






英文题目:AN MVDR-EMBEDDED U-NET BEAMFORMER FOR EFFECTIVE AND ROBUST MULTICHANNEL SPEECH ENHANCEMENT
论文连接:https://ieeexplore.ieee.org/abstract/document/10448366
摘要
在多通道语音增强 (SE) 系统中,深度神经网络 (DNN) 通常用于直接估计干净语音以实现有效的波束形成。然而,这种方法可能无法充分推广到新的声学或噪声条件。或者,DNN 可以通过预测语音和噪声模式的时频掩模来间接执行 SE,以协助经典的统计波束形成器。尽管它很稳健,但其有效性受到后期统计成分依赖于某些建模假设的限制,例如最小方差无失真响应 (MVDR) 波束形成器中基于协方差的建模。在本文中,我们提出了一种新颖的两种方法的集成方法,即在 U-Net 波束形成器中引入一个嵌入的 MVDR 模块,该模块兼具两者的优点,即有效性和稳健性。实验表明,MVDR 内部可以带来改进,而仅仅扩大基线 SE 网络是无法实现的。
索引词——多通道语音增强、神经波束形成、MVDR、时频掩模、空间滤波
1、介绍
基于深度神经网络 (DNN) 的估计目标和输入模式,基于波束成形的多通道语音增强 (SE) 系统已出现多种类型 [1、2、3、4、5、6]。对于仅使用麦克风阵列的 SE 系统,主流的基于波束成形的方法利用 DNN 直接估计干净语音以获得有效性,例如 [7、8、9、10、11、12、13、14],如图 1 (a) 所示。此类方法完全由数据驱动,当测试条件与训练条件相似时能够实现相当有效的性能,但可能缺乏对未见过的室内声学和噪声条件的泛化能力。
另一种流行的方法是基于时频 (T-F) 模板的统计波束形成,其中 DNN 通过估计一些代表 T-F 域中语音和噪声模式的 T-F 模板来间接执行 SE [15、16、17、18、19、20]。随后利用估计的 T-F 模板来估计信号和噪声统计数据,以用于经典波束形成器,例如最小方差无失真响应 (MVDR) 滤波器 [21],如图 1 (b) 所示。虽然这种类型的方法可能更稳健,因为 DNN 只需执行相对简单的 T-F 模板预测任务,但其有效性通常受到后续统计波束形成算法的限制,该算法依赖于几个建模假设。
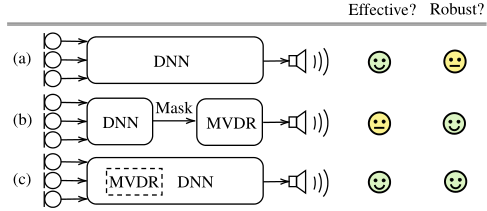
图 1. 不同多通道 SE 系统的说明:(a) DNN 直接波束形成器;(b) DNN 后跟统计波束形成器(例如 MVDR);(c) MVDR 嵌入式 DNN 波束形成器(提出)。
在本文中,我们研究了两种方法类型的集成,以涵盖它们各自的优点,即有效性和鲁棒性,如图 1 (c) 所示。为此,我们引入了嵌入在 U-Net 直接波束形成器网络中的 MVDR 内部模块,以结合基于 TF 掩模的统计波束形成。研究发现,通过将基于掩模的 MVDR 模块放置在 U-Net 的编码器和解码器层中间,可以有效利用多通道信号的空间特征来改善 SE 结果,而模型大小仅略有增加。此外,研究发现,通过利用多尺度空间特征进行处理,以多层次的方式将 MVDR 内部与 U-Net 集成可以进一步改善效果。
2、背景
