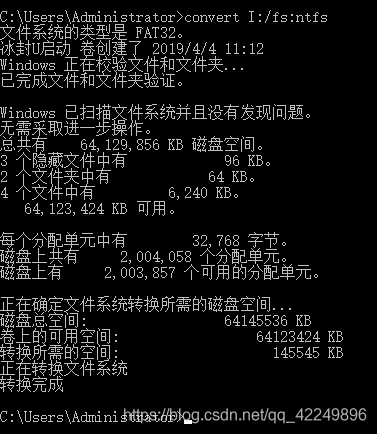
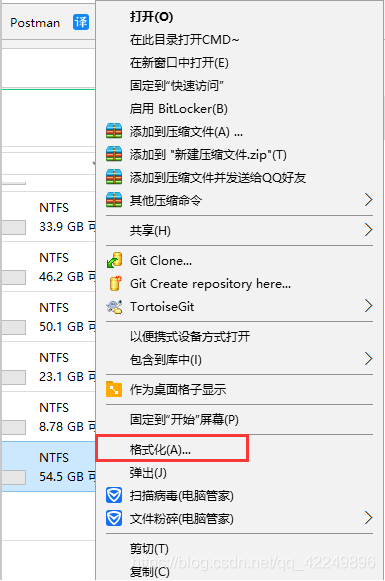
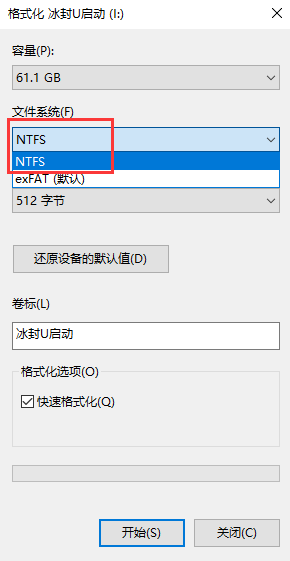
问题场景: 当我们把一个大文件或压缩移入到一个盘(u盘或硬盘)里,提示对于目标文件系统过大无法移动,就是该盘的文件系统导致的,转换为NTFS即可! 方案一(建议使用): 1、windows+R来打开cmd命令行: 2、输入convert H:/fs:ntfs(其中H指的是U盘或硬盘的盘符:我的是H盘) 3、转换成功: 方案二(不建议使用): 选择盘符并右击: 选择相应的NTFS文件系统然后在进行格式化:
























 3909
3909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






