获得的:
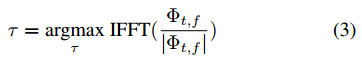
2.2、wRLS 滤波
在频域中对时间对齐的信号![]() 和d(t)执行线性滤波。假设回声路径有 L 个抽头,信号模型重新表述为:
和d(t)执行线性滤波。假设回声路径有 L 个抽头,信号模型重新表述为:
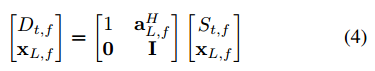
其中![]() 且
且![]() ,其中
,其中![]() 表示转置,
表示转置,![]() 表示Hermitian转置。I是 L 阶酉矩阵。近端语音可以通过以下方式分离:
表示Hermitian转置。I是 L 阶酉矩阵。近端语音可以通过以下方式分离:
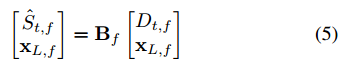
其中![]() 表示变量的估计,
表示变量的估计,![]() 称为解混矩阵。
称为解混矩阵。
方程(5)清楚地定义了半盲源分离问题。假设![]() 独立,解混矩阵具有以下独特形式:
独立,解混矩阵具有以下独特形式:
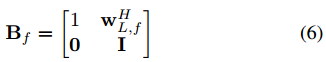
这可以通过成熟的源分离算法来解决,例如独立分量分析(ICA)和基于辅助功能的(Aux-) ICA法[16]。Aux-ICA解决方案简要描述如下,详细推导可见[17]。
引入Kullback-Leibler散度作为独立性度量

其中 p(·) 代表源概率密度函数 (PDF),q(·) 是各个源的近似 PDF 的乘积。损失的上限由辅助损失函数决定
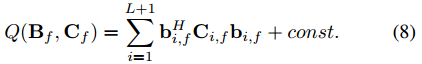
其中![]() 是
是![]() 和辅助变量的第 i 行向量
和辅助变量的第 i 行向量
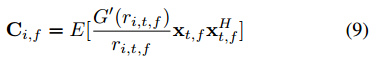
其中![]() 和
和![]() 为第 i 个分离源。G(r) 称为对比函数,具有关系
为第 i 个分离源。G(r) 称为对比函数,具有关系![]() 。
。
方程 (8) 可以根据![]() 最小化为:
最小化为:
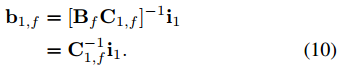
其中![]() 是一个 L+ 1 维向量。进一步通过应用
是一个 L+ 1 维向量。进一步通过应用![]() 的块矩阵求逆,解混滤波器系数由下式给出
的块矩阵求逆,解混滤波器系数由下式给出
![]()
其中
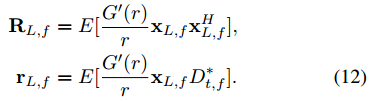
分离的近端语音获得为:
![]()
公式(11)代表加权 RLS 滤波器,其中相关加权因子由底层近端源 PDF 决定。在文献中,一般的超高斯源 PDF 具有以下形式
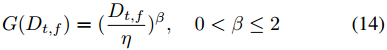
其中建议形状参数为 β ∈ [0.2, 0.4]。
2.3、残余回声抑制
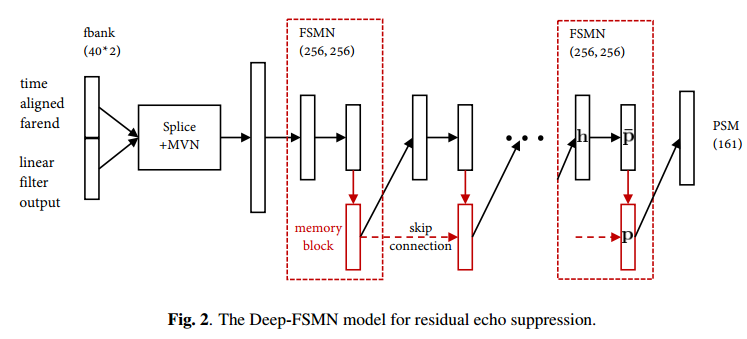
用于残余回声抑制的 Deep-FSMN 模型如图 2 所示。时间对齐远端的对数滤波器组能量 (fbank) 和 wRLS 滤波器输出信号用作神经网络的输入。计算流程由下式给出:
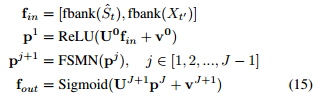
其中![]() 和
和![]() 分别是第j层的权重矩阵和偏置向量。每个 FSMN 块具有 1 个隐藏层、1 个映射层和1个存储块。实现由下式给出:
分别是第j层的权重矩阵和偏置向量。每个 FSMN 块具有 1 个隐藏层、1 个映射层和1个存储块。实现由下式给出:
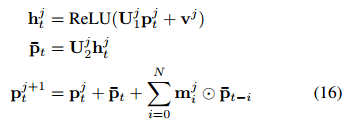
其中![]() 是对历史信息
是对历史信息![]() 进行加权的内存参数,表示逐元素乘法。N是回看顺序。在存储块之间添加跳跃连接以缓解训练阶段的梯度消失问题。
进行加权的内存参数,表示逐元素乘法。N是回看顺序。在存储块之间添加跳跃连接以缓解训练阶段的梯度消失问题。