信号模型:我们考虑一个声学场景,该场景在混响环境中有一个所需语音源和几个干扰噪声信号。我们的系统是使用短时傅里叶变换 (STFT) 在 T-F 域中开发的。令 f, t 代表频率和时间帧索引(总共有 F 个频率箱和 T 个时间帧)。我们考虑一个加性噪声模型,其中第 i 个麦克风噪声信号![]() 属于一个 N 元素本地麦克风阵列,其第 (f, t) 个条目是
属于一个 N 元素本地麦克风阵列,其第 (f, t) 个条目是![]() ,可以写成 [22]:
,可以写成 [22]:![]() 其中
其中![]() 和
和 ![]() 分别是麦克风 i 接收到的语音分量
分别是麦克风 i 接收到的语音分量![]() 和噪声分量
和噪声分量![]() 的第 (f, t) 个条目。在本文中,我们考虑在给定麦克风信号
的第 (f, t) 个条目。在本文中,我们考虑在给定麦克风信号![]() 的情况下恢复选定参考麦克风
的情况下恢复选定参考麦克风![]() 的语音分量
的语音分量![]() 的目标。
的目标。
DNN 直接波束形成器(直接 BF):多通道 SE 系统通常执行“滤波和求和”操作或“波束形成”——线性组合多通道信号以从背景噪声中提取目标信号 S [21]。在 T-F 域中,它可以表示为:![]() ,其中
,其中![]() 是麦克风 i 的对应滤波器权重集,
是麦克风 i 的对应滤波器权重集,![]() 是增强信号,⊙表示逐元素乘法。在许多基于 DNN 的方法 [7、8、9、10、11、12、13、14] 中,网络用于模仿这种波束形成过程(在时间或 TF 域中),以直接输出通过最小化某些信号重建损失训练的干净语音。这种类型的方法是有效的,因为网络可以学习直接从数据中建模噪声-干净映射,但可能无法充分推广到未见过的测试条件。
是增强信号,⊙表示逐元素乘法。在许多基于 DNN 的方法 [7、8、9、10、11、12、13、14] 中,网络用于模仿这种波束形成过程(在时间或 TF 域中),以直接输出通过最小化某些信号重建损失训练的干净语音。这种类型的方法是有效的,因为网络可以学习直接从数据中建模噪声-干净映射,但可能无法充分推广到未见过的测试条件。
基于 T-F 掩模的统计波束形成器:另一类方法利用 DNN 估计一组表示 STFT 域中语音和噪声模式的 T-F 掩模,随后用于估计信号统计数据(即功率谱密度 (PSD) 矩阵),以辅助依赖于精确 PSD 估计的传统波束形成算法,例如 MVDR 波束形成器 [21]。此类方法通常称为基于 T-F 掩模的神经波束形成器 [15、16、17、18、19、20]。具体而言,利用 DNN 预测的 T-F 掩模对带噪信号进行加权,以估计语音和噪声 PSD 矩阵![]() ,例如
,例如
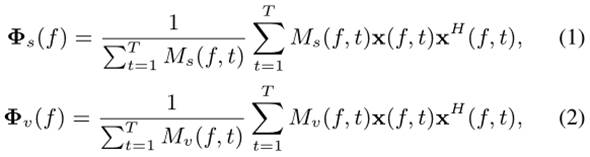
其中![]() 分别是估计的语音和噪声掩模,其第 (f, t) 个条目
分别是估计的语音和噪声掩模,其第 (f, t) 个条目![]() 和
和 ![]() 通常在 [0, 1] 中取值,
通常在 [0, 1] 中取值,![]()
![]() 是第 (f, t) 个 bin 处的带噪信号快照(snapshot)。在这些方法中,通过最小化预测掩模和某个预定义目标掩模之间的某些距离测量(例如平均绝对误差)来训练 DNN 来预测这些掩模 [18, 19]。由于 DNN 只需估计中间掩模,因此它们可以更好地推广到看不见的声学和噪声条件。然而,整体 SE 性能往往受后期统计成分的限制。
是第 (f, t) 个 bin 处的带噪信号快照(snapshot)。在这些方法中,通过最小化预测掩模和某个预定义目标掩模之间的某些距离测量(例如平均绝对误差)来训练 DNN 来预测这些掩模 [18, 19]。由于 DNN 只需估计中间掩模,因此它们可以更好地推广到看不见的声学和噪声条件。然而,整体 SE 性能往往受后期统计成分的限制。
3. 提出的方法
我们的系统如图 2 所示,其中图 3 中所示的所提出的内部 MVDR 模块被整合到骨干 U-Net 直接 BF 模型中。它在 T-F 域中运行,将带噪信号 STFT ![]() 作为输入并预测滤波器权重
作为输入并预测滤波器权重![]() 以估计干净语音。由于 STFT 的复杂性,我们进一步利用了 [23, 24] 之后的复值网络操作,同时注意到实值 U-Net 也可用作具有相同设计概念的骨干模型。接下来,我们详细描述了为改进基线 U-Net 而提出的主要组件。
以估计干净语音。由于 STFT 的复杂性,我们进一步利用了 [23, 24] 之后的复值网络操作,同时注意到实值 U-Net 也可用作具有相同设计概念的骨干模型。接下来,我们详细描述了为改进基线 U-Net 而提出的主要组件。
3.1. 直接BF网络内的MVDR模块
如图 2 所示,所提出的系统具有嵌入在骨干 U-Net 直接 BF 中的 MVDR 内模块,以利用传统的统计波束成形。每个 MVDR 内模块由一个 T-F 掩模估计网络和一个基于掩模的 MVDR 处理组成,如图 3 所示。此处,掩模估计网络采用编码器特征图并预测语音和噪声掩模![]() 和
和![]() ,以估计 PSD 矩阵(如 (1) 和 (2)),以对带噪 STFT 执行 MVDR 滤波。
,以估计 PSD 矩阵(如 (1) 和 (2)),以对带噪 STFT 执行 MVDR 滤波。
在图 2 中,MVDR 内部模块位于编码器和解码器单元之间,作为每个级别的中间特征增强器,它将带噪信号 STFT 和编码器特征图结合起来,从多通道数据中提取有用的空间特征,然后传递给解码器单元。值得注意的是,原始 MVDR 是从最小化零语音失真约束的输出信号方差的标准推导出来的 [21]。在这里,MVDR 被集成为一个网络模块,所有可学习的参数都联合优化,以获得最终的干净信号重建损失,就像在典型的直接 BF 中一样。
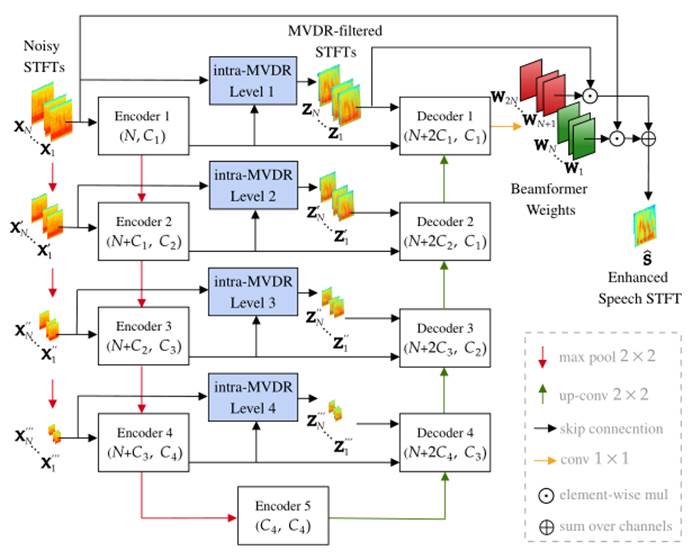
图2. 提出的用于SE的MVDR嵌入式U-Net波束形成器。
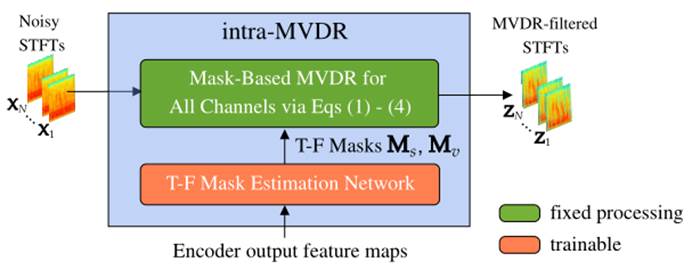
图 3. 所提出的 MVDR 模块(第 1 级)的详细信息。
3.2. 利用所有麦克风的 MVDR 滤波信号
在典型的基于掩模的神经波束形成器中,MVDR 通常是最后的处理阶段,只有参考通道信号通过 MVDR 滤波得到增强。而在我们的方法中,作为中间模块,我们可以更灵活地利用 MVDR 的空间滤波特性,对所有麦克风执行 MVDR 滤波,即以每个麦克风 i 作为参考通道并生成相应的 MVDR 滤波信号![]() ,其中,
,其中,
![]()
![]() 其中x(f, t)为输入带噪信号快照,
其中x(f, t)为输入带噪信号快照,![]()