训练目标是原始相位敏感掩模 (PSM) 的修改版本,并被限制在 [0,1] 范围内
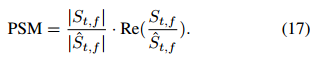
尽管在最近的 DNSChallenge [18] 中应用的复值掩码可能具有更好的性能,但在我们的初步实验中没有观察到显着的增益。
3、与先前工作的关系
[19, 20] 研究了从源分离角度解决 AEC 问题,并讨论了基于 ICA 的解决方案。这里,导出了基于 Aux-ICA 的解决方案,并产生了新颖的加权 RLS 滤波器。
利用深度神经网络进行残余回声抑制是文献中的一种趋势实践。在这里,我们从系统的角度考虑因果 Deep-FSMN 架构与 TDC 和 wRLS 滤波器联合的能力
4、实验
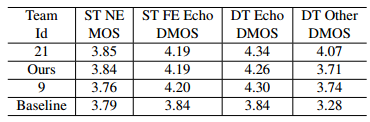
AEC-Challenge 数据集1 涵盖以下场景: 远端 (FE) 单通话 (ST),有或没有回声路径改变;近端 (NE) 单通话,无回声路径变化;双讲 (DT),有或没有回声路径改变。远端和近端语音都可以是干净的或嘈杂的。该评估基于盲测集上的 P.808 平均意见得分 (MOS) [14]。前 3 个结果如表 1 所示。
4.1、算法详情
wRLS 自适应滤波器基于帧移为 10 ms 的 20 ms 帧和 320 点离散傅里叶变换进行计算。使用等式(4)中的 L = 5 的滤波器抽头,并且滤波器系数如等式(11)中那样更新,其中相关矩阵 R 和相关向量 r 使用平滑参数 0.8 和源 PDF 形状递归估计式(14)中参数β = 0.2。
TDC部分配置为覆盖高达500ms的相对延迟,这需要16384点离散傅立叶变换。为了降低计算复杂度,通过式(3)每250 ms更新一次估计,并且在此期间均匀分布不同频率下的![]() 的计算。
的计算。
对于残差回声抑制神经网络,其推理过程按照公式(15)计算。输出![]() 逐点与
逐点与![]() 相乘以进行信号重构。FSMN 块有 J = 9 个,每个块有 256 个隐藏单元、256 个映射单元,回看阶数为 N = 20。输入特征由过去一帧和未来一帧拼接而成,得到一个维度为 240 的向量,然后对均值和方差进行归一化。
相乘以进行信号重构。FSMN 块有 J = 9 个,每个块有 256 个隐藏单元、256 个映射单元,回看阶数为 N = 20。输入特征由过去一帧和未来一帧拼接而成,得到一个维度为 240 的向量,然后对均值和方差进行归一化。
模型中有 1.4M 个可训练参数。在采用时钟频率为 1.9 GHz 的 Intel Core i5-8350U 的 Surface 笔记本电脑上,基于内部 C++/SSE2 实现,推断一帧所需的平均时间为 0.61 毫秒(TDC、wRLS 为 0.19 毫秒,RES 为 0.42 毫秒)。
4.2、训练设置
为了训练神经网络,官方合成数据集中的前 500 个片段用作验证集,其余 9,500 个话语用于训练。此外,训练数据增强如下:
1. 随机重新混合官方合成数据集中的回声和近端语音(19,000 个语句)。
2. 在真实数据集中选择远端单通话话语,并与近端语音(28,998 个语句)随机重新混合。
3. 使用真实数据集中的扫频信号来估计回声路径,并使用 LibriSpeech 语料库 [21] 中的话语重新生成双讲通话数据,信号回声比 (SER) 均匀分布在 [-6, 10] dB (25,540语句)。
其中
- E是统计 期望操作(平均操作)
- s(n)是近端语音
- d(n)是远端回声
代码如下:
def SER(near_speech, far_echo):
"""signal to echo ratio, 信号回声比
:param near_speech: 近端语音
:param far_echo: 远端回声
"""