![]() 为MVDR波束形成器权重向量,由[21]给出:
为MVDR波束形成器权重向量,由[21]给出:
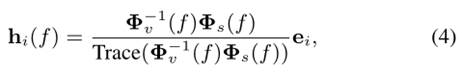
其中,PSD 矩阵![]() 是根据 (1) 和 (2) 以及
是根据 (1) 和 (2) 以及![]() 计算的,其中 1 位于麦克风 i 的第 i 个位置。换句话说,MVDR 滤波 (3) 执行 N 次以获得针对所有 N 个麦克风的滤波信号,其中每次使用 (4) 为每个特定通道 i 计算滤波器系数
计算的,其中 1 位于麦克风 i 的第 i 个位置。换句话说,MVDR 滤波 (3) 执行 N 次以获得针对所有 N 个麦克风的滤波信号,其中每次使用 (4) 为每个特定通道 i 计算滤波器系数![]() 。最后,生成的
。最后,生成的![]() 被输入到解码器单元作为额外的空间特征,以改进模型学习。
被输入到解码器单元作为额外的空间特征,以改进模型学习。
3.3. 基于 Intra-MVDR 的多尺度波束形成
作为 U-Net 编码器和解码器单元之间的桥梁,内部 MVDR 模块在 U-Net 的每一级都配备一个内部 MVDR 模块,自然而然地适应多尺度设计。如图 2 所示,输入的 STFT ![]() 通过最大池化下采样为
通过最大池化下采样为![]() 和
和![]() ,然后输入到相应级别的编码器和内部 MVDR 模块中。更准确地说,我们按照 U-Net 前半部分的下采样操作顺序对 STFT 声谱图执行 2-D 最大池化操作。这样,在池化操作之后,带噪信号声谱图将变得与传递到相应级别 k 的编码器单元的下采样特征图相同大小。然后,N 个频谱图可以通过连接来增强
,然后输入到相应级别的编码器和内部 MVDR 模块中。更准确地说,我们按照 U-Net 前半部分的下采样操作顺序对 STFT 声谱图执行 2-D 最大池化操作。这样,在池化操作之后,带噪信号声谱图将变得与传递到相应级别 k 的编码器单元的下采样特征图相同大小。然后,N 个频谱图可以通过连接来增强![]() 个特征图,从而成为编码器的
个特征图,从而成为编码器的![]() 个输入特征图。最后,通过将编码器输出特征图作为 T-F 掩码估计网络的输入,将帧内 MVDR 应用于相应的带噪信号的频谱图。因此,整个 SE 模型可以利用各种分辨率的粗粒度和细粒度空间特征。
个输入特征图。最后,通过将编码器输出特征图作为 T-F 掩码估计网络的输入,将帧内 MVDR 应用于相应的带噪信号的频谱图。因此,整个 SE 模型可以利用各种分辨率的粗粒度和细粒度空间特征。
3.4. 结合MVDR滤波信号进行目标重建
由于 MVDR 滤波信号![]() 是带噪信号输入的增强版本,因此将它们包含在最终滤波阶段可以为模型提供额外的灵活性,以通过细化来估计干净信号。因此,我们结合
是带噪信号输入的增强版本,因此将它们包含在最终滤波阶段可以为模型提供额外的灵活性,以通过细化来估计干净信号。因此,我们结合![]() 在网络输出端重建目标语音。如图 2 所示,U-Net 输出 2N 组滤波器权重
在网络输出端重建目标语音。如图 2 所示,U-Net 输出 2N 组滤波器权重![]() 。前 N 组是与带噪 STFT
。前 N 组是与带噪 STFT ![]() 相乘的系数,与典型的滤波和求和方案相同;其余滤波器权重
相乘的系数,与典型的滤波和求和方案相同;其余滤波器权重![]() 用于加权 MVDR 输出
用于加权 MVDR 输出![]() ,
,![]() 。增强语音由加权和给出:
。增强语音由加权和给出:
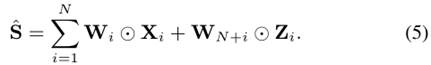
根据经验,我们观察到 (5) 比仅考虑带噪 STFT 的滤波和求和可以产生更好的重建语音。
网络架构细节:我们对图 2 中模型的原始 U-Net [25] 进行了以下修改:U-Net 的卷积层全部被复数卷积层取代。对于激活函数,使用复数 leaky ReLU,即对实值和虚值都应用 leaky ReLU 的激活函数。每层的特征图数量也进行了修改。每个编码器或解码器层由两层“(复数)3×3 卷积→批量归一化→leaky ReLU”组成,其中 (Cin, Cout) 指定输入和输出通道的数量:第一层卷积层采用 Cin 特征图并输出 Cout 特征图;第二层卷积层采用 Cout 特征图并输出 Cout 特征图。关于图 3 中的 T-F 掩码估计网络,它由“(复杂)3×3 卷积→批量归一化→leaky ReLU→1×1 卷积→Sigmoid”层组成。 3×3 卷积层获取 Cout 个特征并输出 Cout 个特征;1×1 卷积层获取 Cout 个特征并输出两个 T-F 掩码,其中 Cout 是给定级别的编码器输出特征图的数量。
4、实验
我们通过实验表明,第 3 节中提出的组件比图 1(a)和(b)中的基线方法可以提高 SE。
数据集和评估:我们使用公开的 CHiME-3 数据集 [26],这是一份 6 麦克风录音,记录了说话者在嘈杂环境中说话,采样率为 16 kHz。它由 7,138 和 1,320 个模拟话语组成,分别用于训练和测试。我们遵循许多现有工作,将第 5 个通道作为 SE 目标的参考麦克风。对于评估,我们使用:PESQ:语音质量感知评估 [27](值:-0.5 到 4.5)。STOI:短时客观清晰度 [28](值:0 到 1)。SNR:信噪比。在所有指标中,分数越高,SE 越好。
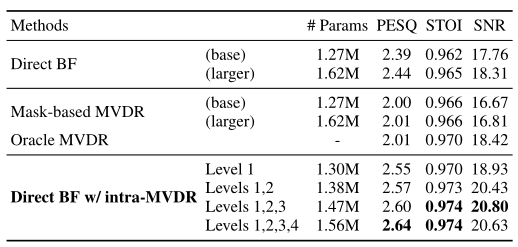
表 1. 不同多通道 SE 方案的比较。对于直接 BF(图 1 (a))和基于掩模的 MVDR(图 1 (b))方法,我们展示了基础(1.27M)和更大(1.62M)U-Net 模型的结果。对于我们的方法(图 1 (c)),我们展示了将不同级别的内部 MVDR 模块合并到基础(1.27M)U-Net 模型中的结果,与图 2 中的系统相对应。
模型设置:我们设置图 2 中的通道数 C1、C2、C3、C4 = 32、64、64、64,从而得到一个包含 1.27M 参数的基本 U-Net 模型。对于 STFT 处理,我们使用 Hann 窗口,窗口大小为 1024,跳数为 256。在训练期间,从训练样本中随机裁剪 4 秒长的片段,而在测试期间则使用整个话语。对于训练,采用 Adam 优化器,学习率为 0.001,在第 50 个 epoch 时降低到 0.0001,总共 80 个 epoch。使用的批处理大小为 4。对于直接波束形成方案,训练网络以最小化信号重建损失:![]() ,即[29]中的组合幂律压缩均方误差损失。
,即[29]中的组合幂律压缩均方误差损失。