return 10*np.log10(np.mean(near_speech**2)/np.mean(far_echo**2))4. 在模拟房间中重新生成 24,000 个随机房间脉冲响应,并有选择地向回声信号(24,000 个话语)添加音频效果 [削波、频带限制、均衡、类 sigmoid 变换]。
Deep-FSMN模型在均方误差损失函数下使用学习率为0.0003的Adam优化器进行优化。该模型首先针对 9,500 个话语进行 10 个 epoch 的训练,然后在增强训练集上进行微调。如果损失改进小于 0.001,则学习率衰减 0.6。最佳模型是根据在验证集上评估的 ITU-T 建议 P.862 语音质量感知评估 (PESQ) 分数来选择的。
4.3、分析
在表1中,基线是一个循环神经网络,它将麦克风信号和远端信号的级联对数功率谱特征作为输入,并输出频谱抑制掩模[13]。它在 ST NE 场景中表现相当不错,但在存在回声时落后于顶级系统。非正式聆听表明,我们提出的算法有时会过度抑制双讲中的近端语音,这可能解释了 DT Other DMOS 与第一个系统的差距。
表 1. 不同测试场景的 MOS。
在表 2 中,就验证集 500 个片段的 PESQ 和短时目标清晰度(STOI)[22] 以及测试集 ST FE 的回声回波损耗增强(ERLE)而言,将拟议的 wRLS 滤波器与 WebRTC-AEC3 [2] 中的线性滤波器进行了比较。ERLE 的定义如下
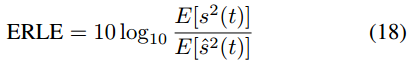
![]()
回波损失增强(ERLE)通常用于评估系统在 没有近端信号 的 单通话情况下 的回声抑制。
ERLE的得分越高,代表回声消除系统越好。
为了评估系统在双讲情况下的性能,通常采用PESQ (语音质量感知评价)或STOI (短时语音可懂度),他是通过将估计的近端语音和仅在双讲通话期间真实的近端语音进行比较得到的。PESQ评分范围为-0.5 ~ 4.5,分数越高质量越好。STOI评分范围为0~1,分数越高越好。
代码如下:
def compute_ERLE(mic_wav, predict_near_end_wav):
"""
:param mic_wav: 麦克风信号(y) = 近端语音(s) + 远端语音回声(s) + 噪声(v)
:param predict_near_end_wav: 估计的近端语音信号 \hat{s}
麦克风信号
"""
mic_near = np.mean(mic_wav**2)
predict_near_end_wav = np.mean(predict_near_end_wav**2)
ERLE = 10 * np.log10(mic_near/predict_near_end_wav)
return ERLE表 2. PESQ 和 STOI 在综合验证集上进行评估。 ERLE 在测试集中的 ST FE 上进行评估。
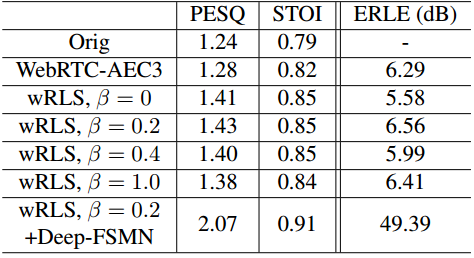
wRLS 滤波器的性能随源 PDF 形状参数的不同而变化。最终选择 β = 0.2 的值,该值在 PESQ 中优于 AEC3 0.15,在 STOI 中优于 AEC3 0.03,在 ERLE 中优于 AEC3 0.27 dB。 Deep-FSMN模型极大地提升了整体性能,达到了2.07的PESQ分数,并且在存在回声时几乎完全消除了回声。
5、结论
本文介绍了我们向 AEC 挑战赛提交的作品。该算法通过系统地结合时间延迟补偿、新颖的 wRLS 线性滤波器和用于残余回声抑制的 Deep-FSMN 模型,在真实录音上获得了令人满意的主观分数。 wRLS 滤波器源自声学回声消除问题的半盲源分离重构和 Aux-ICA 解决方案的简化。一种以原始近端麦克风信号和远端信号作为输入并输出近端语音的端到端神经网络模型更有吸引力,这将是这项工作的未来方向。

















 4973
4973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