我们基于使用相同主干(1.27M)U-Net 模型比较以下案例的 SE 性能:
i)直接 BF(图 1(a)):通过预测用于过滤输入带噪信号的波束形成器滤波器权重,训练 U-Net 直接估计干净语音
ii)基于掩模的 MVDR(图 1(b)):训练 U-Net 估计语音和噪声理想比率掩模 [18]。在推理过程中,估计的掩模用于 MVDR 过滤
iii)带内部 MVDR 的直接 BF(图 1(c)):建议的嵌入 U-Net 直接 BF 的 intraMVDR 模块
对于直接 BF 和基于掩模的 MVDR 这两种基线方法,我们还提供了使用更大的 U-Net 模型(1.62M)的结果,其中 C1、C2、C3、C4 = 36、72、72、72 以供比较。
结果:表 1 显示了结果。我们首先比较了两种基线方法,发现直接 BF 的性能通常优于基于掩模的 MVDR,因为网络经过训练可以直接重建干净的语音以提高效率。另一方面,虽然基于掩模的 MVDR 可能很稳健,但其性能上限受 oracle MVDR 性能(也显示在表中)的限制,该性能使用真实信号 PSD 矩阵来计算最佳滤波器。最后,仅在第一级(1.30M)使用 intraMVDR 的提议直接 BF 已经获得了比两个基线更高的分数。我们还看到,在 U-Net 的后续分辨率(级别)上配备 intra-MVDR 块可以进一步提高性能,这表明多尺度空间特征是有帮助的。请注意,改进并非纯粹是由于添加的 intra-MVDR 模块增加了模型大小,因为我们可以看到,尽管使用了更大的模型大小(1.62M),但这两种基线方法与所提出的方法的性能并不匹配。结果表明,通过结合统计滤波器(鲁棒性)和 DNN 直接 BF(有效性)的优点,我们可以实现 SE 改进,而这并非通过简单地扩大基线网络就能实现的。图 4 可视化了由我们的完整系统(1.56M)和从 CHiME-3 测试集中获取的嘈杂话语的两个较大基线(1.62M)处理的示例 SE 输出,以便于比较。

图 4. SE 输出的可视化。与基于 Mask 的 MVDR 相比,所提出的方法具有更少的残余噪声(即更好的噪声抑制),同时与 Direct BF 相比保留了更多的语音成分(即更少的语音失真),从而实现了最佳语音质量。
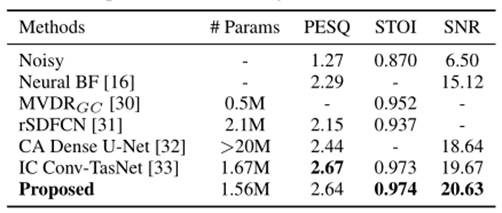
为了更好地量化所提出方法的性能,我们将完整系统(即表 1 中的 1.56M 模型)的结果与也在 CHiME-3 测试集上评估的现有多通道 SE 系统进行了比较,包括 Neural BF [16]:一种通过双向 LSTM 进行掩模估计的 MVDR 波束形成器。MVDRGC [30]:一种使用基于神经网络的方法来识别和纠正转向矢量中的相位误差的 MVDR 波束形成器。rSDFCN [31]:一种用于多通道 SE 的具有 sinc 和扩张卷积层的时域全卷积网络 (FCN)。CA Dense U-Net [32]:一种时频域多通道 SE 模型,结合了 DenseNet、U-Net 和通道注意 (CA) 机制的优点。IC Conv-TasNet [33]:一种基于全卷积时域音频分离网络的多通道 SE 系统,利用通道间关系。在表 2 中,我们报告了取自相应论文的 PESQ、STOI 和 SNR,表中缺失的条目表示参考论文中未报告该指标。可以看出,所提出的方法在 STOI 和 SNR 方面优于其他方法,并且在 PESQ 方面与 IC Conv-TasNet 相当,尽管使用的模型较小,证明了其实现高效 SE 的能力。
表 2. 与现有多通道 SE 方法的比较。
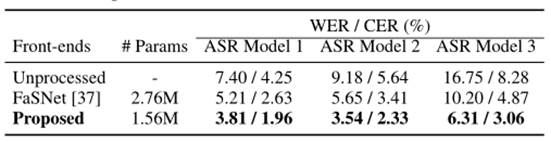
除了上述质量/清晰度分数之外,我们还在表 3 中评估了 SE 模型作为噪声环境下自动语音识别 (ASR) 的前端去噪器的性能。为此,我们通过训练有素的 SE 模型预处理嘈杂的 CHiME-3 多通道数据,并将去噪后的音频分别输入到取自 NVIDIA NeMo 工具包1 的三个预训练 ASR 引擎:模型 1:Conformer-CTC [34]、模型 2:Citrinet [35] 和模型 3:Quartznet [36]。我们报告每个 ASR 引擎结果的字错误率 (WER) 和字符错误率 (CER)。为了证明所提方法的优势,我们将我们的完整系统与一种现有的直接 BF 方法,即滤波求和网络 (FaSNet) [37] 进行了比较。为了公平起见,我们使用相同的信号重建损失自己训练了 FaSNet2。结果表明,我们的方法在三个 ASR 引擎中以较小的模型尺寸实现了比 FaSNet 更低的 WER 和 CER,表明其能够有效提高机器在噪声中的聆听能力。
表 3. SE 模型作为 ASR 前端降噪器的比较。
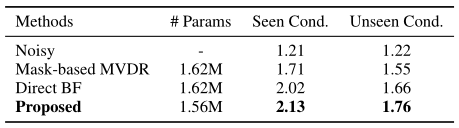
为了进一步验证所提出的方法兼具基于掩模的统计波束形成和 DNN 直接波束形成的优点,我们利用 Pyroomacoustics [38] 模拟训练和测试数据,以使用来自 AVSpeech 数据集 [39] 的语音语料库来证明其有效性(在可见或类似的声学和噪声条件下)和鲁棒性(推广到未知条件)。我们采用 8308 条语音进行训练,1099 条语音进行测试,每条语音都与从 YouTube 下载的四种噪声配置文件混合。我们创建了两个测试集,其中测试集 1 具有与训练相同的声学和噪声环境,即房间大小、混响时间、噪声类型(即 {搅拌机、吸尘器、洗衣机、婴儿哭声})和源位置。同时,测试集 2 具有与训练不同的背景噪声类型,即 {狗叫、孩子玩耍、吹风机、食物咝咝作响},以及不同的房间大小、混响时间和源位置。表 4 显示了 4 麦克风平面阵列的 PESQ 结果。与两个基线相比,所提出的方法在测试集 1 中取得了最高结果,证明了对可见条件的有效性,并且在测试集 2 上的性能下降较少,表明对看不见的条件具有鲁棒性。
表 4. 用于比较在可见房间/噪声条件下对测试数据的有效性以及在未知条件下的稳健性的 PESQ 分数。
5. 结论
在本文中,我们通过引入嵌入在 U-Net 设计中的内部 MVDR 模块,提出了一种 DNN 直接波束成形和基于掩模的统计波束成形的新型集成。新模型兼具两种方法的优点,使所提出的嵌入 MVDR 的 U-Net 波束成形器能够更好地利用多尺度空间特征。我们表明,通过结合内部 MVDR 模块,可以有效实现 SE 有效性的提高以及对可见和不可见的室内声学和噪声条件的稳健性。

















 1836
1836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









